Python可视化数据分析01、python环境搭建

【摘要】 编辑Python可视化数据分析01、python环境搭建📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Python初始环境地址:【Python可视化数据分析01、python环境搭建】💝 环境需求环境:win10开发工具:Py...

![]()
Python可视化数据分析01、python环境搭建
📋前言📋
💝博客:【】💝
✍本文由在下【红目香薰】原创,首发于CSDN✍
🤗2022年最大愿望:【服务百万技术人次】🤗
💝Python初始环境地址:【】💝
环境需求
环境:win10
开发工具:PyCharm Community Edition 2021.2
数据库:MySQL5.6
目录
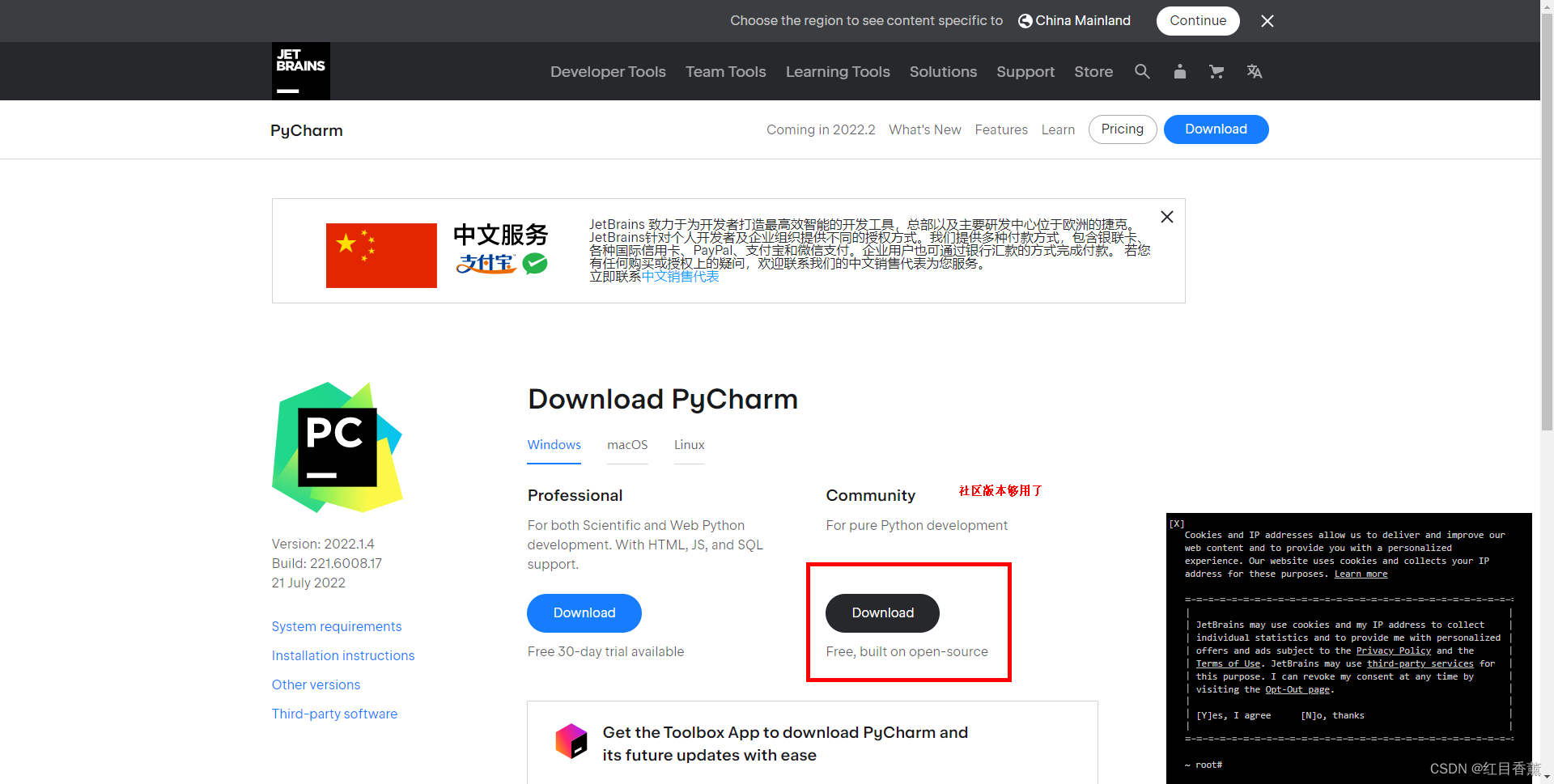
工具下载
下载地址:
![]()
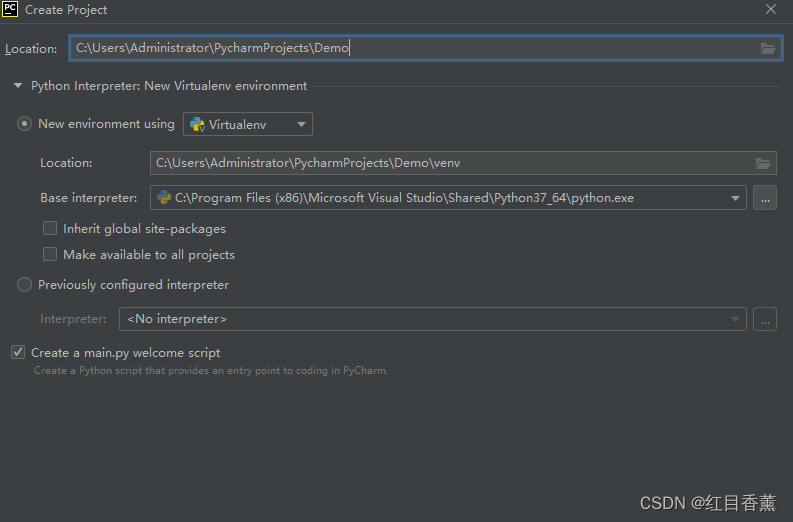
创建项目
![]()
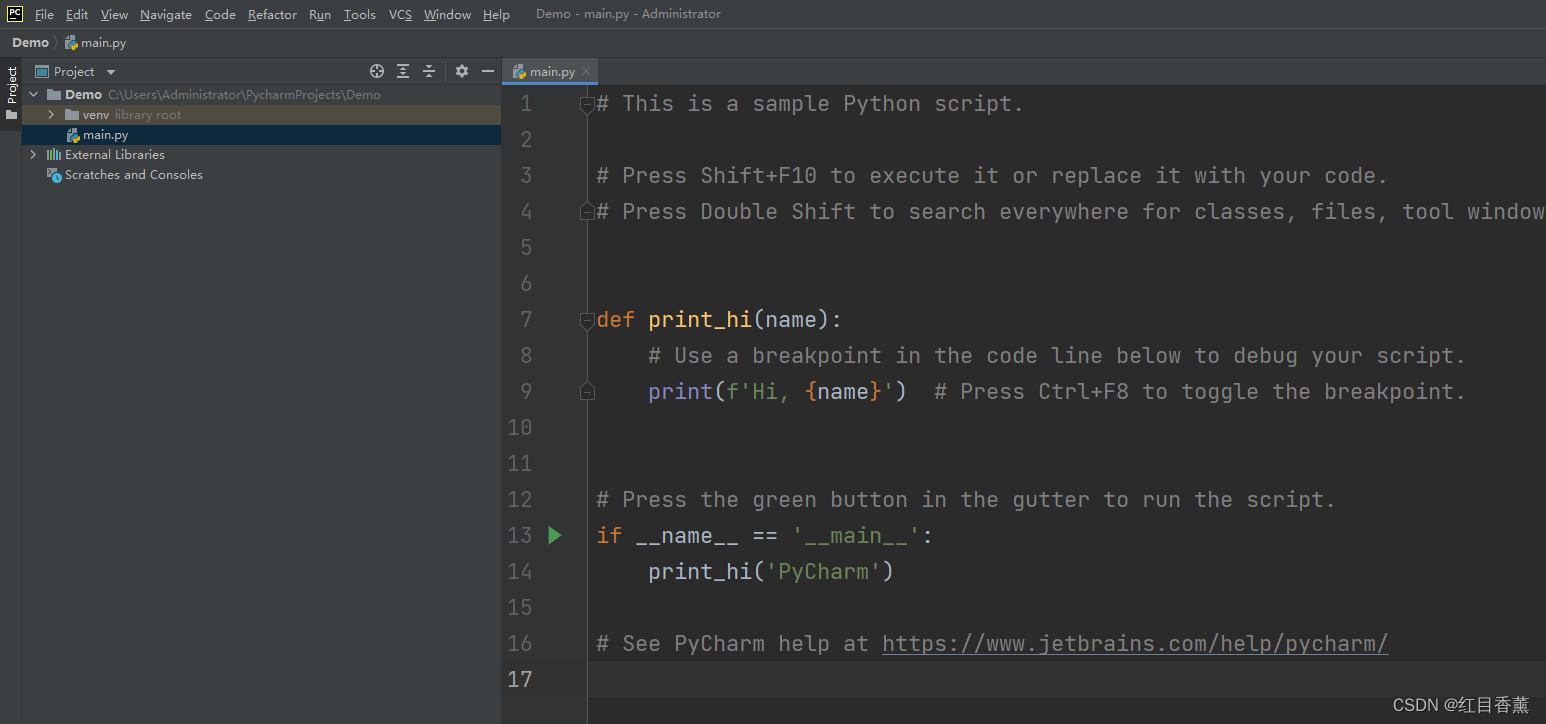
项目:
![]()
面板

![]()
更新最新的pip
pip3 install --upgrade pip控制台和【cmd】都行

![]()
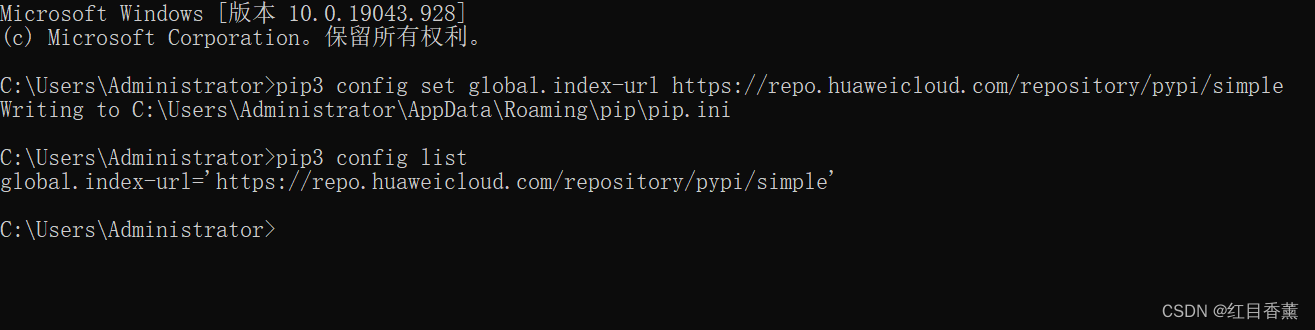
pip更换镜像源
pip3 config set global.index-url https://repo.huaweicloud.com/repository/pypi/simple
pip3 config list
打开一个【cmd】运行即可
![]()
安装requests
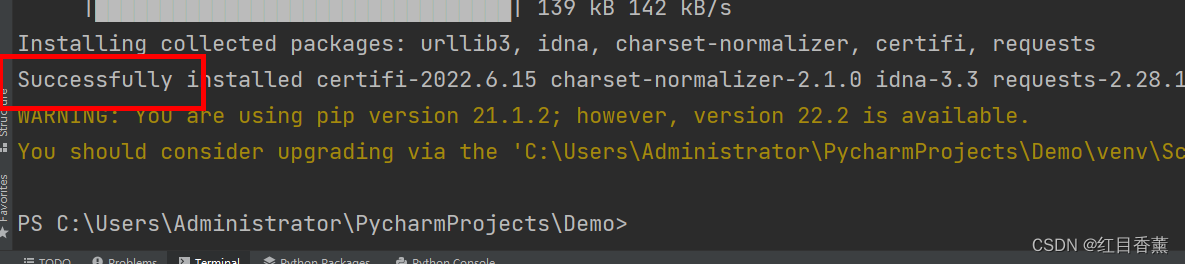
pip3 install requests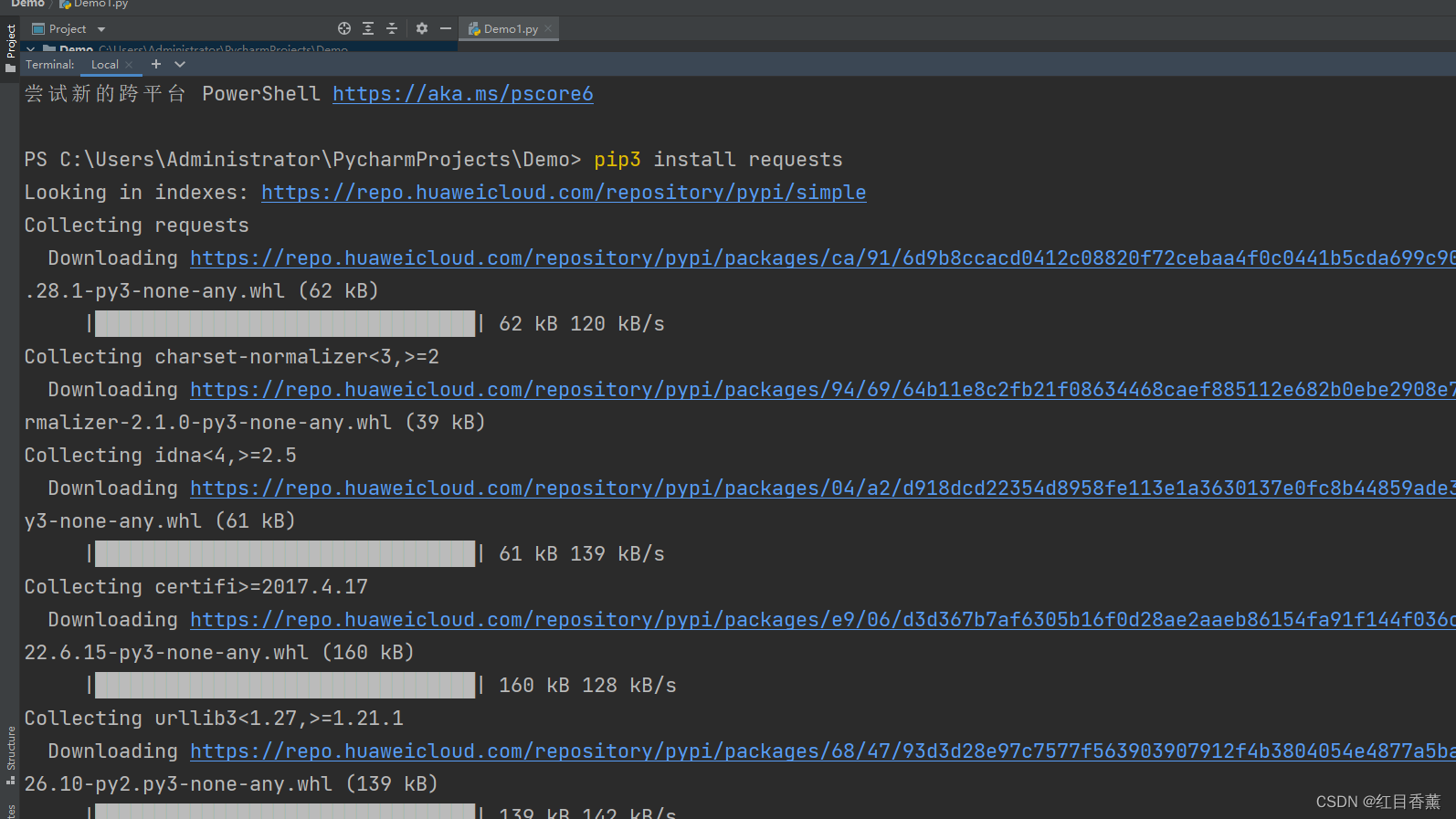
![]()
![]()
看到Successfully代表成功。
使用requests
创建python文件

![]()
写入测试编码:
import requests
# 获取请求的响应结果【response】
response = requests.get("http://www.baidu.com")
# 类型
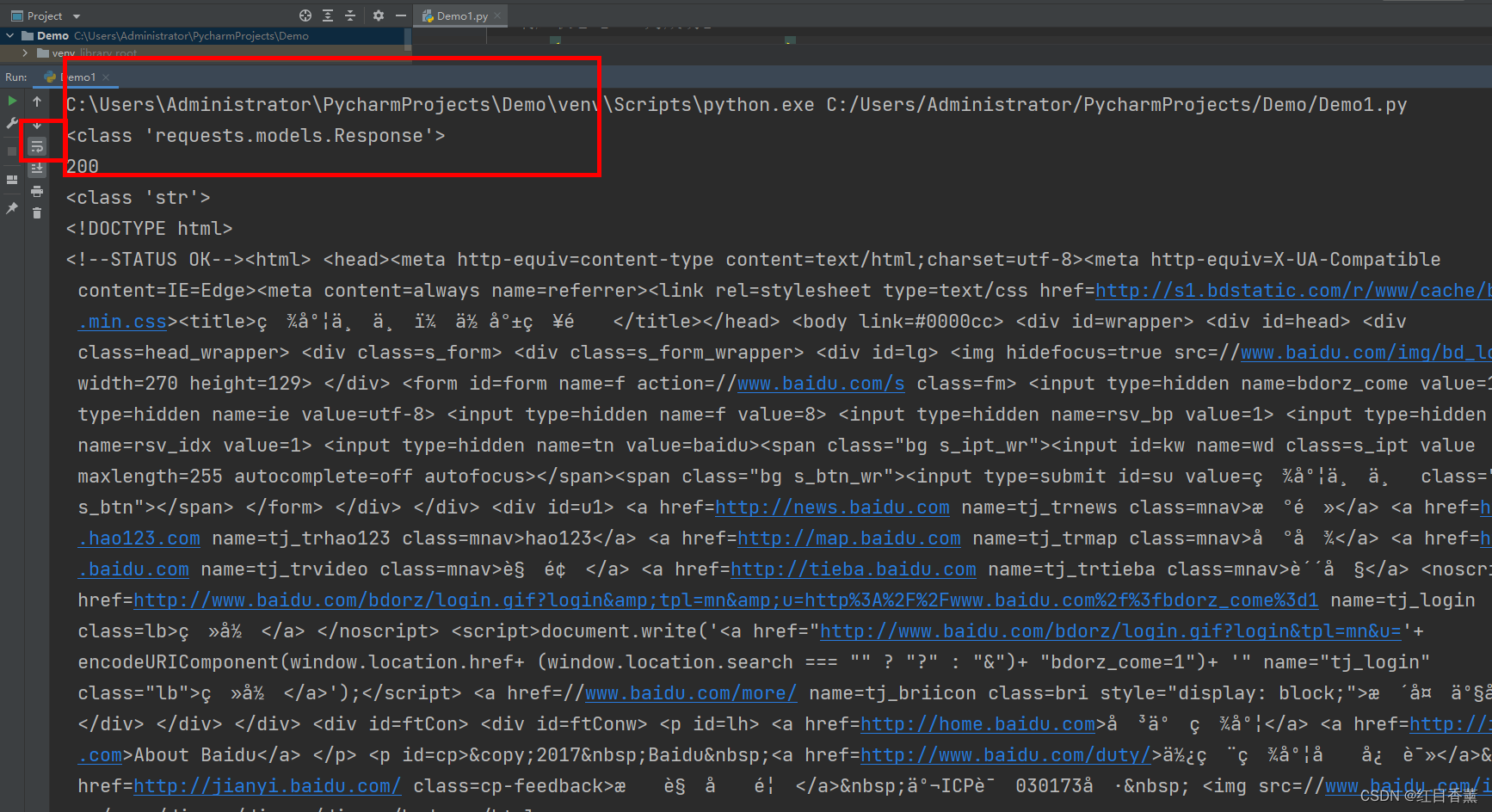
print(type(response))
# 响应状态【200为成功】
print(response.status_code)
# 响应文本类型-一般都是str字符串
print(type(response.text))
# 响应文本内容
print(response.text)
# <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
print(response.cookies)
# 响应内容
print(response.content)
# 修改响应的编码格式
print(response.content.decode("utf-8"))
鼠标右键运行
![]()
结果显示:
![]()
编码:
import requests
# 获取请求的响应结果【response】
response = requests.get("http://www.baidu.com")
# 修改响应的编码格式
print(response.content.decode("utf-8"))这里要注意,一般的编码都是【utf-8】但是有些网站是【GBK】的。
![]()
推荐使用:response.content.decode("编码格式")的方式获取相应的html页面
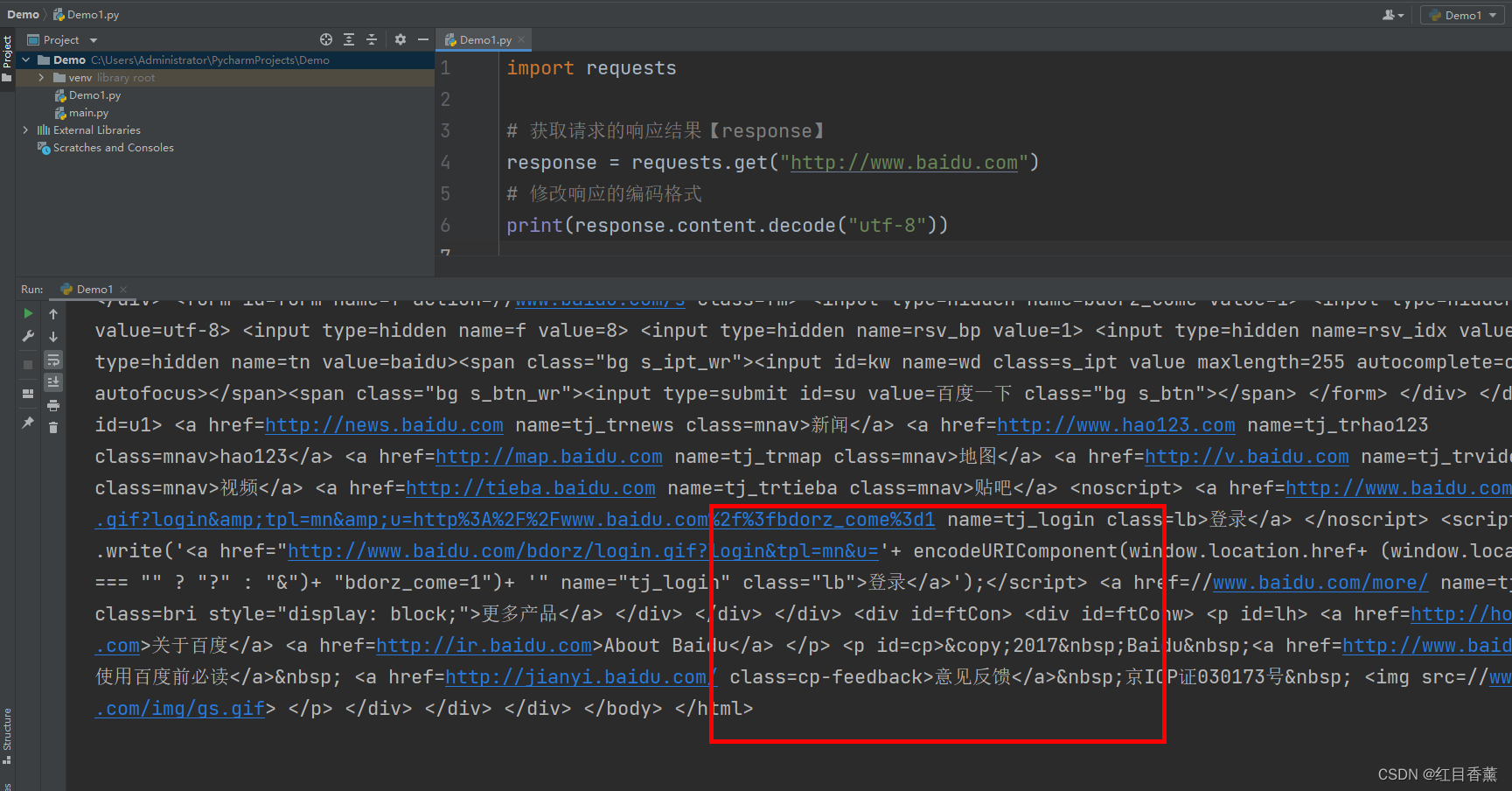
Get请求传参测试1
import requests
response = requests.get("http://httpbin.org/get?name=haomeng&age=21")
print(response.text)
可以看到所访问网站的【头部headers】【参数args】【origin源地址】
![]()
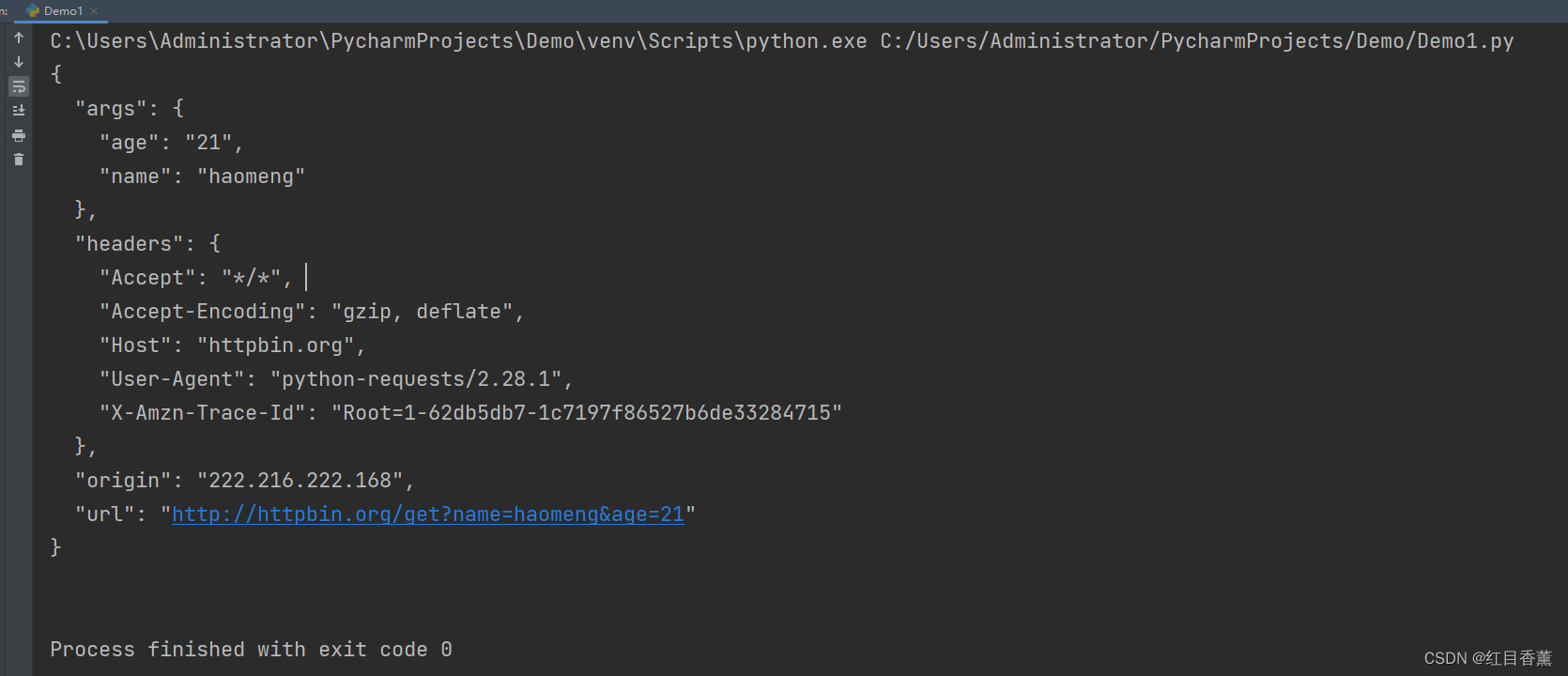
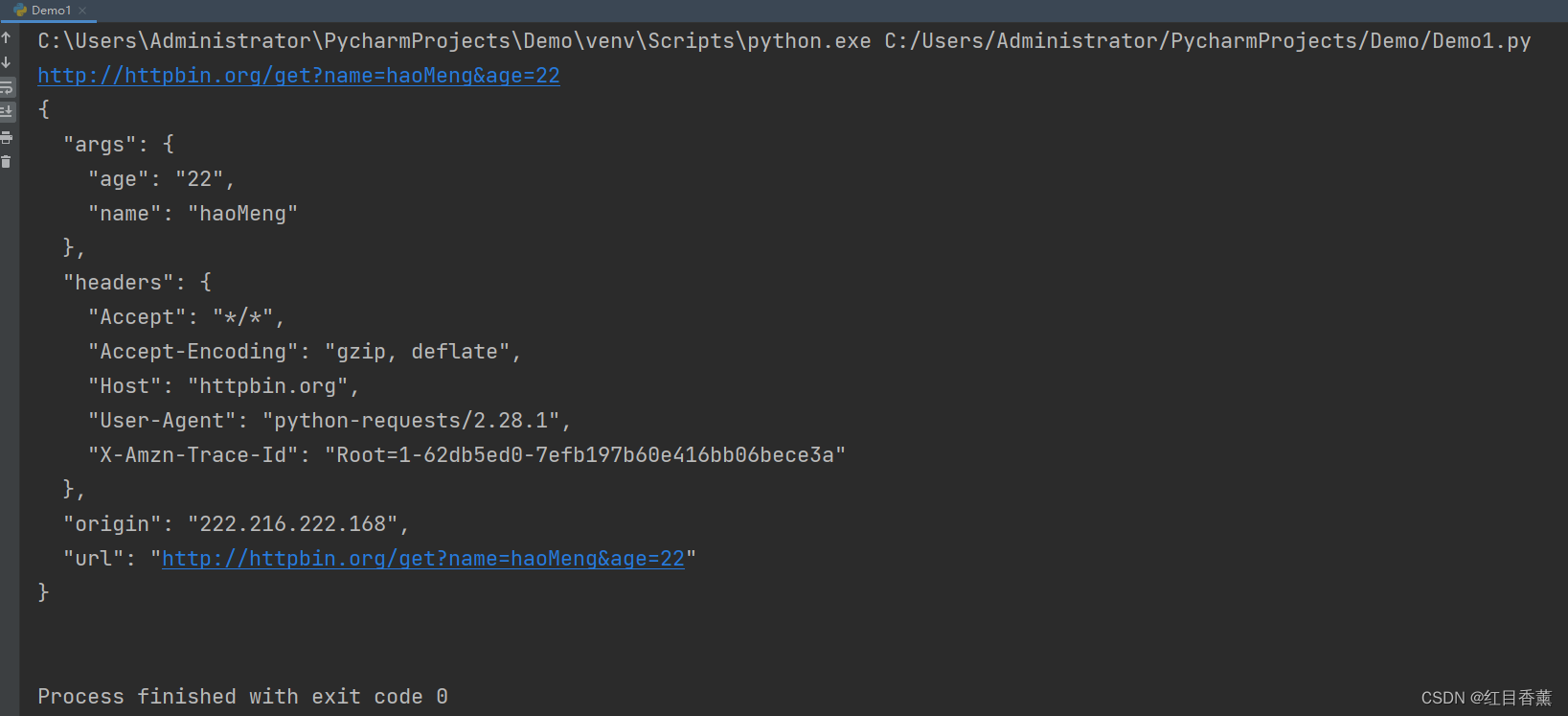
Get请求传参测试2
import requests
data = {
"name": "haoMeng",
"age": 22
}
response = requests.get("http://httpbin.org/get", params=data)
print(response.url)
print(response.text)
![]()
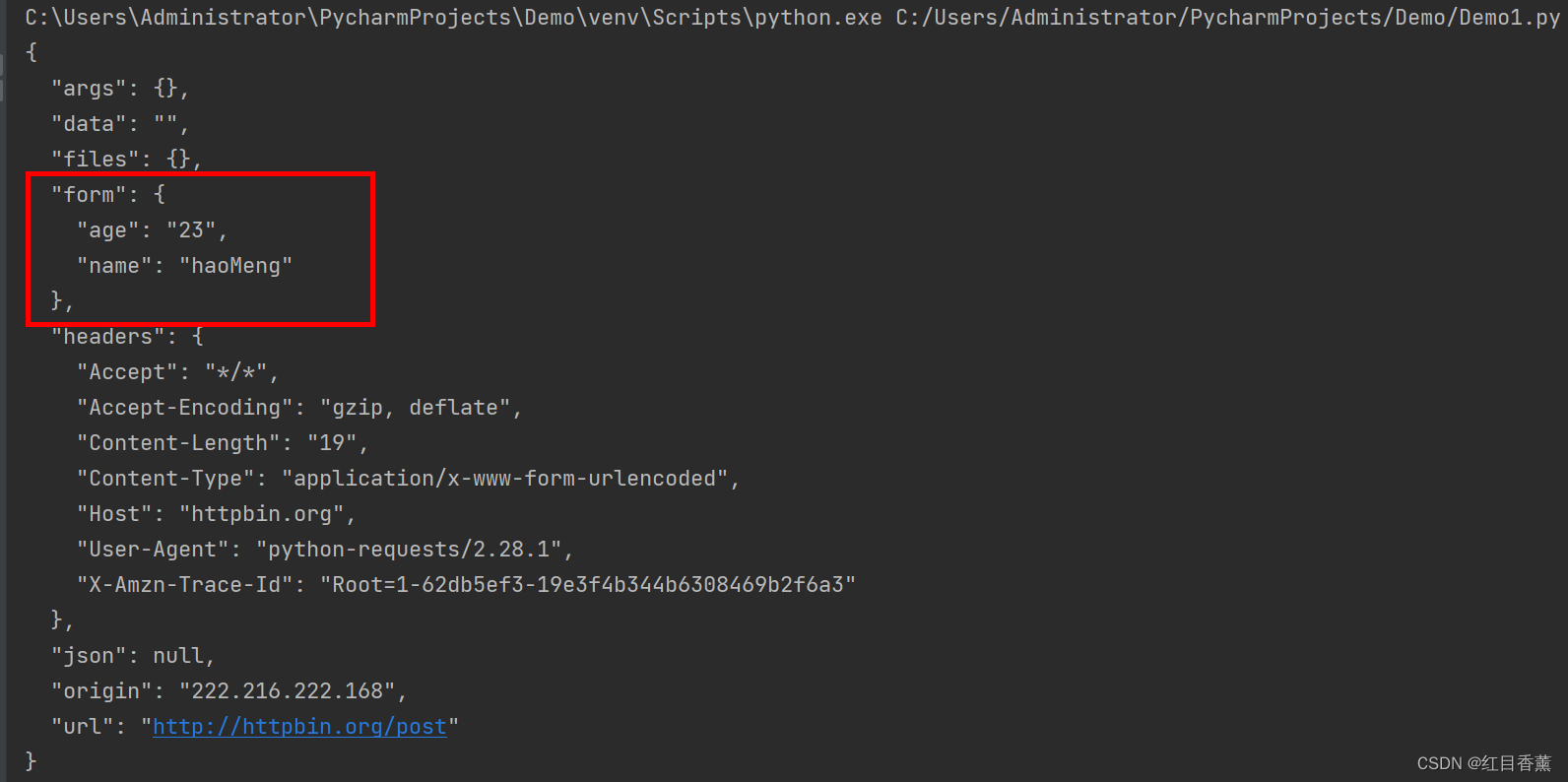
Post请求传参测试
import requests
data = {
"name": "haoMeng",
"age": 23
}
response = requests.post("http://httpbin.org/post", data=data)
print(response.text)
![]()
接口解析示例:
import requests
import json
# 获取请求的响应结果【response】
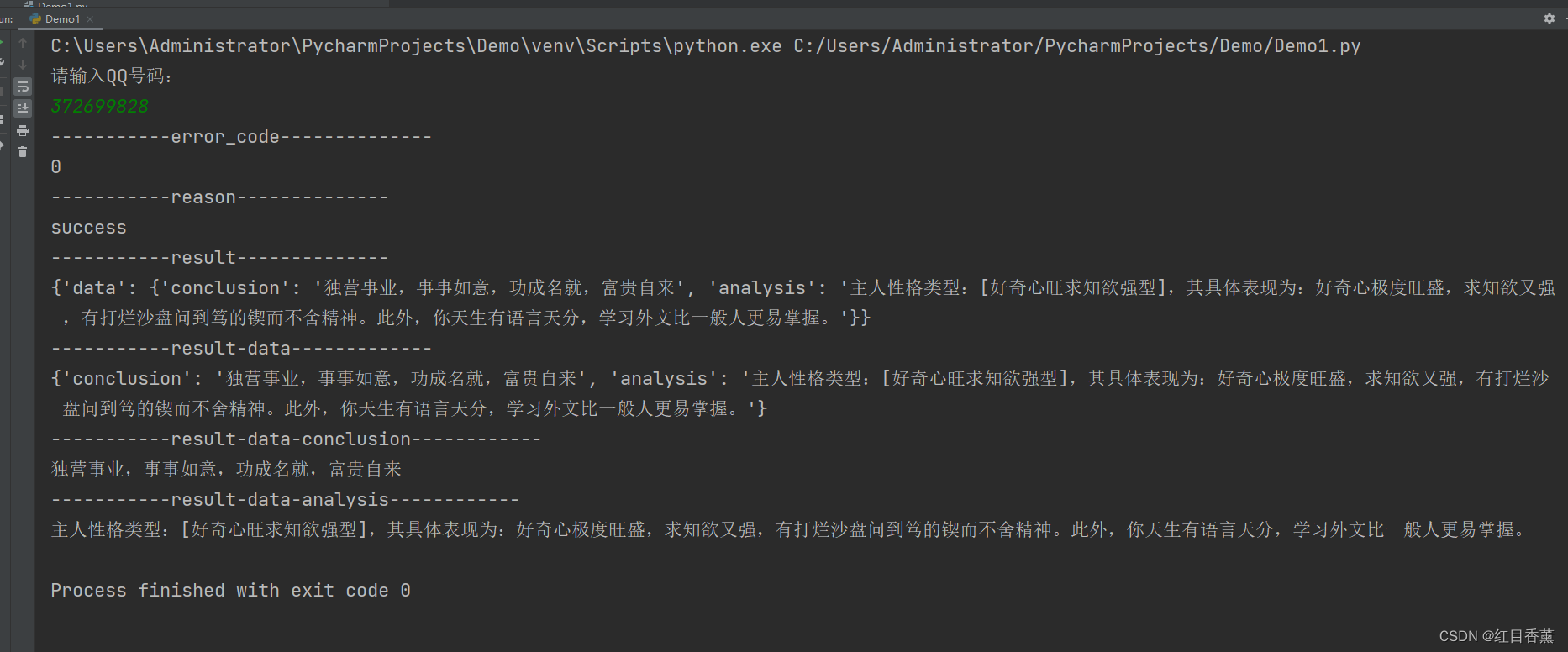
tel = int(input("请输入qiuqiu浩嘛:\n"))
url = "http://japi.juhe.cn/qqevaluate/qq?qq={0}&key=1977031b737429a8c8bc4378b36db390".format(tel)
response = requests.get(url)
info = response.content.decode("utf-8")
json = json.loads(info)
print("-----------error_code--------------")
print(json["error_code"])
print("-----------reason--------------")
print(json["reason"])
print("-----------result--------------")
print(json["result"])
print("-----------result-data-------------")
print(json["result"]["data"])
print("-----------result-data-conclusion------------")
print(json["result"]["data"]["conclusion"])
print("-----------result-data-analysis------------")
print(json["result"]["data"]["analysis"])
![]()
希望能对大家有所帮助。练习的时候注意,一定要先搞好环境再开始训练啊。
Json序列化与反序列化
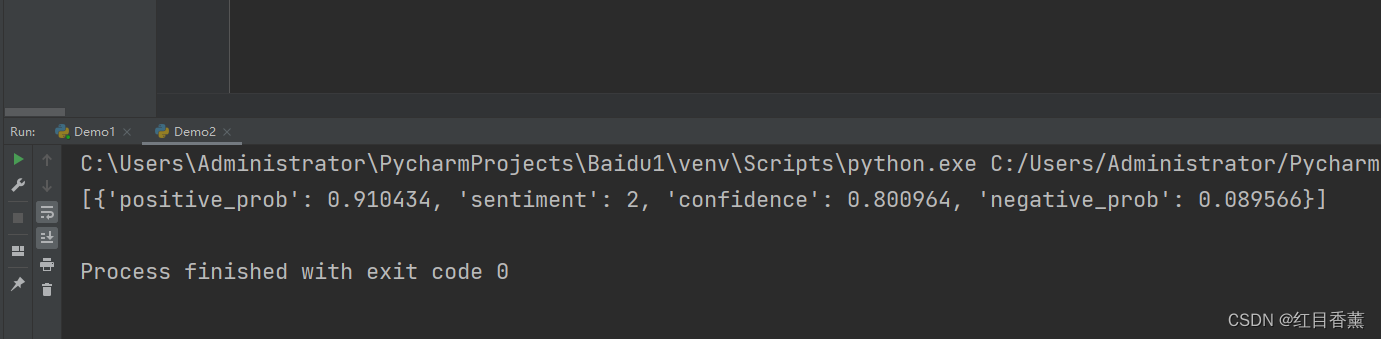
import json
jsonStr = {'msg': 'success', 'code': '0',
'data': [{'positive_prob': 0.910434, 'sentiment': 2, 'confidence': 0.800964, 'negative_prob': 0.089566}]}
json1 = json.dumps(jsonStr) # 序列化
json2 = json.loads(json1) # 反序列化
print(json2['data']) # 获取数据
![]()
正则表达式获取url
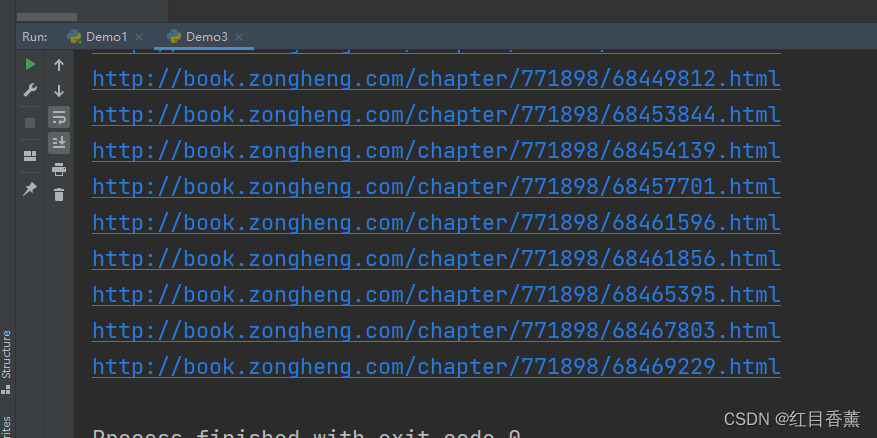
import re
import requests
# 正则表达式,获取所有某网站内所有网址
p = r"(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?"
result = requests.get("http://book.zongheng.com/showchapter/771898.html")
info = result.content.decode("utf-8")
arr = re.finditer(p, info)
for item in arr:
if "771898" in item[0]:
print(item[0])
![]()

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)