Flink原理初探和流批一体API(二)

【摘要】 Flink原理初探和流批一体API(二) 今日目标流处理概念(理解)程序结构之数据源Source(掌握)程序结构之数据转换Transformation(掌握)程序结构之数据落地Sink(掌握)Flink连接器Connectors(理解) 流处理概念 数据的时效性强调的是数据的处理时效网站的数据访问,被爬虫爬取 流处理和批处理流处理是无界的窗口操作来划分数据的边界进行计算批处理是有界的在Fl...
Flink原理初探和流批一体API(二)
今日目标
- 流处理概念(理解)
- 程序结构之数据源Source(掌握)
- 程序结构之数据转换Transformation(掌握)
- 程序结构之数据落地Sink(掌握)
- Flink连接器Connectors(理解)
流处理概念
数据的时效性
-
强调的是数据的处理时效
网站的数据访问,被爬虫爬取
流处理和批处理
-
流处理是无界的
- 窗口操作来划分数据的边界进行计算
-
批处理是有界的
-
在Flink1.12时支持流批一体 既支持流处理也支持批处理。


编程模型
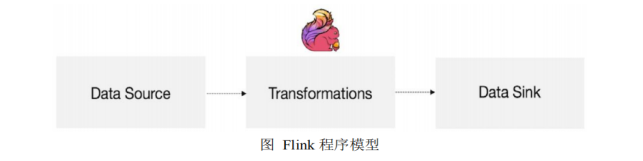
- source
- transformation
- sink
Source
基于File
- 需求env.readTextFile(本地/HDFS文件/文件夹);//压缩文件也可以
package cn.itcast.sz22.day02;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author itcast
* Date 2021/5/5 9:50
* env.readTextFile(本地/HDFS文件/文件夹);//压缩文件也可以
*/
public class FileSourceDemo {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//读取文件 hdfs://node1:8020/user/root/xxx.txt
//读取通过 gzip 压缩的 gz 文件
DataStreamSource<String> source1 = env.readTextFile("data/hello.txt");
DataStreamSource<String> source2 = env.readTextFile("D:\\_java_workspace\\sz22\\data\\hello.txt.gz");
//打印文本
source1.print();
source2.print("source2:");
//执行流环境
env.execute();
}
}
基于数据集合 fromElemet
-
需求
1.env.fromElements(可变参数);
2.env.fromColletion(各种集合);
3.env.generateSequence(开始,结束);
4.env.fromSequence(开始,结束);
-
案例
package cn.itcast.sz22.day02; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * Author itcast * Date 2021/5/5 9:20 * 1. 创建环境(流处理环境) * 2. 获取数据源 * 3. 打印数据 * 4. 执行 */ public class SourceDemo01 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //1.env.fromElements(可变参数); DataStreamSource<String> source1 = env.fromElements("hello world", "hello flink"); //2.env.fromColletion(各种集合); ArrayList list = new ArrayList(); list.add("hello hadoop"); list.add("hello flink"); DataStreamSource source2 = env.fromCollection(list); //3.env.generateSequence(开始,结束); DataStreamSource<Long> source3 = env.generateSequence(1, 10).setParallelism(1); //4.env.fromSequence(开始,结束); DataStreamSource<Long> source4 = env.fromSequence(10, 20); //打印输出 source1.print("source1"); source2.print("source2"); source3.print("source3"); source4.print("source4"); //执行环境 env.execute(); } }
custom
-
几种 SourceFunction
SourceFunction:非并行数据源(并行度只能=1)
RichSourceFunction:多功能非并行数据源(并行度只能=1)
ParallelSourceFunction:并行数据源(并行度能够>=1)
RichParallelSourceFunction:多功能并行数据源(并行度能够>=1)–后续学习的Kafka数据源使用的
-
需求:每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)
package cn.itcast.sz22.day02; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction; import org.apache.flink.streaming.api.functions.source.SourceFunction; import java.util.Random; import java.util.UUID; /** * Author itcast * Date 2021/5/5 10:15 * 每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳) * 要求: * - 随机生成订单ID(UUID) * - 随机生成用户ID(0-2) * - 随机生成订单金额(0-100) * - 时间戳为当前系统时间 */ public class CustomSource { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //自定义 source Random rn = new Random(); DataStreamSource<Order> source = env.addSource(new ParallelSourceFunction<Order>() { boolean flag = true; //创建一个 标记 @Override public void run(SourceContext<Order> ctx) throws Exception { while (flag) { //随机生成订单ID(UUID) String oid = UUID.randomUUID().toString(); //随机生成用户ID(0-2) int uid = rn.nextInt(3); //随机生成订单金额(0-100) int money = rn.nextInt(101); //时间戳为当前系统时间 long timestamp = System.currentTimeMillis(); //将数据封装成 Order 收集数据 ctx.collect(new Order(oid, uid, money, timestamp)); //每一秒休息一次 Thread.sleep(1000); } } @Override public void cancel() { flag = false; } }).setParallelism(1); //打印输出 source.print(); env.execute(); } @Data @AllArgsConstructor @NoArgsConstructor public static class Order{ private String uuid; private int uid; private int money; private Long timestamp; } } -
从mysql 中自定义数据源读取数据
- 初始化
CREATE DATABASE if not exists bigdata; USE bigdata; CREATE TABLE if not exists `t_student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8; INSERT INTO `t_student` VALUES ('1', 'jack', '18'); INSERT INTO `t_student` VALUES ('2', '张三', '19'); INSERT INTO `t_student` VALUES ('3', 'rose', '20'); INSERT INTO `t_student` VALUES ('4', 'tom', '19'); INSERT INTO `t_student` VALUES ('5', '李四', '18'); INSERT INTO `t_student` VALUES ('6', '王五', '20');
package cn.itcast.sz22.day02;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* Author itcast
* Date 2021/5/5 10:32
* Desc TODO
*/
public class MySQLSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.env 设置并行度为 1
env.setParallelism(1);
//2.source,创建连接MySQL数据源 数据源,每2秒钟生成一条数据
DataStreamSource<Student> source = env.addSource(new RichSourceFunction<Student>() {
Connection conn;
PreparedStatement ps;
boolean flag = true;
@Override
public void open(Configuration parameters) throws Exception {
//连接数据源
conn = DriverManager.getConnection("jdbc:mysql://192.168.88.100:3306/bigdata?useSSL=false"
, "root", "123456");
//编写读取数据表的sql
String sql = "select `id`,`name`,age from t_student";
//准备 preparestatement SQL
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<Student> ctx) throws Exception {
while (flag) {
ResultSet rs = ps.executeQuery();
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
Student student = new Student(id, name, age);
ctx.collect(student);
}
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
ps.close();
conn.close();
}
});
//3.打印数据源
//4.执行
//创建静态内部类 Student ,字段为 id name age
//创建静态内部类 MySQLSource 继承RichParallelSourceFunction<Student>
// 实现 open 方法
// 获取数据库连接 mysql5.7版本
//// jdbc:mysql://192.168.88.100:3306/bigdata?useSSL=false
// 实现 run 方法
source.print();
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Student {
private int id;
private String name;
private int age;
}
}
socket 套接字
-
安装 netcat yum install nc -y
-
需求:通过 socket 接收数据并做单词wordcount 统计
package cn.itcast.sz22.day02; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; /** * Author itcast * Date 2021/5/5 9:59 * Desc TODO */ public class SocketSourceDemo { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.source socketSource DataStreamSource<String> source = env.socketTextStream("192.168.88.100", 9999); //3.处理数据-transformation SingleOutputStreamOperator<Tuple2<String, Integer>> result = source .flatMap((String value, Collector<String> out) -> Arrays .stream(value.split(" ")).forEach(out::collect)) .returns(Types.STRING) .map(value -> Tuple2.of(value, 1)) .returns(Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t -> t.f0) .sum(1); //3.1每一行数据按照空格切分成一个个的单词组成一个集合 //3.2对集合中的每个单词记为1 //3.3对数据按照单词(key)进行分组 //3.4对各个组内的数据按照数量(value)进行聚合就是求sum //4.输出结果-sink result.print(); //5.触发执行-execute env.execute(); } }
Transformation
转换操作的数据操作类型
- 对于单条数据的处理 map filter
- 对于多条数据,window窗口内的数据处理 reduce
- 合流 union join 将多个流合并到一起
- 分流 将一个数据流分成多个数据流 spit或 outputTag
案例
- 对流数据中的单词进行统计,排除敏感词heihei
package cn.itcast.sz22.day02;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Author itcast
* Date 2021/5/5 9:59
* 1.filter过滤 将单词中 heihei 单词过滤掉
* 2.reduce聚合
*/
public class SocketSourceFilterDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source socketSource
DataStreamSource<String> source = env.socketTextStream("192.168.88.100", 9998);
//3.处理数据-transformation
SingleOutputStreamOperator<Tuple2<String, Integer>> result = source
.flatMap((String value, Collector<String> out) -> Arrays
.stream(value.split(" ")).forEach(out::collect))
.returns(Types.STRING)
//过滤掉 包含 heihei 单词的所有信息 boolean filter(T value)
.filter(word-> !word.equals("heihei"))
.map(value -> Tuple2.of(value, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(t -> t.f0)
//.sum(1);
//T reduce(T value1, T value2)
// hadoop,1 hadoop,1 => hadoop,1+1
.reduce((Tuple2<String,Integer> a,Tuple2<String,Integer> b)->Tuple2.of(a.f0,a.f1+b.f1));
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
//3.2对集合中的每个单词记为1
//3.3对数据按照单词(key)进行分组
//3.4对各个组内的数据按照数量(value)进行聚合就是求sum
//4.输出结果-sink
result.print();
//5.触发执行-execute
env.execute();
}
}
合并-拆分
- connect 不同的数据类型进行流合并
- union 相同的数据类型进行流合并
案例
需求: 将两个String类型的流进行union
将一个String类型和一个Long类型的流进行connect
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
/**
* Author itcast
* Date 2021/5/5 11:24
* 将两个String类型的流进行union
* 将一个String类型和一个Long类型的流进行connect
*
*/
public class UnionAndConnectDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//2.Source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");
DataStream<String> ds2 = env.fromElements("hadoop", "spark", "flink");
DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);
//3. transformation
//3.1 union
DataStream<String> union = ds1.union(ds2);
union.print("union:");
//3.2 connect
ConnectedStreams<String, Long> connect = ds1.connect(ds3);
SingleOutputStreamOperator<String> source2 = connect.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String value) throws Exception {
return "string->string:" + value;
}
@Override
public String map2(Long value) throws Exception {
return "Long->Long:" + value;
}
});
//打印输出
source2.print("connect:");
env.execute();
}
}
拆分
- 将数据流拆分成多个数据流
案例
- 需求:对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
package cn.itcast.sz22.day02;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* Author itcast
* Date 2021/5/5 11:35
* 对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
*/
public class SplitStreamDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//2.Source 比如 1-20之间的数字
DataStreamSource<Long> source = env.fromSequence(1, 20);
//定义两个输出tag 一个奇数 一个偶数,指定类型为Long
OutputTag<Long> odd = new OutputTag<>("odd", TypeInformation.of(Long.class));
OutputTag<Long> even = new OutputTag<>("even", TypeInformation.of(Long.class));
//对source的数据进行process处理区分奇偶数
SingleOutputStreamOperator<Long> processDS = source.process(new ProcessFunction<Long, Long>() {
@Override
public void processElement(Long value, Context ctx, Collector<Long> out) throws Exception {
if (value % 2 == 0) {
ctx.output(even, value);
} else {
ctx.output(odd, value);
}
}
});
//3.获取两个侧输出流
DataStream<Long> evenDS = processDS.getSideOutput(even);
DataStream<Long> oddDS = processDS.getSideOutput(odd);
//4.sink打印输出
evenDS.printToErr("even");
oddDS.print("odd");
//5.execute
env.execute();
}
}
repartition 重分区
-
需求: 通过重分区保证每个 cpu 处理数据均衡
package cn.itcast.sz22.day02; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * Author itcast * Date 2021/5/5 14:46 * Desc TODO */ public class TransformationRebalance { public static void main(String[] args) throws Exception { //1.env 设置并行度为3 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //env.enableCheckpointing(1000); // 并行度为3 taskslot用3个 env.setParallelism(3); //2.source fromSequence 0-100 DataStreamSource<Long> source = env.fromSequence(0, 100); //3.Transformation //下面的操作相当于将数据随机分配一下,有可能出现数据倾斜,过滤出来大于10 //boolean filter(T value) throws Exception; //11 ~ 100 //默认会将 90 条数据分不到3个分区了 DataStream<Long> filterDS = source.filter(w -> w > 10); //3.1 接下来使用map操作,将Long数据转为(分区编号/子任务编号, 数据) SingleOutputStreamOperator<Tuple2<Integer, Integer>> mapDS = filterDS.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> map(Long value) throws Exception { // getRuntimeContext().getIndexOfThisSubtask() 当前这个子任务执行的CPU的索引 0 , 1 ,2 // (CPU的索引,计数(1)) (0,1) (1,1) (2,1) (1,1) (2,1) (0,1) return Tuple2.of(getRuntimeContext().getIndexOfThisSubtask(), 1); } }); SingleOutputStreamOperator<Tuple2<Integer, Integer>> result = mapDS.keyBy(t -> t.f0).sum(1); //通过getRuntimeContext获取到任务Index //返回Tuple2(任务Index,1) //按照子任务id/分区编号分组,统计每个子任务/分区中有几个元素 //3.2 重新执行以上操作在filter之后先 rebalance 再map SingleOutputStreamOperator<Tuple2<Integer, Integer>> mapDS1 = filterDS //当前处理重分布 .rebalance() .map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> map(Long value) throws Exception { return Tuple2.of(getRuntimeContext().getIndexOfThisSubtask(), 1); } }); SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = mapDS1.keyBy(t -> t.f0).sum(1); //result.print("重分布之前"); result1.print("重分布之后"); //4.sink //result1.print();//有可能出现数据倾斜 //result2.print(); //5.execute env.execute(); } } -
案例-对流中的元素使用各种分区,并输出
/** * Author itcast * Desc */ public class TransformationDemo05 { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); //2.Source DataStream<String> linesDS = env.readTextFile("data/input/words.txt"); SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = value.split(" "); for (String word : words) { out.collect(Tuple2.of(word, 1)); } } }); //3.Transformation DataStream<Tuple2<String, Integer>> result1 = tupleDS.global(); DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast(); DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward(); DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle(); DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance(); DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale(); DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new Partitioner<String>() { @Override public int partition(String key, int numPartitions) { //return key.equals("hello") ? 0 : 1; int keys = Integer.parseInt(key); if(Integer.parseInt(key)>0 && Integer.parseInt(key)<100){ //10000 return 0; }else if(keys>101 && keys <10000){ //11000 return 1; }else{ //8000 return 2; } } }, t -> t.f0); //4.sink //result1.print(); //result2.print(); //result3.print(); //result4.print(); //result5.print(); //result6.print(); result7.print(); //5.execute env.execute(); } }
Sink
- 打印到控制台
- 输出到文件

-
案例
package cn.itcast.sz22.day02; import org.apache.flink.core.fs.FileSystem; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.SinkFunction; /** * Author itcast * Desc * 1.ds.print 直接输出到控制台 * 2.ds.printToErr() 直接输出到控制台,用红色 * 3.ds.collect 将分布式数据收集为本地集合 * 4.ds.setParallelism(1).writeAsText("本地/HDFS的path",WriteMode.OVERWRITE) */ public class SinkDemo01 { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.source //DataStream<String> ds = env.fromElements("hadoop", "flink"); DataStream<String> ds = env.readTextFile("data/input/words.txt"); //3.transformation //4.sink //4.1 控制台输出 ds.print(); ds.printToErr(); //4.2 输出到文件 ds.writeAsText("/data/output/words.txt", FileSystem.WriteMode.OVERWRITE) .setParallelism(1); // /*ds.addSink(new SinkFunction<String>() { @Override public void invoke(String value, Context context) throws Exception { } })*/ //注意: //Parallelism=1为文件 //Parallelism>1为文件夹 //5.execute env.execute(); } } -
案例 - 将Flink集合中的数据通过自定义Sink保存到MySQL
package cn.itcast.sz22.day02;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
/**
* Author itcast
* Date 2021/5/5 16:00
* 将 Student 集合数据sink到MySQL数据库中
*/
public class SinkMySQLDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source 定义 Student 对象
DataStream<Student> studentDS = env.fromElements(new Student(null, "tonyma", 18));
studentDS.addSink(new RichSinkFunction<Student>() {
Connection conn;
PreparedStatement ps;
boolean flag = true;
@Override
public void open(Configuration parameters) throws Exception {
//初始化操作,添加连接MySQL
conn = DriverManager.getConnection("jdbc:mysql://192.168.88.100:3306/bigdata?useSSL=false"
, "root", "123456");
String sql="INSERT INTO t_student(`id`,`name`,`age`) values(null,?,?)";
ps = conn.prepareStatement(sql);
}
@Override
public void invoke(Student value, Context context) throws Exception {
ps.setString(1,value.getName());
ps.setInt(2,value.getAge());
ps.executeUpdate();
}
@Override
public void close() throws Exception {
ps.close();
conn.close();
}
});
//3.Transformation 暂时不需要
//4.Sink 实现自定义 MySQL sink
//5.execute
//创建 Student 类,包含3个字段 id name age
//创建 MySQLSink 类继承 RichSinkFunction<Student>
//实现 open invoke close 方法
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Student {
private String id;
private String name;
private int age;
}
}
Connectors
JDBC
-
官方提供的JDBC,能提供 仅一次 语义的连接数据库的连接
-
需求- 将数据存到 MySQL 中
package cn.itcast.sz22.day02; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.connector.jdbc.JdbcConnectionOptions; import org.apache.flink.connector.jdbc.JdbcExecutionOptions; import org.apache.flink.connector.jdbc.JdbcSink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * Author itcast * Date 2021/5/5 16:16 * Desc TODO */ public class SinkJDBCMySQLDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<Student> studentDS = env.fromElements(new Student(null, "dehua", 22)); studentDS.addSink(JdbcSink.sink( "insert into t_student(`id`,`name`,`age`) values (null,?,?)", (ps, s) -> { ps.setString(1,s.getName()); ps.setInt(2,s.getAge()); }, JdbcExecutionOptions.builder().build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://192.168.88.100:3306/bigdata?useSSL=false") .withUsername("root") .withPassword("123456") .withDriverName("com.mysql.jdbc.Driver") .build()) ); env.execute(); } @Data @AllArgsConstructor @NoArgsConstructor public static class Student { private String id; private String name; private int age; } }

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)