Flink快速入门(概述,安装部署)(一)

引言

大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
下面为大家带来阿里巴巴极度热推的Flink,实时数仓是未来的方向,学好Flink,月薪过万不是梦!!
相关教程直通车:
2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二)
2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二.五)
2021年最新最全Flink系列教程__Flink高级API(三)
day01_Flink概述、安装部署和入门案例
今日目标
- Flink概述(了解)
- Flink安装部署(会部署)
- Flink入门案例(会操作)
Flink概述
什么是批处理和流处理
- 批处理,基于周期的数据一批批处理(数据采集、数据ETL、数据统计分析挖掘、报表展示)
- 流处理,实时的来一条处理一条。
为什么需要流计算
- 流处理应用场景
- 实时监控
- 实时大屏、实时分析
- 实时数据仓库
Flink的发展史
- 2009年柏林工业大学一个研究项目
- 2014年被贡献给 apache 成为顶级项目,Flink 计算的主流方向是流式处理
- 2019年flink 商业公司被阿里收购,Flink 迎来了快速的发展
Flink的官方介绍
- Flink 是 Java 开发的,通信机制使用 akka ,数据的交换是 netty
- Flink 推荐使用 Java 、 scala 、 python
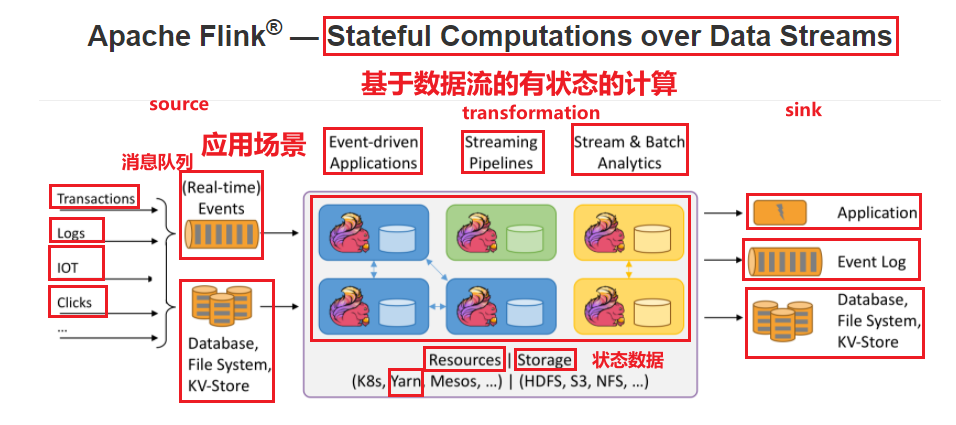
Flink组件栈
-
部署层
local 单机;
集群部署(standalone 、 yarn 、mesos、k8s);
云部署 (阿里云、腾讯云、亚马逊云等)
-
运行层 runtime
StreamingGraph 流图
jobGraph
ExecuteGraph
-
API
DataSet api (软弃用) ,高版本中 全部弃用
DataStream API
-
类库
FlinkML Gelly(图计算)
Flink 中批处理是流处理的一种特例。
Flink基石
- 检查点 checkpoint 轻量级
- 状态 state keyedstate operatorstate
- 时间 time EventTime(业务时间) ingestion time(摄取时间) processing time(处理时间)
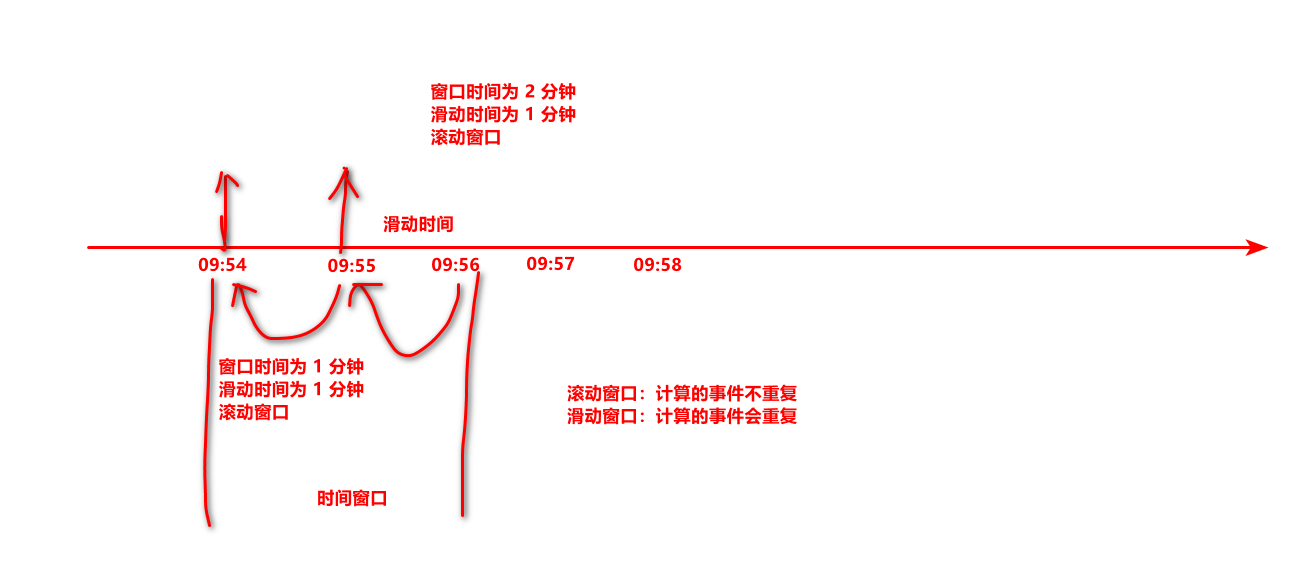
- 窗口 windows 滚动时间、滑动时间、会话窗口、计数窗口
Flink的应用场景
- 常用的应用
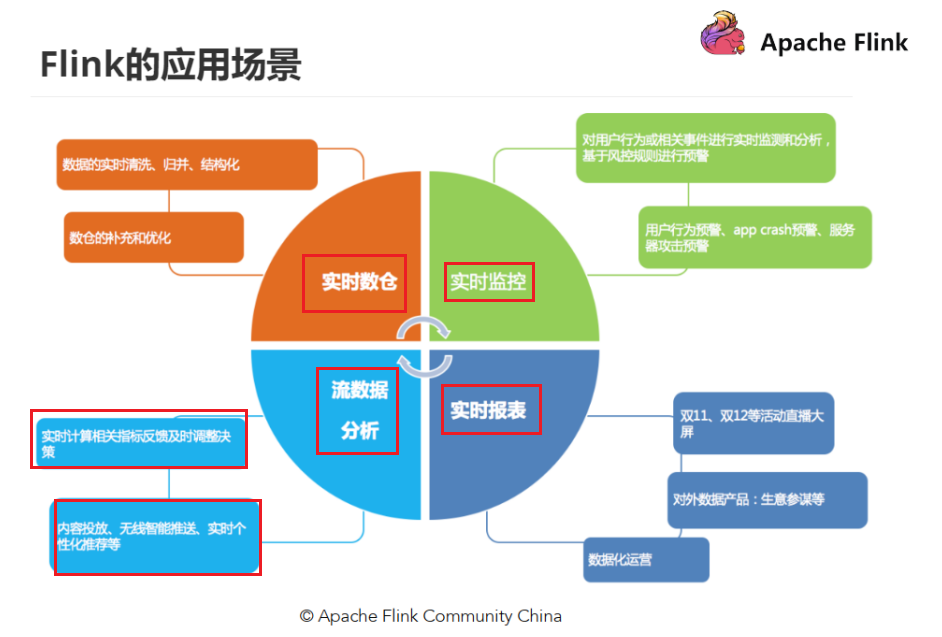
- 应用三个场景
- stream pipeline 流管线
- 批/流分析
- 基于事件驱动
Flink的安装部署
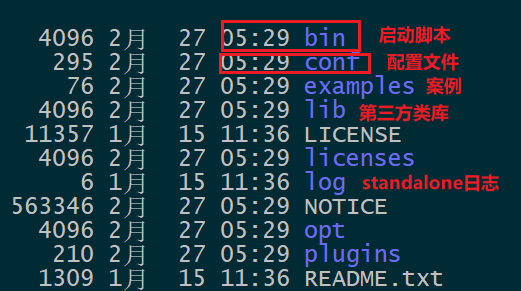
Local本地安装
-

-
-
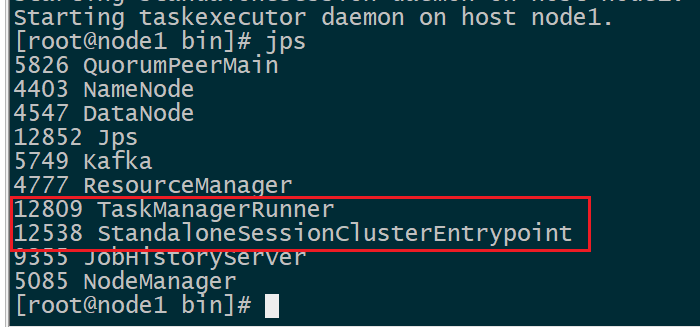
启动 flink
[root@node1 bin]$ start-cluster.sh
-
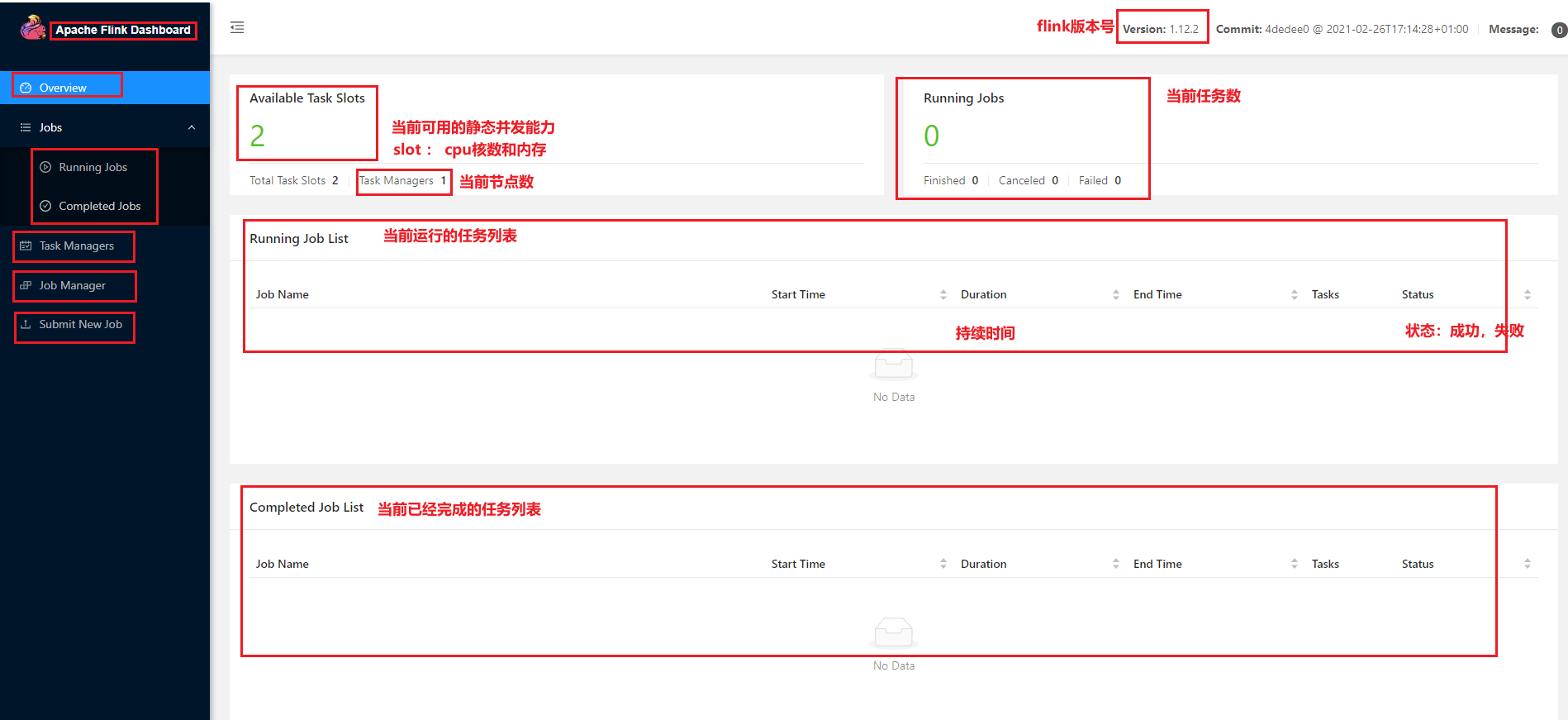
Flink web UI页面
node1:8081 -
执行 wordcount 脚本
[root@node1 flink]$ bin/flink run /opt/server/flink/examples/batch/WordCount.jar --input /root/words.txt

Standalone独立集群安装
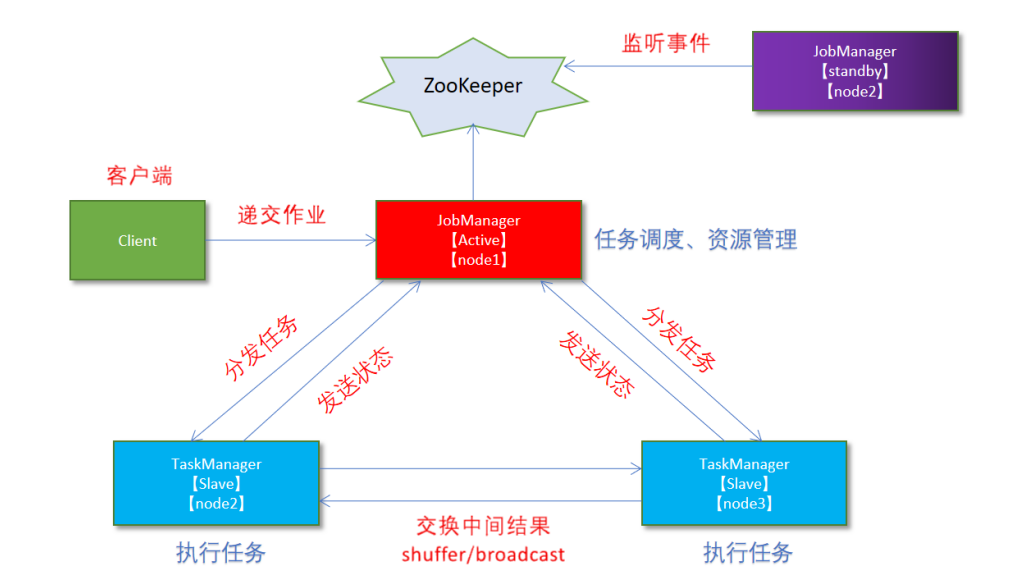
Standalone-HA高可用集群模式
-
zookeeper 选举
-
HDFS
-
-
配置
- node1 上配置 jobmanager.rpc node2上配置 jobmanager.rpc
- zookeeper 的地址
- checkpoint 的hdfs的路径
- zookeeper 恢复的数据在hdfs上的路径
- workers 每一行一个hostname
-
启动
-
启动 hdfs
hadoop-daemon start namenode hadoop-daemon start datanode hadoop-daemon start secondarynamenode -
zookeeper ,每一台都启动,集群模式
/export/server/zookeeper/bin/zkServer.sh start -
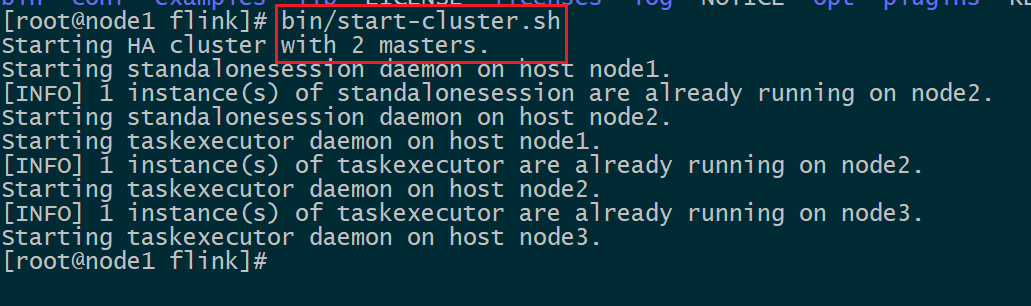
Flink启动
start-cluster.sh
-
Flink on Yarn模式
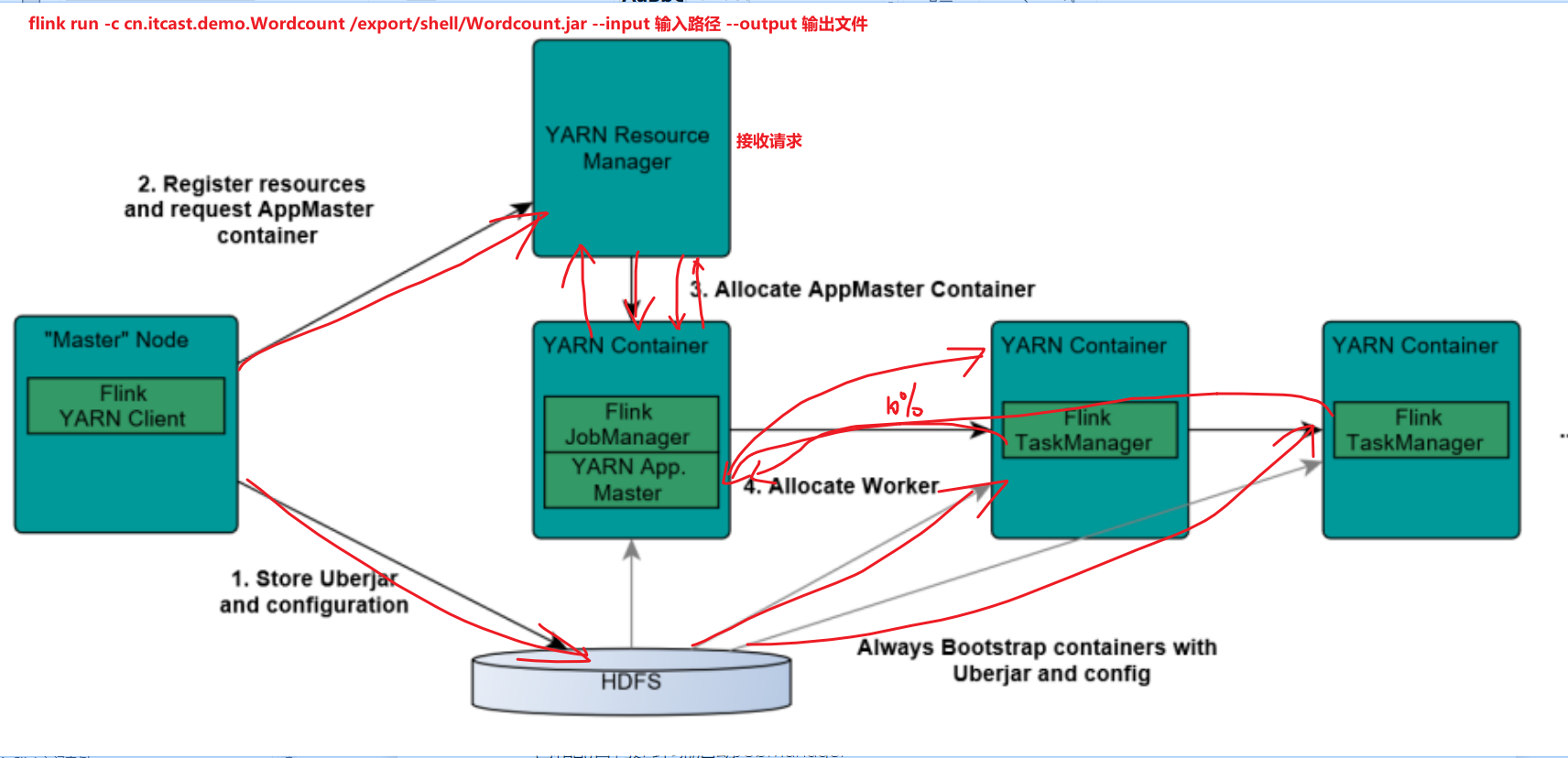
-
yarn 的两种提交方式
-
yarn-session
对于大量的小文件集合处理数据使用 yarn-session
-
per-job-session
对于大的数据量 per-job
-
-
yarn-session 启动并执行任务
-
启动 yarn-session
/export/server/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d -
执行任务在 yarn-session 中
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar
-
-
kill 掉 yarn-session
yarn application -kill application_1620078252622_0006 -
per-job 启动并执行任务 [ -m yarn-cluster ]
/export/server/flink/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 /export/server/flink/examples/batch/WordCount.jar
千亿数据仓库实时项目
- 实时通过大屏或者看板展示订单相关信息
- 技术架构
- 数据源 MySQL、日志数据
- 日志采集工具Flume、CDC工具Canal(binlog日志变化)
- 消息队列 Kafka,数据仓库分层,ODS、DWD、DWS层,时间不受限
- 流式计算引擎 Flink
- 内存(缓存)数据库Redis ,保存维度数据
- 明细数据落到Hbase
- 建索引和SQL查询Phoenix
- 经过ETL或业务分析统计写回Kafka
- 时序数据库Druid加载Kafka中数据进行业务的统计
- 报表展示Superset或者echarts图表工具
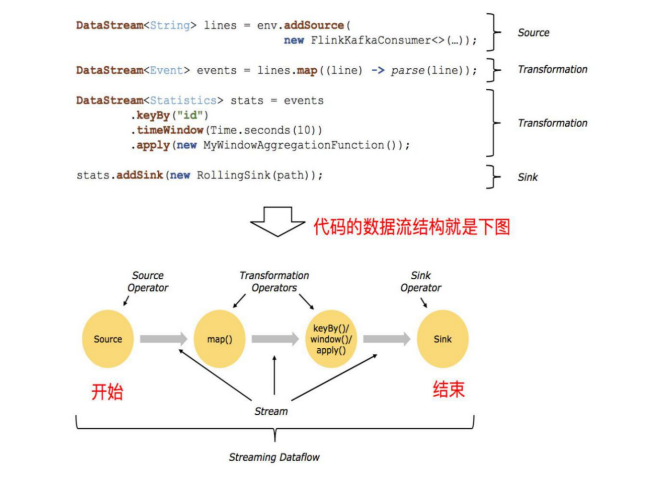
Flink入门案例
Flink API
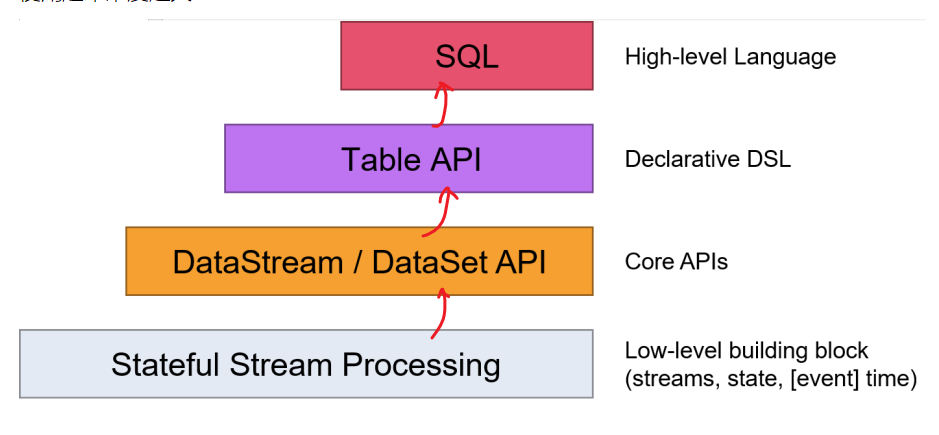
编程模型

- source
- transformation
- sink
批处理案例
package cn.itcast.sz22.day01;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* Author itcast
* Date 2021/5/4 15:25
* 通过 flink 批处理实现 wordcount
* 开发步骤:
* 1. 获取环境变量
* 2. 读取数据源
* 3. 转换操作
* 4. 将数据落地,打印到控制台
* 5. 执行(流环境下)
*/
public class Wordcount {
public static void main(String[] args) throws Exception {
//获取环境变量
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取数据
//1. 文件中读取
//2. 获取本地的数据,开发测试用
DataSource<String> source = env
.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
//3. 进行转换操作
DataSet<String> flatMapDS = source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
});
//3.2 转换成元素 map
MapOperator<String, Tuple2<String, Integer>> mapDS = flatMapDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});
//3.3统计
AggregateOperator<Tuple2<String, Integer>> result = mapDS.groupBy(0).sum(1);
//4.打印输出
result.print();
}
}
流处理案例
package cn.itcast.sz22.day01;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Author itcast
* Date 2021/5/4 15:55
* 流式计算 wordcount 统计
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute
*/
public class Wordcount2 {
public static void main(String[] args) throws Exception {
//编码步骤
//1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.setParallelism(1);
//2.准备数据-source
DataStream<String> linesDS = env
.fromElements("itcast hadoop spark","itcast hadoop spark","itcast hadoop","itcast");
//3.处理数据-transformation
SingleOutputStreamOperator<String> flatMap = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> mapDS = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> result = mapDS.keyBy(t -> t.f0)
.sum(1);
//4.输出结果-sink
result.print();
//5.触发执行-execute
env.execute();
}
}
流处理-Lambda版本
package cn.itcast.sz22.day01;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Author itcast
* Date 2021/5/4 16:05
* 通过 java 的 lambda 表达式实现 wordcount
*/
public class Wordcount3 {
public static void main(String[] args) throws Exception {
//1. 获取环境变量
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2. 读取数据源
DataStreamSource<String> source = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");
//3. 转换操作
// void flatMap(T value, Collector<O> out)
DataStream<String> faltMapDS = source.flatMap((String value, Collector<String> out) ->
Arrays.stream(value.split(" "))
.forEach(out::collect))
.returns(Types.STRING);
//O map(T value)
SingleOutputStreamOperator<Tuple2<String, Integer>> mapDS = faltMapDS
.map((word) -> Tuple2.of(word, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
SingleOutputStreamOperator<Tuple2<String, Integer>> result = mapDS.keyBy(t -> t.f0).sum(1);
//4. 将数据落地,打印到控制台
result.print();
//5. 执行(流环境下)
env.execute();
}
}
Flink原理初探
-
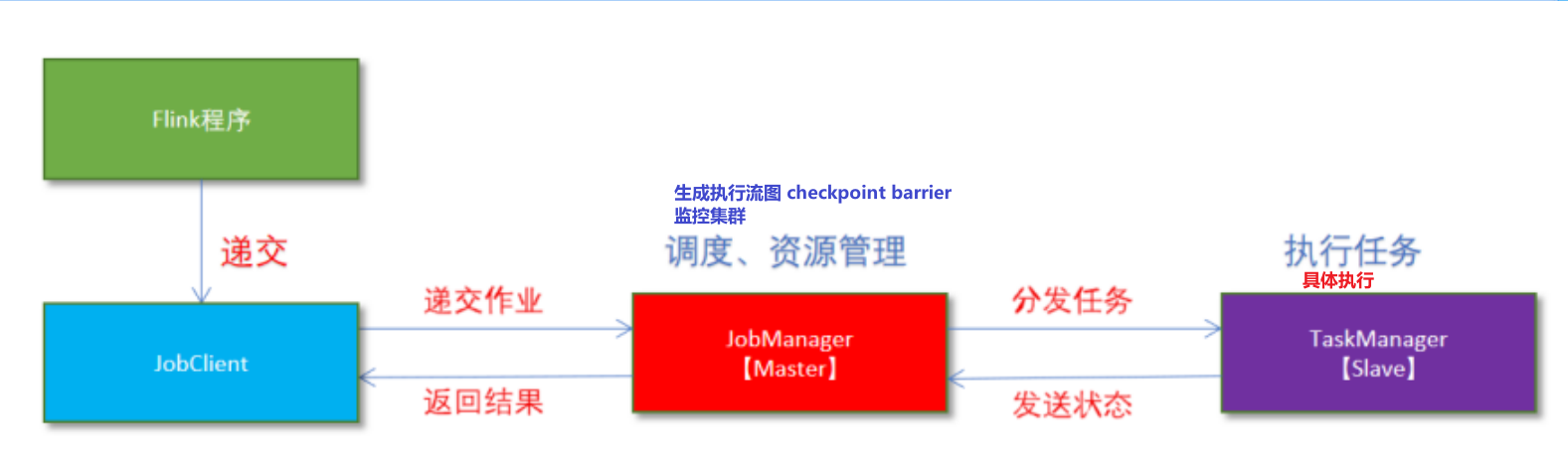
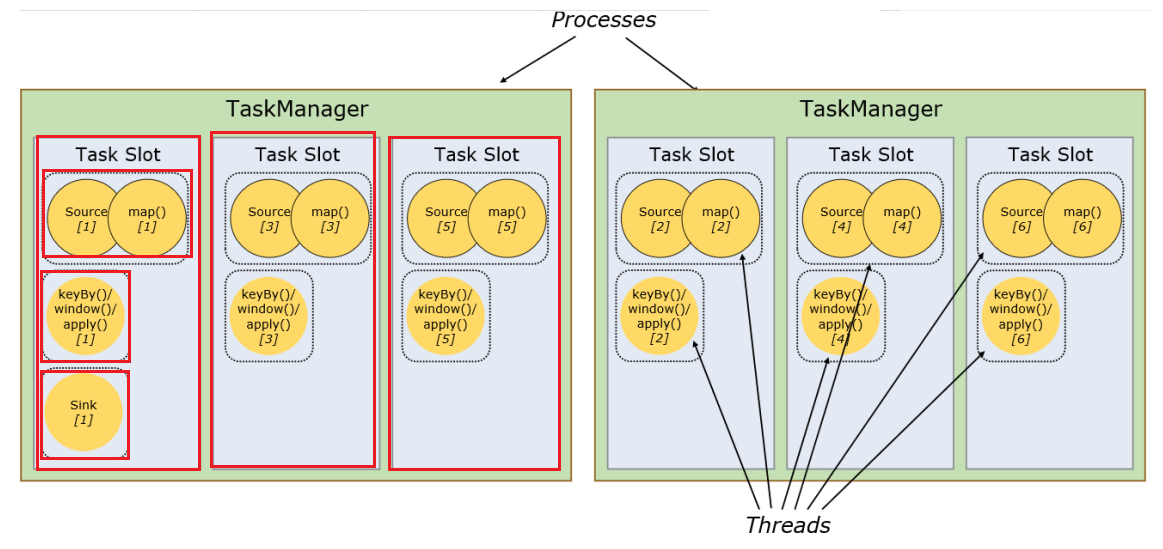
Flink的角色分配
- jobmanager
- taskmanager
- client
-
taskmanager 执行能力
- taskslot 静态的概念
- parallelism 并行度 动态概念
-
每个节点就是一个 task 任务
每个任务拆分成多个并行处理的任务,就叫子任务 subtask
-
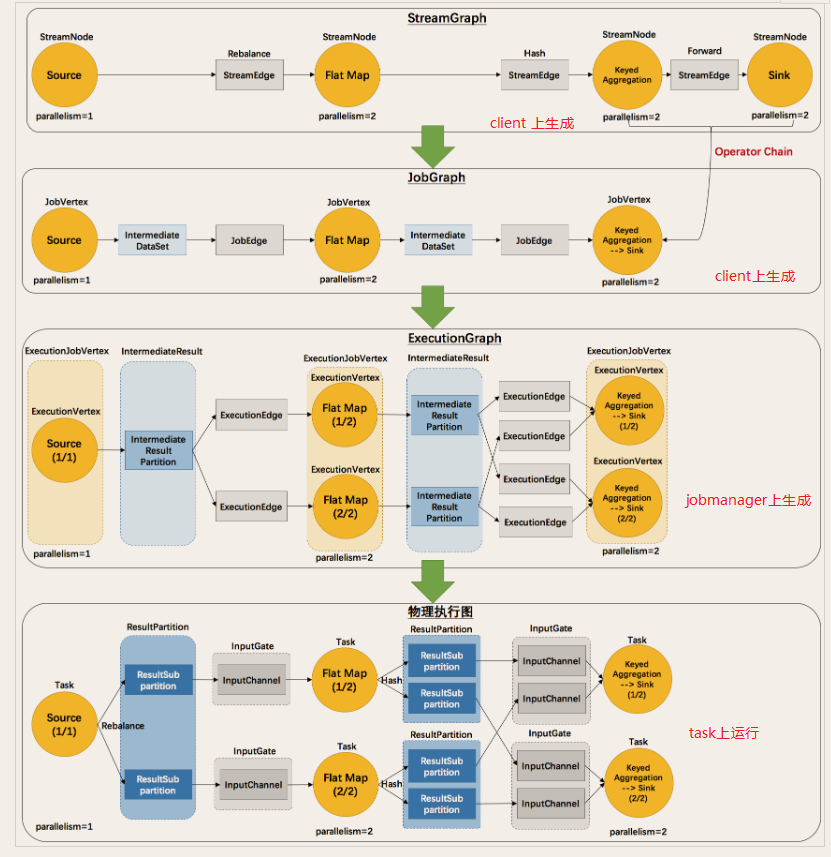
流图 StreamGraph 逻辑执行流图 DataFlow
operator chain 操作链
-
JobGraph
ExecuteGraph 物理执行计划
-
Event 事件 带有时间戳的
-
Operator 传递模式 : one to one 模式, redistributing模式
-
Flink之执行图
总结
以上便是2021年最新最全Flink系列教程_Flink概述、安装部署和入门案例(一)
愿你读过之后有自己的收获,如果有收获不妨一键三连一下~


- 点赞
- 收藏
- 关注作者
评论(0)