编码与解码的一些说明

编码与解码的一些说明
post 请求
POST的请求参数是通过request的getReader()来获取流中的数据TOMCAT在获取流的时候采用的编码是ISO-8859-1
ISO-8859-1编码是不支持中文的,所以会出现乱码
解决方案
页面设置的编码格式为UTF-8
把TOMCAT在获取流数据之前的编码设置为UTF-8
通过request.setCharacterEncoding(“UTF-8”)设置编码,UTF-8也可以写成小写
get请求
get获取数据并不是通过流的方式。post是通过流的方式。所以设置处理流的办法是没办法解决乱码问题的。
我们研究一下get请求的原理
(说明该图引用自黑马资料)
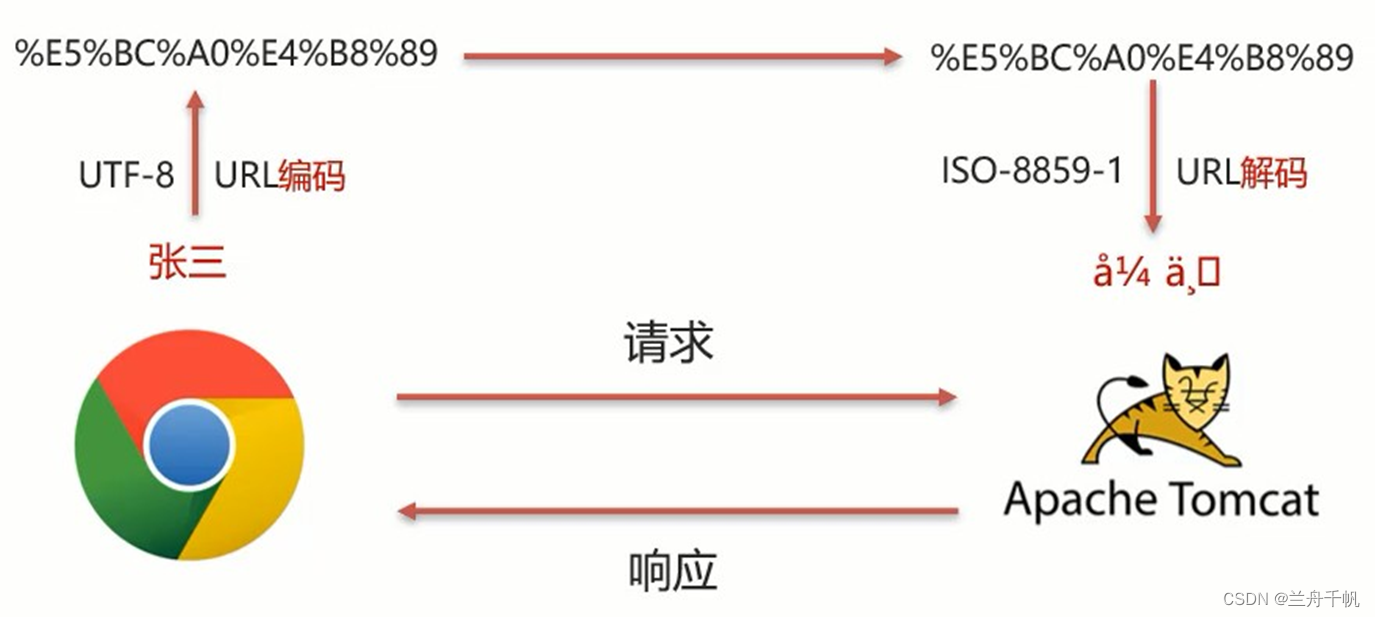
说明:
1:浏览器通过http协议发送请求给服务器
2:发送数据的时候一定会进行编码,进行的是url编码
3:在进行URL编码的时候会采用页面<meta> 标签指定的UTF-8的方式进行编码, 张三编码后的结果%E5%BC%A0%E4%B8%89
4: 后台服务器(Tomcat)接收到%E5%BC%A0%E4%B8%89 后会默认按照ISO-8859-1 进行URL解码
5:(5) 由于前后编码与解码采用的格式不一样,就会导致后台获取到的数据为乱码。
思考: 如果把req.html 页面的<meta> 标签的charset属性改成ISO-8859-1 ,后台不做操作,能解决中文乱码问题么?
答案是否定的,因为ISO-8859-1 本身是不支持中文展示的,所以改了标签的charset属性后,会导致页面上的中文内容都无法正常展示。
url编码
首先转换为二进制
一个汉字占用三个字节,所以张三一共需要6个字节,也就是48位。换算为二进制。
1110 0101 1011 1100 1010 0000 1110 0100 1011 1000 1000 1001
然后转换为16进制
E5BCA0E4B889
其实很好验证
我在浏览器的地址栏的随便一个链接中后面加上参数

然后我再复制完成全部链接,你可以到一个编辑器或者idea里面

取下来
你看就是对应上面我们转换出来的16进制数,然后隔两个加一个%号。
这样就完成了我们的url编码。
解码的话就交给对面的服务器,看按照什么解码方式。逻辑是倒着来,但是用到的方式不同的话,就会出现乱码的问题。
String username = "张三";
//1. URL编码
String encode = URLEncoder.encode(username, "utf-8");
System.out.println(encode); //打印:%E5%BC%A0%E4%B8%89
//2. URL解码
//String decode = URLDecoder.decode(encode, "utf-8");//打印:张三
String decode = URLDecoder.decode(encode, "ISO-8859-1");//打印:`å¼ ä¸ `
System.out.println(decode);
这段代码演示了一个编码解码的方式。
浏览器把中文参数按照UTF-8 进行URL编码
Tomcat对获取到的内容进行了ISO-8859-1 的URL解码
在控制台就会出现类上å¼ ä¸□ 的乱码,最后一位是个空格

- 点赞
- 收藏
- 关注作者
评论(0)