javaIO流之字节流

@TOC
IO引入
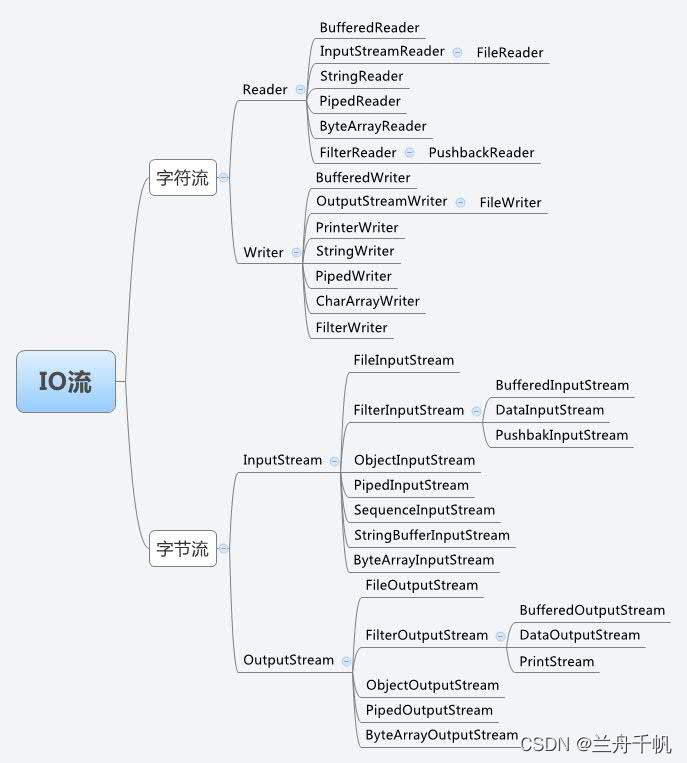
字节流和字符流(一些说明)
在java中io流分为字节流和字符流。字节流和字符流分别对应相应的读取和写入操作。整体的功能就是实现对输入输出的操作。
I/O就是input和output的缩写。而java之所以将此称之为流就是将其抽象化,来表示输入输出的功能。封装为对应的类,实现具体的功能,然后全部都存在io包当中。
用流来表示输入输出是也是非常形象的。可以想象数据传输信道中数据像流水一样进行传输。
字节流就是传输单位按为字节进行传输,字符流就是传输按照字符为单位进行传输
字节流没有用到缓冲区并不是没有用到内存
字节流与字符流的区别是什么呢?
从传输上面讲,字节流是字节在文件测层次上进行操作的,并没有用到缓冲区,字符流会用到缓冲区,然后通过缓冲区操作文件。我们是从传输上面讲,但是不要认为这个缓存区就是缓存,==缓存是cache,缓冲区是buffer。这是两个不同的概念==。
buffer也就是我们的缓冲区是内存空间的一部分,内存空间是预留了一定的存储空间的,用来缓冲输入或者输出。这就是我们 的缓冲区。当然缓冲区根据输入设备或者是输出设备分文输入缓冲区和输出缓冲区。
但是缓存(cache)就是我们为了内存为了弥补速度上与cpu的差异而划分出来的。当然磁盘上也有缓存,cpu也有。但是我们这里只区分内存上的缓冲区与缓存。这是完全不一样的两个概念。
==字节流本身没有用到缓冲区,但是也可以加入缓冲流来加快读取效率。那就是字节缓冲流了==
==缓冲区是为了缓冲,缓存是为了加快存取速度。==
==缓冲区不等于内存,没有用到缓冲区不是没有用到内存==。如果认为没有用到内存,那计算机就白学了。
在处理或者说是传输数据上面,字节流基本是可以处理任何类型的数据类型,但是字符流只能处理的是字符或者是字符串。字节流是不能直接处理Unicode字符的,字符流是可以进行处理的。在涉及到一些编码的问题上,比如文件中存在汉字,我们可以去用字符流去处理。
为什么输入流是读数据,而输出流是写数据?
不知道你是否有这样的疑问。
为什么输入流是读取数据,而输出流却是写数据。、
==因为输入输出都是相对于内存来说的。input是将数据从磁盘读取到内存当中,而输出就是将数据从内存输出道磁盘。==
我们程序在运行地时候也会从磁盘中被调入内存中,程序和其运行时数据都是会在内存中驻留,然后在真正执行的时候,cpu会从中读取到相应的数据指令,执行相应的指令。
字节流说明
字节输入流读数据的方法
public abstract class InputStreamextends InputStream
字节输入流InputStream是一个抽象类,直接继承于Object类。所以我们具体在应用功能的时候,最好还是去用到实现它的一些基本的类。
比较主要的读取方法在参数设定上会和字节输出流的写入方法相似。
public abstract int read()
throws IOException从输入流读取数据的下一个字节。 值字节被返回作为int范围0至255 。 如果没有字节可用,因为已经到达流的末尾,则返回值-1 。 该方法阻塞直到输入数据可用,检测到流的结尾,或抛出异常。
一个子类必须提供这个方法的一个实现。
public int read(byte[] b,
int off,
int len)
throws IOException从输入流读取len字节的数据到一个字节数组。 尝试读取多达len个字节,但可以读取较小的数字。 实际读取的字节数作为整数返回。
该方法阻塞直到输入数据可用,检测到文件结束或抛出异常。
如果len为零,则不会读取字节并返回0 ; 否则,尝试读取至少一个字节。 如果没有字节可用,因为流是文件的-1则返回值-1 ; 否则,读取至少一个字节并存储到b 。
第一个字节读取存储在元素b[off] ,下一个字节存入b[off+1] ,等等。 读取的字节数最多等于len 。 令k为实际读取的字节数; 这些字节将存储在元素b[off]至b[off+ k -1] ,使元素b[off+ k ]至b[off+len-1]不受影响。
在每种情况下,元件b[0]至b[off]和元件b[off+len]至b[b.length-1]不受影响。
该read(b, off, len)类方法InputStream简单地调用该方法read()反复。 如果第一个这样的呼叫产生一个IOException ,那个异常从呼叫返回到read(b, off, len)方法。 如果任何后续调用read()导致IOException ,则异常被捕获并被视为文件的结尾; 读取到该点的字节被存储到b ,并且返回异常发生前读取的字节数。 该方法的默认实现将阻塞,直到所请求的输入数据len已被读取,文件结束被检测到或异常被抛出为止。 鼓励子类提供更有效的方法实现。
public int read(byte[] b)
throws IOException从输入流读取一些字节数,并将它们存储到缓冲区b 。 实际读取的字节数作为整数返回。
字节输入流是用来进行读取数据的,不过读取数据的方式可以有两种,基本的是这样。
package io_demo;
//字节流读取数据
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class IoDrmo_2 {
public static void main(String args[]) throws IOException {
FileInputStream fis = new FileInputStream("E:\\java_doc\\src\\io_demo\\demo_pratice");
//int read() 从该输入流读取一个字节的数据
// int by = fis.read();
// System.out.println(by);
// System.out.println((char)by);
// fis.close();
int by = fis.read();//读取一个字节
while(by!=-1)
{
System.out.print((char)by);
by = fis.read();
}
//优化一下读取
while((by = fis.read())!=-1)
{
System.out.print((char)by);
}
fis.close();
}
}
当然我们也可以按照字节数组去读取,我们可以让一次读取多个字节。这样读取的话,就快一些。
package io_demo;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class IoDemo_4 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("E:\\java_doc\\src\\io_demo\\demo_pratice");
byte[] bytes = new byte[1024];
// System.out.println(len);
int len;
//采用循环
while((len= fis.read(bytes))!=-1)
{
System.out.print(new String(bytes,0,len));
}
fis.close();
}
}
一定要记得在操作完毕之后,关闭资源。
字节缓冲输入流
public class BufferedInputStream
extends FilterInputStream
提供的主要的构造方法
BufferedInputStream(InputStream in)
创建一个 BufferedInputStream并保存其参数,输入流 in ,供以后使用。
BufferedInputStream(InputStream in, int size)
创建 BufferedInputStream具有指定缓冲区大小,并保存其参数,输入流 in ,供以后使用。
从构造方法可知。我们使用它的时候需要传入一个字节缓冲输入流对象。
FileInputStream fis = new FileInputStream("E:\\java_doc\\src\\io_demo\\demo_pratice");
BufferedInputStream bis = new BufferedInputStream(fis);
同样我们可以用这样的对象去进行读取操作。
字节输出流写数据的方法
public abstract class OutputStreamextends OutputStream
字节输出流就是进行写入数据,我们可以进行向文件中写入数据。基本的抽象类还是需要去实现类中实现它的基本功能。
可以这样去实现,输出流的时候可以这样传入参数。
package java_practice;
import java.io.*;
public class FileDemo__ {
public static void main(String args[]) throws IOException {
File file = new File("E:\\java_doc\\src\\io_demo\\jgdabc.txt");
FileOutputStream fos = new FileOutputStream(file);
fos.write(97);
fos.close();
}
}
将这个文件对象传入,当然你也可以向文件输入流一样直接传入文件路径。但是需要注意的是,如果文件不存在的话 输入流是会报错的。因为输入流是读取文件的,被读取的文件不存在,那就会报错。输出流会自动创建文件,==输入流不会自动创建文件。==
写入数据的时候,比如我们写入一个97,
就会转换为字符a。这就涉及到对应的编码。
对照ASCII码表,我们可以看到十进制97对应的字符为a。这个write()方法会把对应的十进制数字97按照ASCII码进行转换。
0到97的输入,会看到ASCII表进行转换,其余的编码默认会查询系统编码GBK。关于编码的问题,我们在后面说。
当然write()方法也可以接收一个数组类型。一个字节数组。去对应的源码里面一看便知。
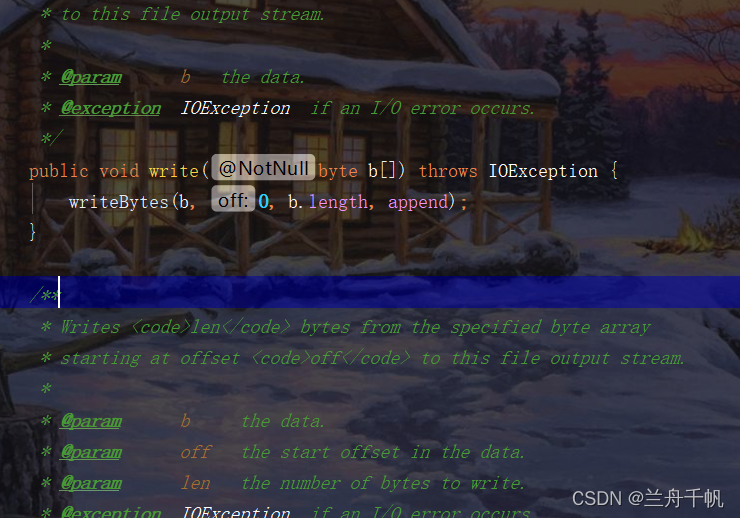
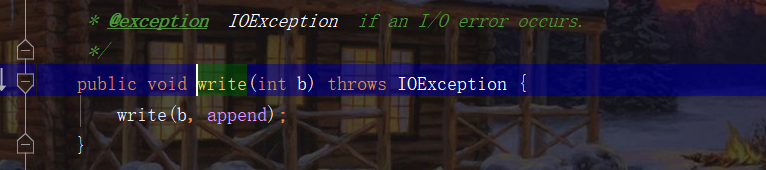
当然还可以有不同的参数列表
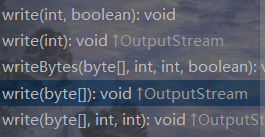
当然你如果不是很想去查看源码,也可以在javaapi里面找到对应的方法说明。
write
public void write(int b)
throws IOException将一个 integer(数组长度)写入此流。
public void write(byte[] b)
throws IOException将b.length字节从指定的字节数组写入此输出流。 write(b)的一般合约是应该具有与电话write(b, 0, b.length)完全相同的效果。
public void write(byte[] b,
int off,
int len)
throws IOException从指定的字节数组写入len字节,从偏移off开始输出到此输出流。 write(b, off, len)的一般合同是数组b中的一些字节按顺序写入输出流; 元素b[off]是写入的第一个字节, b[off+len-1]是此操作写入的最后一个字节。
该write的方法OutputStream调用写出在每个字节中的一个参数的写入方法。 鼓励子类覆盖此方法并提供更有效的实现。
如果b是null ,则抛出NullPointerException 。
如果off为负数,或len为负数,或off+len大于数组b的长度,则抛出IndexOutOfBoundsException 。
与此相关的方法,都可以查阅文档得到。
byte[] by = {97,98,99,100};
//取范围写入
fos.write(by,0,by.length);
fos.write(by);
当然你不能直接给write()中直接传入字符或者是字符串,我们的直接传入类型中是直接接收的是int类型,或者是可以传入一个byte数组。
既然是字节流,我们可以尝试将字符串或者字符转换为对应的byte类型。用到的一个方法是getBytes()。查看一下源码,看看是否转换为了数组类型,你可以验证一下。
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
}
我们也可以直接用代码进行操作。
fos.write("hello".getBytes());
字节缓冲输出流
public class BufferedOutputStream
extends FilterOutputStream
提供的主要的两个构造方法
BufferedOutputStream(OutputStream out)
//创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
BufferedOutputStream(OutputStream out, int size)
//创建一个新的缓冲输出流,以便以指定的缓冲区大小将数据写入指定的底层输出流。
提供的一些具体的方法
void flush()
//主要是进行刷新用的
void write(byte[] b, int off, int len)
//从指定的字节数组写入 len个字节,从偏移 off开始到缓冲的输出流。
void write(int b)
//将指定的字节写入缓冲的输出流。
**从构造方法可知,在使用这个缓冲输出流的时候,我们可以传一个输出流的对象进去。**
```javascript
FileOutputStream fos = new FileOutputStream("E:\\java_doc\\src\\io_demo\\demo_pratice");
BufferedOutputStream bos = new BufferedOutputStream(fos);
当然也可以直接这样进行传
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("E:\\java_doc\\src\\io_demo\\demo_pratice"));
==注意这样的做法叫做匿名对象,而不是匿名内部类==
然后后面的写入操作基本还是一样的。可以按照字节进行写入,也可以写入字节数组。但是加入缓冲区是一定会比较快的,
用输入输出实现数据的复制
可以进行文件到文件的复制
package io_demo;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
//用输入输出流进行文件的复制
public class IoDemo_3 {
public static void main(String args[]) throws IOException {
//字节输入流对象
FileInputStream fis = new FileInputStream("E:\\java_doc\\src\\io_demo\\demo_pratice");
//创建字节输出流对象
FileOutputStream fos = new FileOutputStream("E:\\java_doc\\src\\io_demo\\demo_01");
int by;
while((by = fis.read())!=-1)
{
fos.write(by);
}
fos.close();
fis.close();
}
}
这样可以简单的实现复制。
前面已经说过,读取文件返回-1表示到达文件结尾。
上边这段代码也只是一次读取一个字节,其实你也可以自己加入一个字节数组。来加快读取写入的速度。
当然我们可以用缓冲区,缓冲流。进行相关的操作。可以用字节缓冲流一次读取一个字节的数据,也可以一次读取一个字节数组大小数据。
package io_demo;
import java.io.*;
public class IoDemo_06 {
public static void main(String args[]) throws IOException {
FileOutputStream fos = new FileOutputStream("E:\\java_doc\\src\\io_demo\\demo_pratice");
BufferedOutputStream bos = new BufferedOutputStream(fos);
FileInputStream fis = new FileInputStream("E:\\java_doc\\src\\io_demo\\demo_pratice");
BufferedInputStream bis = new BufferedInputStream(fis);
int bu;
while((bu=bis.read())!=-1)
{
System.out.println((char)bu);
}
//一次读取一个字节数组的数据
byte[] bytes = new byte[1024];
int len;
while((len = bis.read(bytes))!=-1)
{
bos.write(bytes,0,len);
//System.out.println(new String(bytes,0,len));
}
bis.close();
fis.close();
}
}
但是其实你也会发现,假如文本中有中文的话,其实字节流处理的话是不太方便的,会有乱码的问题。
单单从文本中读取中文的话,如果再转换为char类型是绝对会出现乱码,但是如果从文件复制到文件的话,是不会出现问题的。因为复制到文件的时候,底层会自动进行拼接
这样处理的话,其实在后面的字符流中可以得到非常方便的处理。
==我们采用的字节流一般是默认utf-8编码的,这样的编码是会让一个汉字占用三个字节,但是如果是gbk编码的话,就会占用两个字节。但是无论采取何种编码,汉字的第一个字节总会是负数。这样的话,在数据复制的时候,就可以根据第一个字节是否是负数进行判断是汉字还是一般的字符。如果是第一个字节是负数的话,就会进行拼接。==
当然是也是可以实现对视频数据地复制的。选一个视频的话。然后比较一下种复制的效率。
提供一段代码,方法仅供参考,可以自己进行优化。
package io_demo;
import java.io.*;
public class IoDemo_07 {
public static void main(String args[]) throws IOException {
//四种方式实现复制视频
// 1:基本字节流一次读取一个字节
// 2:基本字节流一次读取一个字节数组
// 3:字节缓存流一次读取一个字节
// 4:字节缓存流一次读取一个字节数组
//记录开始时间
long startTime = System.currentTimeMillis();
//复制视频
method();
method_2();
method3();
method4();
//纪录结束时间
long endTime = System.currentTimeMillis();
System.out.println("共耗时:" + (endTime - startTime) + "毫秒秒");
}
private static void method() throws IOException {
//读取字节
FileInputStream fis = new FileInputStream("D:\\KuGou\\Tank - 三国恋.mkv");
FileOutputStream fos = new FileOutputStream("E:\\java_doc\\src\\io_demo\\1.mv");
int by;
while ((by = fis.read()) != -1) {
fos.write(by);
}
fos.close();
fis.close();
}
private static void method_2() throws IOException {
//一次读取一个字节数组
FileInputStream fis = new FileInputStream("D:\\KuGou\\Tank - 三国恋.mkv");
FileOutputStream fos = new FileOutputStream("E:\\java_doc\\src\\io_demo\\1.mv");
byte[] bytes = new byte[1024];
int len;
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
fos.close();
fis.close();
}
private static void method3() throws IOException {
FileInputStream fis = new FileInputStream("D:\\KuGou\\Tank - 三国恋.mkv");
FileOutputStream fos = new FileOutputStream("E:\\java_doc\\src\\io_demo");
BufferedInputStream bis = new BufferedInputStream(fis);
BufferedOutputStream bos = new BufferedOutputStream(fos);
int by;
while ((by = bis.read()) != -1) {
bos.write(by);
}
bos.close();
bis.close();
fis.close();
fos.close();
}
private static void method4() throws IOException {
FileInputStream fis = new FileInputStream("D:\\KuGou\\Tank - 三国恋.mkv");
FileOutputStream fos = new FileOutputStream("E:\\java_doc\\src\\io_demo");
BufferedInputStream bis = new BufferedInputStream(fis);
BufferedOutputStream bos = new BufferedOutputStream(fos);
byte[] bytes = new byte[1024];
int len;
while((len = bis.read(bytes))!=-1)
{
bos.write(bytes,0,len);
}
bos.close();
bis.close();
fis.close();
fos.close();
}
}
事实其实字节缓冲流加上一次读取一个字节数组的话,就非常快了。
复制单级文件夹(文件夹中只含有文件,不包含其它文文件夹)
使用字节流来进行复制
这样的单级文件夹得话,复制的时候主要还是需要对文件夹下面的文件进行一个遍历。
package io_demo;
import java.io.*;
public class Only_doc {
public static void main(String args[]) throws IOException {
//创建数据源
File srcFolder = new File("D:\\c_doc");
String srcFolderName = srcFolder.getName();
//创建目的地
File destFolder = new File("E:\\java_doc\\src\\io_demo", srcFolderName);
if(!destFolder.exists())
{
destFolder.mkdir();
}
File[] listFiles = srcFolder.listFiles();
for(File srcFile:listFiles)
{
String srcFileName = srcFile.getName();
File destFile = new File(destFolder, srcFileName);
copyFile(srcFile,destFile);
}
}
private static void copyFile(File srcFile, File destFile) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(srcFile));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(destFile));
byte[] bytes = new byte[1024];
int len;
while((len=bis.read(bytes))!=-1)
{
bos.write(bytes,0,len);
}
bos.close();
bis.close();
}
}
==需要注意的是,复制到源文件的指定父级路径一定要存在。如果不存在的话,会报错。子级别路径可以自己设定。==
复制多级文件夹(文件夹中包含文件夹)
package io_demo;
import java.io.*;
public class Mult_doc
{
//复制多级文件夹
public static void main(String args[]) throws IOException {
File srcfile = new File("D:\\BaiduNetdiskWorkspace");
File destFile = new File("E:\\java_doc\\src\\io_demo");
copyFolder(srcfile,destFile);
}
//复制文件夹
private static void copyFolder(File srcfile, File destFile) throws IOException {
//判断数据源是否是目录
if(srcfile.isDirectory())
{
//在目的地下创建和数据源File名称一样的目录
String srcFileName = srcfile.getName();
File new_Folder = new File(destFile,srcFileName);
if(!new_Folder.exists())
{
new_Folder.mkdir();
}
File[] filearry = srcfile.listFiles();
for(File file:filearry)
{
copyFolder(file,new_Folder);
}
}else {
File file = new File(destFile,srcfile.getName());
copyFile(srcfile,file);
}
}
private static void copyFile(File srcFile,File destFile) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(srcFile));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(destFile));
byte[] bytes = new byte[1024];
int len;
while((len= bis.read(bytes))!=-1)
{
bos.write(bytes,0,len);
}
}
}
这里面有一个基本的应用点就是采用了递归调用,基于判断是否遍历出来的是文件还是文件夹来采用是否进行继续遍历。
一个编码与解码的过程
这是一段简单的程序
package io_demo;
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class IoDemo_09 {
public static void main(String[] args) throws UnsupportedEncodingException {
//进行编码解码的演示
String s = "中国";
//使用默认的字符集将String编码为一系列字节,将结果存储到新的数组当中
//编码
byte[] bytes = s.getBytes();//使用默认的字符utf-8编码
System.out.println(Arrays.toString(bytes));
byte[] bytes1 = s.getBytes("UTF-8");
System.out.println(Arrays.toString(bytes1));
//解码过程
String ss = new String(bytes);
System.out.println(ss);
//平台的默认编码和平台默认的解码是一样的,所以可以正确输出
}
}
不要疑惑为什么getBytes()可以进行编码,给String()传入这个byte数组却又可以进行解码。直接区看看源码就好啦。可以进行跟进。
好,首先getBytes()。
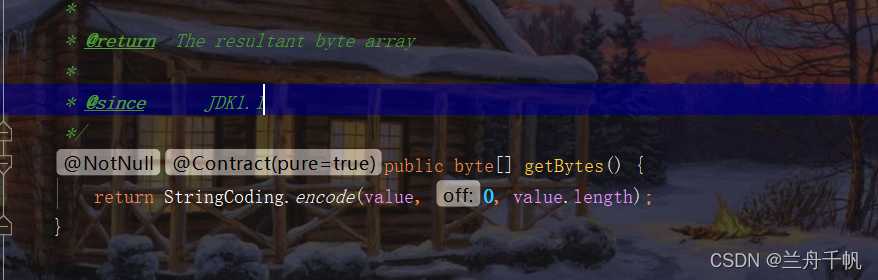
然后我们跟进它的encode方法
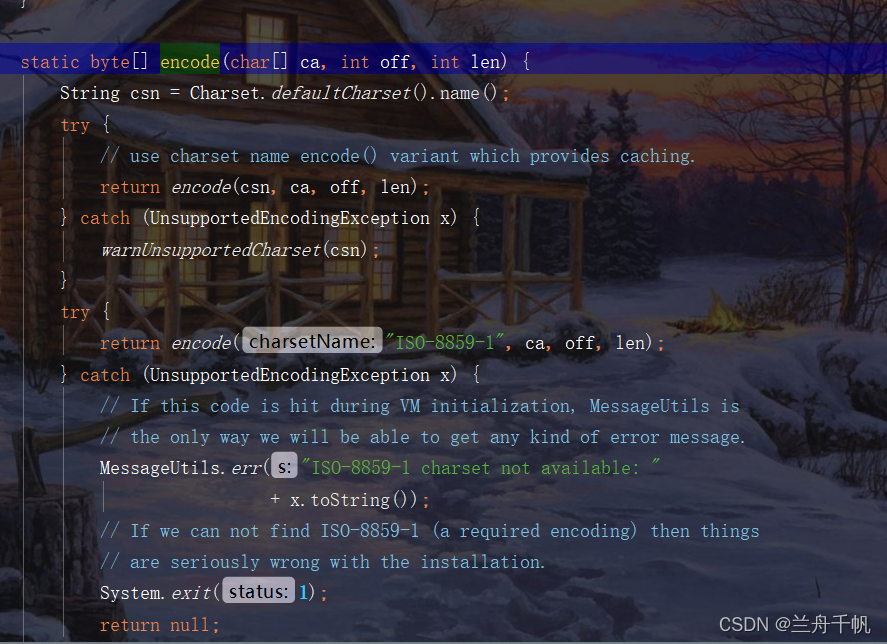
可以看到它这里是指定了编码的。
然后String里面的解码时怎么回事呢?继续跟进。

然后要知道如何区跟进,我们跟进this。
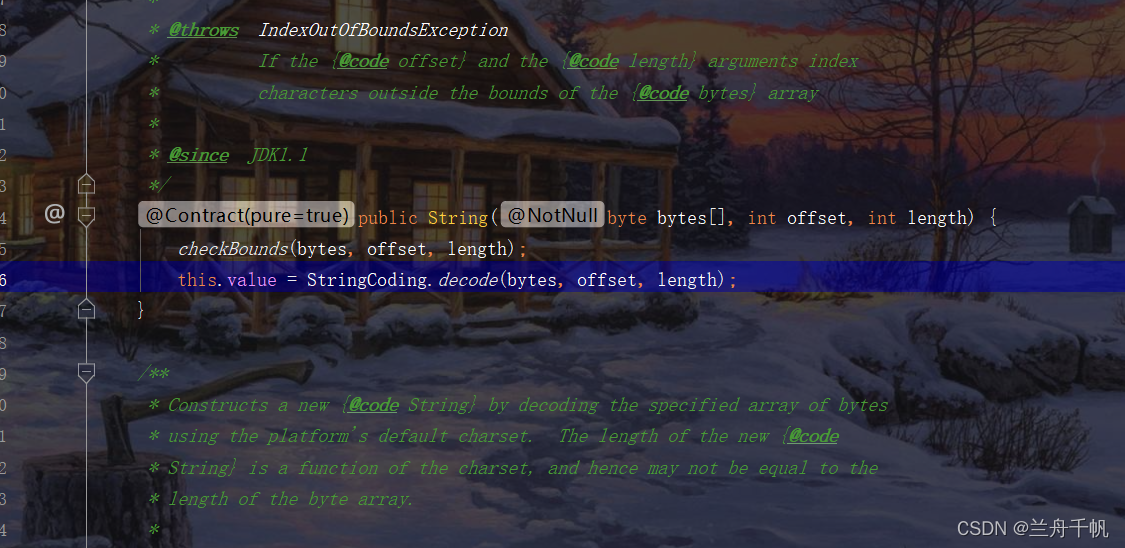
从单词字面意思也可以看出这是一个解码的过程,但是我们可以继续进行跟进。
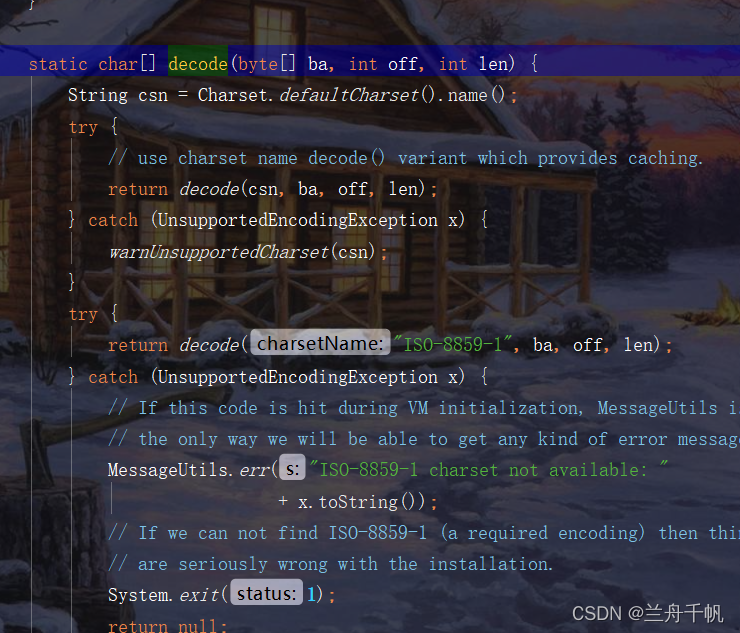
这里时一段解码的过程。所有的调用都可以进行溯源。

- 点赞
- 收藏
- 关注作者
评论(0)