Set集合

四:Set集合
我们来看jdk API对Set集合的概述
一个不包含重复元素的 collection。更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。
在所有构造方法以及 add、equals 和 hashCode 方法的协定上,Set 接口还加入了其他规定,这些规定超出了从 Collection 接口所继承的内容。出于方便考虑,它还包括了其他继承方法的声明(这些声明的规范已经专门针对 Set 接口进行了修改,但是没有包含任何其他的规定)。
对这些构造方法的其他规定是(不要奇怪),所有构造方法必须创建一个不包含重复元素的 set(正如上面所定义的)。
Set集合完整定义
public interface Set <E> extends Collection<E>
Set集合是不允许重复元素的,并且是不保证存取顺序一致的。
1:实现类HashSet
哈希值浅说
哈希值是Jdk根据对象的地址或者字符串或者数字计算出来的int类型的数值。
Object类有方法可以获取到对象的哈希值
还是重JDK API去查找
int hashCode()
返回该对象的哈希码值。
代码举例
TreeSet<Student> ts = new TreeSet<Student>();
Student s1 = new Student(29, "西施");
Student s2 = new Student(28, "王昭君");
Student s3 = new Student(30, "貂蝉");
Student s4 = new Student(33, "杨玉环");
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
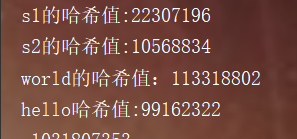
System.out.println("s1的哈希值:"+s1.hashCode());
System.out.println("s2的哈希值:"+s2.hashCode());
System.out.println("world的哈希值:"+"world".hashCode());
System.out.println("hello哈希值:"+"hello".hashCode());
<1 HashSet的数据结构
HashSet的数据结构实现在jdk1.8之前,哈希表=数组+链表,jdk1.8之后加入了红黑树。关于红黑树,后面再另起一篇文章叙述。
我们来看HashSet完整的类定义
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, Serializable
我们具体看JDK API对该类的说明
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
此类为基本操作提供了稳定性能,这些基本操作包括 add、remove、contains 和 size,假定哈希函数将这些元素正确地分布在桶中。对此 set 进行迭代所需的时间与 HashSet 实例的大小(元素的数量)和底层 HashMap 实例(桶的数量)的“容量”的和成比例。因此,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
HashSet底层的实现
看了一下源码,原来底层的实现竟然是Map
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and default load factor (0.75).
*
* @param initialCapacity the initial capacity of the hash table
* @throws IllegalArgumentException if the initial capacity is less
* than zero
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
HashSet要保证没有重复元素,可能是这样的特性才要从Map那里分点基因吧。。
<2>方法说明
API给出了摘要的几个方法
add(),clear(),clone(),contains(),isEmpty(),iterator(),remove()这些方法的使用与上一样。
<1存储不重复
简要演示,来看一段代码
HashSet s = new HashSet();
s.add("jgdabc");
s.add("hello");
s.add("jgdabc");
System.out.println(s);

可以看得出是保证了元素的不重复。
但是很多时候我们是操作对象的,如果我们把new()出来的对象添加进去,对象内部的属性还具有一样的值,那么HashSet能保证它的不重复性吗?示例验证一下
package java_practice;
import java.util.HashSet;
public class HashSetDemo2 {
private String name;
private int age;
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public HashSetDemo2(String name, int age) {
this.name = name;
this.age = age;
}
public static void main(String args[])
{
HashSet<HashSetDemo2> s = new HashSet<HashSetDemo2>();
HashSetDemo2 ha = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha1 = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha2 = new HashSetDemo2("li",20);
s.add(ha);
s.add(ha1);
s.add(ha2);
for(HashSetDemo2 ss : s )
{
System.out.println(ss.getName()+ss.getAge());
}
// s.add("jgdabc");
// s.add("hello");
// s.add("jgdabc");
// System.out.println(s);
}
}
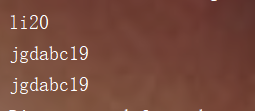
可以看到虽然姓名和年龄都一样,但是都添加进去了。为什么?
原因是因为我们添加的是对象,而对象的地址是不一样的。这里我们就可以引出HashSet如何判断元素唯一性的源码分析
很简单,那就从add()方法一路溯源
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
add这边又调用了put,所以我们去看put(HashMap的put)
好,找到了
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
put调用的是putVal方法,走下去。来了
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
需要注意到的是,首先是比较hashcode值,进行一个判断,然后比较的是equals()方法。
具体比较流程

其实比较的首先是地址,我们上面每个new的对象的地址是不一样的,所以就直接存储进去了。不再比较值。那么如何根据值,来确保不存储同样的学生呢?这样做,重写HashCode和equals()方法。那我们现在修改上面的代码,保证存储的唯一性。
package java_practice;
import java.util.HashSet;
import java.util.Objects;
public class HashSetDemo2 {
private String name;
private int age;
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public HashSetDemo2(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
HashSetDemo2 that = (HashSetDemo2) o;
return age == that.age &&
Objects.equals(name, that.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public static void main(String args[])
{
HashSet<HashSetDemo2> s = new HashSet<HashSetDemo2>();
HashSetDemo2 ha = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha1 = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha2 = new HashSetDemo2("li",20);
s.add(ha);
s.add(ha1);
s.add(ha2);
for(HashSetDemo2 ss : s )
{
System.out.println(ss.getName()+ss.getAge());
}
// s.add("jgdabc");
// s.add("hello");
// s.add("jgdabc");
// System.out.println(s);
}
}
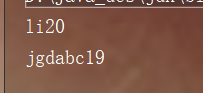
<2输出不保证无序
不一定任何情况输出都是无序的没我们可以参考这篇大佬的文章,很详细了。
深入分析——HashSet是否真的无序?(JDK8)
说实话,这篇文章的探究性比较强,我在写本文这里取看这篇文章没有看到底。目前看的东西太多了,有点烦躁。其实当我们深入探究的化话,就会到内存,数据的位运算,与运算这些,以及优化原理,甚至还有一些函数,还要考虑内存的存放机制。
Hashset其它的方法没有什么特殊的。

- 点赞
- 收藏
- 关注作者
评论(0)