Kubernetes Pod篇:带你轻松玩转Pod(下篇)

5、Pod升级和回滚
当需要升级某个服务时,一般会停止与该服务相关的所有Pod,然后下载新版本镜像并创建新的Pod。如果集群规模较大,则这样的工作就变成了一个挑战,并且长时间的服务不可用,也是很难让用户接受的。
为了解决上述问题,Kubernetes提供了滚动升级能够很好的解决。
如果Pod是通过Deployment创建,则可以在运行时修改Deployment的Pod定义(spc.template)或镜像名称,并应用到Deployment对象上,系统即可完成Deployment的自动更新操作。如果在更新过程中发生了错误,则可以通过回滚操作恢复Pod的版本。
5.1 Deployment的升级
以nginx-deployment.yml为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
(1)已运行的Pod副本数量为3,查看Pod状态:
[xcbeyond@localhost k8s]$ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-86b8cc866b-7rqzt 1/1 Running 2 53d
nginx-deployment-86b8cc866b-k2rwp 1/1 Running 2 53d
nginx-deployment-86b8cc866b-rn7l7 1/1 Running 2 53d
(2)现将nginx版本更新为nginx:1.9.1,可通过执行kubectl set image命令为Deployment设置新的镜像:
[xcbeyond@localhost k8s]$ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 -n test
deployment.apps/nginx-deployment image updated
kubectl set image:更新现有的资源对象的容器镜像。
另一种升级方法是使用kubectl edit命令修改Deployment的配置。
(3)此时(升级过程中),查看Pod状态,发现正在进行升级:
[xcbeyond@localhost k8s]$ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-79fbf694f6-kplgz 0/1 ContainerCreating 0 96s
nginx-deployment-86b8cc866b-7rqzt 1/1 Running 2 53d
nginx-deployment-86b8cc866b-k2rwp 1/1 Running 2 53d
nginx-deployment-86b8cc866b-rn7l7 1/1 Running 2 53d
升级过程中,可以通过执行
kubectl rollout status命令查看Deployment的更新过程。
(4)升级完成后,查看Pod状态:
[xcbeyond@localhost k8s]$ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-79fbf694f6-h7nfs 1/1 Running 0 2m43s
nginx-deployment-79fbf694f6-kplgz 1/1 Running 0 7m21s
nginx-deployment-79fbf694f6-txrfj 1/1 Running 0 2m57s
对比升级完成前后Pod状态列表中的NAME,已经发生了变化。
查看Pod使用的镜像,已经更新为nginx:1.9.1:
[xcbeyond@localhost k8s]$ kubectl describe pod/nginx-deployment-79fbf694f6-h7nfs -n test
Name: nginx-deployment-79fbf694f6-h7nfs
Namespace: test
……
Containers:
nginx:
Container ID: docker://0ffd43455aa3a147ca0795cf58c68da63726a3c77b40d58bfa5084fb879451d5
Image: nginx:1.9.1
Image ID: docker-pullable://nginx@sha256:2f68b99bc0d6d25d0c56876b924ec20418544ff28e1fb89a4c27679a40da811b
Port: 80/TCP
……
那么Deployment是如何完成Pod更新的呢?
使用kubectl describe deployment/nginx-deployment命令仔细查看Deployment的更新过程:
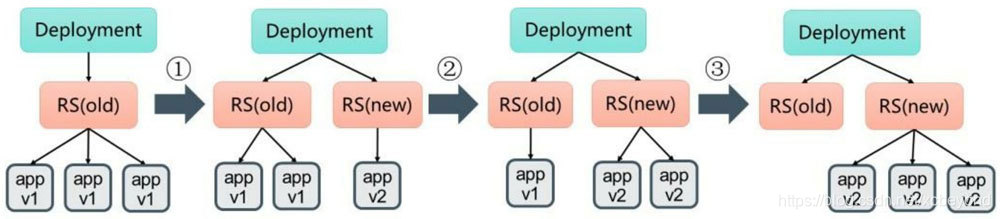
初始创建Deployment时,系统创建了一个ReplicaSet(nginx-deployment-86b8cc866b),并创建了3个Pod副本。当更新Deployment时,系统创建了一个新的ReplicaSet(nginx-deployment-79fbf694f6),并将其副本数量扩展到1,然后将旧的ReplicaSet缩减为2。之后,系统继续按照相同的更新策略对新旧两个ReplicaSet进行逐个调整。最后,新的ReplicaSet运行了3个新版本的Pod副本,旧的ReplicaSet副本数量则缩减为0。
如下图所示:
执行kubectl describe deployment/nginx-deployment命令,查看Deployment的最终信息:
[xcbeyond@localhost k8s]$ kubectl describe deployment/nginx-deployment -n test
Name: nginx-deployment
Namespace: test
CreationTimestamp: Thu, 26 Nov 2020 19:32:04 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 2
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-79fbf694f6 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 30m deployment-controller Scaled up replica set nginx-deployment-79fbf694f6 to 1
Normal ScalingReplicaSet 25m deployment-controller Scaled down replica set nginx-deployment-86b8cc866b to 2
Normal ScalingReplicaSet 25m deployment-controller Scaled up replica set nginx-deployment-79fbf694f6 to 2
Normal ScalingReplicaSet 25m deployment-controller Scaled down replica set nginx-deployment-86b8cc866b to 1
Normal ScalingReplicaSet 25m deployment-controller Scaled up replica set nginx-deployment-79fbf694f6 to 3
Normal ScalingReplicaSet 24m deployment-controller Scaled down replica set nginx-deployment-86b8cc866b to 0
执行kubectl get rs命令,查看两个ReplicaSet的最终状态:
[xcbeyond@localhost k8s]$ kubectl get rs -n test
NAME DESIRED CURRENT READY AGE
nginx-deployment-79fbf694f6 3 3 3 39m
nginx-deployment-86b8cc866b 0 0 0 53d
在整个升级过程中,系统会保证至少有两个Pod可用,并且最多同时运行4个Pod,这是Deployment通过复杂的算法完成。Deployment需要确保在整个更新过程中只有一定数量的Pod可能处于不可用状态。在默认情况下,Deployment确保可用的Pod总数至少所需的副本数量(desired)减1,也就是最多1个不可用(maxUnavailable=1)。
这样,在升级过程中,Deployment就能够保证服务不中断,并且副本数量始终维持为指定的数量(desired)。
更新策略
在Deployment的定义中,可以通过spec.strategy指定Pod更新策略。目前支持两种策略:Recreate(重建)和RollingUpdate(滚动更新),默认值为RollingUpdate。
- **Recreate:**设置
spec.strategy.type=Recrate,表示Deployment在更新Pod时,会先杀掉所有正在运行的Pod,然后创建新的Pod。 - **RollingUpdate:**设置
spec.strategy.type=RollingUpdate,表示Deployment会以滚动更新的方式来逐个更新Pod。同时,可通过设置spec.strategy.rollingUpdate中的两个参数maxUnavailable和maxSurge来控制滚动更新的过程。spec.strategy.rollingUpdate.maxUnavailable:用于指定Deployment在更新过程中最大不可用状态的Pod数量。 该值可以是具体数字,或者Pod期望副本数的百分比。spec.strategy.rollingUpdate.maxSurge:用于指定在Deployment更新Pod的过程中Pod总数超过Pod期望副本数部分的最大值。该值可以是具体数字,或者Pod期望副本数的百分比。
5.2 Deployment的回滚
在默认情况下,所有Deployment的发布历史记录都被保留在系统中,以便于我们随时进行回滚。(历史记录数量可配置)
可通过执行kubectl rollout undo命令完成Deployment的回滚。
(1)执行kubectl rollout history命令检查某个Deployment部署的历史记录:
[xcbeyond@localhost k8s]$ kubectl rollout history deployment/nginx-deployment -n test
deployment.apps/nginx-deployment
REVISION CHANGE-CAUSE
1 <none>
2 <none
在创建Deployment时使用
--record参数,就可以在CHANGE-CAUSE列看到每个版本创建/更新的命令。
(2)如果需要查看指定版本的详细信息,则可加上--revision=<N>参数:
[xcbeyond@localhost k8s]$ kubectl rollout history deployment/nginx-deployment --revision=2 -n test
deployment.apps/nginx-deployment with revision #2
Pod Template:
Labels: app=nginx
pod-template-hash=79fbf694f6
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
(3)先将撤销本次升级版本,并回滚到上一版本,即:nginx:1.9.1-> nginx:latest。执行kubectl rollout undo命令:
[xcbeyond@localhost k8s]$ kubectl rollout undo deployment/nginx-deployment -n test
deployment.apps/nginx-deployment rolled back
当然,也可以使用–to-revision参数指定回滚到具体某个版本号。
(4)可执行kubectl describe deployment/nginx-deployment命令查看回滚的整个过程:
[xcbeyond@localhost k8s]$ kubectl describe deployment/nginx-deployment -n test
Name: nginx-deployment
Namespace: test
CreationTimestamp: Thu, 26 Nov 2020 19:32:04 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 3
Selector: app=nginx
Replicas: 3 desired | 2 updated | 4 total | 3 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:latest
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
OldReplicaSets: nginx-deployment-79fbf694f6 (2/2 replicas created)
NewReplicaSet: nginx-deployment-86b8cc866b (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m50s deployment-controller Scaled up replica set nginx-deployment-86b8cc866b to 1
Normal ScalingReplicaSet 4m55s deployment-controller Scaled down replica set nginx-deployment-79fbf694f6 to 2
Normal ScalingReplicaSet 4m55s deployment-controller Scaled up replica set nginx-deployment-86b8cc866b to 2
5.3 RC的滚动升级
对于RC的滚动升级,Kubernetes还提供了一个kubectl rolling-update命令实现。该命令创建一个新的RC,然后自动控制旧的RC中的Pod副本数量逐渐减少到0,同时新的RC中的Pod副本数量从0逐步增加到目标值,来完成Pod的升级。
5.4 其他对象的更新策略
Kubernetes从1.6版本开始,对DaemonSet和StatefulSet的更新策略也引入类似于Deployment的滚动升级,通过不同的策略自动完成应用的版本升级。
5.4.1 DaemonSet的更新策略
DaemonSet的升级策略包括两种:
OnDelete:DaemonSet的默认策略。当使用OnDelete策略对DaemonSet进行更新时,在创建好新的DaemonSet配置之后,新的Pod并不会被自动创建,直到用户手动删除旧版本的Pod,才会触发新建操作。RollingUpdate:当使用RollingUpdate策略对DaemonSet进行更新时,旧版本的Pod将被自动删除,然后自动创建新版本的Pod。
5.4.2 StatefulSet的更新策略
Kubernetes从1.6版本开始,针对StatefulSet的更新策略逐渐向Deployment和DaemonSet的更新策略看齐,也将实现RollingUpdate、Partioned和onDelete这些策略,以保证StatefulSet中Pod有序地、逐个地更新,并保留更新历史记录,也能够回滚到某个历史版本。
6、Pod扩容
在实际生产环境下,我们面对不同场景,可能会进行服务实例的调整(增加或减少),以确保能够充分利用好系统资源。此时,可以利用Deployment/RC的Scale机制来完成这些工作。
Kubernetes对Pod扩容提供了手动和自动两种模式:
- **手动模式:**通过执行
kubectl scale命令或通过RESTful API对一个Deployment/RC进行Pod副本数量的设置。 - **自动模式:**用户根据某个性能指标或自定义业务指标,并指定Pod副本数量的范围,系统将自动在这个范围内根据性能指标的变化进行调整。
6.1 手动模式扩容
以nginx-deployment.yml为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
(1)已运行的Pod副本数量为3,查看Pod状态:
[xcbeyond@localhost ~]$ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-86b8cc866b-7g4xp 1/1 Running 0 24h
nginx-deployment-86b8cc866b-pgh6c 1/1 Running 0 24h
nginx-deployment-86b8cc866b-qg26j 1/1 Running 0 23h
(2)通过执行kubectl scale命令将Pod副本数量从初始的3个更新为5个:
[xcbeyond@localhost ~]$ kubectl scale deployment nginx-deployment --replicas 5 -n test
deployment.apps/nginx-deployment scaled
[xcbeyond@localhost ~]$ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-86b8cc866b-7g4xp 1/1 Running 0 24h
nginx-deployment-86b8cc866b-dbkms 0/1 ContainerCreating 0 5s
nginx-deployment-86b8cc866b-pgh6c 1/1 Running 0 24h
nginx-deployment-86b8cc866b-qg26j 1/1 Running 0 23h
nginx-deployment-86b8cc866b-xv5pm 0/1 ContainerCreating 0 5s
[xcbeyond@localhost ~]$ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-86b8cc866b-7g4xp 1/1 Running 0 24h
nginx-deployment-86b8cc866b-dbkms 1/1 Running 0 79s
nginx-deployment-86b8cc866b-pgh6c 1/1 Running 0 24h
nginx-deployment-86b8cc866b-qg26j 1/1 Running 0 23h
nginx-deployment-86b8cc866b-xv5pm 1/1 Running 0 79s
如果–replicas设置为比当前Pod副本小,则会删除一些运行中的Pod,以实现缩容。
6.2 自动模式扩容
Kubernetes从1.1版本开始,新增了Pod 横向自动扩容的功能(Horizontal Pod Autoscaler,简称 HPA),用于实现基于CPU使用率进行自动Pod扩容的功能。
HPA 与 Deployment、Service 一样,也属于一种Kubernetes资源对象。
HPA 的目标是通过追踪集群中所有 Pod 的负载变化情况(基于Master的kube-controller-manager服务持续监测目标Pod的某种性能指标),来自动化地调整Pod的副本数,以此来满足应用的需求和减少资源的浪费。
目前Kubernetes支持的指标类型如下:
- Pod资源使用率: Pod级别的性能指标,通常是一个比率指,例如CPU 利用率。
- Pod自定义指标: Pod级别的性能指标,通常是一个数值,例如服务在每秒之内的请求数(TPS 或 QPS)。
- Object自定义指标或外部自定义指标: 通常是一个数值,需要容器应用以某种方式提供,例如通过HTTP URL “/metrics”提供,或使用外部服务提供的指标采集URL(如,某个业务指标)。
如何统计和查询这些指标呢?
Kubernetes从1.11版本开始,弃用基于Heapster组件完成Pod的CPU使用率采集的机制,全面转向基于Metrics Server完成数据采集。Metrics Server将采集到的Pod性能指标数据通过聚合API(如,metrics.k8s.io、custom.metrics.k8s.io和external.metrics.k8s.io)提供给HPA控制器进行查询。
6.2.1 HPA的工作原理
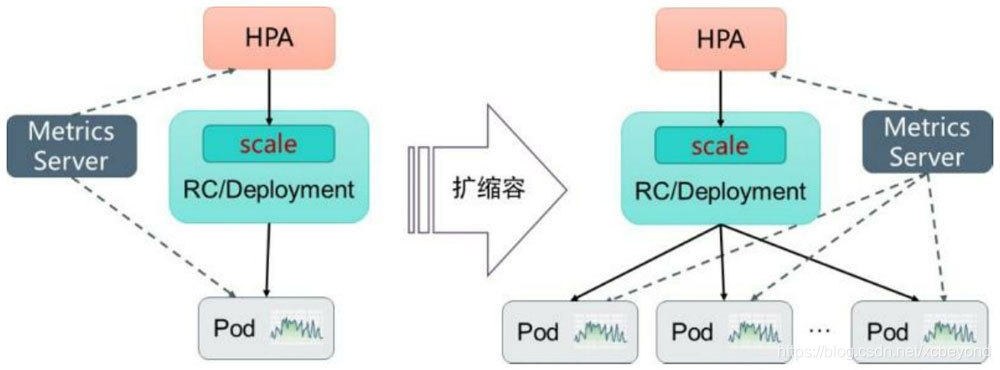
Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。HPA控制器通过Metrics Server的API获取这些数据,基于用户定义的扩容规则进行计算,得到目标Pod副本数量。当目标Pod副本数量与当前副本数量不同时,HPA控制器就向Pod的副本控制器(Deployment、RC或ReplicaSet)发起scale操作(等同于手动模式中执行kubectl scale命令),调整Pod的副本数量,完成扩容操作。
如下图描述了HPA体系中的关键组件和工作流程:
HPA控制器是基于Master的
kube-controller-manager服务启动参数--horizontal-pod-autoscaler-sync-period定义的探测周期(默认值为15s)。
6.2.2 HPA配置说明
自动模式扩容是通过HorizontalPodAutoscaler资源对象提供给用户来定义扩容规则。
HorizontalPodAutoscaler资源对象位于Kubernetes的API组“autoscaling”中,目前包括v1和v2两个版本。
- autoscaling/v1:仅支持基于CPU使用率的自动扩容。
- autoscaling/v2*:支持基于任意指标的自动扩容配置,包括基于资源使用率、Pod指标、其他指标等类型的指标数据。当前版本为autoscaling/v2beta2。
下面对HorizontalPodAutoscaler的配置和用法进行具体说明。
详细配置项可参考:
(1)基于autoscaling/v1版本的HorizontalPodAutoscaler配置:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
参数说明:
scaleTargetRef:目标作用对象,可以是Deployment、RC、ReplicaSet。targetCPUUtilizationPercentage:期望每个Pod的CPU使用率。minReplicas和maxReplicas:P大副本数量的最小值和最大值,系统将在这个范围内进行自动扩容操作,并维持每个Pod的CPU使用率为设置值。
使用autoscaling/v1版本的HorizontalPodAutoscaler,需预先安装Heapster组件或Metrics Server,用于采集Pod的CPU使用率。
(2)基于autoscaling/v2beta2版本的HorizontalPodAutoscaler配置:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
参数说明:
scaleTargetRef:目标作用对象,可以是Deployment、RC、ReplicaSet。minReplicas和maxReplicas:P大副本数量的最小值和最大值,系统将在这个范围内进行自动扩容操作,并维持每个Pod的CPU使用率为设置值。metrics:目标指标值。type:定义指标的类型。可设置四种类型,支持设置一个或多个类型的组合:Resource:基于资源的指标值,如CPU和内存。对应CPU使用率,在target参数中设置averageUtilization定义目标平均CPU使用率;对应内存资源,在target参数中设置AverageValue定义目标平均内存使用值。Pods:基于Pod的指标,系统将对全部Pod副本的指标值进行平均值计算。其target指标类型只能使用AverageValue。指标的数据通常需要搭建自定义Metrics Server和监控工具进行采集和处理。Object:基于某种资源对象的指标或应用系统的任意自定义指标。指标的数据通常需要搭建自定义Metrics Server和监控工具进行采集和处理。External:Kubernetes从1.10版本开始,引入了对外部系统指标的支持。例如,用户使用了公有云服务商提供的消息服务或外部负载均衡,可以基于这些外部服务的性能指标对自己部署在Kubernetes中的服务进行自动扩容操作。
target:定义相应的指标目标值,系统将在指标数据达到目标值时触发扩容操作。
例1,设置指标的名称为requests-per-second,其值来源于Ingress “main-route”,将目标值(value)设置为2000,即在Ingress的每秒请求数量达到2000个时触发扩容操作:
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: extensions/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
例2,设置指标的名称为http_requests,并且该资源对象具有标签“verb=GET”,在指标平均值达到500时触发扩容操作:
metrics:
- type: Object
object:
metric:
name: http_requests
selector: 'verb=GET'
target:
type: AverageValue
averageValue: 500
还可以在同一个HorizontalPodAutoscaler资源对象中定义多个类型的指标,系统将针对每种类型的指标都计算Pod副本的目标数量,以最大值为准进行扩容操作。例如:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: AverageUtilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: extensions/v1beta1
kind: Ingress
target:
type: Value
value: 10k
例3,设置指标的名称为queue_messages_ready,具有queue=worker_tasks标签在目标指标平均值为30时触发自动扩容操作:
metrics:
- type: External
external:
metric:
name: queue_messages_ready
selector: 'queue=worker_tasks'
target:
type: AverageValue
averageValue: 30
在使用外部服务的指标时,需安装、部署能够对接到Kubernetes HPA模型的监控系统,并且完成了解监控系统采集这些指标的机制,后续的自动扩容操作才能完成。
6.2.3 基于自定义指标的HPA实践
下面通过一个完整的示例,对如何搭建和使用基于自定义指标的HPA体系进行说明。
基于自定义指标进行自动扩容时,需预先部署自定义Metrics Server,目前可以使用基于Prometheus、Microsoft Azure、Google Stackdriver等系统的Adapter实现自定义Metrics Server。自定义Metrice Server可参考https://github.com/kubernetes/metrics/blob/master/IMPLEMENTATIONS.md#custom-metrics-api的说明。
本节是基于Prometheus监控系统对HPA的基础组件部署和HPA配置进行详细说明。
基于Prometheus的HPA架构如下图所示:
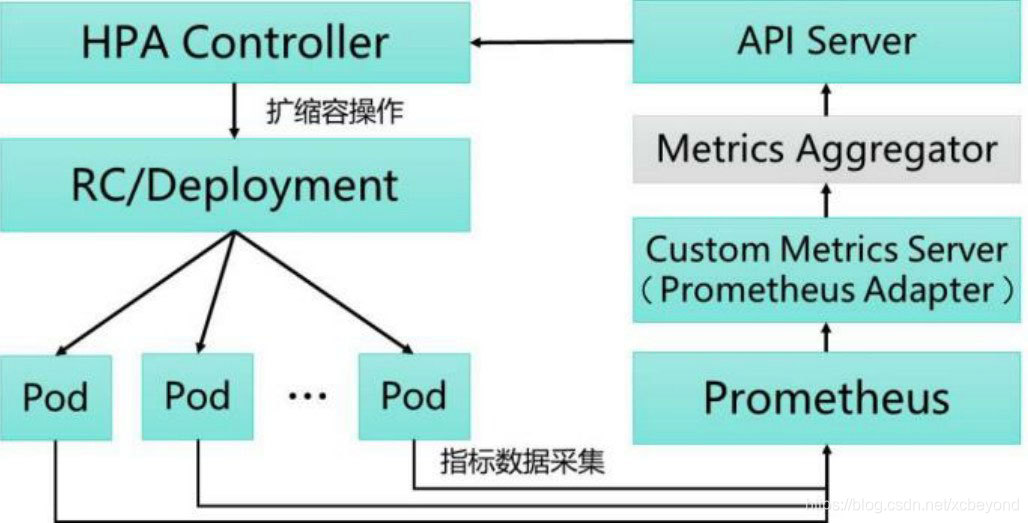
关键组件说明如下:
- Prometheus: 是一个开源的服务监控系统,用于定期采集各Pod的性能指标数据。
- Custom Metrics Server: 自定义Metrics Server,用Prometheus Adapter进行具体实现。它从Prometheus服务采集性能指标数据,通过Kubernetes的Metrics Aggregation层将自定义指标API注册到Master的API Server中以
/apis/custom.metrics.k8s.io路径提供指标数据。 - HPA Controller: Kubernetes的HPA控制器,基于用户自定义的HorizontalPodAutoscaler进行自动扩容操作。
整个部署过程如下:
(1)开启kube-apiserver、kube-controller-manager服务的相关启动参数。
kube-apiserver、kube-controller-manager服务默认已经部署在kube-system命名空间。[xcbeyond@localhost minikube]$ kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE coredns-6c76c8bb89-p26xx 1/1 Running 11 103d etcd-minikube 1/1 Running 11 103d kube-apiserver-minikube 1/1 Running 11 103d kube-controller-manager-minikube 1/1 Running 11 103d kube-proxy-gcd8d 1/1 Running 11 103d kube-scheduler-minikube 1/1 Running 11 103d storage-provisioner 1/1 Running 29 103d注:本Kubernetes环境是基于Minikube方式部署的本地环境。
可通过
kubectl describe命令查看服务目前的启动参数情况,例如:[xcbeyond@localhost minikube]$ kubectl describe pod/kube-apiserver-minikube -n kube-system Name: kube-apiserver-minikube Namespace: kube-system …… Containers: kube-apiserver: …… Command: kube-apiserver --advertise-address=172.17.0.2 --allow-privileged=true --authorization-mode=Node,RBAC --client-ca-file=/var/lib/minikube/certs/ca.crt --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota --enable-bootstrap-token-auth=true --etcd-cafile=/var/lib/minikube/certs/etcd/ca.crt --etcd-certfile=/var/lib/minikube/certs/apiserver-etcd-client.crt --etcd-keyfile=/var/lib/minikube/certs/apiserver-etcd-client.key --etcd-servers=https://127.0.0.1:2379 --insecure-port=0 --kubelet-client-certificate=/var/lib/minikube/certs/apiserver-kubelet-client.crt --kubelet-client-key=/var/lib/minikube/certs/apiserver-kubelet-client.key --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname --proxy-client-cert-file=/var/lib/minikube/certs/front-proxy-client.crt --proxy-client-key-file=/var/lib/minikube/certs/front-proxy-client.key --requestheader-allowed-names=front-proxy-client --requestheader-client-ca-file=/var/lib/minikube/certs/front-proxy-ca.crt --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --secure-port=8443 --service-account-key-file=/var/lib/minikube/certs/sa.pub --service-cluster-ip-range=10.96.0.0/12 --tls-cert-file=/var/lib/minikube/certs/apiserver.crt --tls-private-key-file=/var/lib/minikube/certs/apiserver.key ……可通过
kubectl edit命令对服务启动参数进行更新,如:[xcbeyond@localhost minikube]$ kubectl edit pod kube-apiserver-minikube -n kube-system
在Master的API Server启动Aggregation层,通过设置kube-apiserver服务的下列启动参数进行开启。
--requestheader-client-ca-file=/var/lib/minikube/certs/front-proxy-ca.crt:客户端CA证书。--requestheader-allowed-names=front-proxy-client:允许访问的客户端common names列表,通过header中由--requestheader-username-headers参数指定的字段获取。客户端common names的名称需要在client-ca-file中进行配置,将其设置为空值时,表示任意客户端都可以访问。--requestheader-extra-headers-prefix=X-Remote-Extra-:请求头中需要坚持的前缀名。--requestheader-group-headers=X-Remote-Group:请求头中需要检查的组名。--requestheader-username-headers=X-Remote-User:请求头中需要检查的用户名。--proxy-client-cert-file=/var/lib/minikube/certs/front-proxy-client.crt:在请求期间验证Aggregator的客户端CA证书。--proxy-client-key-file=/var/lib/minikube/certs/front-proxy-client.key:在请求期间验证Aggregator的客户端私钥。
配置kube-controller-manager服务中HPA的相关启动参数(可选配置)如下:
--horizontal-pod-autoscaler-sync-period=10s:HPA控制器同步Pod副本数量的空间间隔,默认值为15s。--horizontal-pod-autoscaler-downscale-stabilization=1m:执行扩容操作的等待时长,默认值为5min。--horizontal-pod-autoscaler-initial-readiness-delay=30s:等待Pod达到Read状态的时延,默认值为30min。--horizontal-pod-autoscaler-tolerance=0.1:扩容计算结果的容忍度,默认值为0.1,表示[-10% - +10%]。
(2)部署Prometheus。
这里使用Prometheus-operator来部署。
Prometheus Operator为监控 Kubernetes service、deployment和Prometheus实例的管理提供了简单的定义,简化在Kubernetes上部署、管理和运行。
(3)部署自定义Metrics Server。
以Prometheus Adapter的实现进行部署。
(4)部署应用程序。
该应用程序提供RESTful接口/metrics,并提供名为http_requests_total的自定义指标值。
(5)创建一个Prometheus的ServiceMonitor对象,用于监控应用程序提供的指标。
(6)创建一个HorizontalPodAutoscaler对象,用于为HPA控制器提供用户期望的自动扩容配置。
(7)对应用程序发起HTTP访问请求,验证HPA自动扩容机制。
参考文章:

- 点赞
- 收藏
- 关注作者
评论(0)