Kubernetes Pod篇:带你轻松玩转Pod(上篇)

本文将对Kubernetes如何发布与管理容器应用进行详细说明,主要包括Pod概述、基本用法、生命周期、Pod的控制和调度管理、Pod的升级和回滚,以及Pod的扩容机制等内容,并结合具体详细的示例,带你轻松玩转Pod,开启Kubernetes容器的编排之路。

1、Pod概述
1.1 Pod是什么?
Pod是Kubernetes中的原子对象,是基本构建单元。
Pod表示集群上一组正在运行的容器。通常创建Pod是为了运行单个主容器。Pod 还可以运行可选的sidecar容器,以实现诸如日志记录之类的补充特性。(如:在Service Mesh中,和应用一起存在的istio-proxy、istio-init容器)
一个Pod中可以包含多个容器(其他容器作为功能补充),负责处理容器的数据卷、秘钥、配置。

1.2 为什么要引入Pod概念?
原因1:Kubernetes可扩展
Kubernetes不会直接和容器打交道,Kubernetes的使用者能接触到的资源只有Pod,而Pod里可以包含多个容器。当我们在Kubernetes里用kubectl执行各种命令操作各类资源时,是无法直接操作容器的,往往都是借助于Pod。
Kubernetes并不是只支持Docker这一个容器运行时。 为了让Kubernetes不和某种特定的容器运行时进行技术绑死,而是能无需重新编译源代码就能够支持多种容器运行时技术的替换,和我们面向对象设计中引入接口作为抽象层一样,在Kubernetes和容器运行时之间我们引入了一个抽象层,即容器运行时接口(CRI:Container Runtime Interface)。
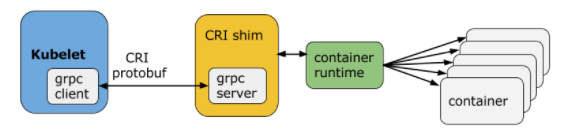
借助CRI这个抽象层,使得Kubernetes不依赖于底层某一种具体的容器运行时实现技术,而是直接操作Pod,Pod内部再管理多个业务上紧密相关的用户业务容器,这种架构更便于Kubernetes的扩展。
原因2:易管理
假设Kubernetes中没有Pod的概念,而是直接管理容器,那么有些容器天生需要紧密关联,如:在ELK中,日志采集Filebeat需要和应用紧密部署在一起。如果将紧密关联的一组容器作为一个单元,假设其中一个容器死亡了,此时这个单元的状态应该如何定义呢?应该理解成整体死亡,还是个别死亡?
这个问题不易回答的原因,是因为包含了这一组业务容器的逻辑单元,没有一个统一的办法来代表整个容器组的状态,这就是Kubernetes引入Pod的概念,并且每个Pod里都有一个Kubernetes系统自带的pause容器的原因,通过引入pause这个与业务无关并且作用类似于Linux操作系统守护进程的Kubernetes系统标准容器,以pause容器的状态来代表整个容器组的状态。

对于这些天生需要紧密关联的容器,可以放在同一个Pod里,以Pod为最小单位进行调度、扩展、共享资源及管理生命周期。
原因3:通讯、资源共享
Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。
相同的namespace可以用localhost通信,可以共享存储等。
1.3 Pod能够带来什么好处
搞清楚了Pod的由来,它到底能够为我们带来哪些好处呢?
- Pod做为一个可以独立运行的服务单元,简化了应用部署的难度,以更高的抽象层次为应用部署管提供了极大的方便。
- Pod做为最小的应用实例可以独立运行,因此可以方便的进行部署、水平扩展和收缩、方便进行调度管理与资源的分配。
- Pod中的容器共享相同的数据和网络地址空间,Pod之间也进行了统一的资源管理与分配。
2、Pod基本用法
无论通过命令kubectl,还是Dashboard图形管理界面来操作,都离不开资源清单文件的定义。如果采用Dashboard图形管理界面操作,最终还是基于kubectl命令操作的,这里只介绍使用kubectl命令来操作Pod。
关于kubectl命令更多说明,可以参考官方文档:https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#-strong-getting-started-strong-
Pod资源清单中有几个重要属性:apiVersion、kind、metadata、spec以及status。其中apiVersion和kind是比较固定的,status是运行时的状态,所以最重要的就是metadata和spec两个部分。
(Kubernetes资源清单的定义,可参考上一篇文章:Kubernetes资源清单篇:如何创建资源?)
先来定义一个简单的Pod资源文件,命名为frontend-pod.yml:
示例中的Pod是在命名空间test中定义的,所以接下来的执行命令中都涉及指定命名空间的参数
-n test。如果在默认命名空间default中定义,无需指定参数-n执行。
apiVersion: v1
kind: Pod
metadata:
name: frontend
namespace: test # 如果没有命名空间test,需提前创建。也可以使用默认命名空间default,即:namespace属性标签可以不定义
labels:
app: frontend
spec:
containers:
- name: frontend
image: xcbeyond/vue-frontend:latest # 发布在DockerHub中的镜像
ports:
- name: port
containerPort: 80
hostPort: 8080
可以使用命令kubectl explain pod来查看各个属性标签的具体用法及含义。
[xcbeyond@bogon ~]$ kubectl explain pod
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is
created by clients and scheduled onto hosts.
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an
object. Servers should convert recognized schemas to the latest internal
value, and may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
metadata <Object>
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
spec <Object>
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
status <Object>
Most recently observed status of the pod. This data may not be up to date.
Populated by the system. Read-only. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
2.1 创建
基于资源清单文件来创建Pod,kubectl create -f <filename>:
[xcbeyond@localhost ~]$ kubectl create -f frontend-pod.yml
pod/frontend created
2.2 查看状态
创建完Pod后,想知道Pod的运行状态,可通过命令kubectl get pods -n <namespace>查看:
(default命名空间,可不指定-n参数,非default则需指定具体namespace,否则查询不到。)
[xcbeyond@localhost ~]$ kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
frontend 1/1 Running 0 36s
2.3 查看配置
如果想了解一个正在运行的Pod配置,可通过命令kubectl get pod <pod-name> -n <namespace> -o <json|yaml>查看:
(-o参数用于指定输出配置格式,json、yaml格式)
此时查看结果处于运行态的结果,其中包含很多属性,我们只需关注关键属性即可。
[xcbeyond@localhost ~]$ kubectl get pod frontend -n test -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-11-19T08:33:20Z"
labels:
app: frontend
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:labels:
.: {}
f:app: {}
f:spec:
f:containers:
k:{"name":"frontend"}:
.: {}
f:image: {}
f:imagePullPolicy: {}
f:name: {}
f:ports:
.: {}
k:{"containerPort":80,"protocol":"TCP"}:
.: {}
f:containerPort: {}
f:hostPort: {}
f:name: {}
f:protocol: {}
f:resources: {}
f:terminationMessagePath: {}
f:terminationMessagePolicy: {}
f:dnsPolicy: {}
f:enableServiceLinks: {}
f:restartPolicy: {}
f:schedulerName: {}
f:securityContext: {}
f:terminationGracePeriodSeconds: {}
manager: kubectl-create
operation: Update
time: "2020-11-19T08:33:20Z"
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:status:
f:conditions:
k:{"type":"ContainersReady"}:
.: {}
f:lastProbeTime: {}
f:lastTransitionTime: {}
f:status: {}
f:type: {}
k:{"type":"Initialized"}:
.: {}
f:lastProbeTime: {}
f:lastTransitionTime: {}
f:status: {}
f:type: {}
k:{"type":"Ready"}:
.: {}
f:lastProbeTime: {}
f:lastTransitionTime: {}
f:status: {}
f:type: {}
f:containerStatuses: {}
f:hostIP: {}
f:phase: {}
f:podIP: {}
f:podIPs:
.: {}
k:{"ip":"172.18.0.5"}:
.: {}
f:ip: {}
f:startTime: {}
manager: kubelet
operation: Update
time: "2020-11-23T08:10:40Z"
name: frontend
namespace: test
resourceVersion: "28351"
selfLink: /api/v1/namespaces/test/pods/frontend
uid: be4ad65c-e426-4110-8337-7c1dd542f647
spec:
containers:
- image: xcbeyond/vue-frontend:latest
imagePullPolicy: Always
name: frontend
ports:
- containerPort: 80
hostPort: 8080
name: port
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-bbmj5
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: minikube
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: default-token-bbmj5
secret:
defaultMode: 420
secretName: default-token-bbmj5
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2020-11-19T08:33:20Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2020-11-23T08:10:40Z"
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2020-11-23T08:10:40Z"
status: "True"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2020-11-19T08:33:20Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: docker://84d978ee70d806d38b9865021d9c68881cf096960c7eb45e87b3099da85b4f6d
image: xcbeyond/vue-frontend:latest
imageID: docker-pullable://xcbeyond/vue-frontend@sha256:aa31cdbca5ca17bf034ca949d5fc7d6e6598f507f8e4dad481e050b905484f28
lastState: {}
name: frontend
ready: true
restartCount: 0
started: true
state:
running:
startedAt: "2020-11-23T08:10:40Z"
hostIP: 172.17.0.2
phase: Running
podIP: 172.18.0.5
podIPs:
- ip: 172.18.0.5
qosClass: BestEffort
startTime: "2020-11-19T08:33:20Z"
2.4 查看日志
如果想查看标准输出的日志,可以通过命令kubectl logs <pod-name> -n <namespace>查看:
[xcbeyond@localhost ~]$ kubectl logs frontend -n test
如果Pod中有多个容器,查看特定容器的日志需要指定容器名称kubectl logs <pod-name> -c <container-name>
2.5 修改配置
如果想修改已创建的Pod,如修改某个标签label,有以下几种方式:
(1)通过标签管理命令kubectl label设置或更新资源对象的labels。
该种方式只是针对标签的修改。
通过命令kubectl get pods -n <namespace> --show-labels查看标签:
[xcbeyond@localhost ~]$ kubectl get pods -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend 1/1 Running 0 4d app=frontend
通过命令kubectl label pod <pod-name> -n <namespace> <key=value>新增标签:
[xcbeyond@localhost ~]$ kubectl label pod frontend -n test tir=frontend
pod/frontend labeled
[xcbeyond@localhost ~]$ kubectl get pods -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend 1/1 Running 0 4d1h app=frontend,tir=frontend
通过命令kubectl label pod <pod-name> -n <namespace> <key=new-value> --overwrite修改标签:
[xcbeyond@localhost ~]$ kubectl label pod frontend -n test tir=unkonwn --overwrite
pod/frontend labeled
[xcbeyond@localhost ~]$ kubectl get pods -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend 1/1 Running 0 4d1h app=frontend,tir=unkonwn
(2)通过命令kubectl apply -f <filename>命令对配置进行更新。
(3)通过命令kubectl edit -f <filename> -n <namespace>命令对配置进行在线更新。
(4)通过命令kubectl replace -f <filename> -n <namespace> --force命令强制替换资源对象。
实际上,先删除在替换。
[xcbeyond@localhost ~]$ kubectl replace -f frontend-pod.yml --force
pod "frontend" deleted
pod/frontend replaced
2.6 删除
通过命令kubectl delete (-f <filename> | pod [<pod-name> | -l label]) -n <namespace>进行删除。
[xcbeyond@localhost ~]$ kubectl delete pod frontend -n test
pod "frontend" deleted
3、Pod生命周期
Pod对象自从其创建开始至其终止退出的时间范围称为其Pod生命周期。在这段时间中,Pod会处于多种不同的状态,并执行一些操作。其中,创建主容器(main container)为必需的操作,其他可选的操作还包括运行初始化容器(init container)、容器启动后钩子(post start hook)、容器的存活性探测(liveness probe)、就绪性探测(readiness probe)以及容器终止前钩子(pre stop hook)等,这些操作是否执行则取决于Pod的定义。如下图所示:

Pod的status字段是一个PodStatus的对象,PodStatus中有一个phase字段。
无论是手动创建还是通过Deployment等控制器创建,Pod对象总是处于其生命周期中以下几个阶段(phase)之一:
- 挂起(
Pending):API Server已经创建了该Pod,并已存入etcd中,但它尚未被调度完成,或者仍处于从仓库下载镜像的过程中。 - 运行中(
Running):Pod内所有容器均已创建,被调度至某节点,并且所有容器都已经被kubelet创建完成,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。 - 成功(
Succeeded):Pod内所有容器都已经成功执行后退出终止,且不会再重启。 - 失败(
Failed):Pod内所有容器都已退出,并且至少有一个容器是因为失败而终止退出。即容器以非0状态退出或者被系统禁止。 - 未知(
Unknown):由于某种原因Api Server无法正常获取到该Pod对象的状态信息,可能由于无法与所在工作节点的kubelet通信所致(网络通讯不畅)。


3.1 Pod的创建过程
Pod是Kubernetes中的基础单元,了解它的创建过程对于理解其生命周期有很大的帮助,如下图描述了一个Pod资源对象的典型创建过程。

(1)用户通过kubectl或其他API客户端提交了Pod Spec给API Server。(create Pod)
(2)API Server尝试着将Pod对象的相关信息写入etcd存储系统中,待写入操作执行完成,API Server即会返回确认信息至客户端。
(3)API Server开始反馈etcd中的状态变化。
(4)所有的kubernetes组件均使用“watch”机制来跟踪检查API Server上的相关的变动。
(5)kube-scheduler(调度器)通过其“watcher”觉察到API Server创建了新的Pod对象但尚未绑定至任何工作节点。
(6)kube-scheduler为Pod对象挑选一个工作节点并将结果信息更新至API Server。
(7)调度结果信息由API Server更新至etcd存储系统,而且API Server也开始反馈此Pod对象的调度结果。
(8)Pod被调度到的目标工作节点上的kubelet尝试在当前节点上调用Docker启动容器,并将容器的结果状态返回送至API Server。
(9)API Server将Pod状态信息存入etcd系统中。
(10)在etcd确认写入操作成功完成后,API Server将确认信息发送至相关的kubelet,事件将通过它被接受。
3.2 重要过程
3.2.1 初始化容器(Init Container)
初始化容器(init container)是一种专用的容器,用于在启动应用容器(app container)之前启动一个或多个初始化容器,完成应用容器所需的预置条件。

初始化容器与普通的容器非常相似,但它有如下独有特征:
- 初始化容器总是运行到成功完成为止。
- 每个初始化容器都必须在下一个初始化容器启动之前成功完成。
根据Pod的重启策略( restartPolicy ),当init container执行失败,而且设置了 restartPolicy 为Never时,Pod将会启动失败,不再重启;而设置 restartPolicy 为Always时,Pod将会被系统自动重启。
如果一个Pod指定了多个初始化容器,这些初始化容器会按顺序一次运行一个。只有当前面的初始化容器必须运行成功后,才可以运行下一个初始化容器。当所有的初始化容器运行完成后,Kubernetes才初始化Pod和运行应用容器。
3.2.2 容器探测
容器探测(container probe)是Pod对象生命周期中的一项重要的日常任务,它是kubelet对容器周期性执行的健康状态诊断,诊断操作由容器的处理器(handler)进行定义。Kubernetes支持三种处理器用于Pod探测:
ExecAction:在容器内执行指定命令,并根据其返回的状态码进行诊断的操作称为Exec探测,状态码为0表示成功,否则即为不健康状态。TCPSocketAction:通过与容器的某TCP端口尝试建立连接进行诊断,端口能够成功打开即为正常,否则为不健康状态。HTTPGetAction:通过向容器IP地址的某指定端口的指定path发起HTTP GET请求进行诊断,响应码为2xx或3xx时即为成功,否则为失败。
任何一种探测方式都可能存在三种结果:“Success”(成功)、“Failure”(失败)、“Unknown”(未知),只有success表示成功通过检测。
容器探测分为两种类型:
- 存活性探测(livenessProbe):用于判定容器是否处于“运行”(
Running)状态。一旦此类检测未通过,kubelet将杀死容器并根据重启策略(restartPolicy)决定是否将其重启,未定义存活检测的容器的默认状态为“Success”。 - 就绪性探测(readinessProbe):用于判断容器是否准备就绪并可对外提供服务。未通过检测的容器意味着其尚未准备就绪,端点控制器(如
Service对象)会将其IP从所有匹配到此Pod对象的Service对象的端点列表中移除。检测通过之后,会再将其IP添加至端点列表中。
什么时候使用存活(liveness)和就绪(readiness)探针?
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针,kubelet将根据Pod的restartPolicy自动执行正确的操作。
如果希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定restartPolicy为Always或OnFailure。
如果要仅在探测成功时才开始向Pod发送流量,请指定就绪探针。在这种情况下,就绪探针可能与存活探针相同,但是spec中的就绪探针的存在意味着Pod将在没有接收到任何流量的情况下启动,并且只有在探针探测成功才开始接收流量。
如果希望容器能够自行维护,可以指定一个就绪探针,该探针检查与存活探针不同的端点。
注意:如果只想在Pod被删除时能够排除请求,则不一定需要使用就绪探针;在删除Pod时,Pod会自动将自身置于未完成状态,无论就绪探针是否存在。当等待Pod中的容器停止时,Pod仍处于未完成状态。
4、Pod调度
在Kubernetes中,实际我们很少会直接创建一个Pod,在大多数情况下会通过RC(Replication Controller)、Deployment、DaemonSet、Job等控制器来完成对一组Pod副本的创建、调度及全生命周期的自动控制任务。
在最早的Kubernetes版本里是没有这么多Pod副本控制器的,只有一个Pod副本控制器RC,这个控制器是这样设计实现的:RC独立于所控制的Pod,并通过Label标签这个松耦合关联关系控制目标Pod实例的创建和销毁,随着Kubernetes的发展,RC也出现了新的继任者Deployment,用于更加自动地完成Pod副本的部署、版本更新、回滚等功能。
严谨地说,RC的继任者其实并不是Deployment,而是ReplicaSet,因为ReplicaSet进一步增强了RC标签选择器的灵活性。之前RC的标签选择器只能选择一个标签,而ReplicaSet拥有集合式的标签选择器,可以选择多个Pod标签,如下所示:
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
与RC不同,ReplicaSet被设计成能控制多个不同标签的Pod副本。一种常见的应用场景是,应用APP目前发布了v1与v2两个版本,用户希望APP的Pod副本数保持为3个,可以同时包含v1和v2版本的Pod,就可以用ReplicaSet来实现这种控制,写法如下:
selector:
matchLabels:
version: v2
matchExpressions:
- {key: version, operator: In, values: [v1,v2]}
其实,Kubernetes的滚动升级就是巧妙运用ReplicaSet的这个特性来实现的,同时Deployment也是通过ReplicaSet来实现Pod副本自动控制功能的。
4.1 全自动调度
Deployment或RC的主要功能之一就是全自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维护用户指定的副本数量。
示例:
(1)下面以一个Deployment配置的示例,使用这个资源清单配置文件nginx-deployment.yml可以创建一个ReplicaSet,这个ReplicaSet会创建3个Nginx的Pod:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
(2)执行kubectl create命令创建这个Deployment:
[xcbeyond@localhost ~]$ kubectl create -f nginx-deployment.yml -n test
deployment.apps/nginx-deployment created
(3)执行kubectl get deployments命令查看Deployment的状态:
[xcbeyond@localhost ~]$ kubectl get deployments -n test
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 17m
该结构表明Deployment已经创建好3个副本,并且所有副本都是最新可用的。
(4)通过执行kubectl get rs和kubectl get pods命令可以查看已经创建的ReplicaSet(RS)和Pod信息:
[xcbeyond@localhost ~]$ kubectl get rs -n test
NAME DESIRED CURRENT READY AGE
nginx-deployment-86b8cc866b 3 3 3 24m
[xcbeyond@localhost ~]$ kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-86b8cc866b-7rqzt 1/1 Running 0 27m
nginx-deployment-86b8cc866b-k2rwp 1/1 Running 0 27m
nginx-deployment-86b8cc866b-rn7l7 1/1 Running 0 27m
从调度策略上来说,这3个Nginx Pod有Kubernetes全自动调度的,它们各自被调度运行在哪个节点上,完全是由Master上的Schedule经过一系列计算得出,用户是无法干预调度过程和调度结果的。
除了使用自动调度,Kubernetes还提供了多种调度策略供用户实际选择,用户只需在Pod的定义中使用NodeSelector、NodeAffinity、PodAffinity、Pod驱逐等更加细粒度的调度策略设置,就能完成对Pod的精准调度。
4.2 NodeSelector:定向调度
Kubernetes Master上的Scheduler(kube-scheduler)负责实现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通过我们无法知道Pod最终会被调度到哪个节点上。
在实际场景下,可能需要将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,来达到上述目的。比如希望将MySQL数据库调度到一个SSD磁盘的目标节点上,此时Pod模板中的NodeSelector属性就发挥作用了。
示例:
(1)执行kubectl label nodes <node-name> <label-key>=<label-value>命令给指定Node添加标签。
如,把SSD磁盘的Node添加标签disk-type=ssd:
$ kubectl label nodes k8s-node-1 disk-type=ssd
(2)在Pod的资源清单定义中添加上nodeSelector属性。
apiVersion: v1
kind: Pod
metadata:
name: mysql
labels:
env: test
spec:
containers:
- name: mysql
image: mysql
nodeSelector:
disk-type: ssd
(3)通过执行kubectl get pods -o wide命令查看是否生效。
除了用户可以给Node添加标签,Kubernetes也给Node预定义了一些标签,方便用户直接使用,预定义的标签有:
- kubernetes.io/arch:示例,
kubernetes.io/arch=amd64。诸如混用 arm 和 x86 节点的情况下很有用。 - kubernetes.io/os:示例,
kubernetes.io/os=linux。在集群中存在不同操作系统的节点时很有用(例如:混合 Linux 和 Windows 操作系统的节点)。 - beta.kubernetes.io/os (已弃用)
- beta.kubernetes.io/arch (已弃用)
- kubernetes.io/hostname:示例,
kubernetes.io/hostname=k8s-node-1。 - ……
更多可参考:https://kubernetes.io/docs/reference/kubernetes-api/labels-annotations-taints/
NodeSelector通过标签的方式,简单实现了限制Pod所在节点的方法,看似既简单又完美,但在真实环境中可能面临以下令人尴尬的问题:
(1)如果NodeSelector选择的Label不存在或者不符合条件,比如这些目标节点宕机或者资源不足时,该怎么办?
(2)如果要选择多种合适的目标节点,比如SSD磁盘的节点或者超高速硬盘的节点,该怎么办?Kubernetes引入了NodeAffinity(节点亲和性)来解决上述问题。
(3)不同Pod之间的亲和性(Affinity)。比如MySQL和Redis不能被调度到同一个目标节点上,或者两种不同的Pod必须调度到同一个Node上,以实现本地文件共享或本地网络通信等特殊要求,这就是PodAffinity要解决的问题。
4.3 NodeAffinity:Node亲和性调度
NodeAffinity,是Node亲和性的调度策略,是用于解决NodeSelector不足的一种全新调度策略。
目前有两种方式来表达:
RequiredDuringSchuedlingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上(功能与nodeSelector很像,但使用的是不同语法),相当于硬限制。PreferredDuringSchedulingIgnoredDuringExection:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重值,以定义执行的先后顺序。
lgnoredDuringExecution隐含的意思是,在Pod资源基于Node亲和性规则调度至某节点之后,节点标签发生了改变而不再符合此节点亲和性规则时 ,调度器不会将Pod对象从此节点上移出。因此,NodeAffinity仅对新建的Pod对象生效。
Node亲和性可通过pod.spec.affinity.nodeAffinity进行指定。
示例:
设置NodeAffinity调度规则如下:
requiredDuringSchedulingIgnoredDuringExecution要求只运行在amd64的节点上(kubernetes.io/arch In amd64)。preferredDuringSchedulingIgnoredDuringExecution要求尽量运行在磁盘类型为ssd的节点上(disk-type In ssd)。
pod-with-node-affinity.yml定义如下:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/arch
operator: In
values:
- amd64
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disk-type
operator: In
values:
- ssd
containers:
- name: with-node-affinity
image: busybox
从上面的示例中看到使用了In操作符。NodeAffinity语法支持的操作符包括: In,NotIn,Exists,DoesNotExist,Gt,Lt。 你可以使用 NotIn 和 DoesNotExist 来实现节点反亲和行为,即实现排查的功能。
NodeAffinity规则定义的注意事项如下:
- 如果同时指定了
nodeSelector和nodeAffinity,那么两者必须都要满足,才能将Pod调度到指定的节点上。 - 如果
nodeAffinity指定了多个nodeSelectorTerms,那么其中一个能够匹配成功即可。 - 如果在
nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions才能运行该Pod。
如果你指定了多个与 nodeSelectorTerms 关联的 matchExpressions,
4.4 PodAffinity:Pod亲和和互斥调度策略
Pod间的亲和与互斥从Kubernetes 1.4版本开始引入的。这一功能让用户从另一个角度来限制Pod所能运行的节点:根据在节点上正在运行的Pod标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条件进行匹配。这种规则可以描述为:如果在具有标签X的Node上运行了一个或者多个符合条件Y的Pod,那么Pod应该运行在这个Node上。
与NodeAffinity不同的是,Pod是属于某个命名空间的,所以条件Y表达的是一个或者全部命名空间中的一个Label Selector。
和NodeAffinity相同,Pod亲和和互斥的设置也是requiredDuringSchedulingIgnoredDuringExecution和PreferredDuringSchedulingIgnoredDuringExection。
Pod亲和性可通过pod.spec.affinity.podAffinity进行指定。
4.5 Taints和Tolerations(污点和容忍)
NodeAffinity节点亲和性,是Pod中定义的一种属性,使得Pod能够被调度到某些Node上运行。而Taints则正好相反,它让Node拒绝Pod的运行。
Taints需要和Toleration配合使用,让Pod避开一些不合适的Node。在Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污点,否则无法在这些Node上运行。Toleration是Pod的属性,让Pod能够运行在标注了Taint的Node上。
可使用kubectl taint命令为Node设置Taint信息:
[xcbeyond@localhost ~]$ kubectl taint nodes node1 key=value:NoSchedule
4.6 Pod优先级调度
在Kubernetes 1.8版本引入了基于Pod优先级抢占(Pod priority Preemption)的调度策略,此时Kubernetes会尝试释放目标节点上优先级低的Pod,以腾出资源空间来安置优先级高的Pod,这种调度方式被称为”抢占式调度“。
可以通过以下几个维度来定义:
- Priority:优先级
- QoS:服务质量等级
- 系统定义的其他度量指标
示例:
(1)创建PriorityClasses,不属于任何命名空间:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "this priority class should be used for XYZ service pods only."
说明:定义名为high-priority的优先级,优先级为1000000,数字越大,优先级越高。优先级数字大于一亿的数字被系统保留,用于指派给系统组件。
(2)在Pod中引用上述定义的Pod优先级:
apiVersion: v1
kind: Pod
metadata:
name: frontend
namespace: test
labels:
app: frontend
spec:
containers:
- name: frontend
image: xcbeyond/vue-frontend:latest
ports:
- name: port
containerPort: 80
hostPort: 8080
priorityClassName: high-priority # 引用Pod优先级
使用优先级抢占的调度策略可能会导致某些Pod永远无法被成功调度。优先级调度不但增加了系统的复杂性,还可能带来额外不稳定的因素。因此,一旦发生资源紧张的局面,首先要考虑的是集群扩容,如果无法扩容,则再考虑有监管的优先级调度特性,比如结合基于Namespace的资源配额限制来约束任意优先级抢占行为。
4.7 DaemonSet:在每个Node上都调度一个Pod
DaemonSet是Kubernetes 1.2版本新增的一种资源对象,用于管理在集群中每个Node上仅运行一份Pod的副本实例。如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3UJhzRij-1611625546431)(./DaemonSet示例.jpg)]
DaemonSet的一些典型用法:
- 在每个节点上运行集群守护进程。如:运行一个GlusterFS存储或Ceph存储的Daemon进程。
- 在每个节点上运行日志收集守护进程。如:运行一个日志采集程序,Fluentd或Logstach。
- 在每个节点上运行监控守护进程。如:采集该Node的运行性能数据,Prometheus Node Exporter、collectd等。
4.8 Job:批处理调度
Job负责批量处理短暂的一次性任务 ,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
按照批处理任务实现方式的不同,有以下几种典型模式适用于不同的业务场景:
-
基于Job模版进行扩展:
需要先编写一个通用的Job模版,根据不同的参数生成多个Job json/yml文件用于Job的创建,可以使用相同的标签进行Job管理。
-
按每个工作项目排列的队列:
- 需要用户提前准备好一个消息队列服务,比如rabbitMQ,该服务是一个公共组件,每个工作项目可以往里塞任务消息。
- 用户可以创建并行Job,需要能适用于该消息队列,然后从该消息队列中消费任务,并进行处理直到消息被处理完。
- 该模式下,用户需要根据项目数量填写
spec.completions, 并行数量.spec.parallelism可以根据实际情况填写。该模式下就是以所有的任务都成功完成了,job才会成功结束。
-
可变任务数量的队列:
- 需要用户提前准备好一个存储服务来保存工作队列,比如Redis。每个项目可以往该存储服务填充消息。
- 用户可以启动适用于该工作队列的多个并行Job,进行消息处理。与前一个Rabbit消息队列的差异在于,每个Job任务是可以知道工作队列已经空了,这时候便可以成功退出。
- 该模式下,
spec.completions需要置1, 并行数量.spec.parallelism可以根据实际情况填写。只要其中有一个任务成功完成,该Job就会成功结束。
-
普通的静态任务:
采用静态方式分配任务项。
考虑到批处理的并行问题,Kubernetes将Job分为以下三种类型:
-
非并行Job:
通常一个Job只运行一个Pod,一旦此Pod正常结束,Job将结束。(Pod异常,则会重启)
-
固定完成次数的并行Job:
并发运行指定数量的Pod,直到指定数量的Pod成功,Job结束。
-
带有工作队列的并行Job:
- 用户可以指定并行的Pod数量,当任何Pod成功结束后,不会再创建新的Pod。
- 一旦有一个Pod成功结束,并且所有的Pods都结束了,该Job就成功结束。
- 一旦有一个Pod成功结束,其他Pods都会准备退出。
4.9 Cronjob:定时任务
类似Linux中的Cron的定时任务CronJob。
定时表达式,格式如下:
Minutes Hours DayofMonth Month DayofWeek Year
-
Minutes:分钟,有效范围为0-59的整数。可以为
,-*/这4个字符。 -
Hours:小时,有效范围为0-23的整数。可以为
,-*/这4个字符。 -
DayofMonth:每月的哪一天,有效范围为0-31的整数。可以为
,-*/?LWC这8个字符。 -
Month:月份,有效范围为1-12的整数或JAN-DEC。可以为
,-*/这4个字符。 -
DayofWeek:星期,有效范围为1-7的整数或SUN-SAT,1表示星期天,2表示星期一,以此类推。可以为
,-*/?LC#这8个字符。
例如,每隔1分钟执行一次任务,则Cron表达式为*/1 * * * *
示例:
(1)定义CronJob的资源配置文件test-cronjob.yml:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: test
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo hello from the Kubernetes cluster
restartPolicy: OnFailure
(2)执行kubectl crate命令创建CronJob:
[xcbeyond@localhost k8s]$ kubectl create -f test-cronjob.yml -n test
cronjob.batch/test created
(3)每隔1分钟执行kubectl get cronjob命令查看任务状态,发现的确是每分钟调度一次:
[xcbeyond@localhost k8s]$ kubectl get cronjob test -n test
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
test */1 * * * * False 1 61s 69s
[xcbeyond@localhost k8s]$ kubectl get cronjob test -n test
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
test */1 * * * * False 2 7s 75s
[xcbeyond@localhost k8s]$ kubectl get cronjob test -n test
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
test */1 * * * * False 3 28s 2m36s
执行
kubectl delete cronjob命令进行删除。
4.10 自定义调度器
如果在上述的调度器还是无法满足一些独特的需求,还可以使用任何语言实现简单或复杂的自定义调度器。

- 点赞
- 收藏
- 关注作者
评论(0)