IO流概述

1. 引言
1.1 传统集合的多步遍历代码
几乎所有的集合(如Collection接口或Map接口等)都支持直接或间接的遍历操作。而当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。例如:
import java.util.ArrayList;
import java.util.List;
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
for (String name : list) {
System.out.println(name);
}
}
}
输出结果:
张无忌
周芷若
赵敏
张强
张三丰
1.2 循环遍历的弊端
Java 8 的 Lambda 让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。现在,我们仔细体会一下上例代码,可以发现:
- for 循环的语法就是“怎么做”
- for 循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
试想一下,如果希望对集合中的元素进行筛选过滤:
- 将集合A根据条件一过滤为子集B;
- 然后再根据条件二过滤为子集C。
那怎么办?在 Java 8 之前的做法可能为:
import java.util.ArrayList;
import java.util.List;
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
List<String> zhangList = new ArrayList<>();
for (String name : list) {
if (name.startsWith("张")) {
zhangList.add(name);
}
}
List<String> shortList = new ArrayList<>();
for (String name : zhangList) {
if (name.length() == 3) {
shortList.add(name);
}
}
for (String name : shortList) {
System.out.println(name);
}
}
}
输出结果:
张无忌
张三丰
这段代码中含有三个循环,每一个作用不同:
- 首先筛选所有姓张的人;
- 然后筛选名字有三个字的人;
- 最后进行对结果进行打印输出。
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
1.3 Stream的更优写法
import java.util.ArrayList;
import java.util.List;
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(System.out::println);
}
}
输出结果:
张无忌
张三丰
直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印。代码中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。
2. 流式思想概述
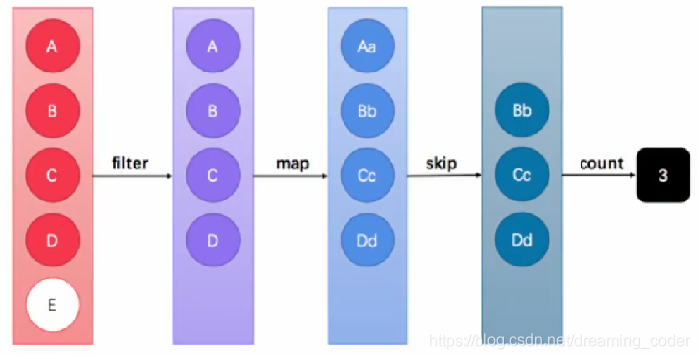
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而最右侧的数字3是最终结果。
这里的filter 、map 、skip 都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法count执行的时候,整个模型才会按照指定策略执行操作。而这得益于 Lambda 的延迟执行特性。
Stream(流)是一个来自数据源的元素队列
-
元素是特定类型的对象,形成一个队列。 Java 中的
Stream并不会存储元素,而是按需计算。 -
数据源可以是集合,数组等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining:中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
当使用一个流的时候,通常包括三个基本步骤:获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道。
3. 获取流
java.util.stream.Stream<T> 是Java 8新加入的最常用的流接口。(这并不是一个函数式接口。)
获取一个流非常简单,有以下几种常用的方式:
- 所有的
Collection集合都可以通过stream()默认方法获取流; Stream接口的静态方法of()可以获取数组对应的流。
import java.util.*;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
// 把集合转换为stream流
List<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<>();
Stream<String> stream2 = set.stream();
Map<String, String> map = new HashMap<>();
Set<String> keySet = map.keySet();
Stream<String> stream3 = keySet.stream();
Collection<String> values = map.values();
Stream<String> stream4 = values.stream();
Set<Map.Entry<String, String>> entries = map.entrySet();
Stream<Map.Entry<String, String>> stream5 = entries.stream();
// 把数组转换为stream
Stream<Integer> stream6 = Stream.of(1, 2, 3, 4, 5);
// 可变参数可以传递数组
Integer[] arr = {1, 2, 3, 4, 5};
Stream<Integer> stream7 = Stream.of(arr);
String[] arr2 = {"a", "bb", "cc"};
Stream<String> stream8 = Stream.of(arr2);
}
}
4. 常用方法
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
- 延迟方法:返回值类型仍然是
Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为延迟方法。) - 终结方法:返回值类型不再是
Stream接口自身类型的方法,因此不再支持类似StringBuilder那样的链式调用。
stream 流属于管道流,只能被消费(使用)一次,前一个 stream 流调用完方法,数据就会流转到下一个 stream 流上,而这时前一个 stream 流已经使用完毕,就会关闭了,所以不能再使用骗一个的 stream 流调用方法了。
4.1 forEach()
虽然方法名字叫forEach ,但是与for循环中的“for-each”昵称不同。
void forEach(Consumer<? super T> action);
该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理。
该方法是一个终结方法
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若");
stream.forEach(name -> System.out.println(name));
}
}
输出结果:
张无忌
张三丰
周芷若
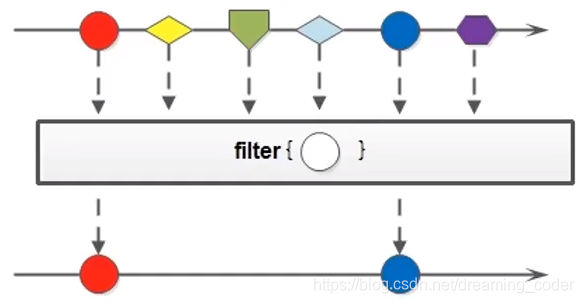
4.2 filter()
可以通过filter方法将一个流转换成另一个子集流。方法签名:
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个Predicate函数式接口参数(可以是一个 Lambda 或方法引用)作为筛选条件。
该方法是一个延迟方法
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若", "赵敏", "张翠山");
stream.filter(name -> name.startsWith("张")).forEach(System.out::println);
}
}
输出结果:
张无忌
张三丰
张翠山
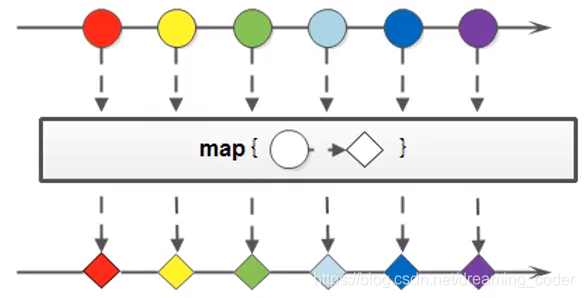
4.3 map()
如果需要将流中的元素映射到另一个流中,可以使用map 方法。方法签名:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
该方法是一个延迟方法
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<String> stream = Stream.of("1", "2", "3", "4", "5");
stream.map(s -> Integer.parseInt(s)).forEach(System.out::println);
}
}
输出结果:
1
2
3
4
5
4.4 count()
正如旧集合Collection当中的size()方法一样,流提供count()方法来数一数其中的元素个数:
long count();
该方法返回一个long值代表元素个数(不再像旧集合那样是int值)
该方法是一个终结方法
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.add(6);
list.add(7);
Stream<Integer> stream = list.stream();
long count = stream.count();
System.out.println(count);
}
}
输出结果:
7
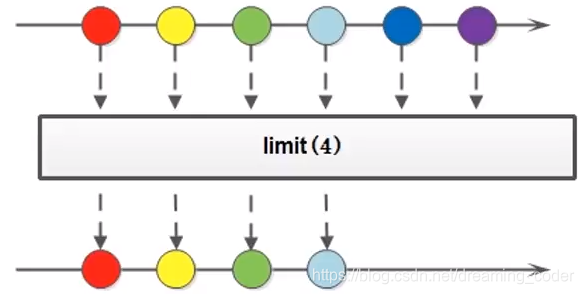
4.5 limit()
limit方法可以对流进行截取,只取用前n个。方法签名:
Stream<T> limit(long maxSize);
参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。
该方法是一个延迟方法
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
String[] arr = {"美羊羊", "喜羊羊", "懒羊羊", "灰太狼", "红太狼"};
Stream<String> stream = Stream.of(arr);
stream.limit(3).forEach(System.out::println);
}
}
输出结果:
美羊羊
喜羊羊
懒羊羊
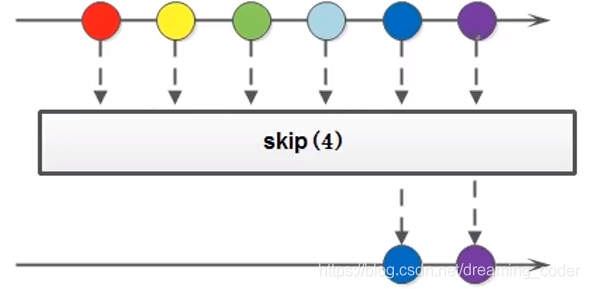
4.6 skip()
如果希望跳过前几个元素,可以使用skip()方法获取一个截取之后的新流:
Stream<T> skip(long n);
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。
该方法是一个延迟方法
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
String[] arr = {"美羊羊", "喜羊羊", "懒羊羊", "灰太狼", "红太狼"};
Stream<String> stream = Stream.of(arr);
stream.skip(3).forEach(System.out::println);
}
}
输出结果:
灰太狼
红太狼
4.7 concat()
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat():
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
这是一个静态方法,与
java.lang.String当中的concat()方法是不同的
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<String> stream1 = Stream.of("张无忌", "张三丰", "周芷若", "赵敏", "张翠山");
Stream<String> stream2 = Stream.of("美羊羊", "喜羊羊", "懒羊羊", "灰太狼", "红太狼");
Stream<String> concat = Stream.concat(stream1, stream2);
concat.forEach(System.out::println);
}
}
输出结果:
张无忌
张三丰
周芷若
赵敏
张翠山
美羊羊
喜羊羊
懒羊羊
灰太狼
红太狼
4.8 distinct()
去除流中重复的元素,其方法签名:
Stream<T> distinct();
该方法是一个延迟方法
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(1, 1, 2, 3, 3, 4, 5, 5, 6);
stream.distinct().forEach(System.out::println);
}
}
输出结果:
1
2
3
4
5
6
4.9 sorted()
该方法用于对 stream 流中的元素排序,其方法签名:
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
该方法是一个延迟方法
如果流中的元素的类实现了Comparable接口,即有自己的排序规则,那么可以直接调用sorted()方法对元素进行排序
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(3, 7, 2, 9, 5, 8, 1);
stream.distinct().sorted().forEach(System.out::println);
}
}
输出结果:
1
2
3
5
7
8
9
如果没有实现Comparable接口,则需要传入比较规则:
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(3, 7, 2, 9, 5, 8, 1);
stream.distinct().sorted((a, b) -> b - a).forEach(System.out::println);
}
}
输出结果:
9
8
7
5
3
2
1
要知道重写的比较方法,默认情况下是
前者-后者这种样式,表示顺序排序,反过来则是降序排序
4.10 reduce()
用于组合流中的元素,如求和,求积,求最大值等,其方法签名:
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
该方法是一个终结方法
import java.util.Optional;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream1 = Stream.of(3, 7, 2, 9, 5, 8, 1);
Stream<Integer> stream2 = Stream.of(3, 7, 2, 9, 5, 8, 1);
Optional<Integer> reduce1 = stream1.reduce((a, b) -> a + b);
Integer reduce2 = stream2.reduce(10, (a, b) -> a + b);
System.out.println(reduce1);
System.out.println(reduce2);
}
}
输出结果:
Optional[35]
45
至于第三种变体,如果你使用了parallelStream, reduce操作是并发进行的,为了避免竞争, 每个reduce线程都会有独立的result。 combiner的作用在于合并每个线程的 result, 得到最终结果。
import java.util.List;
public class Demo {
public static void main(String[] args) {
List<Integer> list = List.of(5, 3, 1, 7, 9, 6, 2, 4, 8);
Integer p = list.parallelStream().reduce(0, (a, b) -> a + b, (m, n) -> m + n);
System.out.println(p);
}
}
这里每个线程先通过第二个参数传入的方法分别计算结果,然后通过第三个参数传入的方法来对每组结果进行处理。
简而言之,第二个参数决定每个线程执行如何执行reduce操作,第三个参数决定的对每个线程reduce的结果如何执行reduce。
4.11 anyMatch()
流中元素是否存在至少一个元素满足要求
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(3, 7, 2, 9, 5, 8, 1);
boolean b = stream.anyMatch(a -> a < 0);
System.out.println(b);
}
}
输出结果:
false
4.12 allMatch()
流中元素是否全部满足要求
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(3, 21, -2, 9, 5, 8, 1);
boolean b = stream.allMatch(a -> a > 0);
System.out.println(b);
}
}
输出结果:
false
4.13 noneMatch()
流中是否没有元素满足要求
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(3, 21, 2, 9, 5, 8, 1);
boolean b = stream.noneMatch(a -> a < 0);
System.out.println(b);
}
}
输出结果:
false
4.14 findAny()和findFirst()
findAny():找到满足要求的一个元素 (使用 stream() 时找到的是第一个元素;使用 parallelStream() 并行时找到的是其中一个元素)findFirst():找到满足要求的第一个元素
import java.util.List;
import java.util.Optional;
import java.util.stream.Stream;
public class Demo {
public static void main(String[] args) {
Stream<Integer> stream1 = Stream.of(3, 21, -2, 9, 5, 8, 1);
Stream<Integer> stream2 = Stream.of(7, 21, -2, 9, 5, 8, 1);
Optional<Integer> first = stream1.findFirst();
System.out.println(first);
Optional<Integer> any = stream2.findAny();
System.out.println(any);
List<Integer> list = List.of(5, 3, 1, 7, 9, 6, 2, 4, 8);
Optional<Integer> r = list.parallelStream().findAny();
System.out.println(r);
}
}
输出结果:
Optional[3]
Optional[7]
Optional[6]
值得注意的是,这两个方法返回的是一个 Optional 对象,它是一个容器类,能代表一个值存在或不存在
4.15 boxed()
将数值流转换为一般流
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Demo{
public static void main(String[] args) {
int[] a = {1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(a);
List<Integer> list = stream.map(n -> 10 - n).boxed().collect(Collectors.toList());
}
}
- 点赞
- 收藏
- 关注作者
评论(0)