人工智能机器学习工具包Scikit-learn

1. 机器学习基础
机器学习是令计算机根据可用数据执行相应策略而无需以明确的编程方式执行策略的一门学科。 在过去几十年间,由于可用数据的数量和质量呈指数级增长,同时高性能的计算设备也得到了快速发展,机器学习在图像识别、自然语言处理、推荐系统和自动驾驶等领域都取得了突破性进展。
机器学习的目标是构建强大的模型,可以操纵输入数据以预测输出,同时随着新数据的增加不断更新模型。传递到计算机中的任何信息或数据都可以被视为输入,通过机器学习模型得到的数据则被认为是输出。
在机器学习中,输入数据也常被称为特征集,输出数据称为目标,特征集也称为特征空间。样本数据通常称为训练数据,使用样本数据训练模型完成后,它就可以对新数据进行预测,新数据通常也称为测试数据。机器学习主要可以分为两类:监督学习和无监督学习。监督学习是指数据集同时包含输入(特征集)和期望的输出(目标)。也就是说,我们知道数据的特征,我们的目的是做出预测,监督学习侧重于基于从训练数据中学习到的已知特征进行预测。常见的监督学习包括分类与回归。为了对新数据进行分类或回归,我们必须训练具有已知结果的数据,通过将数据映射到相应类别来对数据进行分类,通过查找特征集数据和目标数据之间的关系来进行数值预测。
对于无监督学习,数据集仅包含输入,但没有所需的输出(目标),其目标是探索数据并找到这些数据中的结构和模式。
2. Scikit-learn 机器学习库
2.1 Scikit-learn 介绍
Scikit-Learn 是机器学习的常用库,它包含很多实用工具和算法用于构建机器学习模型。它建立在 NumPy、SciPy 和 Matplotlib 之上,是用于入门机器学习的绝佳工具。Scikit-Learn 库旨在使机器学习变得尽可能简单。Scikit-learn 主要是用 Python 编写的,并且使用 Numpy 进行高性能的线性代数和数组运算,其具有各种分类、回归和聚类算法。
2.2 Scikit-learn 安装
与其它标准第三方库一样,可以使用 pip 库安装 Scikit-Learn,在命令行中执行以下命令:
pip install scikit-learn
安装完成后,可以使用以下代码在 Python 中导入 Scikit-learn 库:
import sklearn
3. 监督学习
考虑到篇幅,对于各种机器学习算法背后的原因,本文并不会进行详细的介绍,重点在于介绍如何使用 Scikit-learn 库进行机器学习。我们将要介绍的感知机、逻辑回归、支持向量机、决策树和 K 最近邻居属于分类模型,而最后我们使用线性回归简单介绍 Scikit-learn 库在线性任务中的应用。
3.1 感知器
为了构建感知器 (Perceptron),我们将使用 Iris 数据集。Iris 也称鸢尾花卉数据集,其中包含 150 个数据样本,分为 3 类,每类 50 个数据,每个数据包含 4 个属性,可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性将鸢尾花卉分类为 (Setosa,Versicolour,Virginica) 三类之一。鉴于Iris 数据集的流行性,其可以通过 Scikit-learn 加载,用于测试和试验算法。
我们将 150 个花卉的花瓣长度和花瓣宽度分配给特征矩阵 x,并将花卉相应的类别标签分配给数组 y:
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
x = iris.data[:, [2, 3]]
y = iris.target
print('Class labels: ', np.unique(y))
# 输出结果
# Class labels: [0 1 2]
np.unique(y) 函数返回存储在 iris.target 中的三个不同的类别标签,使用以上代码将鸢尾花类名称 Iris-setosa、Iris-versicolor 和 Iris-virginica 转换为整数 [0, 1, 2],使用整数标签可以提高计算性能,且内存占用更小;此外,将类标签编码为整数是大多数机器学习中的常见方法。
为了评估经过训练的模型在测试数据上的表现,我们首先将数据集拆分为训练和测试数据集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y)
使用 train_test_split 函数,将 x 和 y 数组随机分成 30% 的测试数据和 70% 的训练数据,各自包含的数据量输出如注释所示,我们通过 stratify=y 参数返回与输入数据集具有相同比例类别的训练和测试子集。可以使用 NumPy 的 bincount 函数计算数组中每个值的出现次数,以验证拆分后的数据集:
print('Labels counts in y:', np.bincount(y))
# Labels counts in y: [50 50 50]
print('Labels counts in y_train:', np.bincount(y_train))
# Labels counts in y_train: [35 35 35]
print('Labels counts in y_test:', np.bincount(y_test))
# Labels counts in y_test: [15 15 15]
为了加速训练,使用 Scikit-learn 预处理模块中的 StandardScaler 类对特征进行标准化:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(x_train)
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
使用以上代码,我们加载了 StandardScaler 类,并初始化了 StandardScaler 对象 sc,使用 fit 方法,StandardScaler 从训练数据中估计每个特征维度的参数 μ μ μ (样本均值)和 σ σ σ (标准差)。 通过调用 transform 方法,使用估计的参数 μ μ μ 和 σ σ σ 对训练和测试数据进行标准化。
标准化训练数据后,我们训练感知器模型:
from sklearn.linear_model import Perception
ppn = Perception(eta0=0.1)
ppn.fit(x_train_std, y_train)
在以上代码中,首先加载了 Perceptron 类,并初始化 Perceptron 对象 ppn ,然后通过 fit 方法训练模型,模型参数 eta0 为感知器使用的学习率。训练模型后,可以通过 predict 方法进行预测:
y_pred = ppn.predict(x_test_std)
print('Misclassified examples: %d' % (y_test != y_pred).sum())
# Misclassified examples: 4
我们可以看到感知器在 45 个测试数据中,将 4 个花卉样本错误分类。Scikit-learn 中还包括多种不同的性能指标,用于评估模型性能。例如,我们可以计算感知器在测试数据集上的分类准确率如下:
from sklearn.metrics import accuracy_score
print('Accuracy: %.3f' % accuracy_score(y_test, y_pred))
# Accuracy: 0.911
print('Accuracy: %.3f' % ppn.score(x_test_std, y_test))
# Accuracy: 0.911
最后,我们编写 plot_decision_regions 函数来绘制感知器模型的决策平面:
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
def plot_decision_regions(x, y, classifier, test_idx=None, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = x[:, 0].min() - 1, x[:, 0].max() + 1
x2_min, x2_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=x[y == cl, 0], y=x[y == cl, 1], alpha=0.8, c=colors[idx], marker=markers[idx], label=cl, edgecolor='black')
if test_idx:
x_test, y_test = x[test_idx, :], y[test_idx]
plt.scatter(x_test[:, 0], x_test[:, 1], c='', edgecolor='black', alpha=1.0, linewidth=1, marker='o', s=100, label='test set')
调用 plot_decision_regions,绘制决策平面:
x_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(x=x_combined_std, y=y_combined, classifier=ppn, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
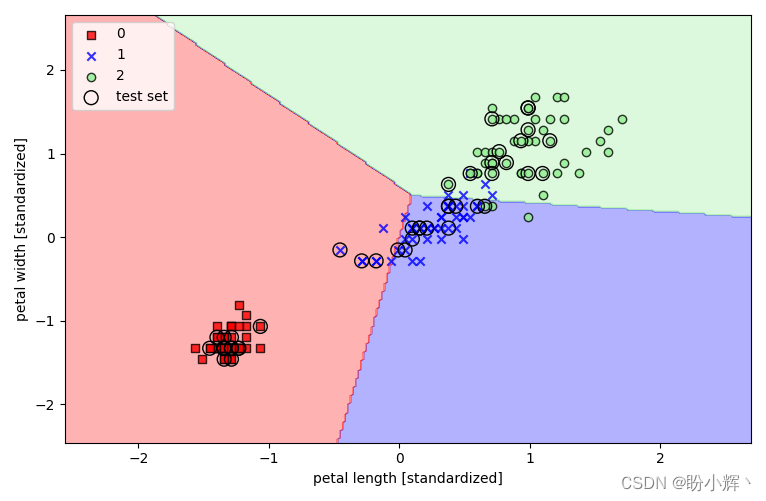
如上图所示,三种花卉并不能被线性感知器完美地进行区分,这就是我们需要在感知器中引入非线性的原因。
3.2 逻辑回归
接下来,我们现在实现另一种简单但更强大的线性的二分类算法:逻辑回归 (Logistic regression),尽管名为逻辑回归,但它是分类模型,而非回归模型。逻辑回归可以很容易地扩展至多分类问题,称为多元逻辑回归或 Softmax 回归。
为了解释逻辑回归背后的想法,我们首先介绍概率: p 1 − p \frac p {1-p} 1−pp 其中 p p p 代表正向事件 (positive event) 的概率。正向事件并不一定意味着是好的事件,而是指我们要预测的事件,例如患者患某种疾病的概率;我们可以将正向事件视为类标签 y = 1 y = 1 y=1。然后,我们可以定义 logit 函数,它是概率的对数:
l o g i t ( p ) = l o g p 1 − p logit(p)=log\frac p {1-p} logit(p)=log1−pp
其中, l o g log log 表示自然对数,因为它是计算机科学中的常用约定,我们可以用它来表示特征值和对数概率之间的线性关系:
l o g i t ( p ( y = 1 ∣ x ) ) = w 0 x 0 + w 1 x 1 + . . . + w n x n = ∑ i = 0 m w i x i = w T x logit(p(y=1|x))=w_0x_0+w_1x_1+...+w_nx_n=\sum ^m _{i=0} w_ix_i=w^Tx logit(p(y=1∣x))=w0x0+w1x1+...+wnxn=i=0∑mwixi=wTx
其中 p ( y = 1 ∣ x ) p(y=1|x) p(y=1∣x) 表示给定特征的样本 x x x 属于类别 1 的条件概率。这样,我们就可以对某个样本属于特定类别的概率进行预测。
简单的了解了逻辑回归的原理后,我们学习如何使用 Scikit-learn 中的 LogisticRegression 类实现逻辑回归,参数 C 用于指定正则化强度倒数,防止过拟合,参数 solver 用于指定优化器。该类还支持使用 multi_class 参数用于多分类问题。本节中,我们依旧使用 Iris 数据集训练模型。为了进行多分类,我们设置 multi_class='multinomial'。除此之外,multi_class 还有一个重要的可选值 'ovr' 进行比较。在实践中,通常对互斥类使用可选值 multinomial,例如在 Iris 数据集中的类别即为互斥类,“互斥”意味着每个训练样本只能属于一个类,多标签分类中一个训练样例可以属于多个别,例如一张图片中包含人、车和路灯等,则此图片可以有三个不同标签。
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=100., solver='lbfgs', multi_class='multinomial')
lr.fit(x_train_std, y_train)
plot_decision_regions(x_combined_std, y_combined, classifier=lr, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
在训练数据上拟合模型后,绘制决策区域、训练数据和测试数据,如下图所示:
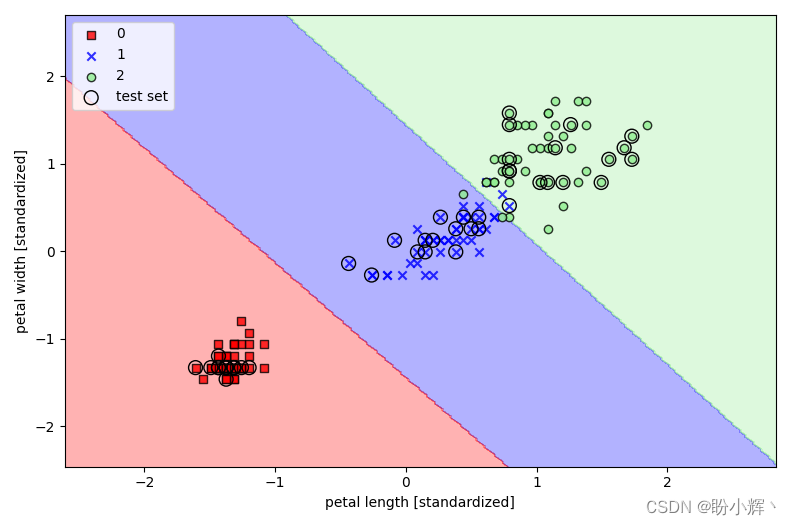
可以使用 predict_proba 方法计算训练样本属于某个类别的概率。例如,预测测试数据集中前三个样本的概率如下:
print(lr.predict_proba(x_test_std[:3, :]))
以上代码输出结果如下所示:
[[5.03465809e-06 9.33980393e-01 6.60145727e-02]
[9.98750558e-01 1.24944182e-03 9.03958143e-16]
[1.15923447e-14 1.73752823e-05 9.99982625e-01]]
第一行对应第一朵花的类别概率,第二行对应第二朵花的类成员概率,依此类推。第一行中的最大值约为 0.93,这意味着第一个示例属于第 2 类,预测概率为 93%。因此,我们可以通过使用 NumPy 的 argmax 函数识别每行中最大的列来获得预测的类标签:
print(lr.predict_proba(X_test_std[:3, :]).argmax(axis=1))
返回的类别索引显示如下:
array([1, 0, 2])
在以上代码示例中,我们计算条件概率,并使用 NumPy 的 argmax 函数手动将它们转换为类标签,我们也可以使用 predict 直接获取类标签:
print(lr.predict(X_test_std[:3, :]))
# array([2, 0, 0])
3.3 支持向量机
支持向量机 (Support Vector Machines, SVM) 是另一种强大的机器学习算法,它是感知器的扩展。 使用感知器算法,我们的目标是最大限度地减少了错误分类概率,在 SVM 中,我们的优化目标是最大化边距 (margin),边距定义为超平面(决策边界)与最接近该超平面的训练样本之间的距离,即所谓的支持向量。简单了解 SVM 背后的基本思想后,我们训练 SVM 模型来对 Iris 数据集中的不同花朵进行分类:
from sklearn.svm import SVC
svm = SVC(kernel='linear', C=1.0)
svm.fit(x_train_std, y_train)
plot_decision_regions(x_combined_std, y_combined, classifier=svm, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
通过执行以上代码在 Iris 数据集上训练分类器后可视化,SVM 的三个决策区域如下图所示:
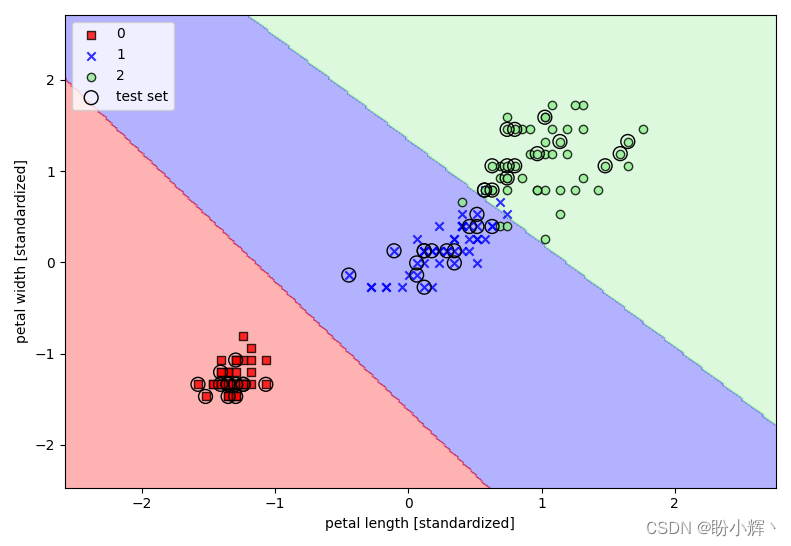
3.4 决策树
决策树分类器的执行过程具有很好的可解释性,正如其名称所示,我们可以将此模型视为通过解决一系列问题做出决策,以此来分解数据。
基于训练数据集中的特征,决策树模型学习一系列问题来推断样本的类别标签。例如在 Iris 数据集中,我们可以沿萼片宽度特征轴定义一个阈值并提出一个二元问题:萼片宽度是否 ≥2.8 cm?通过回答一系列问题完成样本数据的分类。
使用决策树算法,从树根开始,在令最大信息增益 (Information Gain, IG) 的特征上分割数据。在一个迭代过程中,我们可以在每个子节点重复这个分裂过程,直到叶子节点。这意味着每个节点的训练样本都属于同一个类。在实践中,这可能会导致树的节点过多且深度较深,这很容易导致过拟合。因此,我们通常通过设置树的最大深度来修剪树。
决策树可以通过将特征空间划分为矩形来构建复杂的决策边界。但是,决策树越深,决策边界就越复杂,这很容易导致过拟合。接下来,我们使用 Scikit-learn 训练一个最大深度为 4 的决策树,使用 Gini 不纯度作为度量标准。尽管出于可视化目的可能需要对特征进行缩放,但特征缩放对于决策树算法并非必要:
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier(criterion='gini', max_depth=4)
tree_model.fit(x_train, y_train)
x_combined = np.vstack((x_train, x_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(x_combined, y_combined, classifier=tree_model, test_idx=range(105, 150))
plt.xlabel('petal length [cm]')
plt.ylabel('petal width [cm]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
执行代码后,我们得到决策树的决策边界:
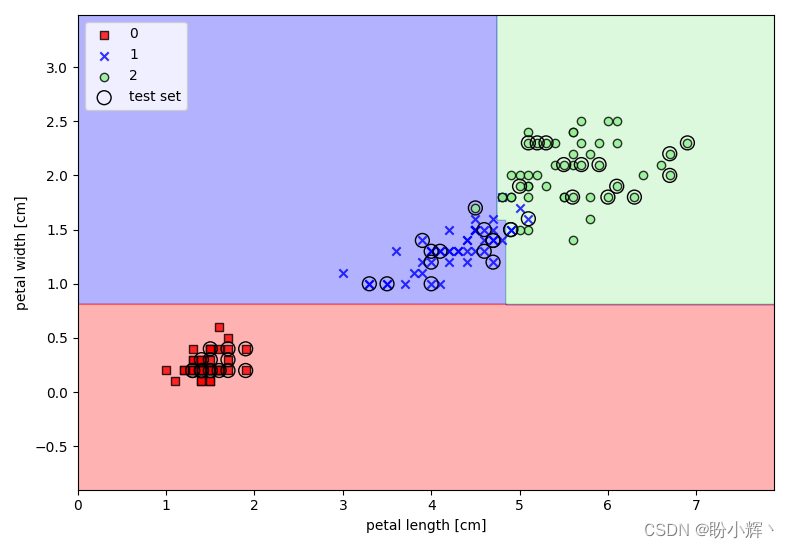
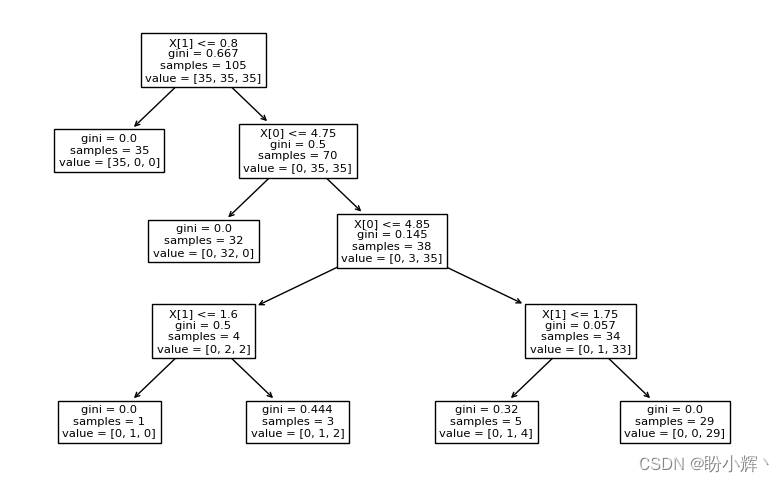
另外,我们可以在 Scikit-learn 轻松可视化训练完成后的决策树模型:
from sklearn import tree
tree.plot_tree(tree_model)
plt.show()
3.5 K近邻算法
我们将介绍的最后一个监督学习分类算法是 k 近邻 (K-nearest neighbors, KNN) 算法,它与我们之前讨论的分类算法有着根本的不同。KNN 是惰性学习 (lazy learner) 的典型例子,它之所以被称为 lazy,并不是因为它非常简单,而是因为它并不从训练数据中学习判别函数,而是记住训练数据集。KNN 算法的步骤可以总结如下:
- 选择
k值和距离度量函数 - 找到要分类的数据样本的
k最近邻 - 以多数票分配类别标签
基于所选择的距离度量函数,KNN 算法在训练数据集中找到最接近(最相似)要分类的数据样本的 k 个样本。然后,数据样本的类别标签由其 k 个最近邻居中的数量最多的类别确定。通过执行以下代码,我们使用欧几里德距离度量使用 Scikit-learn 实现 KNN 模型:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(x_train_std, y_train)
plot_decision_regions(x_combined_std, y_combined,
classifier=knn, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
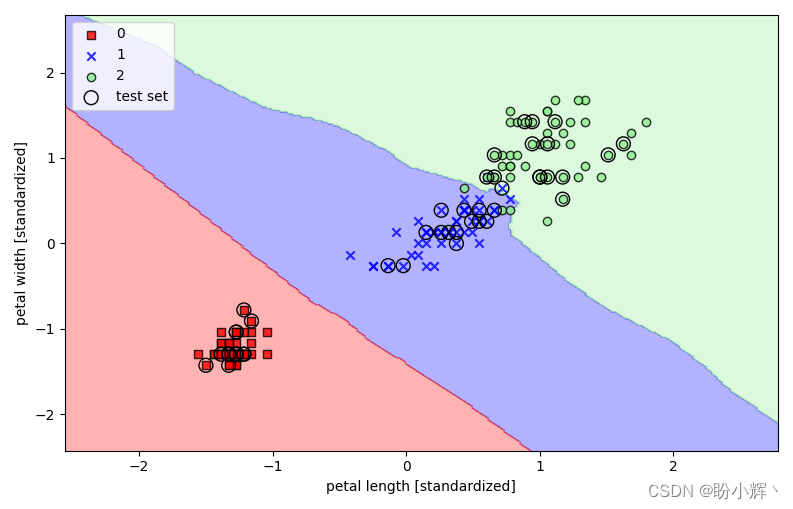
通过在 KNN 模型中指定 5 个邻居,我们可以获得一个相对平滑的决策边界,如下图所示:
3.6 线性回归
最后,我们来了解另一类监督学习算法——线性回归。线性回归的目标是对一个或多个特征与连续目标变量之间的关系进行建模。与分类任务相比,回归分析旨在预测连续输出,而不是类别标签。接下里,我们将介绍最基本的线性回归类型——简单线性回归。我们使用波士顿房价数据集,Scikit-learn 数据集中同样内置对此数据集的支持。
接下来,我们将使用最小二乘法 (Least Squares),有时也称为线性最小二乘法,估计线性回归线的参数,该线性回归线能够使与训练样本的误差之和最小,并使用梯度下降算法训练回归线参数。要查看 LinearRegressionGD 回归器的实际效果,我们选择最好特征作为自变量,并训练一个可以预测 MEDV (房价)的模型。此外,我们将标准化自变量和目标变量以更好地收敛梯度下降算法:
from sklearn import datasets
import numpy as np
from matplotlib import pyplot as plt
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.preprocessing import StandardScaler
house = datasets.load_boston() # 加载数据
x = house.data # 获取特征数据
y = house.target # 目标房价信息
# 创建标准化对象
stand_x = StandardScaler()
stand_y = StandardScaler()
# 对特征数据进行标准化处理
x_std = stand_x.fit_transform(x)
y_std = stand_y.fit_transform(y[:, np.newaxis]).flatten()
best = SelectKBest(f_regression, k=1) # 根据回归结果,选择最好特征
best_x = best.fit_transform(x_std, y) # 拟合数据得到结果
在以上代码中,y[:, np.newaxis] 中使用 np.newaxis 为数组添加了一个新维度。然后,在 StandardScaler 返回缩放后的变量后,为了方便起见,我们使用 flatten() 方法将其转换回原始的一维数组表示。接下来,我们实现线性回归类,并拟合数据:
class LinearRegressionGD(object):
def __init__(self, eta=0.001, n_iter=20):
self.eta = eta
self.n_iter = n_iter
def fit(self, x, y):
self.w_ = np.zeros(1 + x.shape[1])
self.cost_ = []
for i in range(self.n_iter):
output = self.net_input(x)
errors = (y - output)
self.w_[1:] += self.eta * x.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = (errors**2).sum() / 2.0
self.cost_.append(cost)
return self
def net_input(self, x):
return np.dot(x, self.w_[1:]) + self.w_[0]
def predict(self, x):
return self.net_input(x)
lr = LinearRegressionGD()
lr.fit(best_x, y_std)
plt.plot(range(1, lr.n_iter+1), lr.cost_)
plt.ylabel('SSE')
plt.xlabel('Epoch')
plt.show()
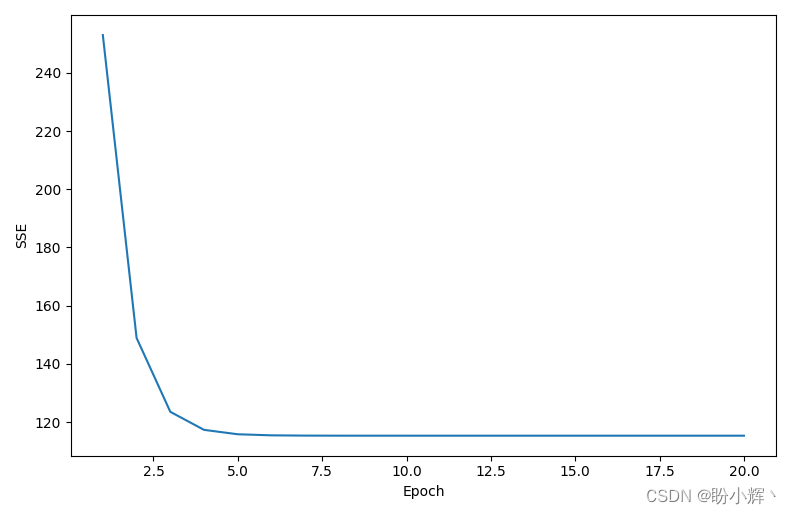
如下图所示,梯度下降算法在第 5 个 epoch 后收敛:
接下来,我们可视化线性回归线与训练数据的拟合程度。为此,我们定义一个简单的辅助函数,该函数用于绘制训练样本的散点图并添加回归线,并使用 lin_regplot 函数来绘制自变量与变量间的关系:
def lin_regplot(x, y, model):
plt.scatter(x, y, c='steelblue', edgecolor='white', s=70)
plt.plot(x, model.predict(x), color='black', lw=2)
return None
lin_regplot(best_x, y_std, lr)
plt.xlabel('Average number of rooms [RM] (standardized)')
plt.ylabel('Price in $1000s [MEDV] (standardized)')
plt.show()
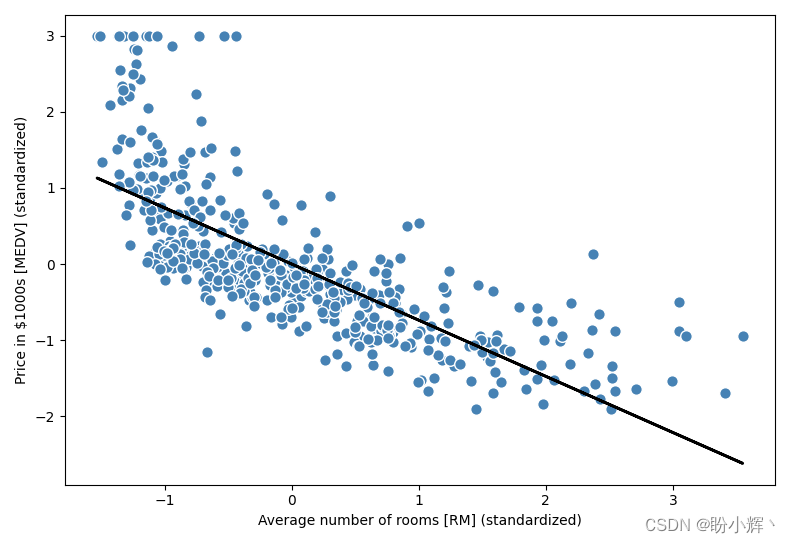
如下图所示,线性回归线反映了房价随房间数量增加的趋势:
4. 无监督学习
同样,我们可以在 Sciit-learn 库的帮助下快速训练不同的无监督机器学习算法。
4.1 KMeans 聚类
K-means 是一种基于质心的聚类方法,旨在创建 K 个簇并为其分配数据样本,以使簇内相似度高,簇间相似度低。该算法基于最小化簇内平方和:
∑ i = 0 n min μ j ∈ C ( ∣ ∣ x i − μ j ∣ ∣ 2 ) \sum ^n _{i=0}\min_{\mu_j\in C}(||x_i-\mu_j||^2) i=0∑nμj∈Cmin(∣∣xi−μj∣∣2)
该算法首先选择 K 个随机点,作为聚类的质心,然后算法进行多次迭代以对簇进行细分。在每次迭代中,对于每个数据点,算法通过计算该点与所有质心的距离来找到最近的质心,并将其分配给该簇。将所有点分配给簇后,通过计算所有点的平均值来计算新的质心。接下来,我们实现 Scikit-learn 提供的 K-means 算法。
首先,使用 sklearn.datasets 生成合成数据集:
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
x, y = make_blobs(n_samples=500, centers=5, n_features=2)
plt.scatter(x[:,0], x[:,1], edgecolor='r')
plt.show()
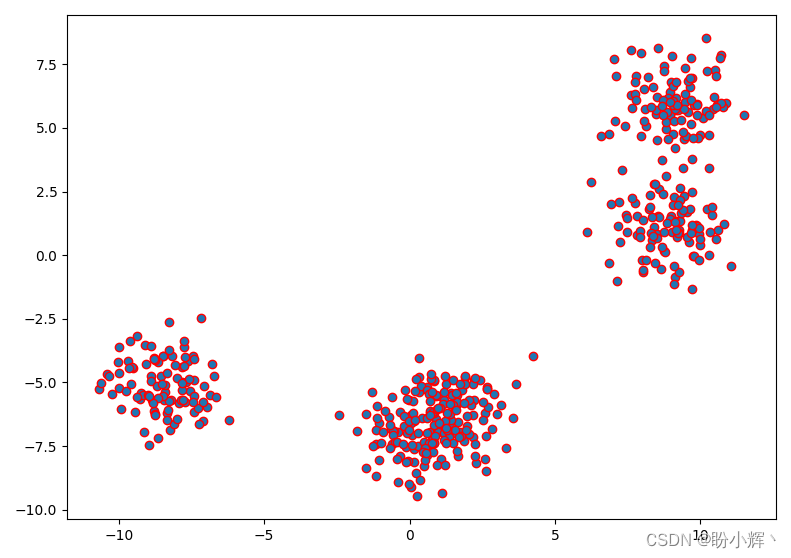
使用 K-means 聚类算法的方式与监督学习中的标准 sklearn 函数类似,从 sklearn.clustering 导入 KMeans,并根据数据集执行聚类,为每个数据样本分配聚类标签,我们可以使用 predict 方法:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=5)
kmeans.fit(x)
y = kmeans.predict(x)
y 是一个包含从 0 到 4 的一维数组,每个数字代表 KMeans 算法生成的 5 个簇中的一个簇,我们也可以获取簇中心:
print(kmeans.cluster_centers_)
输出如下:
[[ 9.10334972 5.98961671]
[-0.1189991 -7.27821318]
[-8.4565052 -5.08916993]
[ 8.85384679 1.10017216]
[ 1.56545633 -6.0570874 ]]
因为簇中心是二维数据,且有 5 个聚类中心,查看生成的簇,并根据数据样本所在的簇为它们分配不同颜色,并对簇中心进行标记:
plt.scatter(x[:,0], x[:,1], c=y)
plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], c='black', marker='+')
plt.show()
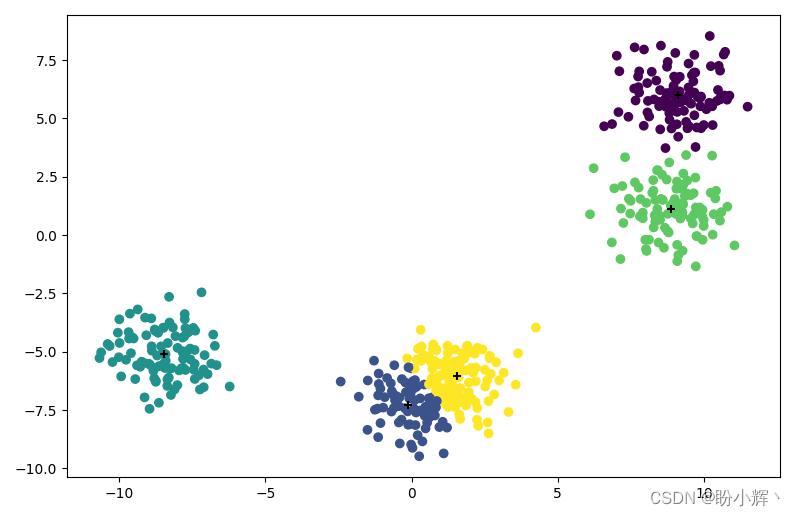
4.2 主成分分析
主成分分析 (Principal Component Analysis, PCA) 与特征选择类似,我们可以使用不同的特征提取技术来减少数据集中的特征数量。特征选择和特征提取之间的区别在于,特征选择算法保留了原始特征,特征提取将数据转换或投影到新的特征空间上,PCA 是一种特征提取技术。
特征提取可以理解为一种数据压缩方法,其目标是保留大部分相关信息,特征提取不仅用于提高算法的计算效率,还可以通过减少维度来提高预测性能。PCA 算法的原理介绍超出了本节范围。
接下来,我们使用 Scikit-learn 在 Iris 数据集中执行 PCA,并使用它从不同的角度进行可视化,我们将 Iris 数据集的四个特征分解为两个主成分特征,最后直接映射到 2D 图表上。首先,导入数据集:
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
数据集中有四列——难以进行可视化,我们可视化前三个维度简化可视化步骤,而忽略第四个维度:
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure(1, figsize=(4, 3))
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
ax.scatter(x[:, 0], x[:, 1], x[:, 2], c=y, cmap=plt.cm.nipy_spectral, edgecolor='k')
for name, label in [('Setosa', 0), ('Versicolour', 1), ('Virginica', 2)]:
ax.text3D(x[y == label, 0].mean(),
x[y == label, 1].mean() + 0.5,
x[y == label, 2].mean(), name,
horizontalalignment='center',
bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
plt.show()
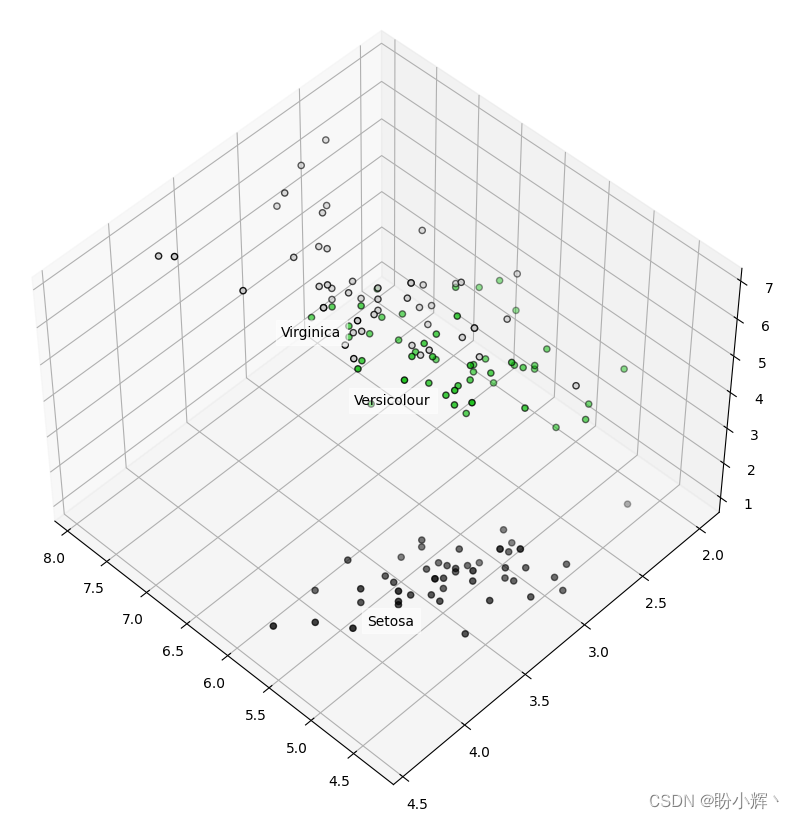
三维图能够传达出更多的信息,但缺少的第 4 维度同样可能含有更多信息。PCA 能够将数据转换为二维,同时确保保留主成分,这会将数据集转换到新的二维空间:
from sklearn import decomposition
pca = decomposition.PCA(n_components=2)
pca.fit(x)
x = pca.transform(x)
转换后可以查看 x 的前几行数据:
print(x[:5])
输出结果如下:
[[-2.68412563 0.31939725]
[-2.71414169 -0.17700123]
[-2.88899057 -0.14494943]
[-2.74534286 -0.31829898]
[-2.72871654 0.32675451]]
这里的 x 值实际上并不对应于实际的萼片、花瓣长度或宽度,而是只是新二维空间中转换得到的特征。我们可以使用 Matplotlib 将每类鸢尾花的数据点以不同的颜色进行可视化:
fig = plt.figure(figsize=(8,8))
plt.scatter(x[:,0], x[:,1], c=y, cmap=plt.cm.nipy_spectral, edgecolor='k')
for name, label in [('Setosa', 0), ('Versicolour', 1), ('Virginica', 2)]:
plt.text(x[y == label, 0].mean(),
x[y == label, 1].mean(),
name, horizontalalignment='center',
bbox=dict(alpha=0.8,edgecolor='w', facecolor='w'))
plt.show()

上图显示 Iris 数据集的 PCA 提取特征的二维散点图,可以看到转换后的特征可以更好地简化数据集。
总结
通过对于 Scikit-learn 的快速入门介绍,我们可以看到使用 Scikit-learn 库时,可以很方便的使用许多不同类型的监督或无监督的流行机器学习算法。本文是真正开始探索 Scikit-learn 的速览,通过本文的学习可以使在机器学习世界中的探索旅程变得更加容易。
系列链接

- 点赞
- 收藏
- 关注作者
评论(0)