结构化数据分析工具PandasPandas概览

Pandas是做数据分析最核心的一个工具。我们要先了解数据分析,才能更好的明白Pandas,因此,本文分为三个部分:
- 1.数据分析
- 2.Pandas概述
- 3.Pandas安装anaconda
1. 数据分析
1.1 数据分析的背景
随着计算机的大规模普及,网络数据有了一个爆发性地增长,驱使着人们进入了一个崭新的时代:大数据时代
思考一个问题
既然数据这么多,怎么才能快速地拿到有价值的数据呢?
数据分析就可以从海量数据中挖掘潜藏的有价值的信息,帮助企业或个人预测未来的趋势和行为。所以,不管从事什么行业,如果掌握了数据分析的能力,就会在其岗位上非常具有竞争力!
1.2 什么是数据分析
数据分析是使用统计分析方法对数据进行分析,从中提取有用信息和形成结论,并加以详细研究和概括总结的过程。
数据分析的目的是:将隐藏在一大批看似杂乱无章的数据信息集中提炼出来有用的数据,以找出所研究对象的内在规律。
在统计学领域中,数据分析可以划分为如下三类:
| 类目 | 描述 |
|---|---|
| 描述性数据分析 | 从一组数据中,可以摘要并且描述这份数据的集中和离散情形。 |
| 探索性数据分析 | 从海量数据中找出规律,并产生分析模型和研究假设。 |
| 验证性数据分析 | 验证科研假设测试所需的条件是否达到,以保证验证性分析的可靠性。 |
1.3 数据分析的应用场景
| 应用 | 方法及其结果 |
|---|---|
营销方面 |
通过会员卡形式获得消费者的个人信息,以便对消费者的购买信息进一步研究其购买习惯,发现各类有价值的目标群体。 |
医疗方面 |
医生通过记录和分析婴儿的心跳来监视早产婴儿和患病婴儿的情况,并针对婴儿的身体可能会出现的不适症状做出预测,这样可以帮助医生更好的救助患儿。 |
零售方面 |
在美国零售业曾经有这样一个传奇故事,某家商店将纸尿裤和啤酒并排放在一起销售,结果纸尿裤和啤酒的销量双双增长! |
网络安全方面 |
新型的病毒防御系统可以使用数据分析技术,建立潜在攻击识别分析模型,监测大量网络活动数据和相应的访问行为,识别可能进行入侵的可疑模式。 |
交通物流方面 |
用户可以通过业务系统和GPS定位系统获得数据,使用数据构建交流状况预测分析模型,有效预测实时路况、物流状况、车流量、货物吞吐量,进而提前补货,制定库存管理策略。 |
1.4 数据分析的流程
数据分析大致可以分为以下五个阶段: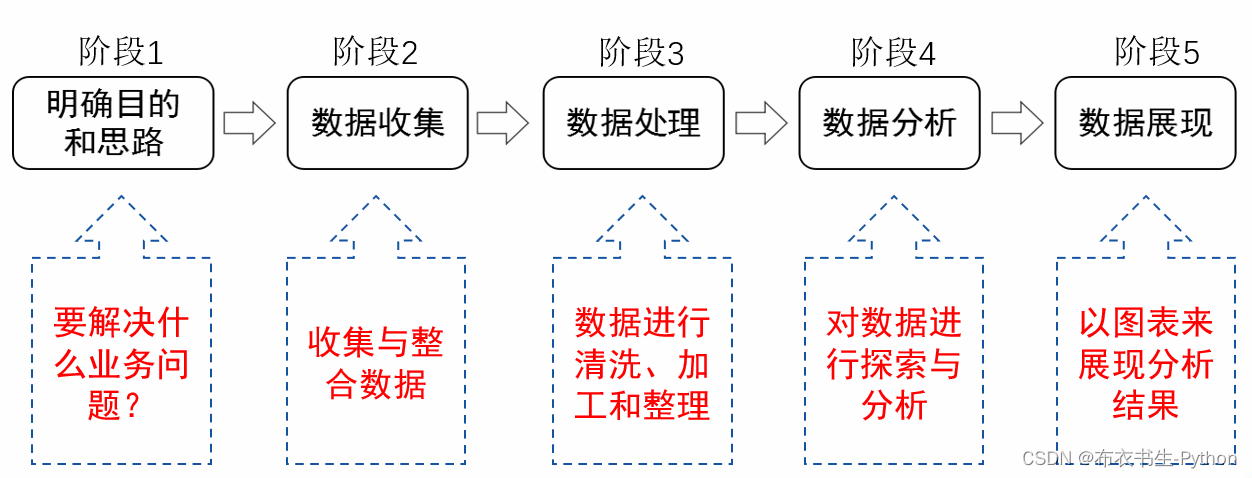
1.5 为什么选择Python做数据分析
问:
为什么选择
Python做数据分析?

答:
选择Python做数据分析,主要考虑的是Python
具有以下优势:
- 语法
简单精炼,适合初学者 - 拥有一个
巨大且活跃的科学计算社区(强大的后援团!) - 拥有强大的
通用编程能力 - 人工智能时代的通用语言
方便对接其它语言(Python是一种胶水语言)
2. Pandas概述
2.1 Pandas简介
Python本身的数据分析功能并不强,需要安装一些第三方的扩展库来增强它的能力。其中,针对结构化数据(可简单理解为二维表数据,或我们常用的Excel表格数据)分析能力最强的第三方扩展库就是Pandas
2.2 Pandas来源
Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来的,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。
2.3 Pandas 特点
Pandas是基于NumPy的一种工具包,是为解决数据分析任务而创建的。但Numpy只能处理数字,若想处理其他类型的数据,如字符串,就要用到Pandas了。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法,是使Python成为强大而高效的数据分析语言的重要因素之一。- Pandas 可以从各种文件格式比如
CSV、JSON、SQL、MicrosoftExcel导入数据。 - Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有
数据清洗和数据加工特征。 - Pandas 广泛应用在
学术、金融、统计学等各个数据分析领域。
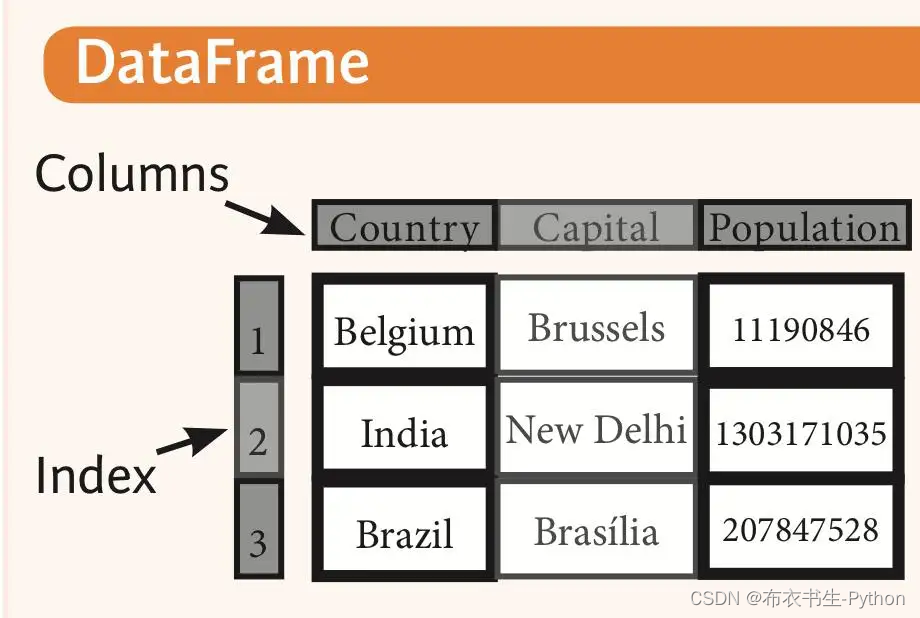
2.4 Pandas最主要的两种数据结构:
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
-
Series是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
-
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由Series 组成的字典(共同用一个索引)。

3. Pandas安装
3.1 创建新的python环境:anaconda环境
Anaconda可以简单理解为非常多的python库的集合,包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,具有一下特点:
- 包含了众多流行的科学、数学、工程和数据分析的Python库
- 完全开源和免费
- 对于学术用途,可以申请免费的License
- 全平台支持Linux、Windows、Mac OS X
当然,我们可以简单的只安装pandas,但是我们推荐数据分析的初学者安装Anaconda进行学习
在windows中安装anaconda:
(1) 在浏览器的地址栏中输入https://www.anaconda.com/download/进入Anaconda的官方网站下载,或者到历史版本中选择https://repo.anaconda.com/archive/,然后单击你电脑系统所对应版本的应用程序下载。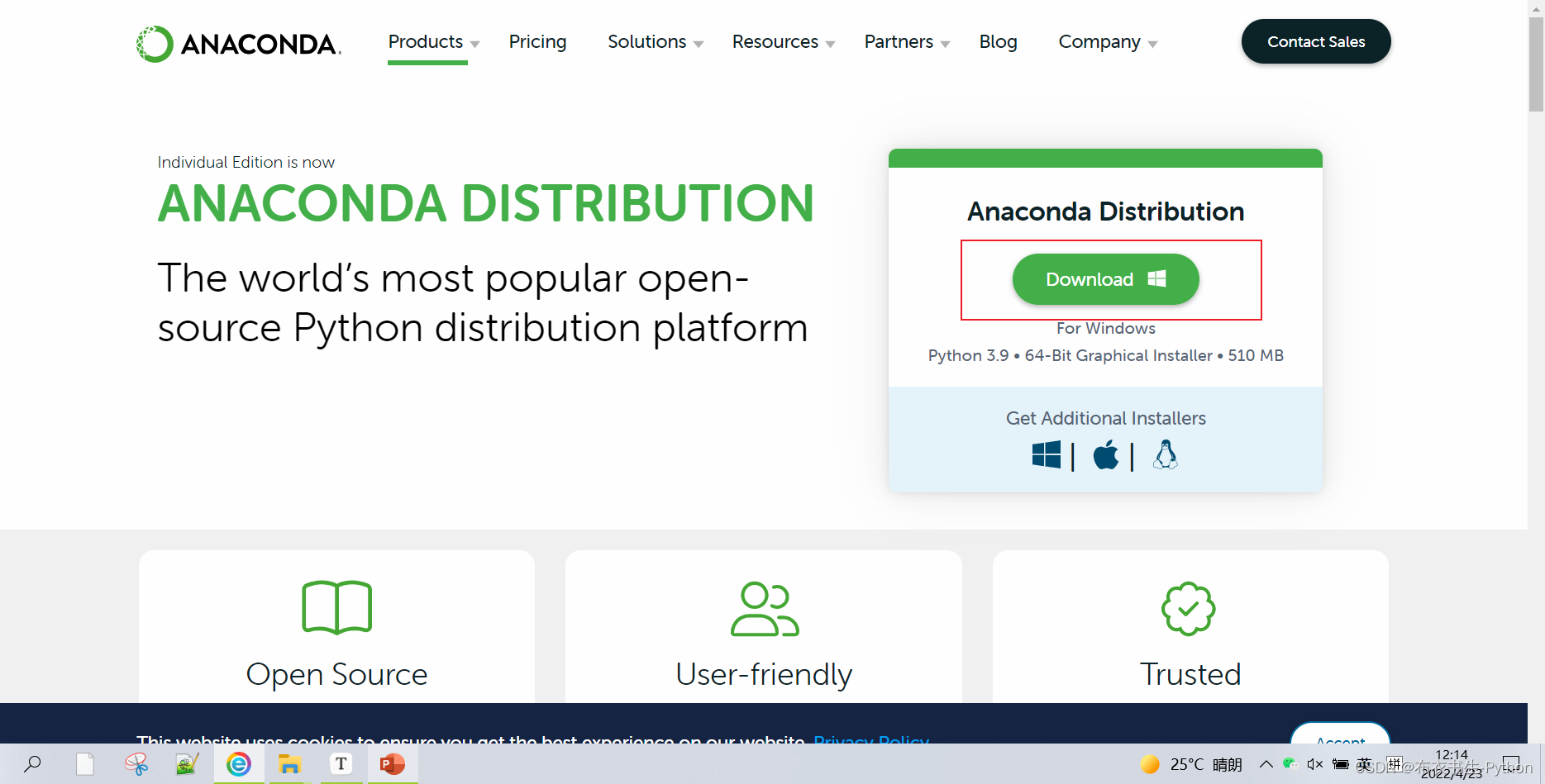
(2) 采用默认安装路径,在指定完安装路径后,点击下一步窗口会提示是否勾选如下复选框选项,两个都勾选即可。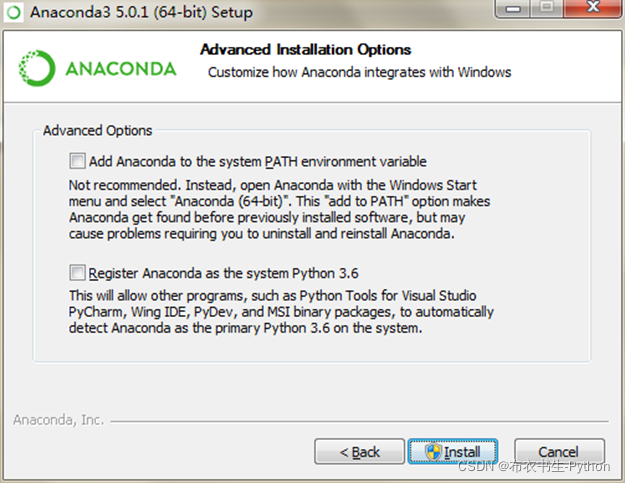
(3) 安装完以后,在系统左下角的【开始菜单】->【所有程序】中找到Anaconda3文件夹,可以看到该目录下包含了多个组件。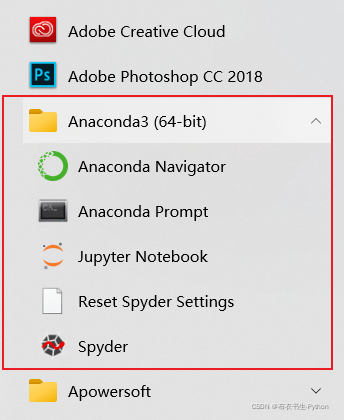
(4) Anaconda Navigator成功打开后的首页界面如下图所示。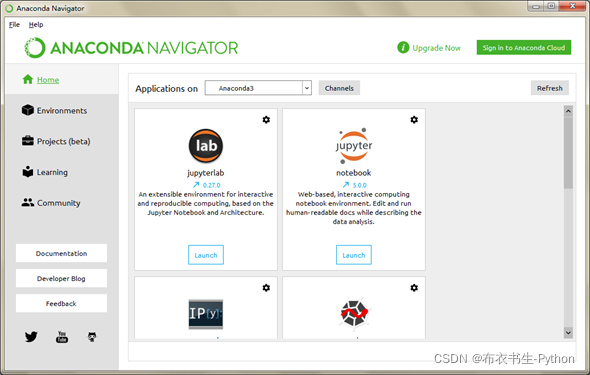
通过Anaconda管理Python包
Anaconda集成了常用的扩展包,能够方便地对这些扩展包进行管理,比如安装和卸载包,这些操作都需要依赖conda。
conda是一个在Windows、Mac OS和Linux上运行的开源软件包管理系统和环境管理系统,可以快速地安装、运行和更新软件包及其依赖项。
在Windows系统下,用户可以在Anaconda Prompt中通过命令检测conda是否被安装。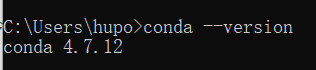
如果希望快速了解如何使用conda命令管理包,则可以在Anaconda Prompt中输入“conda -h”或“conda --help”命令来查看帮助文档。
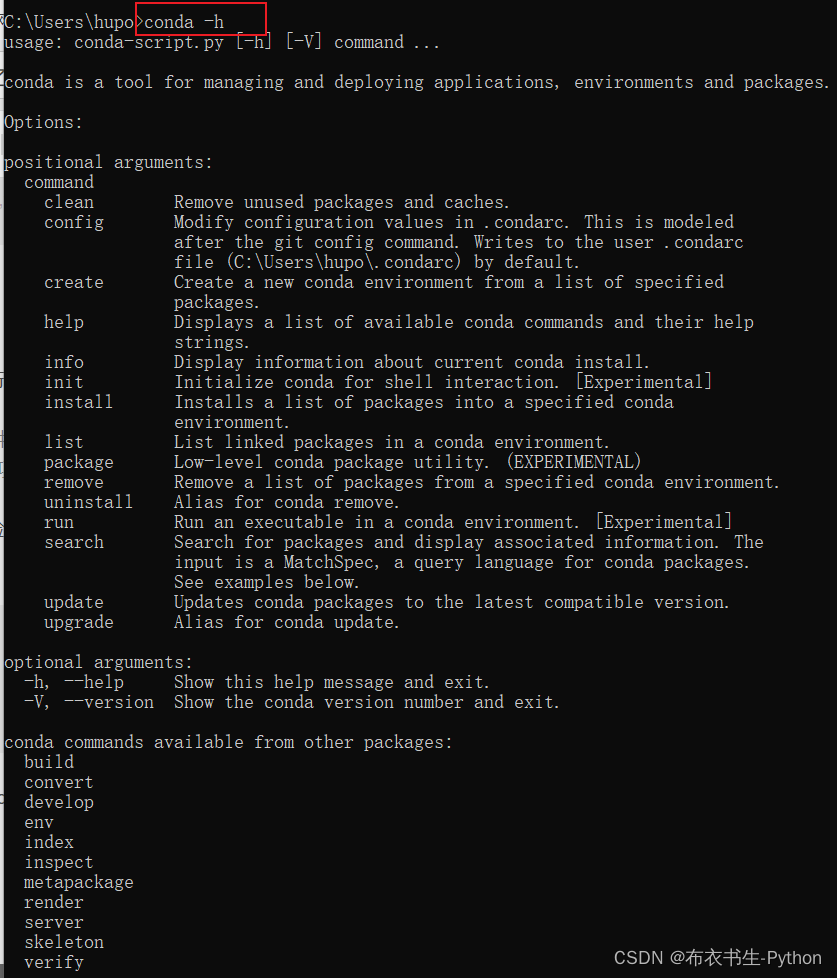
使用list命令可以获取当前环境中已经安装的包信息,执行list命令后,终端会显示当前环境下已安装的包名及版本号。
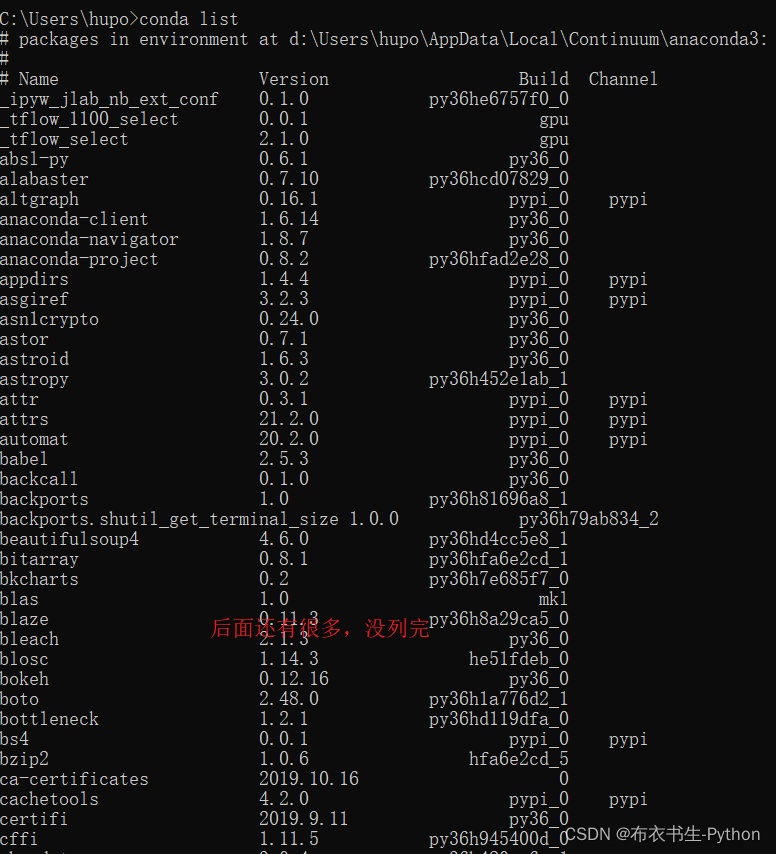
使用search命令可以查找可供安装的包,该命令中,–full-name为精确查找的参数,后面紧跟的是包的全名
>>> conda search --full-name 包的全名
例如: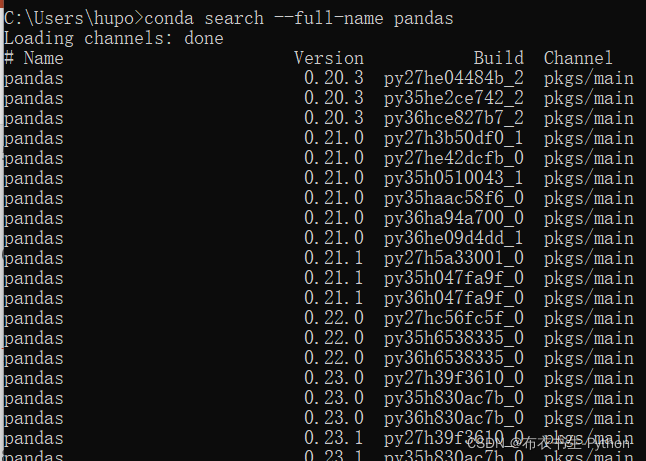
如果希望在指定的环境中进行安装,则可以在install 命令的后面显式地指定环境名称。
>>>conda install --name env_name package_name
上述命令中,env_name参数表示包安装的环境名称,package_name表示将要安装的包名称。比如: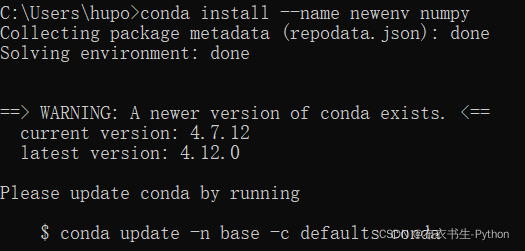
如果要在指定的环境中卸载包,则可以在指定环境下使用remove命令进行移除。
>>>conda remove --name env_name package_name
如果要卸载当前环境中的包,可以直接使用remove命令进行卸载。
更新当前环境下所有的包,可使用如下命令完成:
>>> conda update --all
如果只想更新某个包或某些包,则直接在update命令的后面加上包名即可,多个包之间使用空格隔开。
>>> conda update pandas numpy matplotlib
需要注意:
一般来说anaconda是比较大的,因为里面集成了非常多的python包,但我们如果根本不需要那么多的包,就可以安装Miniconda,它是最小的conda安装环境,只包含最基本的Python与conda以及相关的必须依赖项。对于空间要求严格的用户,Miniconda是一种选择,它只包含了最基本的库,其它的库需要自己手动安装。
3.2 启用Jupyter Notebook开发环境,并使用pandas
在“开始菜单”中打开Anaconda3目录,找到并单击“Jupyter Notebook”会弹出启动窗口,同时,系统默认的浏览器会弹出如下页面: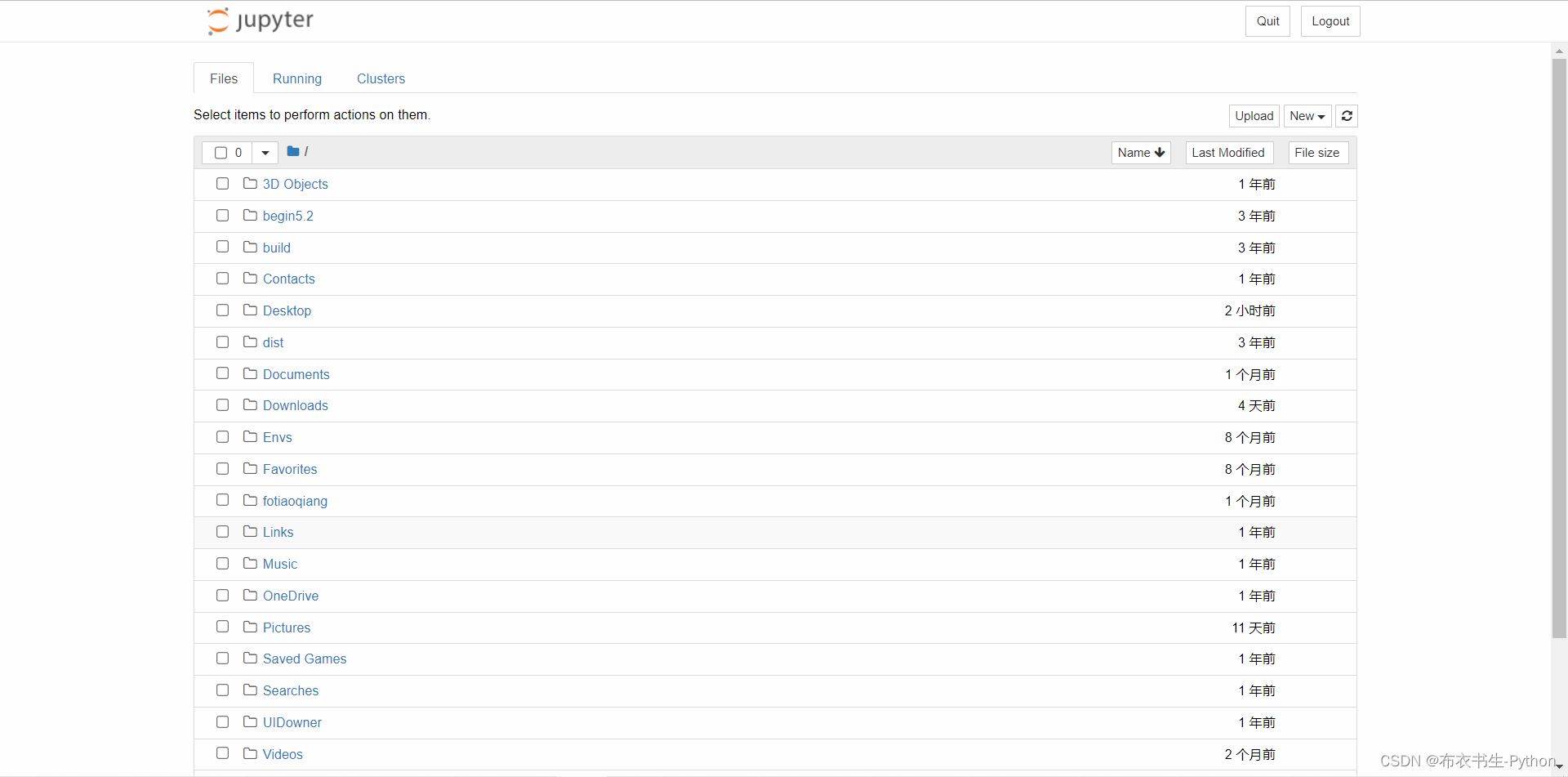
上图是浏览器中打开的Jupyter Notebook主界面,默认打开和保存的目录为C:\Users\当前用户名。
除了上述的启动方式外,还可以用命令行打开,这种方式可以控制Jupyter Notebook的显示和保存路径,是推荐的启动方式。
在主界面中单击右上方的“New”按钮,打开如图所示的下拉列表。
这里我们选择“Python 3”,创建一个基于Python 3的笔记本。
选中单元格,按下“Enter”键进入单元格的编辑模式,此时可以输入任意代码,按shift+enter执行代码: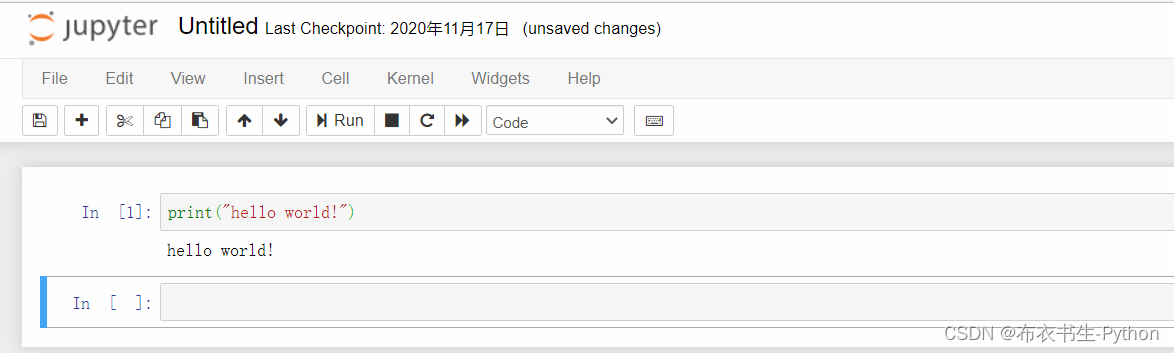
接着,在新的单元格中输入for循环代码,然后再运行,笔记本的编辑界面如下图所示: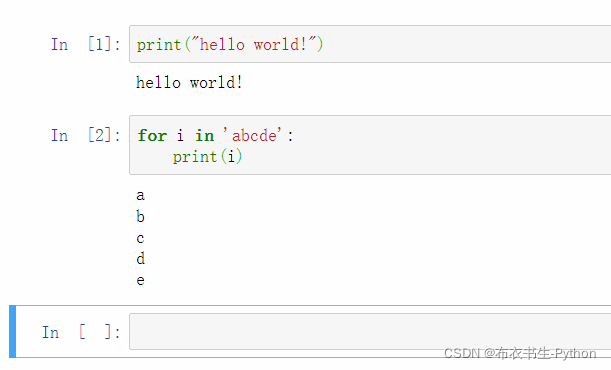
除此之外,还可以修改之前的单元格,对其重新运行。
选中最上面的单元格,单击【Insert】->【Insert Cell Above】在单元格的上方插入一个新的单元格。
也可以添加一些markdown的内容,做解释或注释用,例如: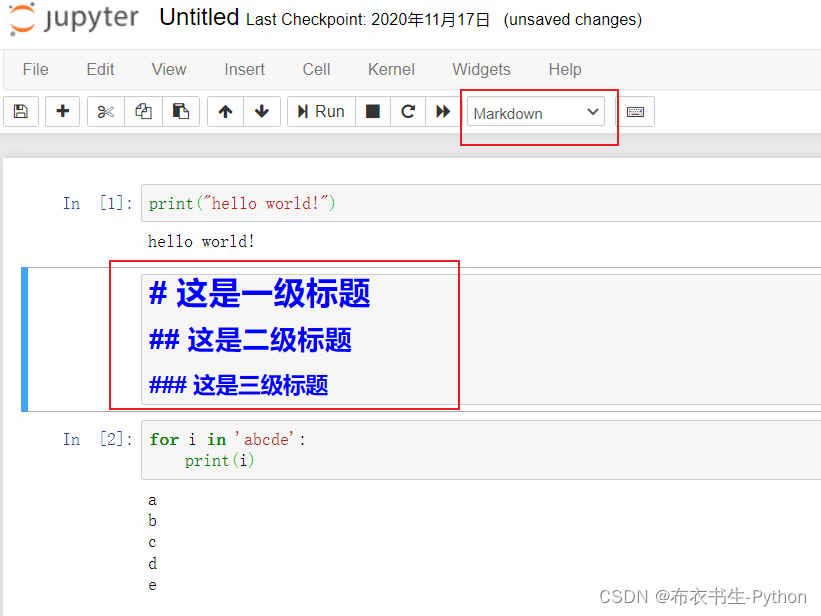
当然,还能导出很多格式,PDF、HTML等等: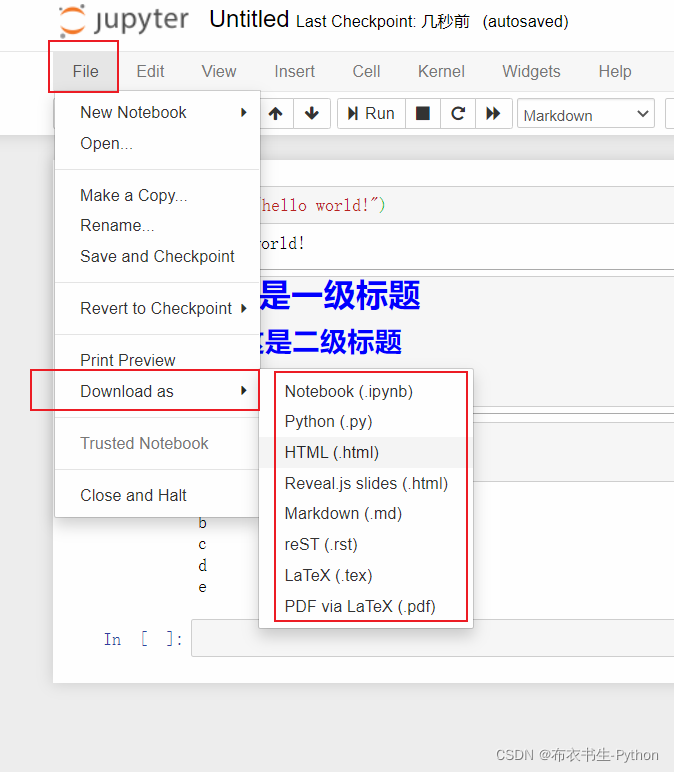
好,接下来就是使用Jupyter导入pandas模块,并创建一个series数据: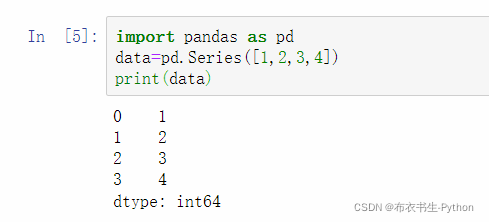
3.3 常见的数据分析工具
Python本身的数据分析功能并不强,需要安装一些第三方的扩展库来增强它的能力,常用的有:
- NumPy
- Pandas
- Matplotlib
- Seaborn
- NLTK

- 点赞
- 收藏
- 关注作者
评论(0)