Linux基本命令实现Makefile

1.linux下查看进程占用cpu的情况(top);
格式
top [-] [d delay] [q] [c] [S] [s] [i] [n]
主要参数
- d:指定更新的间隔,以秒计算。
- q:没有任何延迟的更新。如果使用者有超级用户,则top命令将会以最高的优先序执行。
- S:累积模式,会将己完成或消失的子行程的CPU时间累积起来。
- s:安全模式。
- n:显示更新的次数,完成后将会退出top。

在图1中,第一行表示的项目依次为当前时间、系统启动时间、当前系统登录用户数目、平均负载(最近一分钟,五分钟和十五分钟的系统负载。load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。)。第二行显示的是所有启动的进程、目前运行的、挂起(Sleeping)的和无用(Zombie)的进程。
第三行,cpu状态信息,具体属性说明如下: - 5.9%us — 用户空间占用CPU的百分比。
- 3.4% sy — 内核空间占用CPU的百分比。
- 0.0% ni — 改变过优先级的进程占用CPU的百分比
- 90.4% id — 空闲CPU百分比
- 0.0% wa — IO等待占用CPU的百分比
- 0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
- 0.2% si — 软中断(Software Interrupts)占用CPU的百分比
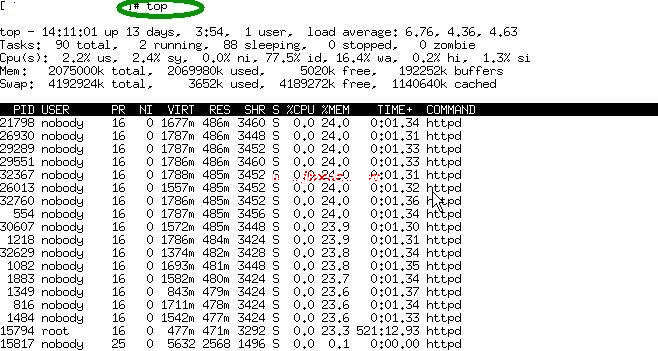
第四行显示物理内存的使用情况,包括总的可以使用的内存、已用内存、空闲内存、缓冲区占用的内存。
第五行显示交换分区使用情况,包括总的交换分区、使用的、空闲的和用于高速缓存的大小。对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
- PID — 进程id
- USER — 进程所有者
- PR — 进程优先级
- NI — nice值。负值表示高优先级,正值表示低优先级
- VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR — 共享内存大小,单位kb
- S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
- %CPU — 上次更新到现在的CPU时间占用百分比
- %MEM — 进程使用的物理内存百分比
- TIME+ — 进程使用的CPU时间总计,单位1/100秒
- COMMAND — 进程名称(命令名/命令行)
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
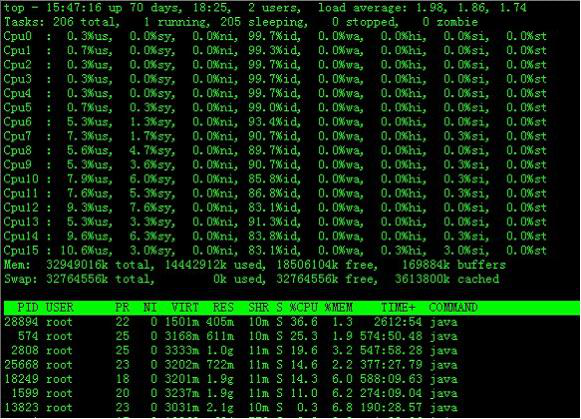
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。再按数字键1,就会返回到top基本视图界面。
高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
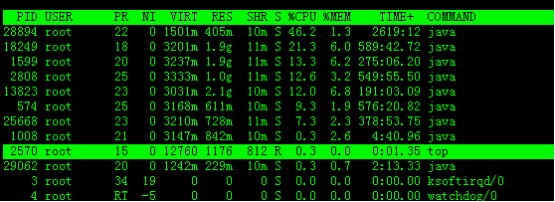
我们发现进程id为2570的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
##2.查看内存使用情况free
free命令用来显示内存的使用情况,使用权限是所有用户。
格式
free [-b-k-m] [-o] [-s delay] [-t] [-V]
主要参数
- -b -k -m:分别以字节(KB、MB)为单位显示内存使用情况。
- -s delay:显示每隔多少秒数来显示一次内存使用情况。
- -t:显示内存总和列。
- -o:不显示缓冲区调节列。
应用实例
free命令是用来查看内存使用情况的主要命令。和top命令相比,它的优点是使用简单,并且只占用很少的系统资源。通过-S参数可以使用free命令不间断地监视有多少内存在使用,这样可以把它当作一个方便实时监控器。
#free -b -s5
使用这个命令后终端会连续不断地报告内存使用情况(以字节为单位),每5秒更新一次。
##3.linux下查看目录(ls);
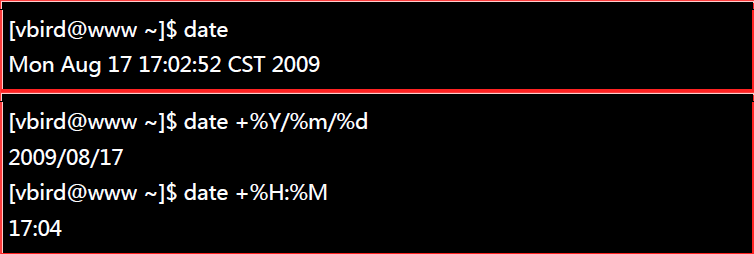
##4.显示日期的指令: date
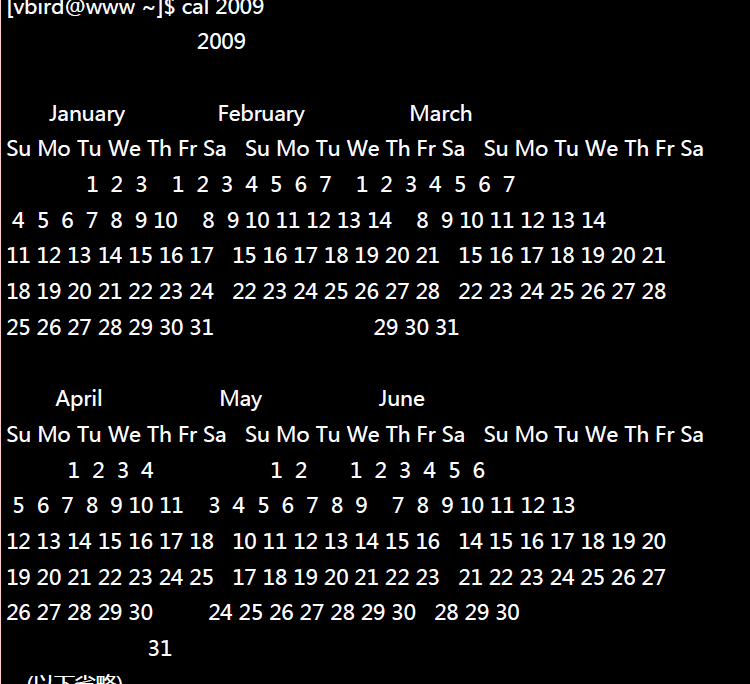
##5.显示日历的指令:cal

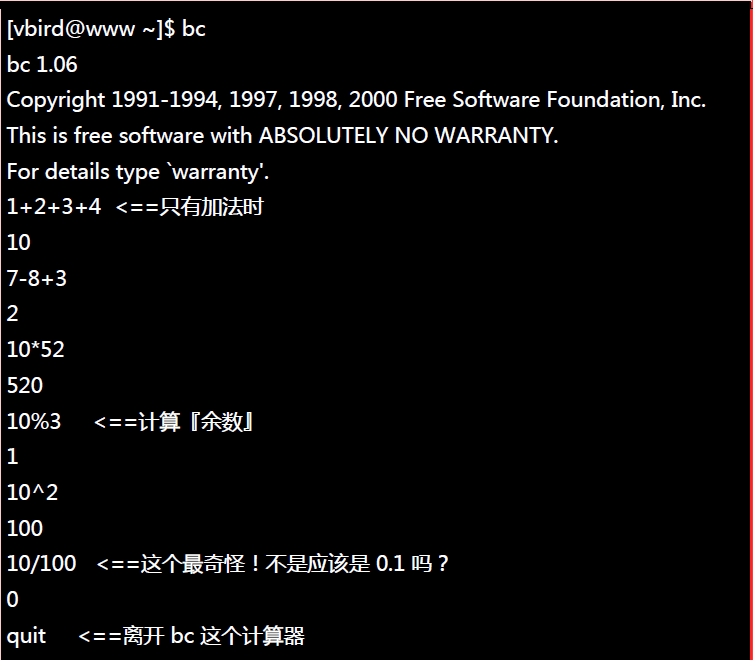
##5.1简单好用的计算器:bc
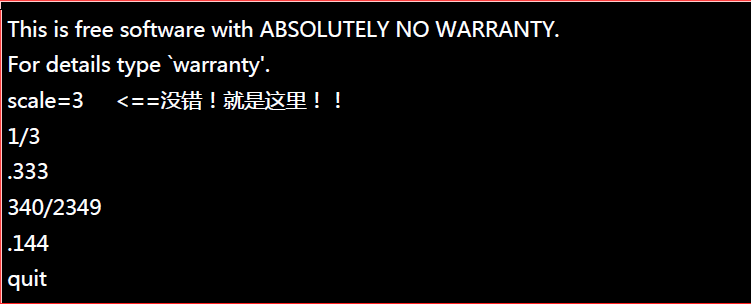
怎么10/100会变成0呢?这是因为bc预设仅输出整数,如果要输出小数点下位数,那么就必须要执行 scale=number ,那个number就是小数点位数,例如:
##数据同步写入磁盘: sync
输入sync,在内存中尚未被更新的数据就会被写入硬盘中;所以,这个指令在系统关机重新启动之前很重要!最好多执行几次!
##7.惯用的关机指令:shutdown

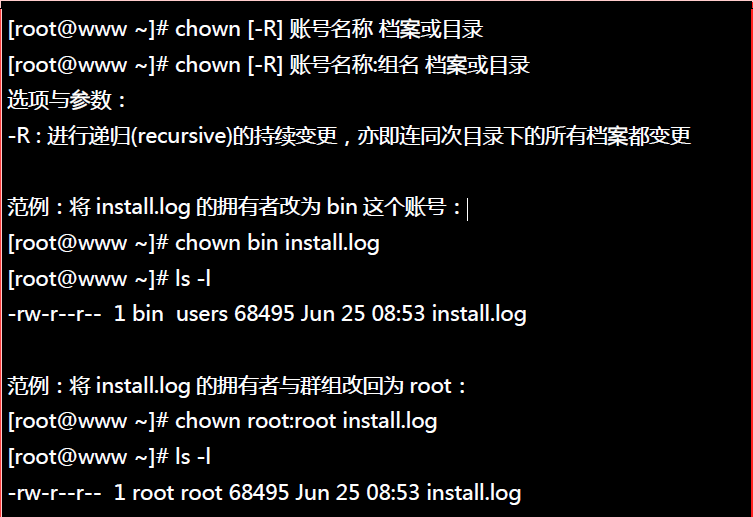
##8.改变文件拥有者:chown
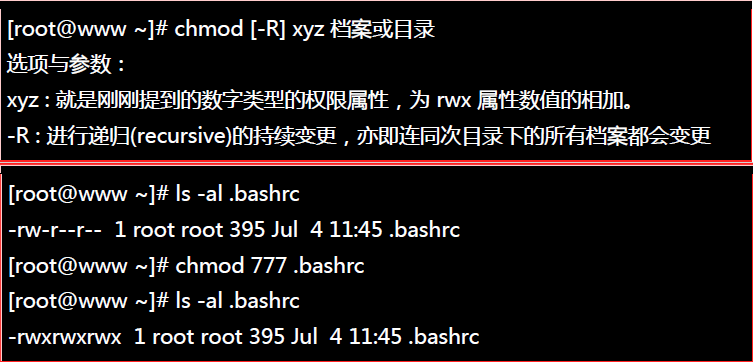
##9.改变文件的权限:chmod
权限的设定方法有两种, 分别可以使用数字或者是符号来进行权限的变更。
–数字类型改变档案权限:
##10.变换目录:cd

##11.显示当前所在目录:pwd

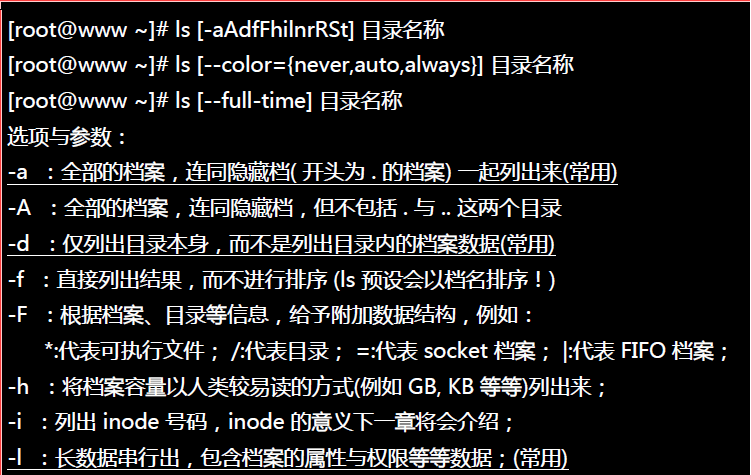
##12.档案与目录的显示:ls
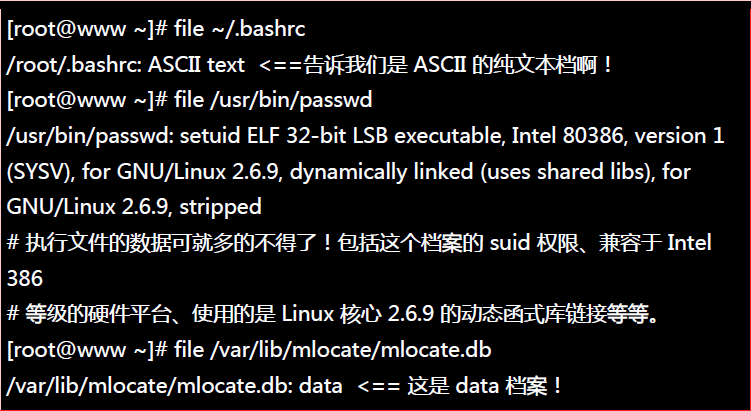
##13.观察文件类型:file
##14. 网络操作命令:ifconfig、ip、ping、netstat、telnet、ftp、route、rlogin、rcp、finger。
netstat 查看网络信息
telnet命令通常用来远程登录。telnet程序是基于TELNET协议的远程登录客户端程序。Telnet协议是TCP/IP协议族中的一员,是Internet远程登录服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。
telnet 192.168.120.209
##15.终止当前执行命令 ctrl+c
##16.打开终端: ctrl+alt+t;关闭当前终端:exit
##vi编辑器命令
三种工作模式:输入模式、命令模式、底行命令模式。三种模式转换方式如下:
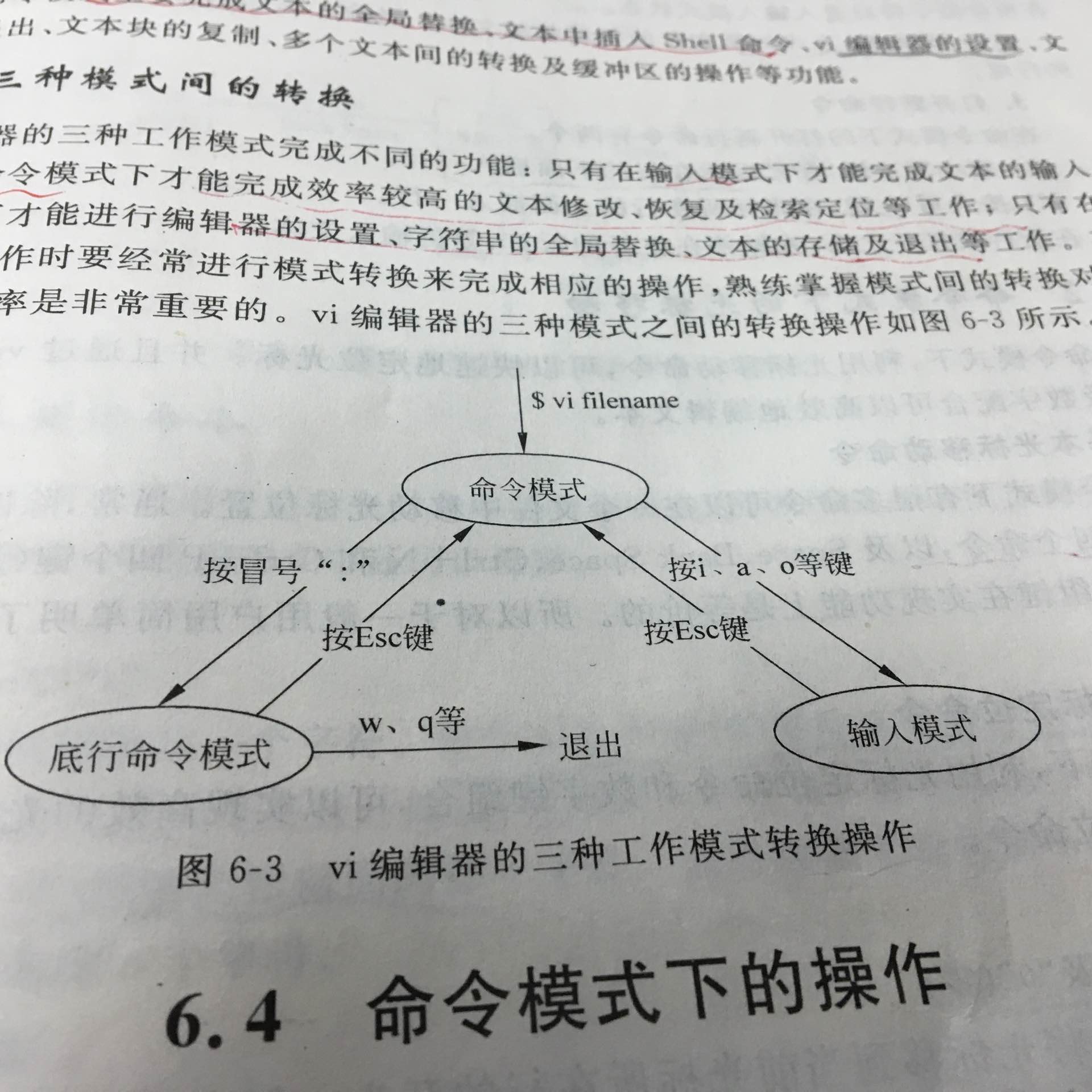
- i键–光标之前插入
- I键–光标所在行的行首插入
- a键-- 光标之后插入
- A键–光标所在行的行尾插入
- o键–光标所在行的下一行插入
- O键–光标所在行的上一行插入
- x键–删除光标所在字符
- X键–删除光标前面的字符
- dd–删除光标所在的整行
- u键–取消最近的一次操作
- U键–取消所有的操作
底行命令
- :set number 显示正文行号
- :set autoindent 设置正文自动缩进
文件间的文本移动(前提:目标文件已存在)
- :1,5 w filename
- :1,5 w >> filename
文本块移动
- :1,3 m 7
按行复制
- :1,3 co . 将1-3行复制到光标所在位置
- :1.3 co 7 将1-3行复制到第7行
编辑多个文件
- vi m1.c m2.c m3.c
编辑下一个文件
- : n
跳跃式编辑
- : e m3.c
返回刚才编辑的文件
- :e #
- :wq 存盘后退出
- :q 若无修改直接退出
- :w filename 另存为
- :w 将编辑缓冲区的文件写入编辑的文件中
- :q! 强制退出,丢弃缓冲区内容
##注 makefile
makefile关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。
makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
一般来说,无论是C、C++、还是pas,首先要把源文件编译成中间代码文件,在Windows下也就是 .obj 文件,UNIX下是 .o 文件,即 Object File,这个动作叫做编译(compile)。然后再把大量的Object File合成执行文件,这个动作叫作链接(link)。
编译时,编译器需要的是语法的正确,函数与变量的声明的正确。对于后者,通常是你需要告诉编译器头文件的所在位置(头文件中应该只是声明,而定义应该放在C/C++文件中),只要所有的语法正确,编译器就可以编译出中间目标文件。一般来说,每个源文件都应该对应于一个中间目标文件(O文件或是OBJ文件)。
链接时,主要是链接函数和全局变量,所以,我们可以使用这些中间目标文件(O文件或是OBJ文件)来链接我们的应用程序。链接器并不管函数所在的源文件,只管函数的中间目标文件(Object File),在大多数时候,由于源文件太多,编译生成的中间目标文件太多,而在链接时需要明显地指出中间目标文件名,这对于编译很不方便,所以,我们要给中间目标文件打个包,在Windows下这种包叫“库文件”(Library File),也就是 .lib 文件,在UNIX下,是Archive File,也就是 .a 文件。
总结一下,源文件首先会生成中间目标文件,再由中间目标文件生成执行文件。在编译时,编译器只检测程序语法,和函数、变量是否被声明。如果函数未被声明,编译器会给出一个警告,但可以生成Object File。而在链接程序时,链接器会在所有的Object File中找寻函数的实现,如果找不到,那到就会报链接错误码(Linker Error).
新建文件 vi、vim、touch
假设我们有下面这样的程序:
/*main.c*/
#include "mytool1.h"
#include "mytool2.h"
#include <stdio.h>
int main(int argc,char *argv[])
{
mytool1_print("hello");
mytool2_print("hello");
}
/*mytoo1.h*/
#ifndef _MYTOOL1_H
#define _MYTOOL1_H
void mytool1_print(char *print_str);
#endif
/*mytool1.c*/
#include "mytool1.h"
void mytool1_print(char *print_str)
{
printf("This is mytool1 print %s\n",print_str);
}
/*mytool2.h*/
#ifndef _MYTOOL2_H
#define _MYTOOL2_H
void mytool2_print(char *print_str);
#endif
/*mytool2.c*/
#include "mytool2.h"
void mytool2_print(char *print_str)
{
printf("This is mytool2 print %s\n",print_str);
}
我们可以这么编译链接这个程序:
gcc -c main.c
gcc -c mytool1.c
gcc -c mytool2.c
gcc -o myprint main.o mytool1.o mytool2.o
这样之后只需执行命令"./myprint",便可以简单的运行这个程序。
但是当我们修改了其中的一个文件之后是不是还要不厌其烦的输入上面的编译命令?
为了解决这一问题,我们有个好方法去解决,那就是编写一个makefile文件,用make命令去编译上面的程序。
执行命令"vim Makefile”
编写如下代码:
main: main.o mytool1.o mytool2.o
[Tab]gcc -o myprint main.o mytool1.o mytool2.o
main.o: main.c mytool1.h mytool2.h
[Tab]gcc -c main.c
mytool1.o: mytool1.c mytool1.h
[Tab]gcc -c mytool1.c
mytool2.o: mytool2.c mytool2.h
[Tab]gcc -c mytool2.c
保存后执行命令“make -f Makefile”
这样也可以生成一个可执行程序。
有了这个Makefile文件之后,无论我们修改什么地方,只要make一些这个文件,就可以轻松的生成可执行文件。
在Makefile中#开始的行为注释行,此文件的一般格式为:
(target目标):(components依赖对象)
【Tab制表符按键】(rule规则)
第一行为依赖关系,比如上面那个Makefile文件的第一行,我们的目标main的依赖对象为main.o、mytool1.o和mytool2.o
第二行为执行规则,当依赖的对象在目标修改后修改的话,就要执行规则这一行所指定的命令,注意,这一行开头必须是Tab键。
上面的make里的-f参数表示寻找到名为Makefile的文件进行make,因为make只能自动识别名为makefile或者Makefiile两个文件,如果你编译的makefile文件名为my_makefile的话,就需要加上-f参数,否则make无法找到你指定的my_makefile文件。
此外,makefile里面还有三个非常有用的变量:$@(目标文件)、$^(所有的依赖文件)和$<(第一个依赖文件)
如果使用这三个变量,我们的Makefile文件可以简化为:
main: main.o mytool1.o mytool2.o
[Tab]gcc -o $@ $^
main.o: main.c mytool1.h mytool2.h
[Tab]gcc -c $<
mytool1.o: mytool1.c mytool1.h
[Tab]gcc -c $<
mytool2.o: mytool2.c mytool2.h
[Tab]gcc -c $<

- 点赞
- 收藏
- 关注作者
评论(0)