经典/最新计算机视觉论文及代码推荐

今日推荐几篇最新/经典计算机视觉方向的论文,涉及诸多方面,其中多篇都是CVPR2021录用的文章,具体内容详见论文原文和代码链接。
人体姿态估计
- 论文题目:Deep Dual Consecutive Network for Human Pose Estimation
- 论文链接:https://arxiv.org/abs/2103.07254
- 代码链接:https://github.com/Pose-Group/DCPose
在本文中,我们提出了一种新的多帧人体姿势估计框架,利用视频帧之间丰富的时间线索来改进关键点检测。在我们的框架中设计了三个模块化组件。姿势-时间合并对关键点时空上下文进行编码以生成有效的搜索范围,而姿势-残差融合模块计算双向加权姿势残差。然后通过我们的姿势校正网络对这些进行处理,以有效地细化姿势估计。我们的方法在大规模基准数据集PoseTrack2017和PoseTrack2018的多帧人姿势估计挑战中排名第一,论文主要结构如下:
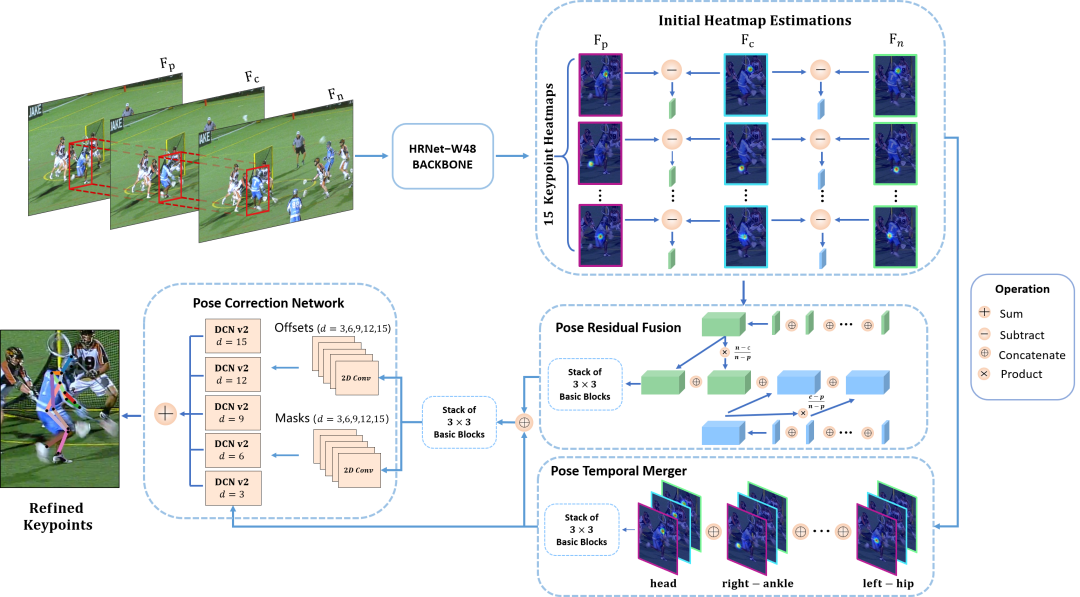
![]()
实例感知的人类可表示学习
-
论文题目:Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing
-
论文链接:https://arxiv.org/pdf/2103.04570.pdf
-
代码链接:https://github.com/tfzhou/MG-HumanParsing
为了解决具有实例感知的人体部分解析这一具有挑战性的任务,提出了一种新的自底向上机制,以联合和端到端的方式学习类别级人体语义分割和多人位姿估计。它是一个紧凑、高效和强大的框架,可以利用不同粒度的结构信息,并减轻人员划分的困难。具体而言,通过网络特征金字塔学习并逐步改进密集到稀疏的投影场,该投影场允许显式地将密集的人类语义与稀疏的关键点相关联,以增强鲁棒性。然后,将困难的像素分组问题转化为更简单的多人联合装配任务。通过将联合关联表示为最大权重二部匹配,提出了一种利用投影梯度下降和Dykstra循环投影算法的可微解。这使得我们的方法可以进行端到端的训练,并允许分组错误的反向传播来直接监督多粒度人类表示学习。

一种用于航空目标检测的旋转检测器
-
论文题目:Camera-Space Hand Mesh Recovery via Semantic Aggregation
and Adaptive 2D-1D Registratio
-
论文链接:https://arxiv.org/pdf/2103.02845.pdf
-
代码链接:https://github.com/SeanChenxy/HandMesh

我们将相机空间网格恢复分为两个子任务,即根相对网格恢复和根恢复。首先,从单个输入图像中提取关节标注和轮廓,为3D任务提供2D线索。在根相关网格恢复任务中,我们利用关节之间的语义关系从提取的2D线索生成3D网格。此类生成的三维网格坐标相对于根位置(即手的手腕)表示。在根恢复任务中,通过将生成的3D网格与2D线索对齐,将根位置注册到摄影机空间,从而完成cameraspace 3D网格恢复。论文所提出的主要框架如下所示:
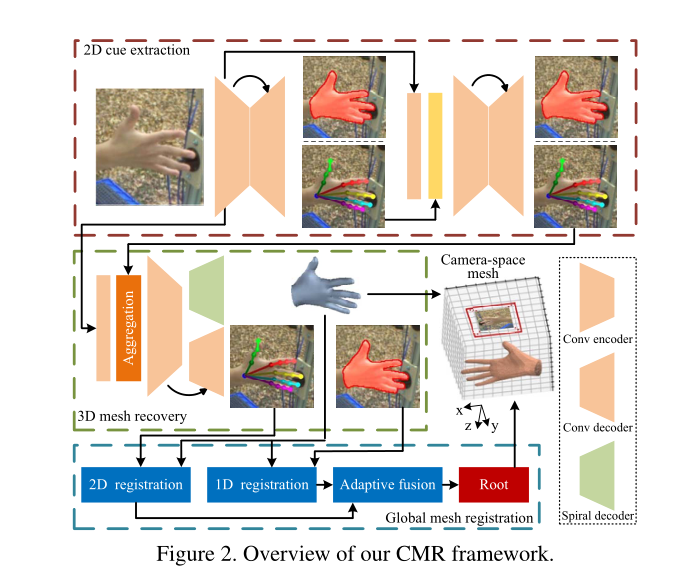
后续
下一期最新/经典视觉论文敬请期待!
文章来源: blog.csdn.net,作者:小小谢先生,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/xiewenrui1996/article/details/125773905

- 点赞
- 收藏
- 关注作者
评论(0)