RabbitMQ 3.8 特性聚焦:仲裁队列(Quorum Queues)

翻译自:https://www.cloudamqp.com/blog/rabbitmq-quorum-queues.html,写于 2019-03-28
RabbitMQ 3.8 版本中最重要的改动那非仲裁队列(Quorum Queues)莫属。它提供队列复制的能力,保障数据的高可用和安全性。使用仲裁队列可以在 RabbitMQ 节点间进行队列数据的复制,从而达到在一个节点宕机时,队列仍然可以提供服务的效果。
其实 RabbitMQ 已经有一个高可用队列的实现,那就是镜像队列(Mirror Queues)。在 RabbitMQ 3.8 版本问世之前,镜像队列是实现数据高可用的唯一手段,但是它有一些设计上的缺陷,这也是 RabbitMQ 提供仲裁队列的原因。
镜像队列的设计缺陷
镜像队列主要的问题是消息同步的性能。由于使用了一种低效的消息复制方法,镜像队列的性能会比较低下。
镜像队列会选择一个主队列和多个从队列,主队列会将自己接收的读、写请求同步给所有从队列。当所有的从队列保存消息之后,主队列才会向生产者发送确认。如果主队列挂掉,其中一个从队列会晋升成主队列,让整个镜像队列仍然保持可用,避免消息丢失。
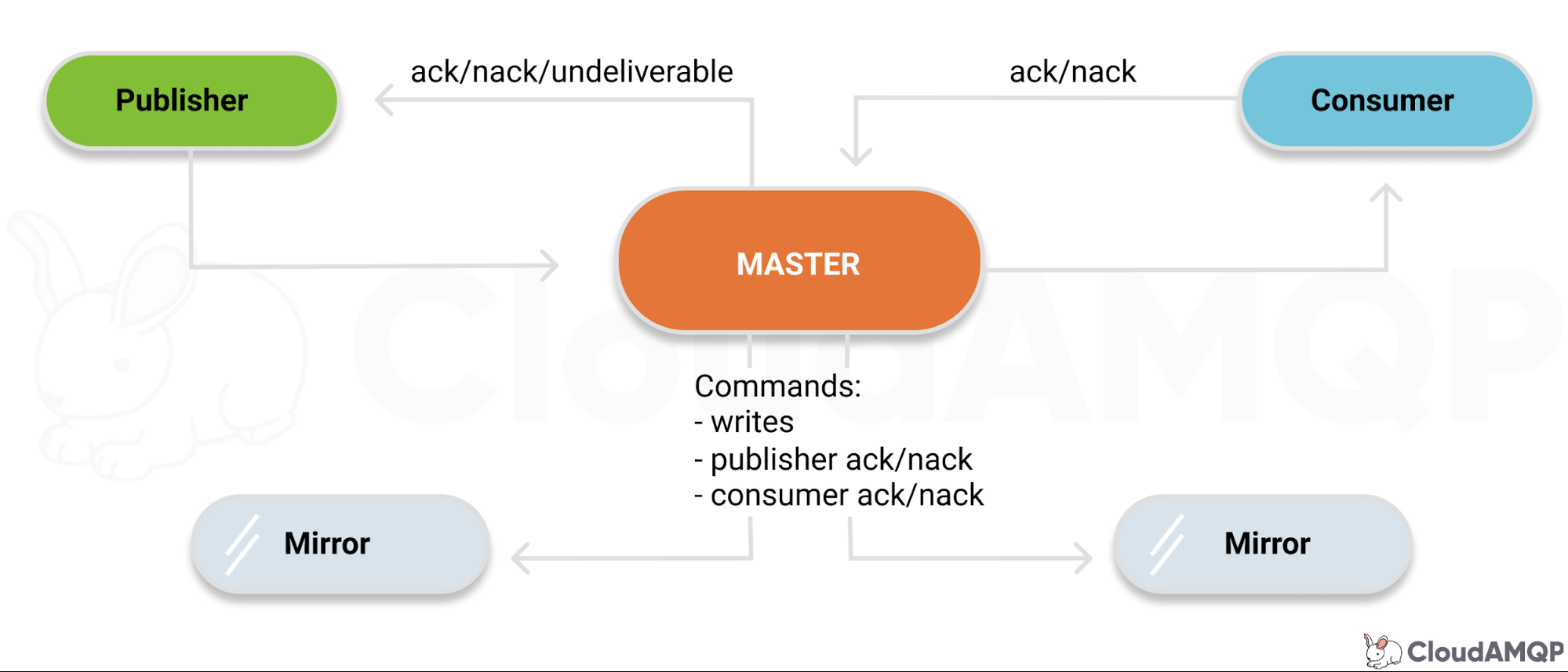
当你有多个镜像队列时,主队列和从队列会分布在集群的不同节点上,每个节点可以承载多个主队列和从队列。
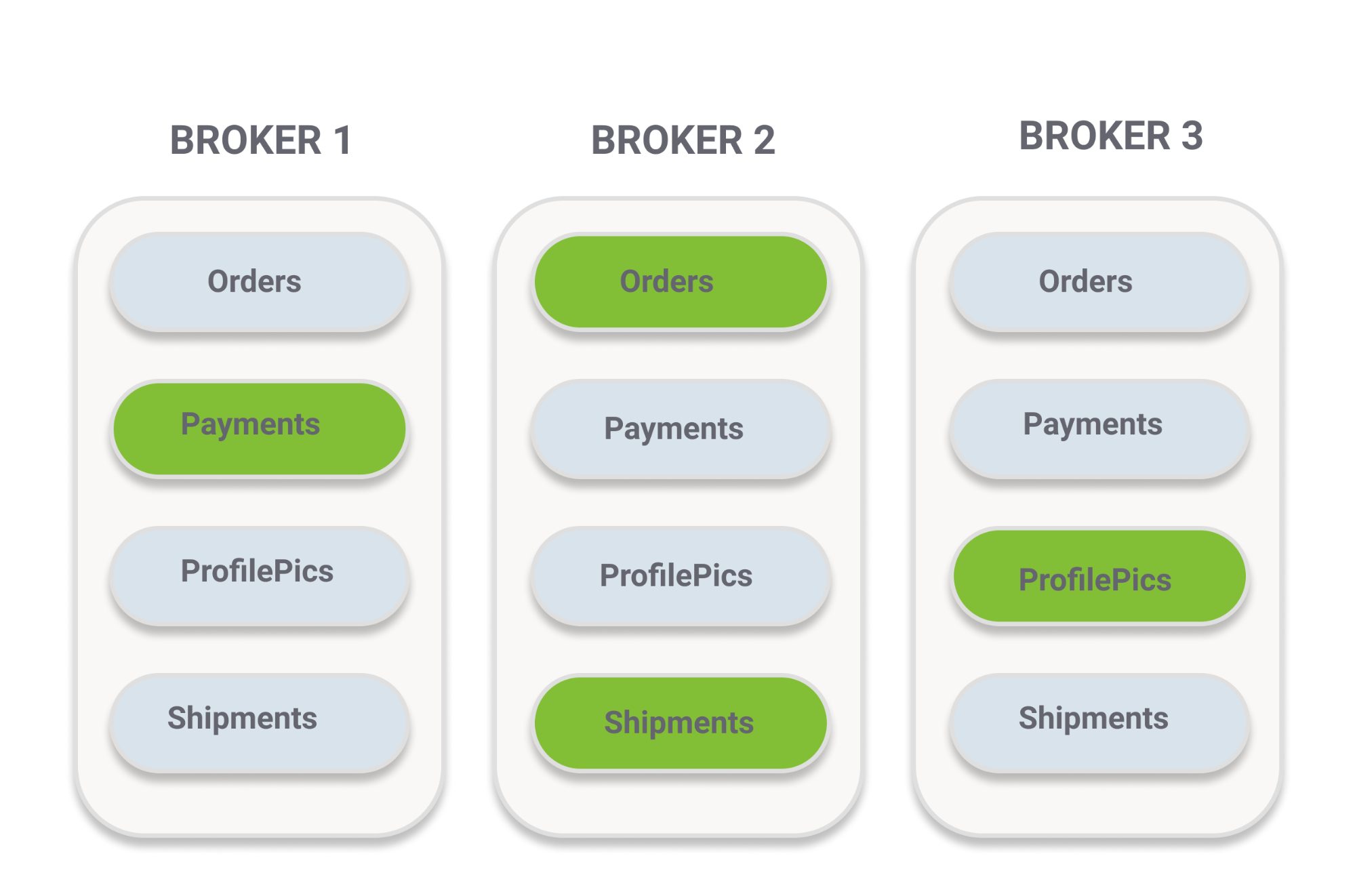
所有问题的源头来自于节点的宕机。当一个节点下线,然后恢复上线之后,它保存的所有从队列的镜像数据都会丢失。这就是第一个致命的设计缺陷。此时从队列重新上线,但是它是空的,运维人员必须做出选择,是否要将数据同步到这个队列。如果选择同步,那么就意味着要将当前所有的消息从主队列同步到从队列。
这引出了第二个致命的设计缺陷:同步是阻塞的,它会让整个队列不可用。通常情况下,如果生产和消费的速度能够基本匹配,那么队列应该是没有消息堆积或者堆积非常少的,这样同步只会阻塞很短的时间。但是有时有些队列有时会存在大量堆积,可能是由于故意设计成这样,也可能是因为消费端或者下游服务非常慢或者挂掉,但是上游生产者仍然不停生产消息。
如果队列的堆积少,那么同步的影响就比较小,同步很快结束,然后生产者可以重试之前阻塞的时候生产失败的消息。但是如果队列的消息堆积量很大,同步的影响就会抱很大,可能要消耗几分钟、几小时或者更多时间去同步消息,不仅如此,同步还会消耗内存,导致内存相关的问题,甚至可能造成节点需要重启。
所以运维有时就不会选择进行消息同步,仅仅让新的消息复制到这个重新上线的镜像队列,老的消息不进行同步。但是这样的话会让消息丢失的风险增加。
这个问题同样使节点的滚动升级存在很大的隐患,因为在滚动升级时,节点的重启会丢失所有数据,需要进行数据的同步或者恢复。
仲裁队列——下一代高可用队列
仲裁队列旨在解决镜像队列的性能和同步问题。但是相对的,它没有包含队列的所有功能,并且有它自己的局限性。所以在仲裁队列和镜像队列之间的选择不是一个容易的事情。
Raft 共识协议逐渐成为了工业上大量使用的分布式共识协议,仲裁队列就是基于 Raft 共识算法的一个变种。它比镜像队列更安全、性能更好。
Raft 协议下的消息复制
每个仲裁队列都有多个副本,它包含一个主和多个从副本。replication factor 为 5 的仲裁队列将会有 1 个主副本和 4 个从副本。每个副本都在不通的 RabbitMQ 节点上。
客户端(生产者和消费者)只会与主副本进行交互,主副本再将这些命令复制到从副本。与镜像队列类似,从副本不与客户端进行交互,它们仅仅作为一个冗余备份,在节点挂掉或重启时提供高可用的能力。当主副本所在的节点下线,其中一个在另外节点的从副本会被选举成为主副本,继续提供服务。
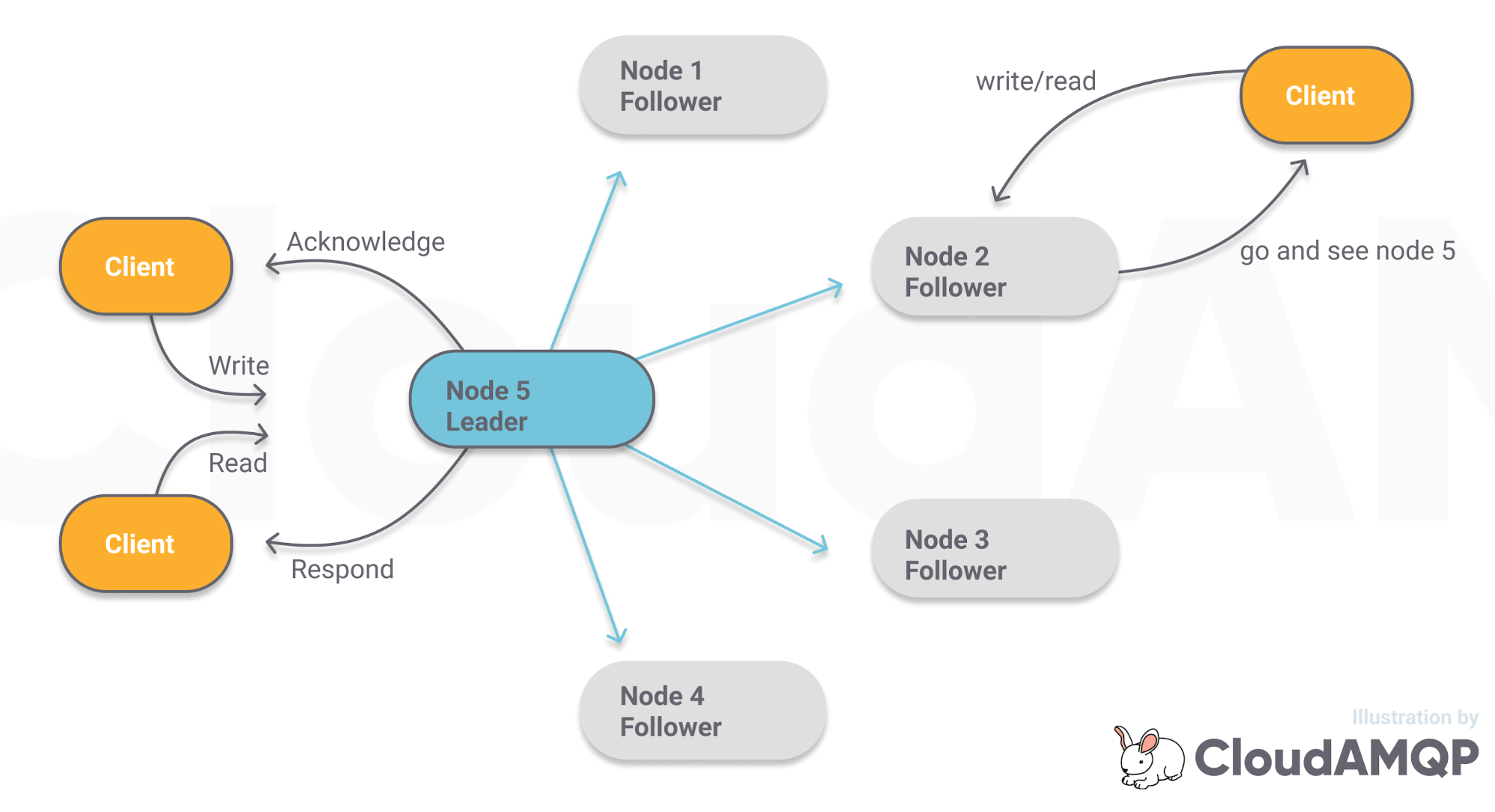
消息复制和主副本选举的操作,需要超过半数的副本同意,所以我管它叫做仲裁队列。当生产者发送一条消息,需要超过半数的队列副本都将消息写入磁盘以后才会向生产者进行确认。这意味着少部分比较慢的副本不会影响整个队列的性能。同样地,主副本的选举也需要超过半数的副本同意才行,这会避免出现网络分区时 2 个主副本,所以说仲裁队列相对于可用性更看重一致性。
仲裁队列的优势
-
客户端不需要改变它们生产和订阅的方法,无需考虑队列类型。唯一的区别就是在客户端定义队列的时候需要定义成仲裁队列(代码中添加相关属性)
-
同步的问题被解决,当节点重新上线时,不会丢数据,主副本会直接从从副本中断的地方开始复制消息。复制的过程是非阻塞的,所以整个队列不会因为新的副本加入而收到影响。唯一的影响是网络使用率。
没有了同步问题,不仅让仲裁队列比镜像队列更可靠,同时,因为写入必须被超过半数的副本接受,所以不会因为脑裂而丢数据。
-
Raft 协议比镜像队列的算法更有效率,可以提供更好的消息吞吐量。
总结起来,仲裁队列可以提供更高的性能、更好的数据安全性、更容易进行节点的滚动升级。
仲裁队列的劣势
特性更少
这些特性在仲裁队列的第一个版本中不会提供
- 非持久化消息
- 排它队列
- 队列/消息 TTL(超时时间)
- 一些规则(Policy)不可用,只有死信队列、队列长度限制可用
- 优先级
- 惰性队列
- 非全局的消息预取(Qos)
磁盘使用——写入放大
仲裁队列的磁盘和内存配置与普通队列不同。
普通队列
普通队列使用“共享”存储模型,对于一条要投递到多个队列的消息,只会存储一次,其他队列只会保存这条消息的引用。也就是说,在发布-订阅模型下,一条将要投递到多个队列的消息,它的存储大小不会随着投递到的队列变多而线性增长。
举个例子,我们用一个 fanout 类型的 exchange,绑定 10 个队列。

这 10 个队列每个都设置成 5 副本镜像队列。
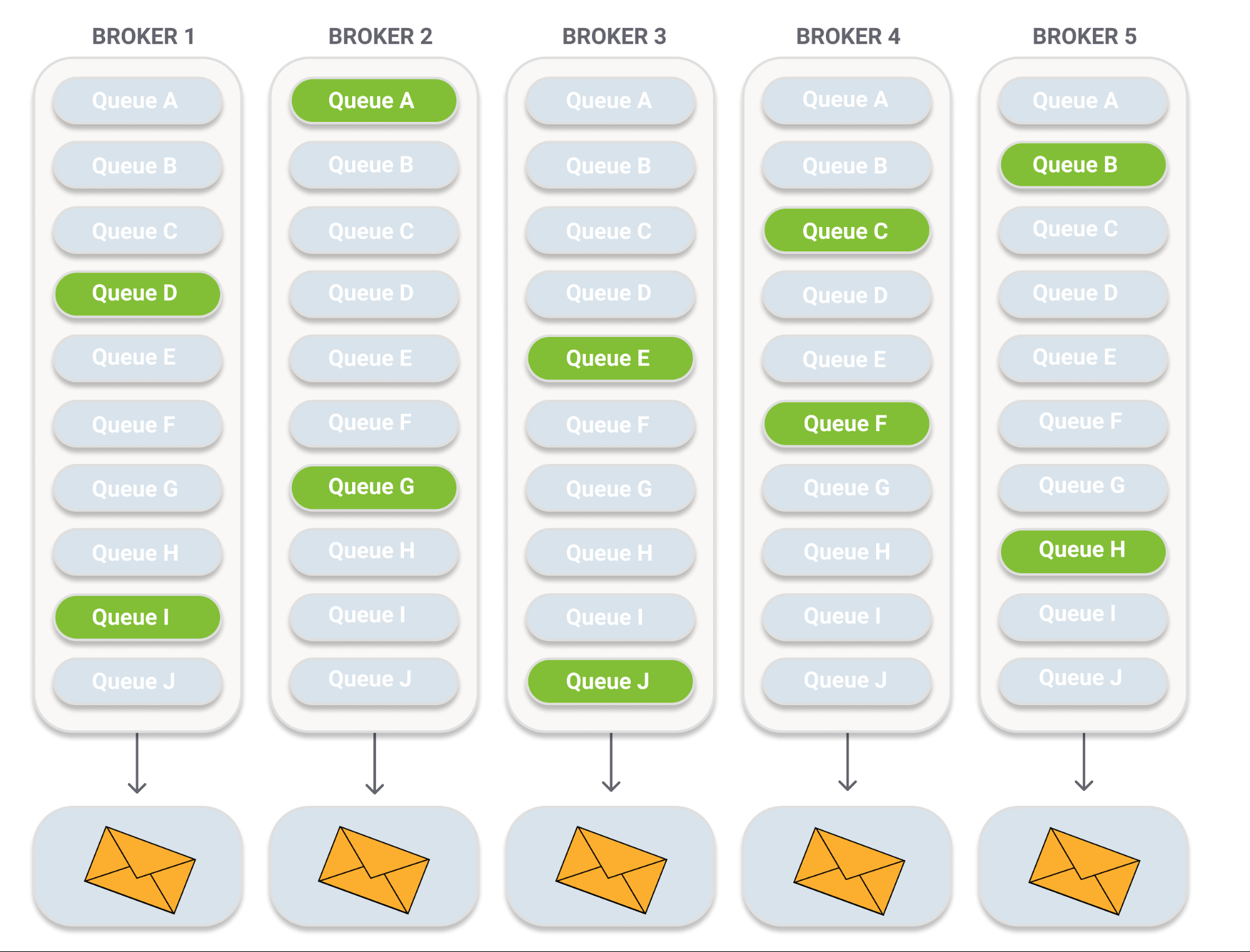
最终,发布一条消息后,只有 5 条消息存储到集群中,每个节点存储 1 条。所以在这个情况下的写入放大是 5 倍。
仲裁队列
仲裁队列使用在内存中“共享”的存储模型,在磁盘中,每条消息都会分别被存储。所以发布-订阅模型会造成更严重的写入放大,可能导致更大的磁盘使用,甚至不得不放弃使用仲裁队列。
还是上面那个例子,当每个队列都变成仲裁队列,并且复制因子为 5 时。

最终集群中的磁盘上存储了 50 条消息,每条消息的写入放大是 50 倍。
因此,把 fanout 交换器和仲裁队列一起使用不太合适。
内存使用——所有消息一直保存在内存中
仲裁队列的所有消息一直会保存在内存中,这会增加内存的使用量,最终可能导致集群不可用。如果不进行一些检查和监控,队列消息不断堆积,可能会导致生产停止(内存高水位),直到消息被消费或者从内存中删除。所以当使用仲裁队列时,设置队列的长度限制非常重要。此外还有必要用惰性队列作为仲裁队列的死信队列,通过死信交换器将这些消息转发到死信队列中。
因此,队列的规划和监控边得比普通场景下更为重要。下游(消费者和下游服务)的中断或者变慢可能导致多个队列消息堆积,需要有对应的规划和措施。你需要多少个仲裁队列、它们的写入速率时多少,当集群达到内存高水位时其他队列会不会收到影响?
失去多数节点时意味着队列不可用
如果仲裁队列超过半数的副本永久丢失,那么队列数据就永久丢失了。即便有小部分的副本仍然可用,队列仍然没有办法恢复,只能被强制删除。虽然这种场景出现的可能性较小,但是仍有这样的危险存在。所以,推荐使用可靠的磁盘,并且把复制因子设置为 5 ~ 3。
延迟
尽管仲裁队列的吞吐量更高,但是延迟也可能更高,这是由于使用了 Raft 协议。在仲裁队列中,所有消息都是持久化的,所有消息都会保存到每个副本的磁盘中。安全性是仲裁队列的主要目标。

- 点赞
- 收藏
- 关注作者
评论(0)