python爬取中国天气网中城市及其对应编号

【摘要】
文章目录
一、前言二、思路三、程序四、注意事项
一、前言
为了实现爬取各地城市天气预报及其可视化的需要,爬取中国天气网中城市及其对应编号 。
天气预报可视化文章如下:
《pytho...
一、前言
为了实现爬取各地城市天气预报及其可视化的需要,爬取中国天气网中城市及其对应编号 。
天气预报可视化文章如下:
二、思路
首先,进入页面:
http://www.weather.com.cn/forecast/
紧接着,就对页面进行检查,寻找所要数据。通过寻找,可以发现,有很多包含城市及其编号的数据,我这里选的是这个:
https://img.weather.com.cn/newwebgis/fc/nation_fc24h_wea_2022010420.json
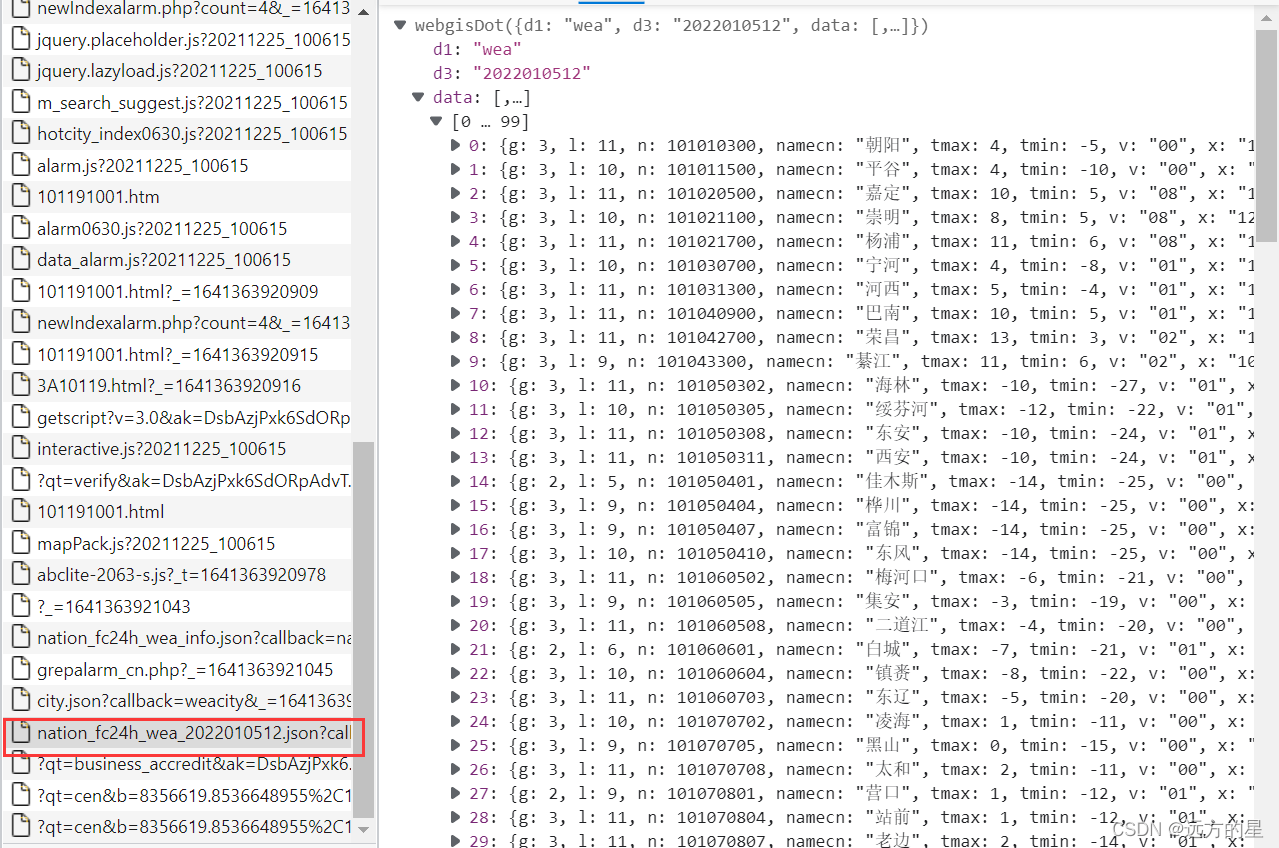
接下来,就是对json数据的爬取
三、程序
# -*- coding: UTF-8 -*-
"""
# @Time: 2022/1/4 17:18
# @Author: 远方的星
# @CSDN: https://blog.csdn.net/qq_44921056
"""
import requests
import pandas as pd
import json
import pprint
import chardet
from fake_useragent import UserAgent
# 随机产生请求头
ua = UserAgent(verify_ssl=False, path='D:/Pycharm/fake_useragent.json')
# 随机切换请求头
def random_ua():
headers = {
"user-agent": ua.random
}
return headers
def main():
url = 'https://img.weather.com.cn/newwebgis/fc/nation_fc24h_wea_2022010420.json'
res = requests.get(url=url, headers=random_ua())
res.encoding = chardet.detect(res.content)['encoding']
res = res.text
# print(res)
res = res.replace('webgisDot(', '').replace(')', '') # 获取的数据不是标准的json格式,需要修改处理
data = json.loads(res)
# pprint.pprint(data)
a = data["data"]
# pprint.pprint(a)
city_s, num_s = [], []
for i in range(len(a)):
city = a[i]['namecn']
num = a[i]['n']
city_s.append(city)
num_s.append(num)
excel = pd.DataFrame()
excel['城市'] = city_s
excel['编号'] = num_s
# print(excel)
excel.to_csv('D:/中国天气城市编号.csv', encoding="utf_8_sig") # 解决pandas输出乱码
print("下载完成")
if __name__ == '__main__':
main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
四、注意事项
①、直接爬取的页面不是标准的json数据,需要进行简单的处理
②、使用pandas导出二维列表时,编码格式需要改变,否则会出现乱码
这篇文章如果对你有帮助,记得点个赞👍哟,也是对作者最大的鼓励🙇♂️。
如有不足之处可以在评论区👇多多指正,我会在看到的第一时间进行修正
作者:远方的星
CSDN:https://blog.csdn.net/qq_44921056
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。
文章来源: luckystar.blog.csdn.net,作者:爱打瞌睡的CV君,版权归原作者所有,如需转载,请联系作者。
原文链接:luckystar.blog.csdn.net/article/details/122322712

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)