Linux下如何让你的CPU保持在90%以上

【摘要】 命令一:“cat /dev/urandom | md5sum”或“dd if=/dev/zero of=/dev/null” 命令二:使用sysbench来压测 命令三:使用stress来压测如何让你的CPU保持在90%以上的使用率呢?这在某些场景下非常有用。麦老师统计了一下,有如下几种办法。 命令一:“cat /dev/urandom | md5sum”或“dd if=/dev/zero...
如何让你的CPU保持在90%以上的使用率呢?这在某些场景下非常有用。麦老师统计了一下,有如下几种办法。

命令一:“cat /dev/urandom | md5sum”或“dd if=/dev/zero of=/dev/null”
for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do cat /dev/urandom | md5sum & done
for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do dd if=/dev/zero of=/dev/null & done
说明:
- cat /proc/cpuinfo |grep “physical id” | wc -l 可以获得CPU的个数, 我们将其表示为N.
- seq 1 N 用来生成1到N之间的数字
- for i in
seq 1 N; 就是循环执行命令,从1到N- dd if=/dev/zero of=/dev/null 执行dd命令, 输出到/dev/null, 实际上只占用CPU, 没有IO操作.
- 由于连续执行N个(N是CPU个数)的dd 命令, 且使用率为100%, 这时调度器会调度每个dd命令在不同的CPU上处理.
- 最终就实现所有CPU占用率100%
另外,上述程序的结束可以使用:
fg 后按 ctrl + C (因为该命令是放在后台执行)
-- 删掉上述会话
pkill -9 dd
pkill -9 cat
注意:
- cat /proc/cpuinfo |grep “physical id” |wc -l 这个命令的目的是获取当前CPU的个数
- 但有的系统,cat /proc/cpuinfo打印出来的信息里没有包含"physical id",可能是其他值
- 这就需要根据实际打印出来的信息,修改grep "physical id"中的关键字
- 最终效果是执行这行命令,打印CPU个数
执行过程:
[root@docker35 ~]# for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do cat /dev/urandom | md5sum & done
for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do dd if=/dev/zero of=/dev/null & done
[1] 15061
[2] 15063
[3] 15065
[4] 15067
[5] 15069
[6] 15071
[7] 15073
[8] 15075
[root@docker35 ~]# for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do dd if=/dev/zero of=/dev/null & done
[9] 15091
[10] 15092
[11] 15093
[12] 15094
[13] 15095
[14] 15096
[15] 15097
[16] 15098
执行结果:
使用top命令查看:

在执行了top命令后,按下数字1键,可以看所有cpu的使用率:
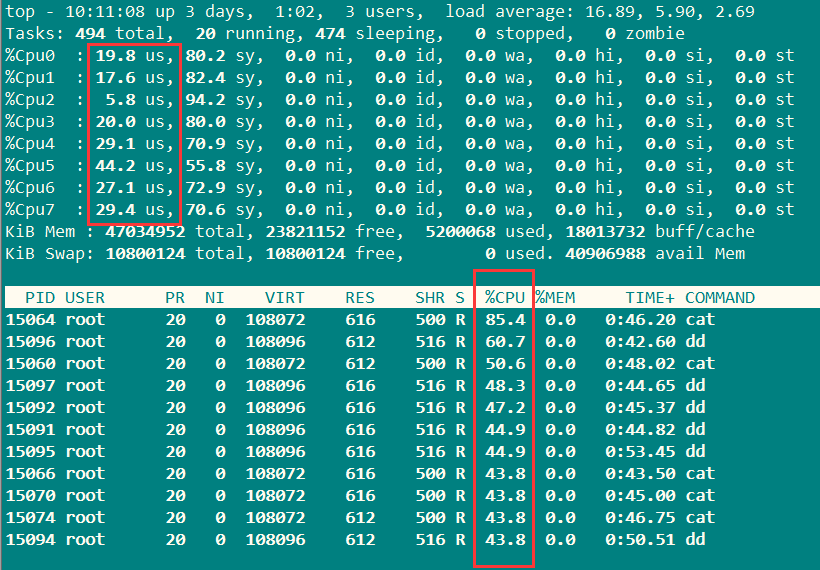
可以看到,用户的使用率us%不是很高,而sys%很高,我们杀掉会话后,换一个命令:
[root@docker35 ~]# pkill -9 cat
pkill -9 ddd6401a791fd4d6df02201eeb53023720 -
84fd58d503f105b5694826b7b517a836 -
021224c074d9035d9696e88c0bded178 -
3705e304f99b2b71e42faca281593e9e -
7e01874e9a0d448dcc42a6949aaff0c3 -
f33601ed177b579f760490573ec36dc4 -
19a91d3c08f9e6368b83bb0f571375aa -
0eb9db659308c375745f9b558fc01ada -
[1] Done cat /dev/urandom | md5sum
[2] Done cat /dev/urandom | md5sum
[3] Done cat /dev/urandom | md5sum
[4] Done cat /dev/urandom | md5sum
[5] Done cat /dev/urandom | md5sum
[6] Done cat /dev/urandom | md5sum
[7] Done cat /dev/urandom | md5sum
[8] Done cat /dev/urandom | md5sum
[root@docker35 ~]# for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do dd if=/dev/zero bs=1M count=80000 | md5sum & done
[17] 16094
[18] 16105
[19] 16107
[20] 16109
[21] 16119
[22] 16121
[23] 16123
[24] 16133
继续使用top查看:
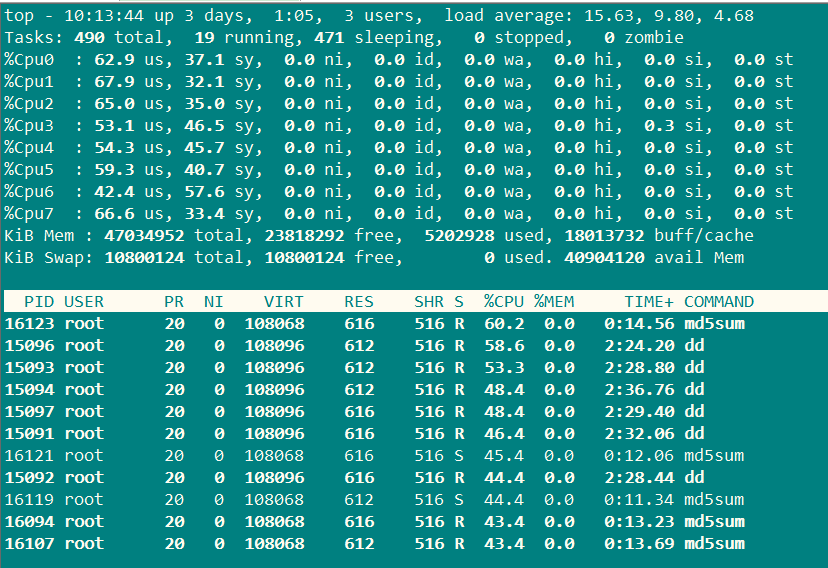

用户的使用率仍然没有上到90%。
所以,这个时候可以考虑对CPU进行性能压测,由于CPU主要用于计算的,所以,可以使用sysbench或stress来压测。
命令二:使用sysbench来压测
sysbench是一款开源的、模块化的、跨平台的多线程性能测试工具,可用于CPU、内存、磁盘I/O、线程、数据库的性能测试。sysbench目前支持的数据库压测有PG和MySQL。(若想学习数据库压测,可以私聊麦老师哟,MySQL和PG均有相关课程)
工具的官网说明:https://launchpad.net/sysbench
sysbench支持以下几种测试模式:
1、CPU运算性能
2、磁盘IO性能
3、调度程序性能
4、内存分配及传输速度
5、POSIX线程性能–互斥基准测试
6、数据库性能(OLTP基准测试)
sysbench可以直接使用yum来安装:
yum install -y sysbench
对CPU的性能测试通常有:1.质数计算;2圆周率计算;sysbench使用的就是通过质数相加的测试。对CPU测试直接运行run即可。
下面的命令表示100个线程执行8万次请求,每个请求执行质数相加到8000000,下面开始压测:
[root@docker35 ~]# sysbench --threads=100 --events=80000 cpu --cpu-max-prime=8000000 run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Prime numbers limit: 8000000
Initializing worker threads...
Threads started!
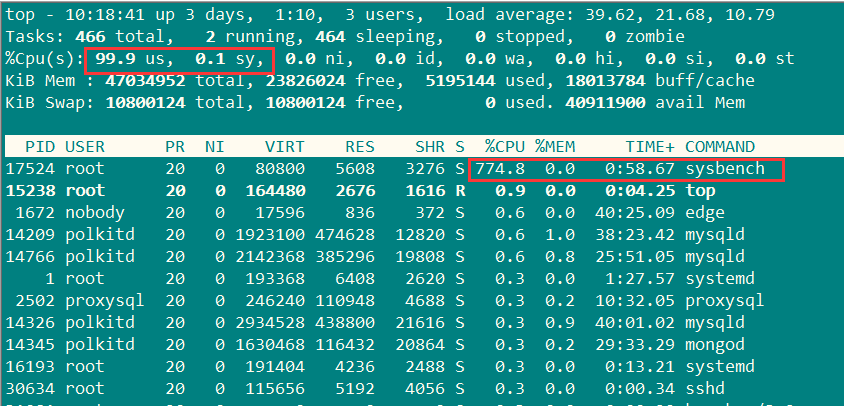
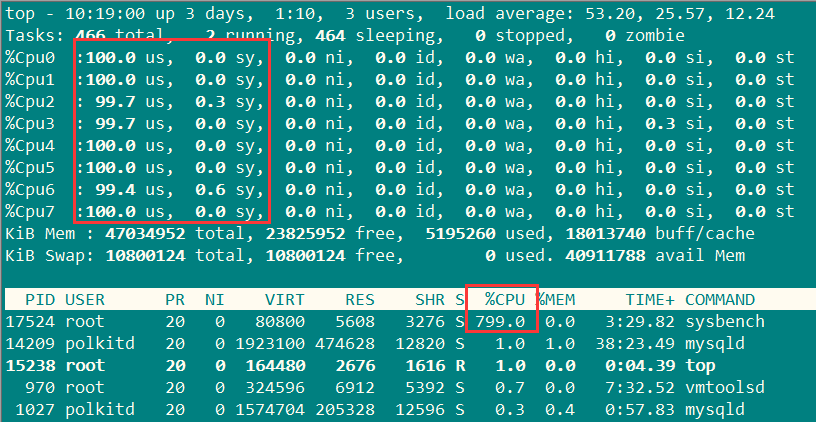
可以看到,用户的cpu已达到90%以上了。
命令三:使用stress来压测
需要安装:
yum install -y stress
stress命令的帮助内容:
[root@docker35 ~]# stress --help
`stress' imposes certain types of compute stress on your system
Usage: stress [OPTION [ARG]] ...
-?, --help show this help statement
--version show version statement
-v, --verbose be verbose
-q, --quiet be quiet
-n, --dry-run show what would have been done
-t, --timeout N timeout after N seconds
--backoff N wait factor of N microseconds before work starts
-c, --cpu N spawn N workers spinning on sqrt()
-i, --io N spawn N workers spinning on sync()
-m, --vm N spawn N workers spinning on malloc()/free()
--vm-bytes B malloc B bytes per vm worker (default is 256MB)
--vm-stride B touch a byte every B bytes (default is 4096)
--vm-hang N sleep N secs before free (default none, 0 is inf)
--vm-keep redirty memory instead of freeing and reallocating
-d, --hdd N spawn N workers spinning on write()/unlink()
--hdd-bytes B write B bytes per hdd worker (default is 1GB)
Example: stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s
Note: Numbers may be suffixed with s,m,h,d,y (time) or B,K,M,G (size).
开始压测:
[root@docker35 ~]# stress --cpu 8 --timeout 600
stress: info: [18740] dispatching hogs: 8 cpu, 0 io, 0 vm, 0 hdd
^C
查看CPU使用率:
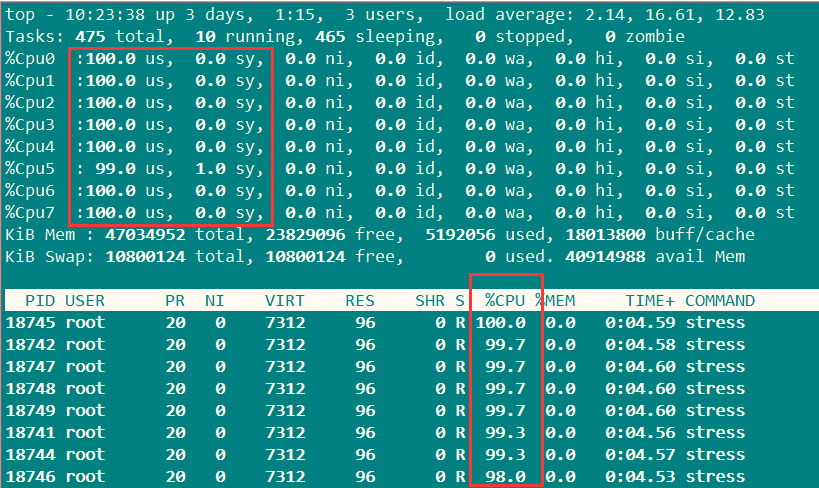
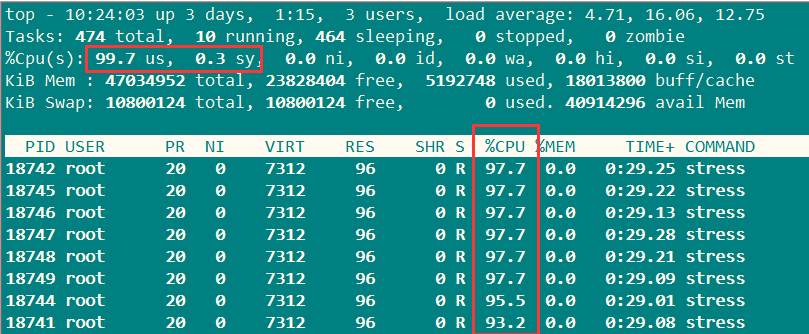
找了这么多的方法,应该可以满足某个人的要求了吧!!!

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)