使用MitmProxy离线缓存360度全景网页

📢博客主页:https://blog.csdn.net/as604049322
📢欢迎点赞 👍 收藏 ⭐留言 📝 欢迎讨论!
📢本文由 小小明-代码实体 原创,首发于 CSDN🙉
昨天遇到一个问题:
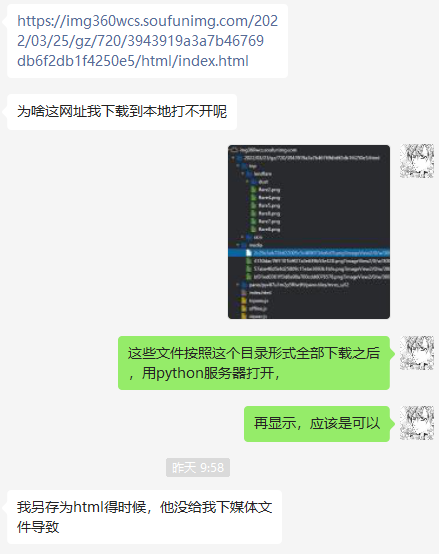
有些涉及动态加载的网页,有游览器自带的保存网页功能是无法保存全部资源的。
假如我们手工挨个文件去保存,未免也太多了:
超多的文件夹,一层一层的。
此时我为了实现离线缓存目标网页,想到了一个好方法,那就是通过支持python编程的代理,让每一个请求都根据URL保存对应的文件到本地。
MitmProxy的安装
比较推荐MitmProxy,安装方法在命令行中执行:
pip install mitmproxy
- 1
MitmProxy分为mitmproxy,mitmdump和mitmweb三个命令,其中mitmdump支持使用指定的python脚本处理每个请求(使用-s参数指定)。
安装后我们需要安装证书MitmProxy对应的证书,访问:http://mitm.it/
直接访问会显示:If you can see this, traffic is not passing through mitmproxy.
这里我们先执行mitmweb启动一个网页版的代理服务器:

我们给所使用的游览器,设置代理服务器的地址,以360安全游览器为例:
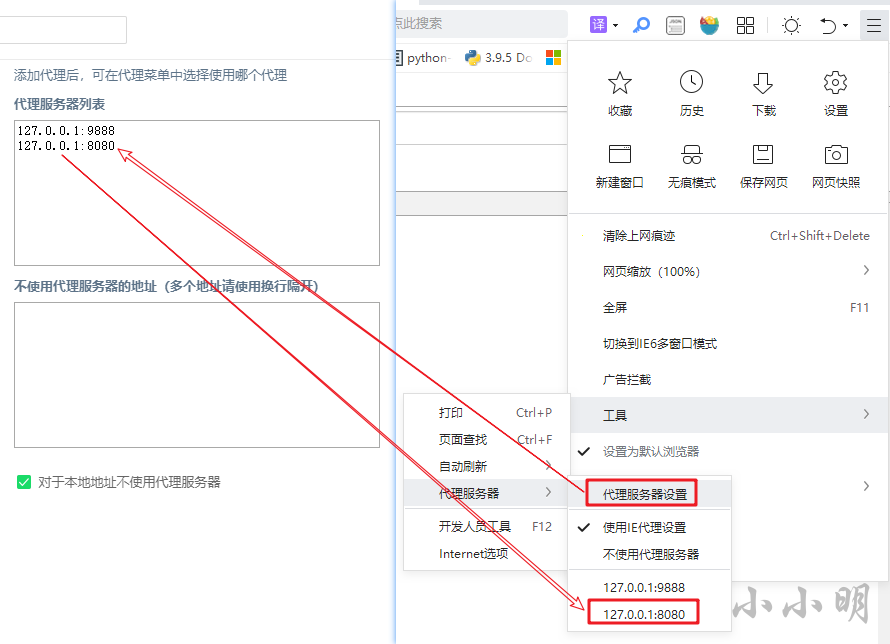
在设置并使用MitmProxy提供的代理服务器之后再次访问http://mitm.it/就可以下载并安装证书了:

下载后打开证书不断点击下一步即可安装完成。
此时访问百度,可以看到MitmProxy的证书验证信息:

编写mitmdump所需的脚本
mitmdump所支持的脚本的模板代码如下:
# 所有发出的请求数据包都会被这个方法所处理
def request(flow):
# 获取请求对象
request = flow.request
# 所有服务器响应的数据包都会被这个方法处理
def response(flow):
# 获取响应对象
response = flow.response
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
request和response对象与requests库中的对象几乎一致。
我们的需求是根据url保存文件,只需要处理响应即可,先尝试缓存百度首页:
import os
import re
dest_url = "https://www.baidu.com/"
def response(flow):
url = flow.request.url
response = flow.response
if response.status_code != 200 or not url.startswith(dest_url):
return
r_pos = url.rfind("?")
url = url if r_pos == -1 else url[:r_pos]
url = url if url[-1] != "/" else url+"index.html"
path = re.sub("[/\\\\:\\*\\?\\<\\>\\|\"\s]", "_", dest_url.strip("htps:/"))
file = path + "/" + url.replace(dest_url, "").strip("/")
r_pos = file.rfind("/")
if r_pos != -1:
path, file_name = file[:r_pos], file[r_pos+1:]
os.makedirs(path, exist_ok=True)
with open(file, "wb") as f:
f.write(response.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
将上述脚本保存为dump.py然后使用如下命令启动代理(先关闭之前启动的mitmweb):
>mitmdump -s dump.py
Loading script dump.py
Proxy server listening at http://*:8080
- 1
- 2
- 3
刷新页面后已经顺利缓存了百度首页:

使用python自带的服务器测试运行并访问一下:
可以看到已经顺利访问了本地的百度。
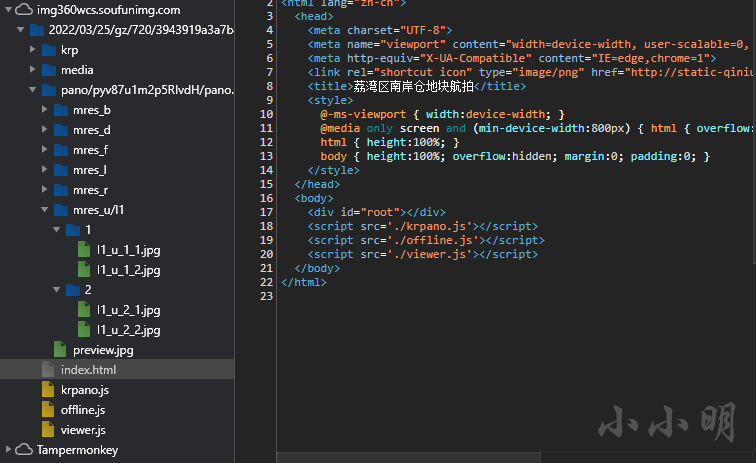
离线缓存360全景网页
将上述脚本的dest_url修改为如下地址并保存:
dest_url = "https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html"
- 1
再次访问:https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html/index.html
如果发现保存的文件不够全,可以打开开发者工具,在网络选项卡勾选 禁用缓存 后,再次刷新网页:

此时主体文件已经全部缓存:
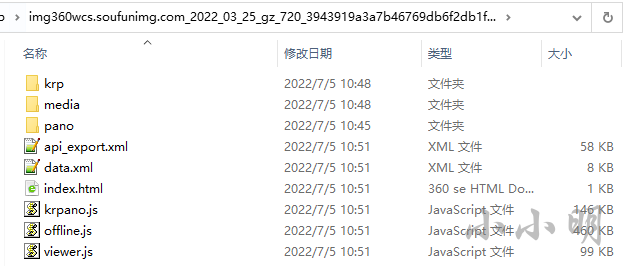
此时只要尽量多的在原始网页上游览各个方向,并放大缩小就可以尽量多缓存更多高清细节图片。
使用本地服务器启动测试已经顺利访问:
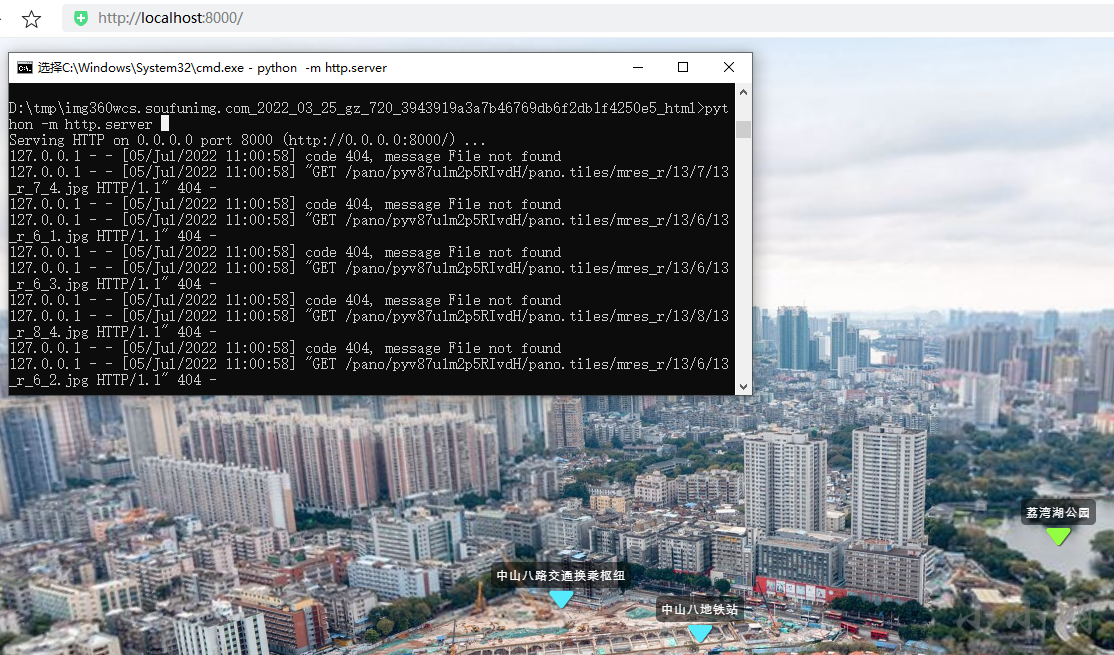
不过原始脚本只缓存响应码为200的普通文件,上述网站还会返回响应码为206的分片音乐文件,如果也需要缓存就稍微复杂一些,下面我们研究一下如何缓存音乐文件。
缓存206分片文件
经过一番研究,将上述代码修改为如下形式即可:
import os
import re
dest_url = "https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html"
def response(flow):
url = flow.request.url
response = flow.response
if response.status_code not in (200, 206) or not url.startswith(dest_url):
return
r_pos = url.rfind("?")
url = url if r_pos == -1 else url[:r_pos]
url = url if url[-1] != "/" else url+"index.html"
path = re.sub("[/\\\\:\\*\\?\\<\\>\\|\"\s]", "_", dest_url.strip("htps:/"))
file = path + "/" + url.replace(dest_url, "").strip("/")
r_pos = file.rfind("/")
if r_pos != -1:
path, file_name = file[:r_pos], file[r_pos+1:]
os.makedirs(path, exist_ok=True)
if response.status_code == 206:
s, e, length = map(int, re.fullmatch(
r"bytes (\d+)-(\d+)/(\d+)", response.headers['Content-Range']).groups())
if not os.path.exists(file):
with open(file, "wb") as f:
pass
with open(file, "rb+") as f:
f.seek(s)
f.write(response.content)
elif response.status_code == 200:
with open(file, "wb") as f:
f.write(response.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
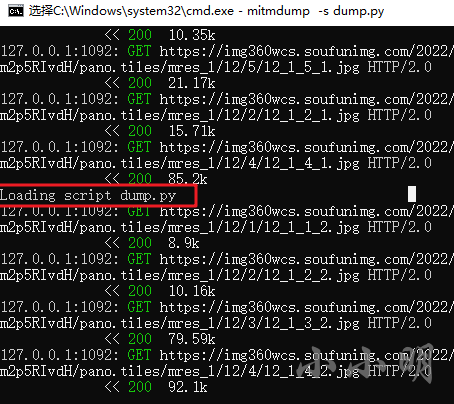
保存修改完的脚本,mitmdump可以自动重载:
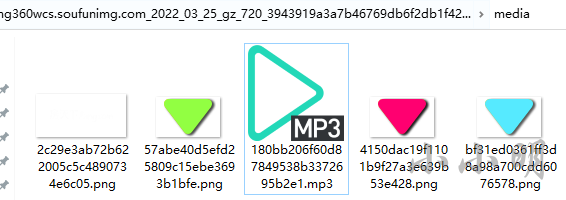
清理缓存并重新访问之后,音乐文件已经顺利下载:
总结
通过mitmdump我们已经顺利实现了对指定网站的缓存,以后想缓存其他网站到本地只需要修改dest_url的网址即可。
文章来源: xxmdmst.blog.csdn.net,作者:小小明-代码实体,版权归原作者所有,如需转载,请联系作者。
原文链接:xxmdmst.blog.csdn.net/article/details/125617140

- 点赞
- 收藏
- 关注作者
评论(0)