JVM内存模型

JAVA的主旨是它著名的WOTA:“一次编写,随处运行”。为了应用它,Sun Microsystems创建了Java虚拟机,这是解释已编译的Java代码的基础操作系统的抽象。JVM是JRE(Java运行时环境)的核心组件,是为运行Java代码而创建的,但现在被其他语言(Scala,Groovy,JRuby,Closure…)使用。
在本文中,我将重点介绍 JVM 规范中描述的运行时数据区域。这些区域旨在存储程序或 JVM 本身使用的数据。我将首先介绍JVM的概述,然后是字节码是什么,并以不同的数据区域结束。
全球概况
JVM 是底层操作系统的抽象。它确保相同的代码将以相同的行为运行,无论JVM在什么硬件或操作系统上运行。例如:
- 无论 JVM 是否在 16 位/32 位/64 位操作系统上运行,基元类型 int 的大小将始终为从 -2^31 到 2^31-1 的 32 位有符号整数。
- 每个 JVM 都以大端顺序(其中高字节优先)在内存中存储和使用数据,无论底层操作系统/硬件是大端还是小端序。
注意:有时,JVM 实现的行为与另一个 JVM 实现不同,但通常是相同的。
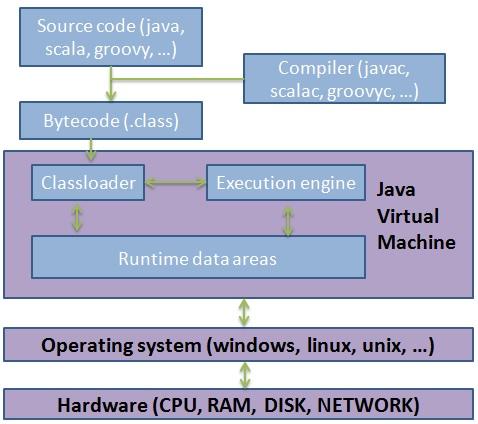
下图给出了 JVM 的概述:
- JVM 解释由编译类的源代码生成的字节码。虽然术语JVM代表“Java虚拟机”,但它可以运行其他语言,如scala或groovy,只要它们可以编译成java字节码。
- 为了避免磁盘 I/O,字节码由其中一个运行时数据区域中的类装入器加载到 JVM 中。此代码将保留在内存中,直到 JVM 停止或类装入器(装入它)被销毁。
- 然后,加载的代码由执行引擎解释和执行。
- 执行引擎需要存储数据,就像指向正在执行的代码的指针一样。它还需要存储开发人员代码中处理的数据。
- 执行引擎还负责处理底层操作系统。
注意:许多 JVM 实现的执行引擎不会总是解释字节码,而是将字节码编译为本机代码(如果经常使用)。它被称为Just In Time(JIT)编译,大大加快了JVM的速度。编译的代码临时保存在通常称为代码缓存的区域中。由于该区域不在 JVM 规范中,因此在本文的其余部分我不会讨论它。
基于堆栈的架构
JVM 使用基于堆栈的体系结构。虽然它对开发人员来说是不可见的,但它对生成的字节码和JVM架构有巨大的影响,这就是为什么我将简要解释这个概念。
JVM通过执行Java字节码中描述的基本操作来执行开发人员的代码(我们将在下一章中看到它)。操作数是指令操作的值。根据 JVM 规范,这些操作要求通过称为操作数堆栈的堆栈传递参数。
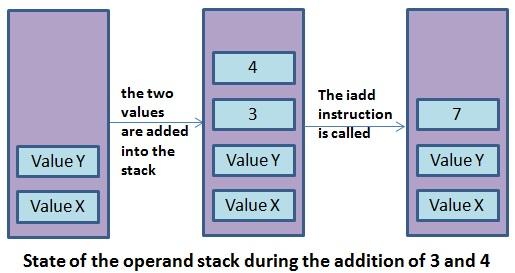
例如,让我们取 2 个整数的基本相加法。此操作称为 iadd(对于 integer addition)。如果要在字节码中添加 3 和 4:
- 他首先在操作数堆栈中推送 3 和 4。
- 然后调用 iadd 指令。
- iadd 将从操作数堆栈中弹出最后 2 个值。
- int 结果 (3 + 4) 被推送到操作数堆栈中,以便其他操作使用。
这种工作方式称为基于堆栈的体系结构。还有其他方法可以处理基本操作,例如,基于寄存器的体系结构将操作数存储在小型寄存器中,而不是堆栈中。这种基于寄存器的架构由桌面/服务器(x86)处理器和以前的Android虚拟机Dalvik使用。
字节码
由于JVM解释字节码,因此在深入研究之前了解它是什么很有用。
java字节码是转换为一组基本操作的java源代码。每个操作由一个表示要执行的指令的字节(称为操作码或操作代码)以及零个或多个用于传递参数的字节组成(但大多数操作使用操作数堆栈来传递参数)。在 256 个可能的一字节长的操作码(从值 0x00 到十六进制的 0xFF)中,有 204 个目前在 java8 规范中使用。
下面是不同类别的字节码操作的列表。对于每个类别,我添加了一个小描述和操作代码的十六进制范围:
- 常量:用于将值从常量池(我们稍后会看到它)或从已知值推送到操作数堆栈中。从价值0x00到0x14
- 加载:用于将值从局部变量加载到操作数堆栈中。从价值0x15到0x35
- 存储:用于将操作数堆栈存储到局部变量中。从价值0x36到0x56
- 堆栈:用于处理操作数堆栈。从价值0x57到0x5f
- Math:用于对操作数堆栈中的值进行基本数学运算。从价值0x60到0x84
- 转换:用于从一种类型转换为另一种类型。从价值0x85到0x93
- 比较:用于两个值之间的基本比较。从价值0x94到0xa6
- 控制:基本操作,如转到,返回,…允许更高级的操作,如返回值的循环或函数。从价值0xa7到0xb1
- 引用:用于分配对象或数组,获取或检查对对象,方法或静态方法的引用。还用于调用(静态)方法。从价值0xb2到0xc3
- 扩展:之后添加的其他类别中的操作。从价值0xc4到0xc9
- 保留:供每个 Java 虚拟机实现内部使用。3 个值:0xca、0xfe和0xff。
这 204 个操作非常简单,例如:
- 操作数 ifeq (0x99 ) 检查 2 个值是否相等
- 操作数 iadd (0x60) 添加 2 个值
- 操作数 i2l (0x85) 将整数转换为长整型
- 操作数数组长度 (0xbe) 给出数组的大小
- 操作数 pop (0x57) 从操作数堆栈中弹出第一个值
要创建字节码,需要一个编译器,JDK中包含的标准Java编译器是javac。
让我们看一个简单的添加:
public class Test {
public static void main(String[] args) {
int a =1;
int b = 15;
int result = add(a,b);
}
public static int add(int a, int b){
int result = a + b;
return result;
}
}
“javac Test.java”命令在 Test.class 中生成一个字节码。由于java字节码是二进制代码,因此人类无法读取它。Oracle在其JDK中提供了一个工具javap,该工具将二进制字节码转换为JVM规范中人类可读的标记操作代码集。
命令 “javap -verbose Test.class” 给出以下结果:
Classfile /C:/TMP/Test.class
Last modified 1 avr. 2015; size 367 bytes
MD5 checksum adb9ff75f12fc6ce1cdde22a9c4c7426
Compiled from "Test.java"
public class com.codinggeek.jvm.Test
SourceFile: "Test.java"
minor version: 0
major version: 51
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #4.#15 // java/lang/Object."<init>":()V
#2 = Methodref #3.#16 // com/codinggeek/jvm/Test.add:(II)I
#3 = Class #17 // com/codinggeek/jvm/Test
#4 = Class #18 // java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 main
#10 = Utf8 ([Ljava/lang/String;)V
#11 = Utf8 add
#12 = Utf8 (II)I
#13 = Utf8 SourceFile
#14 = Utf8 Test.java
#15 = NameAndType #5:#6 // "<init>":()V
#16 = NameAndType #11:#12 // add:(II)I
#17 = Utf8 com/codinggeek/jvm/Test
#18 = Utf8 java/lang/Object
{
public com.codinggeek.jvm.Test();
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
public static void main(java.lang.String[]);
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: iconst_1
1: istore_1
2: bipush 15
4: istore_2
5: iload_1
6: iload_2
7: invokestatic #2 // Method add:(II)I
10: istore_3
11: return
LineNumberTable:
line 6: 0
line 7: 2
line 8: 5
line 9: 11
public static int add(int, int);
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=2
0: iload_0
1: iload_1
2: iadd
3: istore_2
4: iload_2
5: ireturn
LineNumberTable:
line 12: 0
line 13: 4
}
可读.class表明字节码包含的不仅仅是java源代码的简单转录。它包含:
- 类的常量池的描述。常量池是JVM的数据区域之一,它存储有关类的元数据,例如方法的名称,参数…当一个类在JVM中加载时,这部分进入常量池。
- 像 LineNumberTable 或 LocalVariableTable 这样的信息,用于指定函数的位置(以字节为单位)及其变量在字节码中的位置。
- 开发人员的 java 代码(加上隐藏构造函数)的字节码中的转录。
- 处理操作数堆栈的特定操作,更广泛地说是处理传递和获取参数的方式。
仅供参考,以下是存储在.class文件中的信息的简要说明:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
运行时数据区域
运行时数据区域是用于存储数据的内存中区域。这些数据由开发人员的程序或JVM用于其内部工作。
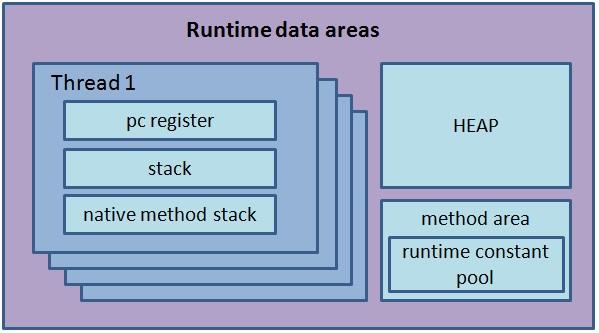
此图显示了 JVM 中不同运行时数据区域的概述。某些区域是每个线程的其他区域所独有的。
堆
堆是所有 Java 虚拟机线程之间共享的内存区域。它是在虚拟机启动时创建的。所有类实例和数组都在堆中分配(使用 new 运算符)。
MyClass myVariable = new MyClass();
MyClass[] myArrayClass = new MyClass[1024];
此区域必须由垃圾回收器管理,以便在不再使用开发人员分配的实例时将其删除。清理内存的策略取决于 JVM 实现(例如,Oracle Hotspot 提供了多种算法)。
堆可以动态扩展或收缩,并且可以具有固定的最小和最大大小。例如,在Oracle Hotspot中,用户可以通过以下方式使用Xms和Xmx参数指定堆的最小大小“java -Xms=512m -Xmx=1024m…”
注意:堆不能超过的最大大小。如果超过此限制,JVM 将抛出一个 OutOfMemoryError。
方法区域
方法区域是所有 Java 虚拟机线程之间共享的内存。它是在虚拟机启动时创建的,由类装入器从字节码装入。只要加载方法区域中的类装入器处于活动状态,它们就会保留在内存中。
方法区域存储:
- 类信息(字段/方法数、超类名、接口名、版本等)
- 方法和构造函数的字节码。
- 每个装入的类的运行时常量池。
规范不会强制在堆中实现方法区域。例如,在JAVA7之前,Oracle HotSpot使用一个名为PermGen的区域来存储方法区域。这个PermGen与Java堆(以及像堆一样由JVM管理的内存)是连续的,并且被限制为默认空间64Mo(由参数-XX:MaxPermSize修改)。从Java 8开始,HotSpot现在将方法区域存储在称为Metaspace的单独本机内存空间中,最大可用空间是总可用系统内存。
注意:方法区域不能超过的最大大小。如果超过此限制,JVM 将抛出一个 OutOfMemoryError。
运行时常量池
此池是方法区域的子部分。由于它是元数据的重要组成部分,因此 Oracle 规范除了“方法区域”之外,还描述了运行时常量池。对于每个加载的类/接口,此常量池都会增加。这个池就像传统编程语言的符号表。换句话说,当引用类、方法或字段时,JVM 通过使用运行时常量池搜索内存中的实际地址。它还包含常量值,如字符串 litteral 或常量基元。
String myString1 = “This is a string litteral”;
static final int MY_CONSTANT=2;
PC 寄存器(每个线程)
每个线程都有自己的 pc(程序计数器)寄存器,与线程同时创建。在任何时候,每个 Java 虚拟机线程都在执行单个方法的代码,即该线程的当前方法。pc 寄存器包含当前正在执行的 Java 虚拟机指令(在方法区域中)的地址。
注: 如果线程当前正在执行的方法是本机的,则 Java 虚拟机的 pc 寄存器的值是未定义的。Java 虚拟机的 pc 寄存器足够宽,可以在特定平台上保存 returnAddress 或本机指针。
Java 虚拟机堆栈(每个线程)
堆栈区域存储多个帧,因此在讨论堆栈之前,我将介绍这些帧。
框架
帧是一种数据结构,它包含多个数据,这些数据表示当前方法(被调用的方法)中线程的状态:
-
操作数堆栈:我已经在关于基于堆栈的体系结构的章节中介绍了操作数堆栈。此堆栈由字节码指令用于处理参数。此堆栈还用于在 (java) 方法调用中传递参数,并在调用方法的堆栈顶部获取被调用方法的结果。
-
局部变量数组:此数组包含当前方法范围内的所有局部变量。此数组可以保存基元类型、引用或返回地址的值。此数组的大小是在编译时计算的。Java虚拟机使用局部变量在方法调用时传递参数,被调用方法的数组是从调用方法的操作数堆栈创建的。
-
运行时常量池引用:对正在执行的当前方法****的当前类的常量池的引用。JVM 使用它来将符号方法/变量引用(例如:myInstance.method())转换为实际内存引用。
叠
每个 Java 虚拟机线程都有一个私有 Java 虚拟机堆栈,与该线程同时创建。Java 虚拟机堆栈存储帧。每次调用方法时,都会创建一个新帧并将其放入堆栈中。当帧的方法调用完成时,无论该完成是正常还是突然(它会引发未捕获的异常),帧都会被销毁。
只有一个帧(执行方法的帧)在给定线程中的任何点处于活动状态。此帧称为*当前帧*,其方法称为*当前方法*。在其中定义当前方法的类是*当前类*。对局部变量和操作数堆栈的操作通常参考当前帧。
让我们看看下面的例子,这是一个简单的加法
public int add(int a, int b){
return a + b;
}
public void functionA(){
// some code without function call
int result = add(2,3); //call to function B
// some code without function call
}
以下是当函数A()运行时它在JVM中的工作方式:
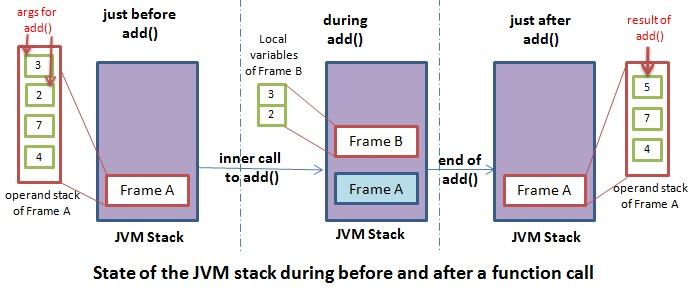
内部函数A() 帧 A 是堆栈帧的顶部,是当前帧。在内部调用添加 () 时,一个新帧(帧 B)被放置在堆栈中。帧 B 成为当前帧。帧 B 的局部变量数组是通过弹出帧 A 的操作数堆栈来填充的。当 add() 完成后,帧 B 将被销毁,帧 A 再次成为当前帧。add() 的结果放在 Frame A 的操作数堆栈上,以便 functionA() 可以通过弹出其操作数堆栈来使用它。
注意:这个堆栈的功能使它动态可扩展和收缩。存在堆栈不能超过的最大大小,这会限制递归调用的数量。如果超过此限制,JVM 将抛出一个 StackOverflowError。
使用 Oracle HotSpot,您可以使用参数 -Xss 指定此限制。
本机方法堆栈(每线程)
这是一个用Java以外的语言编写的本机代码的堆栈,并通过JNI(Java本机接口)调用。由于它是一个“本机”堆栈,因此此堆栈的行为完全依赖于底层操作系统。
结论
我希望本文能帮助您更好地了解 JVM。在我看来,最棘手的部分是JVM堆栈,因为它与JVM的内部功能密切相关。

- 点赞
- 收藏
- 关注作者
评论(0)