使用极狐GitLab定时爬取付费专栏榜,并制作图表分析,最终使用极狐GitLab Pages 展示

前言
作为一名大数据前端开发,我经常会尝试做一些分析案例,比如最近我在分析付费专栏榜单的数据,分析一下高销量, 高浏览量的专栏,想要得到一些 价格,销量,主题,文章数,阅读量 之间的一些关系,这也算数据挖掘吧。在这个过程中我用到了很多工具,整个过程我也学到了很多,现在把整个流程分享出来,供大家学习参考。
先说一下我的具体思路
首先要拿到热门专栏的数据,热门专栏榜单。该榜单会提供100条数据,每天都会变化,变化规则也是CSDN自己定义的。100条数据看请求是分页加载的,我试着使用PostMan直接请求接口,能够得到想要的结果。于是第一步获取数据轻松解决。
获取接口数据后,需要将数据保存到一个文件里,我定义了一个blogdata.json。使用nodejs的脚本将接口的json数据保存到文件里,全量覆盖地保存。这样就没有历史数据了。我们的目的也不是分析历史数据。
有了持久化的数据后,我们编写一个index.html页面,使用保存好的数据制作一个图表,横坐标是 专栏名称,纵坐标有多个,分别是订阅数,阅读数,文章数(很可惜,接口中没有提供价格属性,如果提供了分析效果会更好,可以做出专销售额折线图)
通过该图我们可以很轻松地找到最高销售量,最高阅读数,最多文章的专栏。
展示页面做好后,就可以实现自动化了,编写.gitlab-ci.yml,实现定时自动化获取数据,并搭配极狐GitLab Pages的功能,将做好的页面托管到极狐GitLab Pages,以此实现外网域名访问。
数据获取与保存
通过 F12看到获取榜单数据的接口为https://xxxx,
我们可以使用axios这个库直接发起请求,而数据保存,可以使用Nodejs 的 fs.writeFile来实现,保存到一个json文件里,后面我们使用ajax直接请求该json数据。
如下完整的 index.js 代码
const axios = require('axios').default
var fs = require('fs')
async function getData() {
try {
const link = `xxxx`
const { data } = await axios.get(link)
return data
} catch (error) {
console.log(error)
}
}
async function saveDataToFile(blogData) {
fs.writeFile('./blogdata.json', JSON.stringify(blogData), function (err) {
if (err) {
console.log(err)
} else {
console.log('写入成功')
}
})
}
async function init() {
const {
data: { payColumnRankListItemList },
} = await getData()
saveDataToFile(payColumnRankListItemList)
}
init()
图表展示
创建一个index.html文件,用于实现我们的图表,这里我们使用echarts作为图表库,使用jquery作为ajax库,blogdata.json作为数据源,其数据结构 是这样子的
[
{
"currentRank": 1,
"columnName": "R语言从入门到机器学习",
"hotRankScore": 22500,
"loginUserIsFollow": false,
"columnUrl": "https://blog.csdn.net/zhongkeyuanchongqing/category_11123154.html",
"nickName": "Data+Science+Insight",
"avatarUrl": "https://profile.csdnimg.cn/2/6/2/3_zhongkeyuanchongqing",
"articleCount": 1917,
"viewCount": 1298566,
"subscribeCount": 1079,
"userName": "zhongkeyuanchongqing",
"imgUrl": "https://img-blog.csdnimg.cn/60ad717d9cd645b9a1f5101ac493845c.png?x-oss-process=image/resize,m_fixed,h_224,w_224"
},
{....}
]
为了学到更多知识,我们对原数据结构不做改动,在图表配置上使用 echarts的数据源特性: dataset
index.html 中的核心代码
const option = {
grid: {
top: 80,
bottom: 80
},
legend: {
top: 30,
},
tooltip: {
trigger: 'axis',
},
dataset: {
dimensions: ['columnName', 'subscribeCount', 'viewCount', 'articleCount'],
source: []
},
xAxis: { type: 'category' },
yAxis: [
{
name: '订阅量',
type: 'value'
},
{
name: '阅读量',
type: 'value'
},
],
series: [
{
type: 'line',
smooth: true,
seriesLayoutBy: 'row',
yAxisIndex: 0,
emphasis: { focus: 'series' }
},
{
type: 'line',
smooth: true,
seriesLayoutBy: 'row',
yAxisIndex: 1,
emphasis: { focus: 'series' }
},
{
type: 'line',
smooth: true,
seriesLayoutBy: 'row',
yAxisIndex: 0,
emphasis: { focus: 'series' }
}
]
}
$.get('./blogdata.json', (data) => {
var myChart = echarts.init(document.getElementById('container'));
option.dataset.source = data
myChart.setOption(option);
})
echarts的数据源是一个非常好用的特性,使用它你可以不用修改后端返回的数据结构而直接使用,并且配置多折线图,多图例非常方便使用。
核心配置是这两句
dimensions: ['columnName', 'subscribeCount', 'viewCount', 'articleCount'] 选取数据源中的字段作为维度,第一个维度作为x轴,
要配置多个y轴,需要将 yAxis 配置成包含多个元素的数组,并在 series中使用下标来使用对应的y周,如yAxisIndex: 1
又学到了。
流水线功能
我们获取了数据,保存了数据,也将数据展示到页面上了。接下来我们需要将这一过程自动化,并设置为每天获取一次。
编写 .gitlab-ci.yml文件
default:
interruptible: false
tags:
- for-live-runner
cache:
key:
files:
- yarn.lock
paths:
- node_modules
getdata:
image: node:12.21.0-alpine3.12
stage: build
script:
- yarn
- node index.js
artifacts:
paths:
- blogdata.json
pages:
stage: test
script:
- mkdir .public
- cp -r * .public
- mv .public public
artifacts:
paths:
- public
在getdata作业里,我们安装依赖包,并执行index.js文件。结束后再把最新的blogdata.json做成制品,供下一阶段使用。
作业pages 是使用了极狐GitLab Pages的功能,一个免费的网站托管服务。
开发者只需要将要托管的完整文件 存放到 public文件夹里,并使用artifacts将其做成制品。就是使用该功能了。
然后我们配置定时运行流水线,每天北京时间晚上2点执行一次。

效果图展示
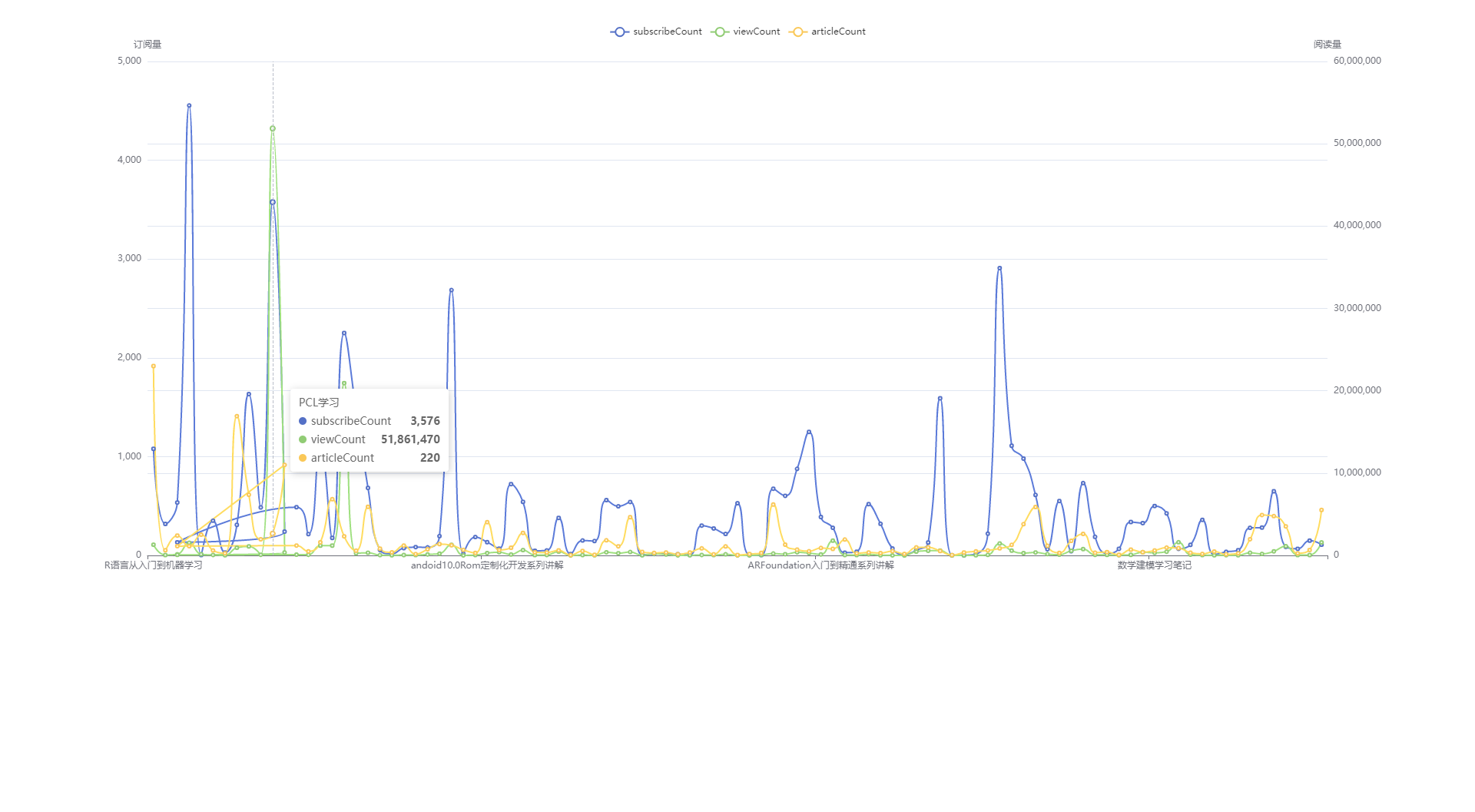
访问地址 https://pmcfizz.gitlab.io/blog/
通过该图我们可以很清楚地看到,那个专栏销量最高,阅读量最高,文章最多。
后记
该项目我已经上传到极狐GitLab,大家可以下载学习研究。项目地址
对于数据分析,数据挖掘我并不擅长,希望能够抛砖引玉,路过的大佬分析,指点一下。
技术,要学以致用,为实际问题所服务。在实践中学习,要比死记硬背更加有效。

- 点赞
- 收藏
- 关注作者
评论(0)