【愚公系列】2022年06月 .NET架构班 070-分布式中间件 Elasticsearch集群数据存储原理和分片

【摘要】 一、Elasticsearch存储数据原理核心细节如下:shard = hash(routing) % number_of_primary_shards1、先Hash,先对文档_idHash,2、然后取模,然后对分片数取模流程如下:以下是在主副分片和任何副本分片上面成功新建,索引和删除文档所需要的步骤顺序:客户端向 Node 1 发送新建、索引或者删除请求。节点使用文档的 _id 确定文档...
一、Elasticsearch存储数据原理
核心细节如下:
shard = hash(routing) % number_of_primary_shards
1、先Hash,先对文档_idHash,
2、然后取模,然后对分片数取模
流程如下:
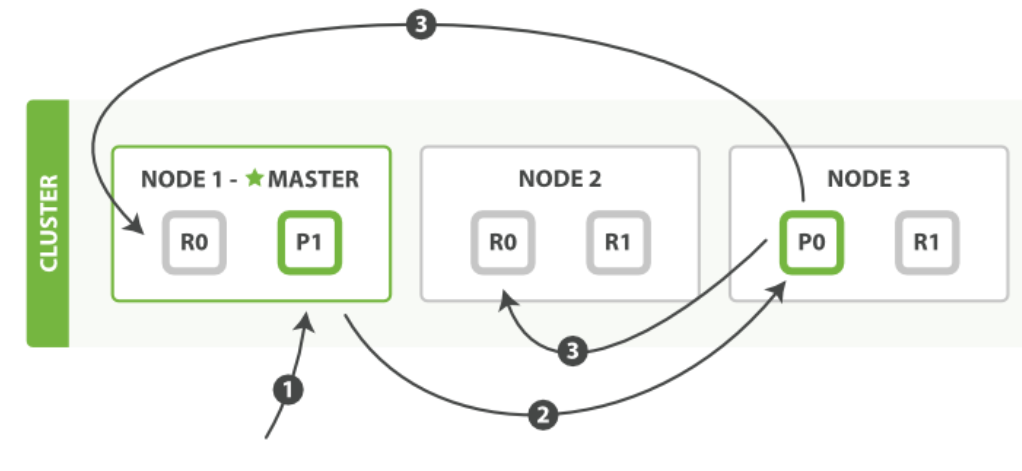
以下是在主副分片和任何副本分片上面成功新建,索引和删除文档所需要的步骤顺序:
- 客户端向 Node 1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
二、Elasticsearch查询数据原理
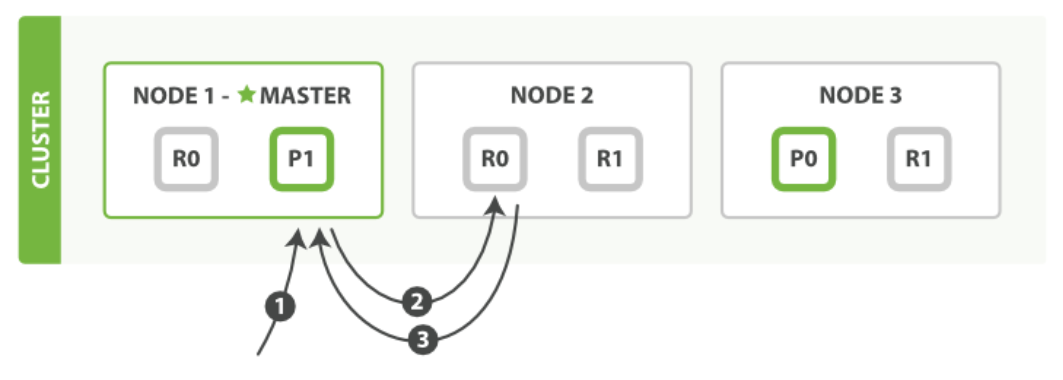
原理图如下:
流程如下:
以下是从主分片或者副本分片检索文档的步骤顺序:
1、客户端向 Node 1 发送获取请求。
2、节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到 Node 2 。
3、Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
三、集群分片
1.集群分片-情况1
情况1:集群分片默认只有一个主分片,一个副本分片,如果遇到海量商品存储,一个分片无法存储,如何存储海量数据?
方案:多分片机制
1、进入到kibana中进行,创建新数据库,输入
PUT products_cluster_0
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
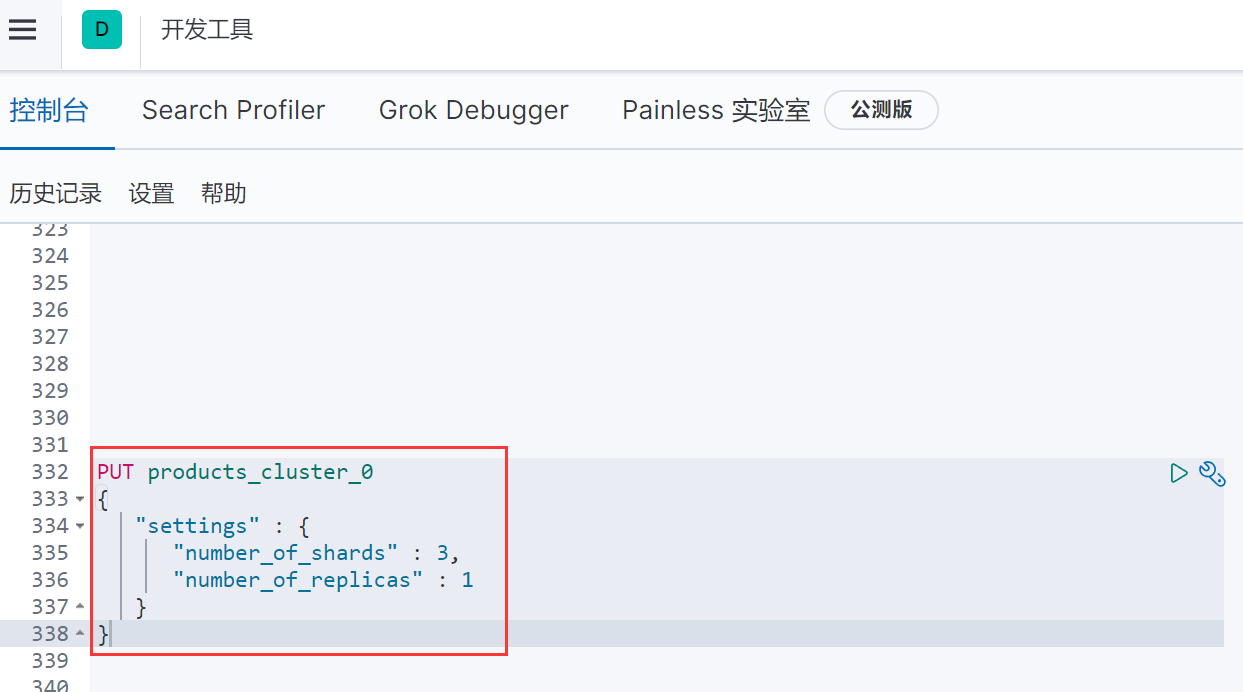
说明:
- number_of_shards代表分片数量
- number_of_replicas代表分表副本
2、然后在elasticsearch-head查看结果
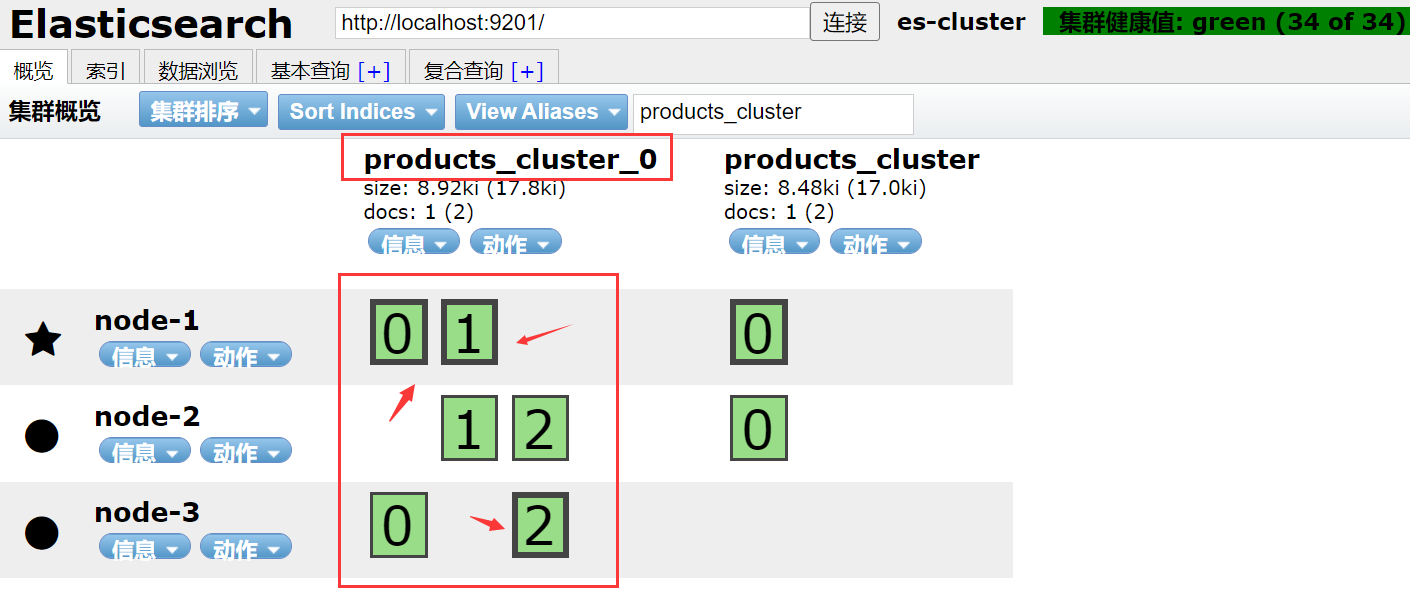
粗线0,1,2代表主分片
细线0,1,2代表副本分片

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)