5000+ 字解读 | 产品经理:如何做好元器件选型?


卫朋丨第112篇原创文章
阅读提示丨5775字 30分钟
实操干货,大家可先收藏
虚实结合,打造最强产品人
上到战略规划,下至元器件选型,本号力图为读者呈现一整套的产品落地化打法。
市面上的内容 90% 以上都是启发式的,而启发式最大的问题是很难落地,对个体悟性要求极高。
有一句万金油式的说法“量变引起质变”,问题是绝大多数人都等不到质变的点。
更有效的学习方式是“实践+失败+再实践”的轮回,这也是每个人从小畜成长起来的底层逻辑。
这也是本号想要解决的问题,通过“启发+实践”的新形式带大家高效进阶。
言归正传,今天聊聊产品选型的落地打法。
最近在做产品的低成本替代方案,涉及到元器件的重新选型。
这里卫 Sir 以电子部分的语音模块为例,带大家全面了解一下选型过程。
这部分内容偏技术侧,你可能暂时用不到,建议收藏以备不时之需。
目录如下:
1. 选型基础
2. 语音基础知识扫盲
3. 方案 A
4. 方案 B
1. 选型基础
首先,选型要以整体方案为基准,没有这个基点,后续的所有工作都是白费。
其次,你需要明确选型的目的。
本篇案例主要针对降成本,其中隐含两个层面的信息。
一个是满足降成本业务层面的需求;
一款产品一般由几百甚至几千个元件组成,这些元件必须按期备齐,以便制造产品。

哪怕缺失一个小小的阻容件,生产也无法正常开展。
不仅所有生产所需元件需要按时到位,而且要保证这些元件尽可能价格低廉。
在这个过程中你会面临多个挑战:
(1)元件来自多家供应商,经常有几十个供应商为一款产品供应元件;
(2)通常元件购买支出占产品总成本的最大头,采购者需要跟供应商协商争取一个好价格,不然就会产生不必要的成本支出;
(3)某个元件供应商突然中断供货,比如经销商把所有存货卖给一个大客户或地震造成工厂停工等,这时必须尽快找到其他供应商,以免影响正常生产;
(4)所用元件都可能被淘汰,供应链的工作人员需要负责找到合格的可替代元件,并且可能需要工程师参与修改元件的重新设计工作;
(5)元件的交货期不一样,常见元件可能第二天就到货,甚至当天就到,但是有些元件,比如定制的 LCD 可能要等上几个月。
以 LCD 为例,如果你发现到货的 LCD 有缺陷,则可能需要再等上几个月才能拿到合格的元件。
(6)确保元件是正品,市面上会有一些品质低劣的货源,可能会引发安全性和可靠性问题。
如果发货的产品包含劣质元件,可能会导致产品召回,甚至是更严重的后果。
针对上述问题,你可能已经想到了一种简单的解决办法,那就是在项目开始时就预定好生产需要用到的所有元件,然后把它们存放在库房中。
这样生产时可以直接从库房取用已经备好的元件,这样就永远不会出现元件供应中断的问题了,因为所有元件都可以随时从库房中取用。
但是,就财务和管理来说,库存一般是需要花钱买来的,而且在做成成品之前,这些元件无法直接带来任何收益。
换句话说,库存就意味着把投入的资金摆在货架上,不但无法产生收益,而且占空间。
从财务和管理的角度看,最理想的情况是元件到达的当天就投入使用,它们存入库房的时间最多几个小时。
正常情况下,你可以存放可供几天生产的元件库存,以便元件的供应不中断。
而那些比较少见的元件可存放较大量的库存,因为供给链断裂产生的风险也相应较高。
与制造商和分销商进行谈判:
-
一方面要确保所需元件能够正常供应;
-
另一方面要尽可能地减少购买支出。
在元件供应问题解决之后,你就有了生产所需的所有元件,接下来就要开始生产了。
另一个是满足最低使用要求,如果客户不认可,也代表选型失败。
继续以语音选型为例。
2. 语音基础知识扫盲

将语音应用于智能硬件就绕不开模拟信号的数字化,也就是指语音信号的量化。
涉及的三个关键词分别是:
-
采样:将语音模拟信号转化成数字信号;
-
采样率(f):每秒采样的个数(byte);
-
波特率(T):每秒钟采样的位数(bit),波特率直接决定音质,bps: bit per second。
-
采样位数(n):是指在二进制条件下的位数,一般在没有特别说明的情况下,声音的采样位数指 8 位,由 00H--FFH,静音定为 80H。
采样率
嗓音的频带宽度为 20~20KHZ 左右,人们说话的语音频率范围是300Hz~3400Hz,比如电话机电路就是按照这个指标设计的。
根据奈奎斯特定律,采样频率只要高于最高频率的两倍,就可以实现声音不失真还原。
而小于两倍频谱最高频率时,信号的频谱就会有混叠。
因此,只要采样率大于 6.8k=3.4k*2,即可还原电话语音。
一般针对普通的语音 IC,采样率做到 16K 就足够了。
说话声一般取 8K(如电话音质)或 6K 左右,低于 6K 效果比较差。
在应用到单片机的过程中,采样越高,定时器中断速度越快,会影响到其他信号的监控和检测,所以要综合考虑。
考虑到硬件损耗和破音情况,一般将语音转化为数字声音时,采样频率至少需要 8KHz,采样位数为 16 位。
也就是说 1 秒就可以采集 15.625KB 的数据。
8000*16=128000bit=128000bit/8=16000byte=16000byte/1024=15.625K。
语音压缩技术
由于语音数据量庞大,对语音数据进行有效压缩是很有必要的,能够在有限的 ROM 空间里录入更多的语音内容。
以唯创生成的语音 bin 文件为例,对于采样率为 8KHz,采样位数为 16bit 的语音文件,实际码率为 8*16=128kbps,而设置的目标码率为 16kbps,数据压缩率在 8 倍左右。
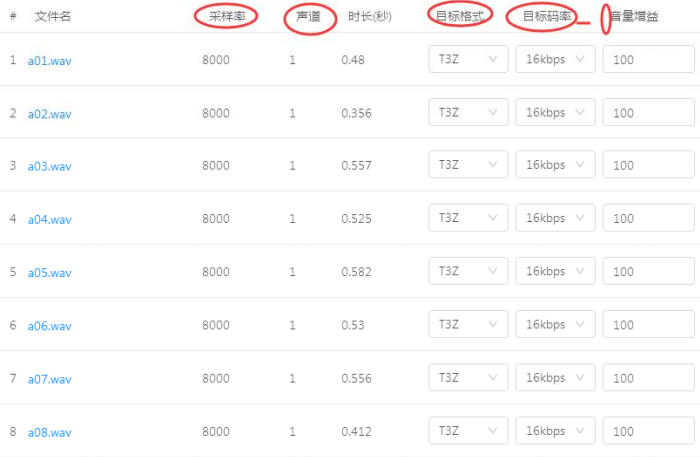
压缩有以下几种方式:
(1)语音分段
将语音中可以重复的部分截取出来,通过排列组合将内容完整地回放出来;
(2)语音采样
一般使用的喇叭频响曲线在中频部分,较少用到高频。
所以,在喇叭音质可以接受的情况下,适当降低采样频率,达到压缩效果,这种过程是不可逆的,无法恢复原貌,叫有损压缩;
(3)数学压缩
主要是针对采样位数进行压缩,这种方式也是有损压缩。例如,采用 ADPCM 压缩格式,是将语音数据从 16bit 压缩到 4bit,压缩率是 4 倍。
MP3 是对数据流进行压缩,涉及到数据预测问题,它的波特率压缩倍率为 10 倍左右。
以 Speex 进行压缩为例:
下载地址:
https://www.speex.org/downloads/
Speex 是一套主要针对语音的开源免费,无专利保护的音频压缩格式。
Speex 工程着力于通过提供一个可以替代高性能语音编解码来降低语音应用输入门槛 。
另外,相对于其它编解码器,Speex 也很适合网络应用,在网络应用上有着自己独特的优势。
同时,Speex 还是 GNU 工程的一部分,在改版的 BSD 协议中得到了很好的支持。
Speex 是基于 CELP 并且专门为码率在 2-44kbps 的语音压缩而设计的。
它的特点有:
-
窄带(8kHz),宽带(16kHz)和超宽带(32kHz)压缩于同一位流;
-
强化立体编码;
-
数据包丢失隐蔽;
-
可变比特率(VBR);
-
语音捕捉(VAD);
-
非连续传输(DTX);
-
定点运算;
-
感官回声消除(AEC);
-
噪音屏蔽。
因为 speex 的压缩率为16:1。
文章来源: blog.csdn.net,作者:产品人卫朋,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/liwei16611/article/details/125510018

- 点赞
- 收藏
- 关注作者
评论(0)