大数据物流项目:Structured Streaming(内置数据源、自定义Sink(2种方式)和集成Kafka)(十三)

## 05-[了解]-内置数据源之Rate Source 使用
> `以每秒指定的行数生成数据,`每个输出行包含2个字段:timestamp和value。其中timestamp是一个Timestamp含有信息分配的时间类型,并且value是Long(包含消息的计数从0开始作为第一
> 行)类型。

> 演示范例代码如下:
```scala
package cn.itcast.spark.source
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 数据源:Rate Source,以每秒指定的行数生成数据,每个输出行包含一个timestamp和value。
*/
object _03StructuredRateSource {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,相关配置进行设置
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle时分区数目
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
// TODO:从Rate数据源实时消费数据
val rateStreamDF: DataFrame = spark.readStream
.format("rate")
.option("rowsPerSecond", "10")
.option("numPartitions", "2")
.load()
// TODO: 将结果输出(ResultTable结果输出,此时需要设置输出模式)
val query: StreamingQuery = rateStreamDF.writeStream
.outputMode(OutputMode.Append()) // 当数据更新时再进行输出: mapWithState
.format("console")
.option("numRows", "500")
.option("truncate", "false")
.start()
// 启动流式应用后,等待终止
query.awaitTermination()
query.stop()
}
}
```
## 06-[掌握]-基础特性之名称、触发、检查点及输出模式设置
> 在StructuredStreaming中定义好Result DataFrame/Dataset后,调用writeStream()返回DataStreamWriter对象,设置查询Query输出相关属性,启动流式应用运行,相关属性如下:
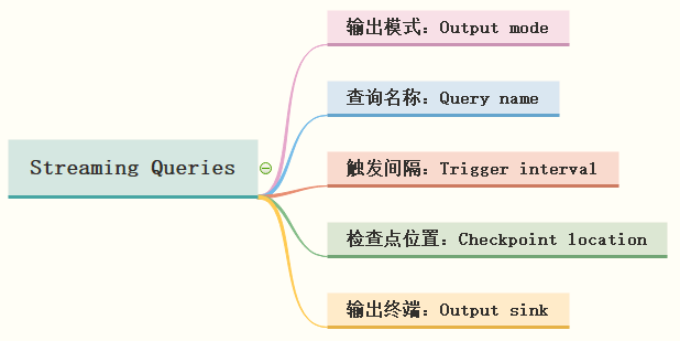
### 第一、输出模式
> "`Output`"是用来定义写入外部存储器的内容,输出可以被定义为不同模式:

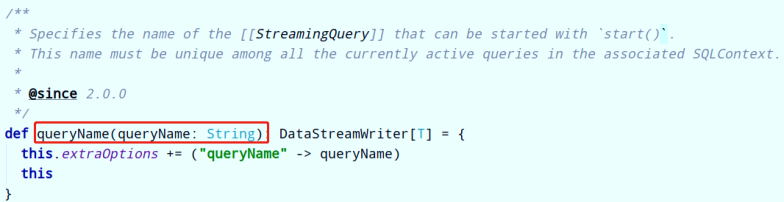
### 第二、查询名称
> 可以给每个查询Query设置名称Name,必须是唯一的,直接调用`DataFrameWriter`中`queryName`方法即可,实际生产开发建议设置名称,API说明如下:
### 第三、触发间隔
> `触发器Trigger决定了多久执行一次查询并输出结果`,当不设置时,`默认只要有新数据`,就立即执行查询Query,再进行输出。目前来说,支持三种触发间隔设置:

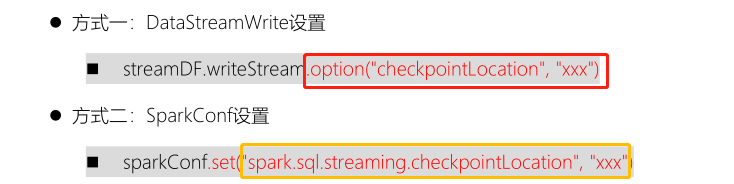
### 第四、检查点位置
> 在Structured Streaming中使用Checkpoint 检查点进行故障恢复。如果实时应用发生故障或关机,可以恢复之前的查询的进度和状态,并从停止的地方继续执行,使用Checkpoint和预写日志WAL完成。
此检查点位置必须是HDFS兼容文件系统中的路径,两种方式设置Checkpoint Location位置:
> 修改上述词频统计案例程序,设置输出模式、查询名称、触发间隔及检查点位置,演示代码如下:
```scala
package cn.itcast.spark.output
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果打印到控制台。
* 设置输出模式、查询名称、触发间隔及检查点位置
*/
object _04StructuredQueryOutput {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,相关配置进行设置
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle时分区数目
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
// 从TCP Socket加载数据,读取数据列名称为value,类型是String
val inputStreamDF: DataFrame = spark.readStream
.format("socket")
.option("host", "node1.itcast.cn")
.option("port", 9999)
.load()
// 进行词频统计
val resultStreamDF: DataFrame = inputStreamDF
.as[String] // 将DataFrame转换为Dataset
.filter(line => null != line && line.trim.length > 0 )
.flatMap(line => line.trim.split("\\s+"))
// 按照单词分组和聚合
.groupBy($"value").count()
resultStreamDF.printSchema()
// 将结果输出(ResultTable结果输出,此时需要设置输出模式)
val query: StreamingQuery = resultStreamDF.writeStream
// TODO: a. 设置输出模式, 当数据更新时再进行输出
.outputMode(OutputMode.Update())
// TODO: b. 设置查询名称
.queryName("query-wordcount")
// TODO: c. 设置触发时间间隔
.trigger(Trigger.ProcessingTime("0 seconds"))
.format("console")
.option("numRows", "10")
.option("truncate", "false")
// TODO: d. 设置检查点目录
.option("checkpointLocation", "datas/ss-ckpt/0001")
.start()
// 启动流式应用后,等待终止
query.awaitTermination()
query.stop()
}
}
```
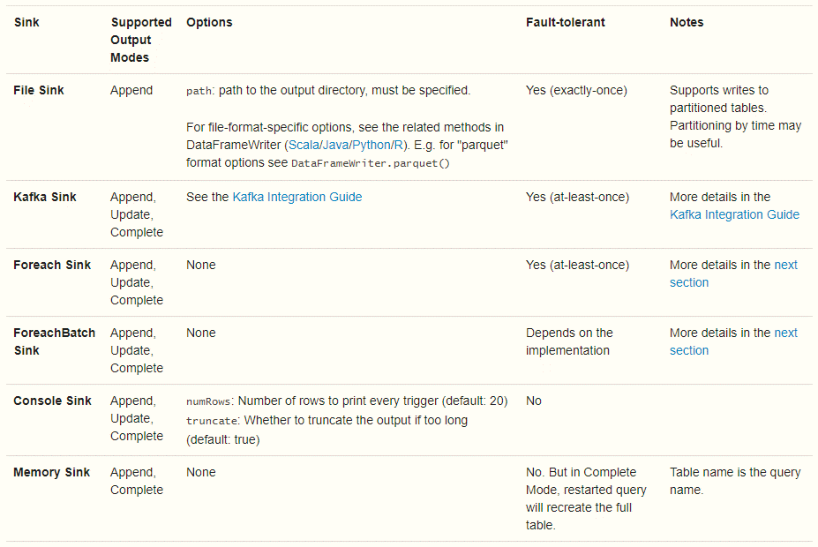
## 07-[了解]-自定义Sink之综合概述
> 目前Structured Streaming内置FileSink、Console Sink、`Foreach Sink(ForeachBatch Sink)`、Memory Sink及`Kafka Sink`,其中测试最为方便的是`Console Sink`。
```
其中最终重要三个Sink:
第一个、Console Sink
直接将流式数据集打印到控制台
测试开发使用
第二个、Foreach Sink / ForeachBatch Sink
提供自定义流式数据输出接口
Foreach Sink ,表示针对每条数据操作
ForeachBatch Sink,表示针对每个微批处理结果数据操作
第三个、Kafka Sink
将流式数据写入到Kafka Topic中
```
### File Sink(文件接收器)
> 将输出存储到目录文件中,支持文件格式:parquet、orc、json、csv等,示例如下:

### Memory Sink(内存接收器)
> 输出作为内存表存储在内存中, 支持Append和Complete输出模式。

## 08-[掌握]-自定义Sink之foreach使用
> Structured Streaming提供接口`foreach`和`foreachBatch`,允许用户在流式查询的输出上应用任意操作和编写逻辑,比如输出到MySQL表、Redis数据库等外部存系统。
>
> - `foreach`允许每行自定义写入逻辑(每条数据进行写入)
> - `foreachBatch`允许在`每个微批量的输出`上进行任意操作和自定义逻辑,从Spark 2.3版本提供
```
foreach表达自定义编写器逻辑具体来说,需要编写类class继承ForeachWriter,其中包含三个方法来表达数据写入逻辑:打开,处理和关闭。
```

> 演示案例:将前面词频统计结果输出到MySQL表【`db_spark.tb_word_count`】中。
```scala
package cn.itcast.spark.sink.foreach
import java.util.concurrent.TimeUnit
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果存储到MySQL数据库表中
*/
object _05StructuredMySQLSink {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,相关配置进行设置
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle时分区数目
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
// 从TCP Socket加载数据,读取数据列名称为value,类型是String
val inputStreamDF: DataFrame = spark.readStream
.format("socket")
.option("host", "node1.itcast.cn")
.option("port", 9999)
.load()
// 进行词频统计
val resultStreamDF: DataFrame = inputStreamDF
.as[String] // 将DataFrame转换为Dataset
.filter(line => null != line && line.trim.length > 0 )
.flatMap(line => line.trim.split("\\s+"))
// 按照单词分组和聚合
.groupBy($"value").count()
//resultStreamDF.printSchema()
// 将结果输出(ResultTable结果输出,此时需要设置输出模式)
val query: StreamingQuery = resultStreamDF.writeStream
// a. 设置输出模式, 当数据更新时再进行输出: mapWithState
.outputMode(OutputMode.Update())
// b. 设置查询名称
.queryName("query-wordcount")
// c. 设置触发时间间隔
.trigger(Trigger.ProcessingTime(0, TimeUnit.SECONDS))
// TODO: 使用foreach方法,自定义输出结果,写入MySQL表中
// def foreach(writer: ForeachWriter[T]): DataStreamWriter[T]
.foreach(new MySQLForeachWriter())
// d. 设置检查点目录
.option("checkpointLocation", "datas/spark/structured-ckpt-1002")
.start()
// 启动流式应用后,等待终止
query.awaitTermination()
query.stop()
}
}
```
> 其中自定义输出Writer:`MySQLForeachWriter`,代码如下;
```scala
package cn.itcast.spark.sink.foreach
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.sql.{ForeachWriter, Row}
/**
* 创建类继承ForeachWriter,将数据写入到MySQL表中,泛型为:Row,针对DataFrame操作,每条数据类型就是Row
*/
class MySQLForeachWriter extends ForeachWriter[Row] {
// 定义变量
var conn: Connection = _
var pstmt: PreparedStatement = _
val jdbcUrl: String = "jdbc:mysql://node1.itcast.cn:3306/db_spark?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true"
val insertSQL = "REPLACE INTO `tb_word_count` (`id`, `word`, `count`) VALUES (NULL, ?, ?)"
// 获取MySQL数据连接, 如果获取连接成功,返回true,进行向下执行
override def open(partitionId: Long, epochId: Long): Boolean = {
// step1. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// step2. 获取连接
conn = DriverManager.getConnection(
jdbcUrl, "root", "123456"
)
// step3. 构建PreparedStatement对象
pstmt = conn.prepareStatement(insertSQL)
// TODO: 返回true,表示连接获取成功
true
}
// 如何将每条数据写入到MySQL表中
override def process(row: Row): Unit = {
// step4. 设置每条数据值得值到Statement对象中
pstmt.setString(1, row.getString(0))
pstmt.setInt(2, row.getInt(1))
// step5. 执行插入
pstmt.executeUpdate()
}
// 写入结束,关闭数据库连接
override def close(errorOrNull: Throwable): Unit = {
// step6. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
```
## 09-[掌握]-自定义Sink之foreachBatch使用
> 方法`foreachBatch`允许指定在流式查询的每个微批次的输出数据上执行的函数,需要两个参数:**微批次的输出数据DataFrame或Dataset、微批次的唯一ID**。

使用`foreachBatch`函数输出时,以下几个注意事项:
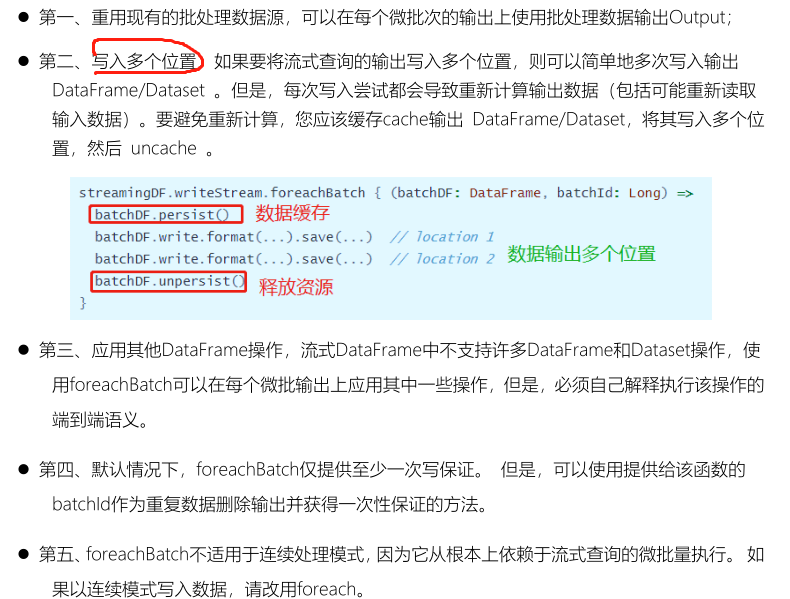
> **范例演示**:使用foreachBatch将词频统计结果输出到MySQL表中,代码如下:
```scala
package cn.itcast.spark.sink.batch
import java.util.concurrent.TimeUnit
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果存储到MySQL数据库表中
*/
object _06StructuredForeachBatch {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,相关配置进行设置
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle时分区数目
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
// 从TCP Socket加载数据,读取数据列名称为value,类型是String
val inputStreamDF: DataFrame = spark.readStream
.format("socket")
.option("host", "node1.itcast.cn")
.option("port", 9999)
.load()
// 进行词频统计
val resultStreamDF: DataFrame = inputStreamDF
.as[String] // 将DataFrame转换为Dataset
.filter(line => null != line && line.trim.length > 0 )
.flatMap(line => line.trim.split("\\s+"))
// 按照单词分组和聚合
.groupBy($"value").count()
resultStreamDF.printSchema()
// 将结果输出(ResultTable结果输出,此时需要设置输出模式)
val query: StreamingQuery = resultStreamDF.writeStream
// a. 设置输出模式, 当数据更新时再进行输出: mapWithState
.outputMode(OutputMode.Complete())
// b. 设置查询名称
.queryName("query-wordcount")
// c. 设置触发时间间隔
.trigger(Trigger.ProcessingTime(0, TimeUnit.SECONDS))
// TODO: 使用foreachBatch方法,将结果数据,写入MySQL表中
// def foreachBatch(function: (Dataset[T], Long) => Unit): DataStreamWriter[T]
.foreachBatch{(batchDF: DataFrame, batchId: Long) =>
batchDF
.coalesce(1)
.write
.mode(SaveMode.Overwrite)
.format("jdbc")
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "tb_wordcount_v2")
.save()
}
// d. 设置检查点目录
.option("checkpointLocation", s"datas/spark/structured-ckpt-${System.currentTimeMillis()}")
.start()
// 启动流式应用后,等待终止
query.awaitTermination()
query.stop()
}
}
```
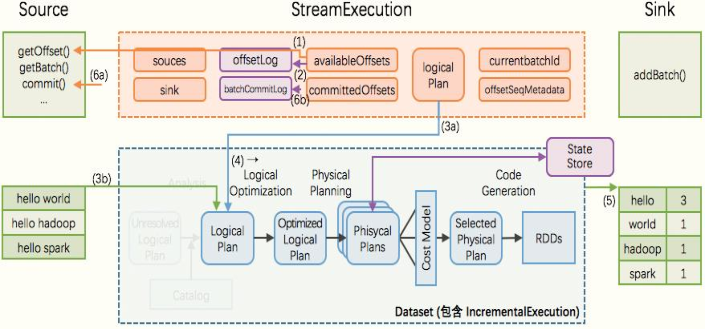
## 10-[掌握]-基础特性之StructuredStreaming保证容错语义
> 针对任何流式应用处理框架(Storm、SparkStreaming、StructuredStreaming和Flink等)处理数据时,都要考虑语义,任意流式系统处理流式数据三个步骤:
>
> [容错语言,表示的是,当流式应用重启执行时,数据是否会被处理多次或少处理,以及处理多次时对最终结果是否有影响]()
>
> `容错语义:流式应用重启以后,最好数据处理一次,如果处理多次,对最终结果没有影响`

> 在处理数据时,往往需要保证数据处理一致性语义`:从数据源端接收数据,经过数据处理分析,到最终数据输出仅被处理一次,是最理想最好的状态`。
>
> 在Streaming数据处理分析中,需要`考虑数据是否被处理及被处理次数,称为消费语义`,主要有三种:

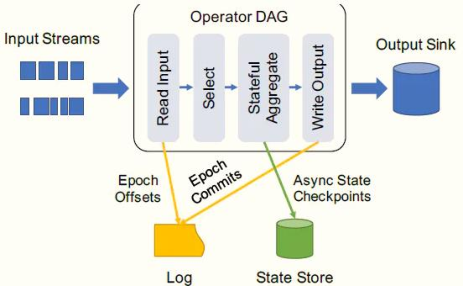
目前Streaming应用系统中提出:End-to-End Exactly Once,端到端精确性一次语义。
> Structured Streaming的核心设计理念和目标之一:`支持一次且仅一次Extracly-Once的语义,并且是端到端`。
```
1、每个Streaming source都被设计成支持offset,进而可以让Spark来追踪读取的位置;
2、Spark基于checkpoint和wal来持久化保存每个trigger interval内处理的offset的范围;
```
```
3、sink被设计成可以支持在多次计算处理时保持幂等性,就是说,用同样的一批数据,无论多少次去更新sink,都会保持一致和相同的状态。
```
> [基于offset的source,基于checkpoint和wal的execution engine,以及基于幂等性的sink,可以支持完整的一次且仅一次的语义。]()
## 11-[掌握]-集成Kafka之Kafka Source
> StructuredStreaming集成Kafka,官方文档如下:http://spark.apache.org/docs/2.4.5/structured-streaming-kafka-integration.html
目前仅支持Kafka 0.10.+版本及以上,底层使用Kafka New Consumer API拉取数据,StructuredStreaming既可以从Kafka读取数据,又可以向Kafka 写入数据,添加Maven依赖:
```xml
<!-- Structured Streaming + Kafka 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
```
Maven Project工程中目录结构如下:
> Structured Streaming消费Kafka数据,采用的是`poll方式拉取数据`,与Spark Streaming中NewConsumer API集成方式一致。
>
> [StructuredStreaming仅仅支持Kafka New Consumer API,采用poll拉取方式获取数据,依据偏移量范围获取数据,与SparkStreaming中Direct 方式获取数据是一致的。]()
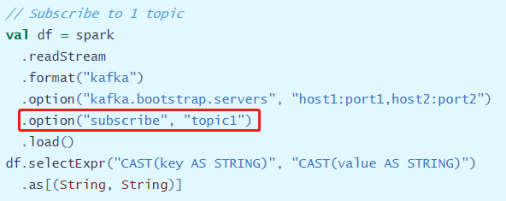
官方提供三种方式从Kafka topic中消费数据,主要区别在于每次消费Topic名称指定,
- 方式一:消费一个Topic数据
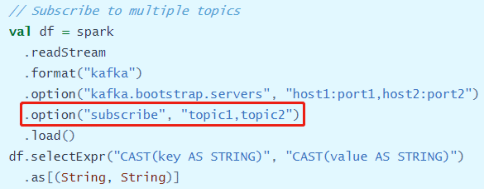
- 方式二:消费多个Topic数据
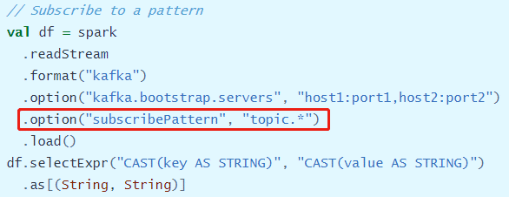
- 方式三:消费通配符匹配Topic数据
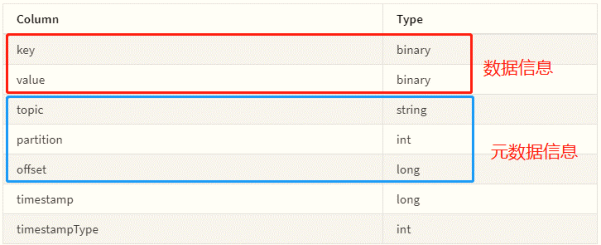
> 从Kafka 获取数据后Schema字段信息如下,既包含数据信息有包含元数据信息:
> [查看官方提供从Kafka消费数据代码可知,获取Kafka数据以后,封装到DataFrame中,获取其中value和key的值,首先转换为String类型,然后再次转换为Dataset数据结构,方便使用DSL和SQL编程处理]()

> 范例演示:从Kafka消费数据,进行词频统计,Topic为wordsTopic。
```scala
package cn.itcast.spark.kafka.source
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用Structured Streaming从Kafka实时读取数据,进行词频统计,将结果打印到控制台。
*/
object _07StructuredKafkaSource {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,相关配置进行设置
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle时分区数目
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
// TODO: 从Kafka 加载数据
val kafkaStreamDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("subscribe", "wordsTopic")
.load()
// 进行词频统计
val resultStreamDF: DataFrame = kafkaStreamDF
.selectExpr("CAST(value AS STRING)")
.as[String]
.filter(msg => null != msg && msg.trim.length > 0)
.flatMap(msg => msg.trim.split("\\s+"))
.groupBy($"value").count()
// 将结果输出(ResultTable结果输出,此时需要设置输出模式)
val query: StreamingQuery = resultStreamDF.writeStream
// 设置输出模式, 当数据更新时再进行输出: mapWithState
.outputMode(OutputMode.Update())
// 设置查询名称
.queryName("query-wordcount-kafka")
// 设置触发时间间隔
//.trigger(Trigger.ProcessingTime("5 seconds"))
.format("console")
.option("numRows", "10")
.option("truncate", "false")
// 设置检查点目录
.option("checkpointLocation", s"datas/spark/structured-ckpt-${System.nanoTime()}")
.start()
// 启动流式应用后,等待终止
query.awaitTermination()
query.stop()
}
}
```
> 与前面从TCP Socket读取数据相比,进行修改数据源获取数据代码:

## 12-[掌握]-集成Kafka之Kafka Sink 概述
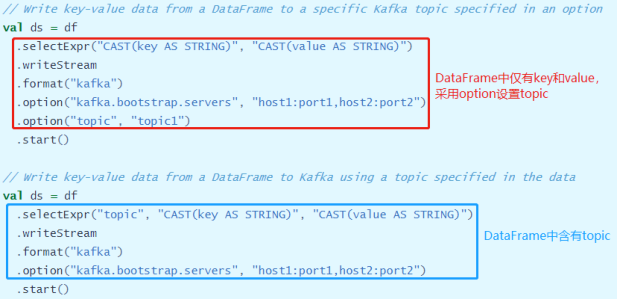
> 往Kafka里面写数据类似读取数据,可以在DataFrame上调用`writeStream`来写入Kafka,`设置参数指定value`,其中key是可选的,如果不指定就是null。
[将DataFrame写入Kafka时,Schema信息中所需的字段:]()

需要写入哪个topic,可以像上述所示在操作DataFrame 的时候在每条record上加一列topic字段指定,也可以在DataStreamWriter上指定option配置。
## 13-[掌握]-集成Kafka之实时增量ETL
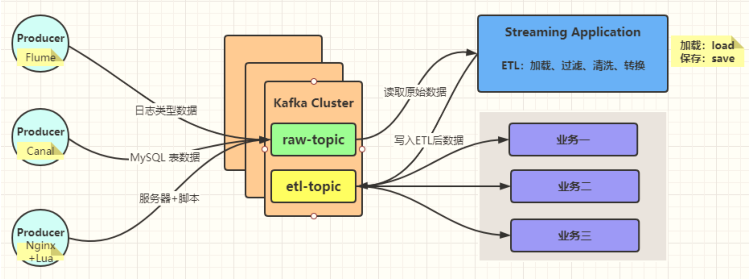
> 在实际实时流式项目中,无论使用Storm、SparkStreaming、Flink及Structured Streaming处理流式数据时,往往先从Kafka 消费原始的流式数据,经过ETL后将其存储到Kafka Topic中,以便其他业务相关应用消费数据,实时处理分析,技术架构流程图如下所示:
```
如果大数据平台,流式应用有多个,并且处理业务数据是相同的,建议先对原始业务数据进行ETL转换处理存储到Kafka Topic中,其他流式用直接消费ETL后业务数据进行实时分析即可。
```
> 需求:接下来模拟产生运营商基站数据,实时发送到Kafka 中,使用StructuredStreaming消费,经过ETL(获取通话状态为success数据)后,写入Kafka中,便于其他实时应用消费处理分析。
- 模拟产生基站数据,发送到Kafka Topic中
```scala
package cn.itcast.spark.kafka.mock
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/**
* 模拟产生基站日志数据,实时发送Kafka Topic中,数据字段信息:
* 基站标识符ID, 主叫号码, 被叫号码, 通话状态, 通话时间,通话时长
*/
object MockStationLog {
def main(args: Array[String]): Unit = {
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "node1.itcast.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random = new Random()
val allStatus =Array(
"fail", "busy", "barring", "success", "success", "success",
"success", "success", "success", "success", "success", "success"
)
while (true){
val callOut: String = "1860000%04d".format(random.nextInt(10000))
val callIn: String = "1890000%04d".format(random.nextInt(10000))
val callStatus: String = allStatus(random.nextInt(allStatus.length))
val callDuration = if("success".equals(callStatus)) (1 + random.nextInt(10)) * 1000L else 0L
// 随机产生一条基站日志数据
val stationLog: StationLog = StationLog(
"station_" + random.nextInt(10), //
callOut, //
callIn, //
callStatus, //
System.currentTimeMillis(), //
callDuration //
)
println(stationLog.toString)
Thread.sleep(10 + random.nextInt(100))
val record = new ProducerRecord[String, String]("stationTopic", stationLog.toString)
producer.send(record)
}
producer.close() // 关闭连接
}
}
```
- 实时增量ETL
> 编写应用实时从Kafka的【stationTopic】消费数据,经过处理分析后,存储至Kafka的【etlTopic】,其中需要设置检查点目录,保证应用一次且仅一次的语义。
```scala
package cn.itcast.spark.kafka.sink
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 实时从Kafka Topic消费基站日志数据,过滤获取通话转态为success数据,再存储至Kafka Topic中
* 1、从KafkaTopic中获取基站日志数据(模拟数据,JSON格式数据)
* 2、ETL:只获取通话状态为success日志数据
* 3、最终将ETL的数据存储到Kafka Topic中
*/
object _08StructuredEtlSink {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
// TODO: 1. 从KafkaTopic中获取基站日志数据(模拟数据,文本数据)
val kafkaStreamDF: DataFrame = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("subscribe", "stationTopic")
.option("maxOffsetsPerTrigger", "10000")
.load()
// TODO: 2. ETL:只获取通话状态为success日志数据
val etlStreamDF: Dataset[String] = kafkaStreamDF
.selectExpr("CAST(value AS STRING)") // 提取value字段值,并且转换为String类型
.as[String] // 转换为Dataset
.filter{msg =>
null != msg && msg.trim.split(",").length == 6 && "success".equals(msg.trim.split(",")(3))
}
// TODO:作业【自定义UDF函数实现上述过滤功能】
// TODO: 3. 最终将ETL的数据存储到Kafka Topic中
val query: StreamingQuery = etlStreamDF
.writeStream
.queryName("query-state-etl")
.outputMode(OutputMode.Append())
.trigger(Trigger.ProcessingTime(0))
// TODO:将数据保存至Kafka Topic中
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("topic", "etlTopic")
.option("checkpointLocation", "datas/ckpt-kafka/10001")
.start()
query.awaitTermination()
query.stop()
}
}
```

- 点赞
- 收藏
- 关注作者
评论(0)