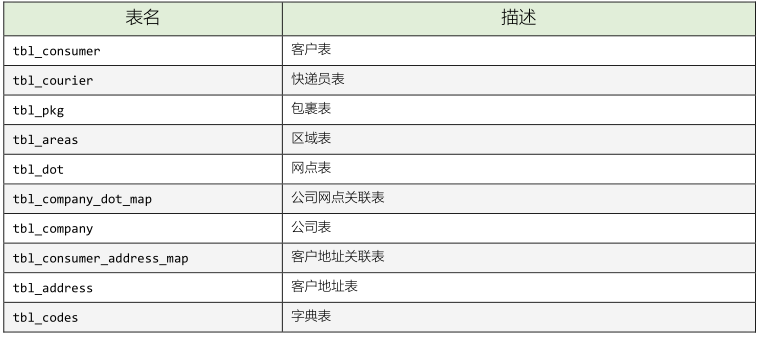
大数据物流项目:主题及指标开发之如何对Kudu表数据分析【离线报表分析(1个主题)】(十)

# Logistics_Day10:主题及指标开发
## 01-[复习]-上次课程内容回顾
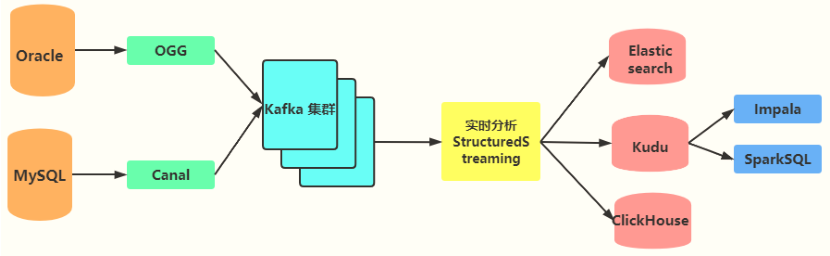
> 主要讲解:实时ETL转换开发,[编写结构化流(StructuredStreaming)程序,实时从Kafka消费数据,进行ETL转换处理,最终保存到Kudu存储引擎(表中)。]()
>
> ==从分布式消息队列Kafka中消费数据,每个业务系统业务数据存储在1个Topic中。==
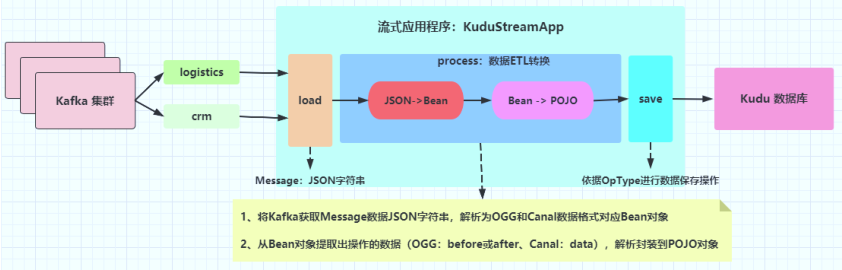
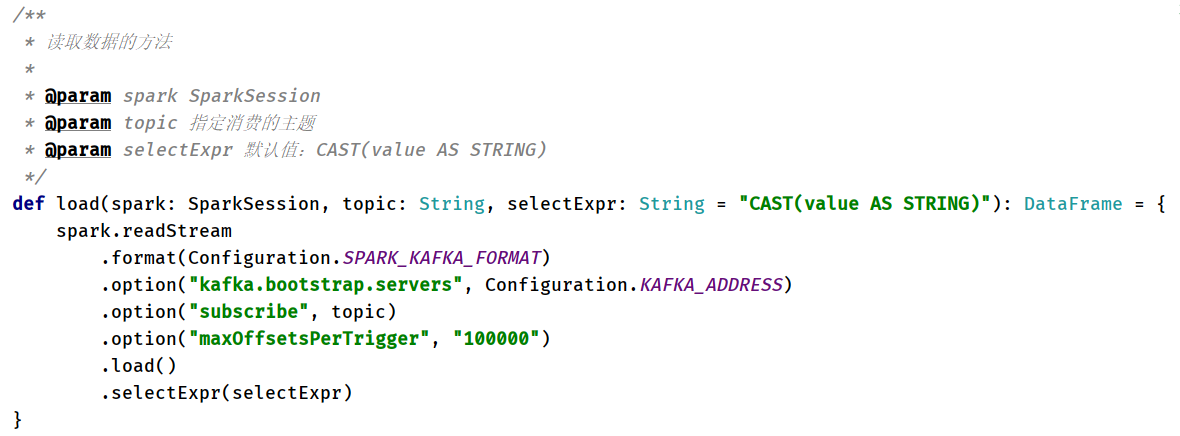
> - 1)、加载数据:`load`方法,[从Kafka中实时消费数据]()
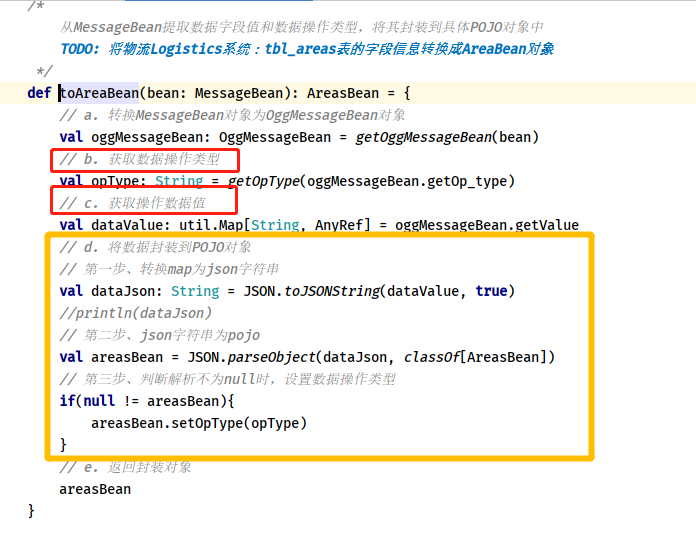
> - 2)、处理数据:`process`方法,[对消费数据原始消息数据Message,按照业务需求进行ETL转换,首先将JSON数据转换为MessageBean对象,然后提取数据字段和操作数据类型,封装到POJO对象中]()。
>
> - 第一步、转换消息数据JSON字符串为`MessageBean`对象:process方法
>
> [不同采集方式,得到JSON字符串结构不一样的,OGG采集和Canal采集完全不一样的]()
>
> ```scala
> /**
> * 数据的处理,仅仅实现JSON -> MessageBean
> *
> * @param streamDF 流式数据集StreamingDataFrame
> * @param category 业务数据类型,比如物流系统业务数据,CRM系统业务数据等
> * @return 流式数据集StreamingDataFrame
> */
> override def process(streamDF: DataFrame, category: String): DataFrame = {
> // 导入隐式转换
> import streamDF.sparkSession.implicits._
>
> val etlStreamDF: DataFrame = category match {
> // TODO: 物流系统业务数据,OGG采集数据
> case "logistics" =>
> val oggBeanStreamDS: Dataset[OggMessageBean] = streamDF
> // 由于从Kafka消费数据,只获取value消息,将其转换DataSet
> .as[String]
> // 过滤数据
> .filter(msg => null != msg && msg.trim.length > 0)
> // 解析每条数据
> .map{
> msg => JSON.parseObject(msg, classOf[OggMessageBean])
> }(Encoders.bean(classOf[OggMessageBean])) // TODO: 指定编码器
>
> // 返回转换后的数据
> oggBeanStreamDS.toDF()
> // TODO: CRM系统业务数据
> case "crm" =>
> val canalBeanStreamDS: Dataset[CanalMessageBean] = streamDF
> // 过滤数据
> .filter(row => !row.isNullAt(0))
> // 解析数据,对分区数据操作
> .mapPartitions { iter =>
> iter.map { row =>
> val jsonValue: String = row.getAs[String]("value")
> // 解析JSON字符串
> JSON.parseObject(jsonValue, classOf[CanalMessageBean])
> }
> }
>
> // 返回转换后的数据
> canalBeanStreamDS.toDF()
>
> // TODO: 其他业务系统数据
> case _ => streamDF
> }
> // 返回ETL转换后的数据
> etlStreamDF
> }
> ```
>
>
>
> - 第二步、从MessageBean对象提取`数据字段值`和`数据操作类型`,封装到POJO对象
>
> [针对不同的业务系统,定义不同方法,进行提取字段封装为JOJO对象,并保存到外部系统]()
>
> - 针对物流系统来说,OGG采集数据,方法:`logisticsEtl`,按照表进行分组POJO对象
> - 针对CRM系统来说,Canal采集数据,方法:`crmEtl`,按照表进行分组POJO对象
>
> 
>
> 如何提取字段值,封装到POJO对象中,依然使用fastJson库转换

> 对应解析数据,封装POJO对象
> - 3)、保存数据:`save`方法,[将转换后数据,保存至Kudu表中,如果表不存在,创建表]()
>
> - 第一点、表是否存在,及是否允许创建,都满足,创建表
>
> 
>
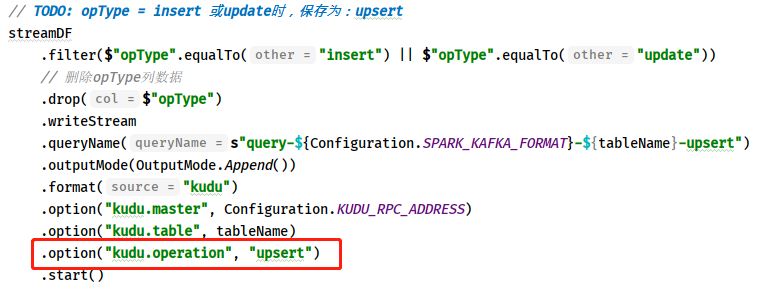
> - 第二点、保存数据到Kudu表时,依据数据操作类型:`opType`
>
> - 如果值为:`insert`或`update`,将数据保存操作:`kudu.operation=upsert`
>
> 
>
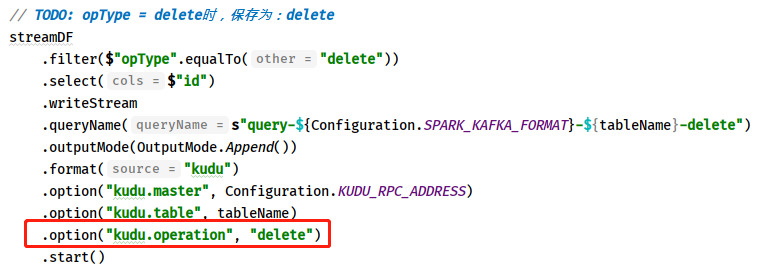
> - 如果值为:`delete`,依据主键到Kudu表中删除数据,保存数据操作:`kudu.operation=delete`
>
> 
> 上述ETL转换代码可不可以简化,比如不适用fastJson库,将数据2次封装到JavaBean对象,而是使用:`get_json_object`,提取表的名称、数据值及数据操作类型,最终保存到Kudu表中。
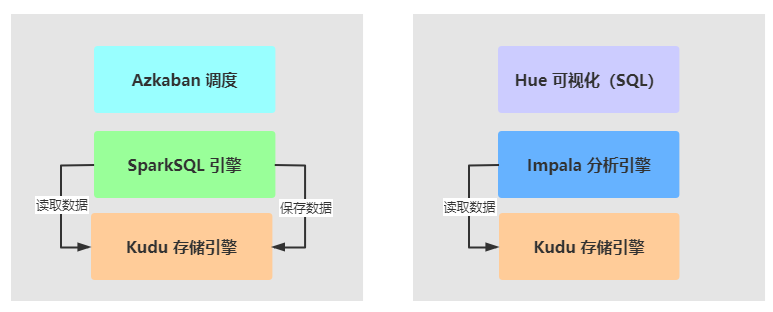
## 02-[理解]-第6章:内容概述和学习目标
> 前面第5章,已经将业务数据实时增量同步到Kudu存储引擎中,需要对Kudu表的数据进行分析处理。
>
> [第6章,针对Kudu表存储的业务数据进行分析处理:按照不同业务主题划分,进行报表分析和即席查询。]()
>
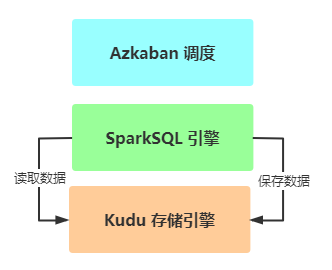
> - 1)、`Report`:离线报表分析,==类似在线教育项目==
> - 使用分析引擎:SparkSQL,全部采用DSL语句分析
> - 采用数据仓库分层(典型分层:ODS、DW、DA/APP)结构管理数据
> - 离线报表,往往都是每日报表统计,需要调度引擎,进行`定时调`度执行和`依赖调度`执行
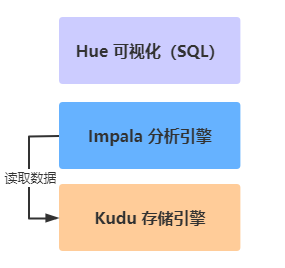
> - 2)、`Ad Hoc`:即席查询,==依据业务需求,快速分析数据==
> - 定义:即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选
> 择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而
> 即席查询是由用户自定义查询条件的。
> - 使用分析引擎:`Impala` 基于内存分析引擎
> - 结合`Hue`可视化界面工具,提供编写Impala SQL语句,查询分析数据
> 第6章课程内容目标:

## 03-[了解]-第10天:课程内容提纲
> 主要讲解:如何对Kudu表数据分析【==离线报表分析(1个主题)==】
> - 1)、离线报表分析:1个主题报表【快递单`tbl_express_bill`主题报表开发】
> - 按照数据仓库分层结构管理数据
> - 使用SparkSQL DSL编程,所有分析数据来源:Kudu表,最终分析结果存储到`Kudu`表中
> - 分析报表:Java Client API读取报表结果进行展示;集成报表工具:Superset
```
重点掌握,物流项目中离线报表,按照主题开发时流程步骤,及其中核心编程代码。
```
## 04-[理解]-主题及指标开发之功能总述
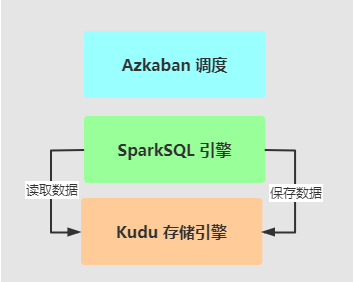
> 使用OGG和Canal实时增量采集数据发送Kafka,结构化流程序`KuduStreamApp`实时消费数据,进行数据ETL转换操作,存储至Kudu表中。
>
> [大数据分析平台,离线报表分析有2个特点:]()
>
> - 第一个、按照业务主题划分,报表属于定制化开发,离线报表
> - 第二个、每日报表,90%以上报表,每天统计前一天数据
>
> ==针对物流项目来说,离线报表分析中,各个主题报表数据使用Kudu数据库,类似Hive数仓==
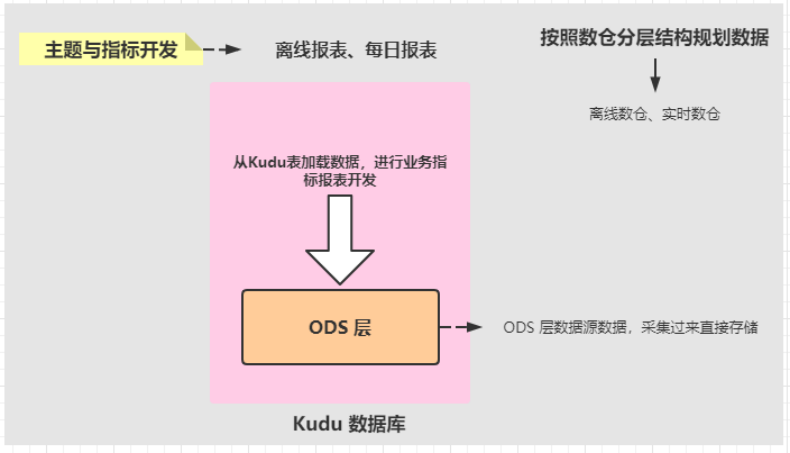
> 数据存储在Kudu表中,使用结构化流存储的数据属于ODS层数据。

> 各个主题报表开发时,从Kudu表加载数据,分析处理以后,再次存储到Kudu表中。
>
> ==实时数仓(数据实时采集、实时分析和实时展示)和离线数仓(数据采集离线和实时,离线分析和展示)==
```
P8大佬讲实时数据仓库课程:
https://www.bilibili.com/video/BV1Lf4y1q7XV
```
## 05-[掌握]-主题及指标开发之数仓分层架构
> 数据仓库典型分层结构:`3层结构【ODS层、DW层和DA层】`
>
> - 1)、ODS层数据:原始数据,往往来源于业务系统产生的数据,比如RDBMS表数据、日志文件数据或爬虫获取数据及第三方购买的数据等
> - 2)、DW层:数据仓库层,数据来源ODS成数据,整合拉宽和分析数据
> - 3)、DA层:数据应用层,数据来源DW层数据分析处理,按照需要业务分析
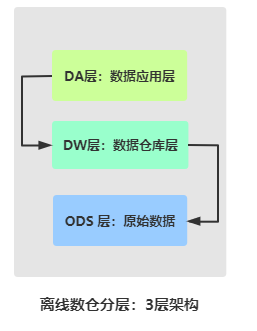
> 有时,将业务数据中维度数据,单独放到一层:`DIM层(维度层)`,存储都是维度表的数据。
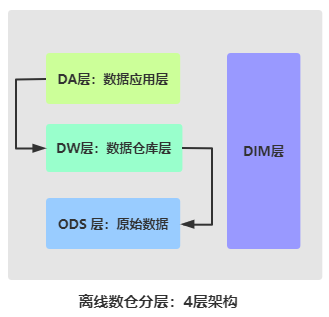
> 主题指标开发,按照数据仓库分层结构进行存储数据,分为典型数仓三层架构:`ODS 层、DW层和APP层`,==更加有效的数据组织和管理,使得数据体系更加有序==。
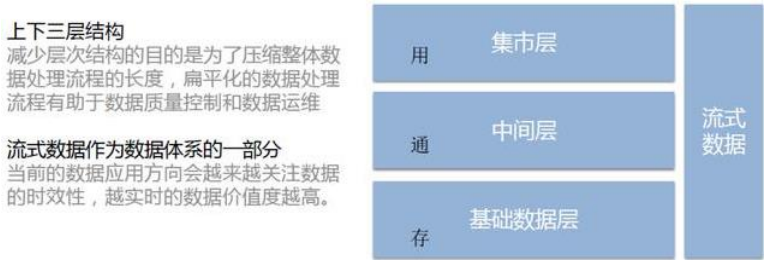
> 数据分层的好处:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-13zhSKeu-1641190057422)(/img/1616294126549.png)]
> 通用的数据分层设计:
>
> - ODS:存放原始数据
> - DW:存放数仓中间层数据
> - APP:面向业务定制的应用数据

> 电商网站的数据体系设计,只关注`用户访问日志`这部分数据:

> 各层会用到的计算引擎和存储系统:
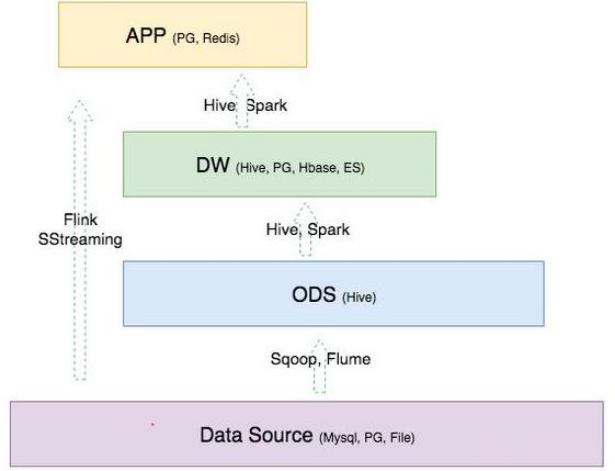
> 京东的`数据仓库分层模式`,是根据标准的模型演化而来。
```
数据仓库分层:
BDM:缓冲数据,源数据的直接映像,缓冲:Buffer
FDM:基础数据层,数据拉链处理、分区处理,基础:Foundation
GDM:通用聚合,通用:Generic
ADM:高度聚合,聚合:Aggregation,应用层:Application
```
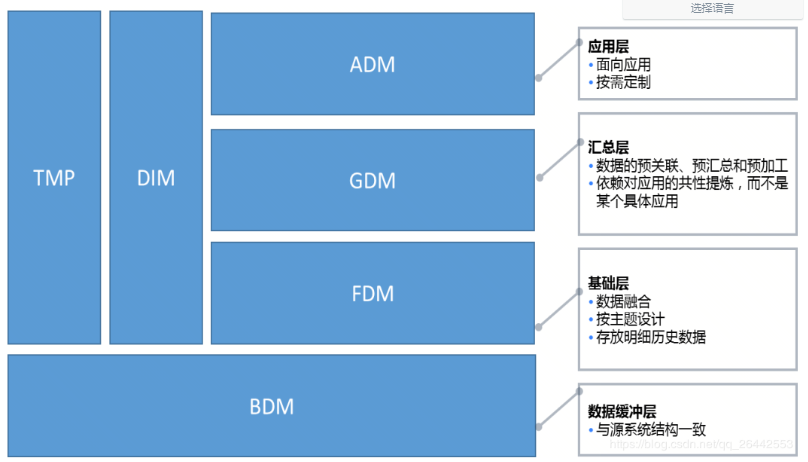
先把数据从源数据库中抽取加载到BDM层中,然后FDM层根据BDM层的数据按天分区
```
DIM:维度,全称为dimension,[daɪˈmenʃn]
TMP:临时,全称为temporary,temprəri]
DM:数据集市,全称为Data Mart,有时候也是数据挖掘(Data Mining)
```
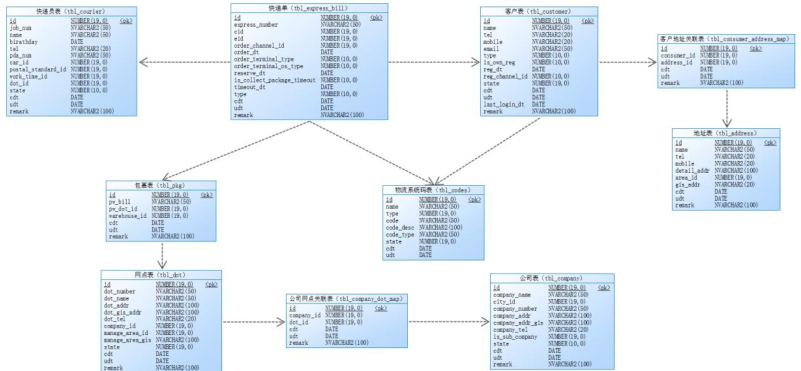
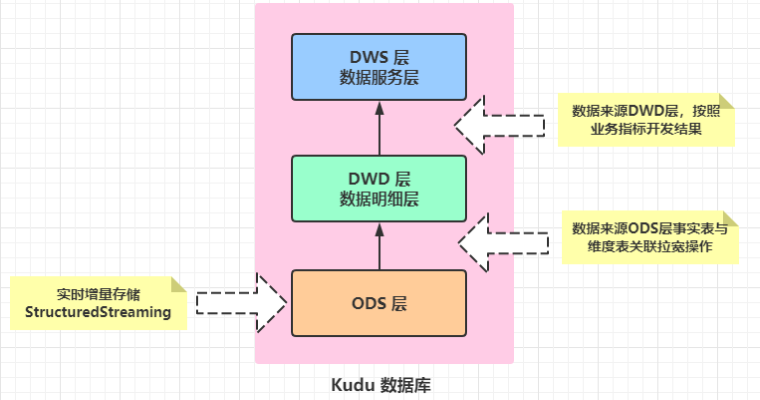
## 06-[掌握]-主题及指标开发之三层架构流程
> 查看物流项目数据流转图:当数据存到Kudu表以后,需要进行分析(离线报表分析和即席查询分析)
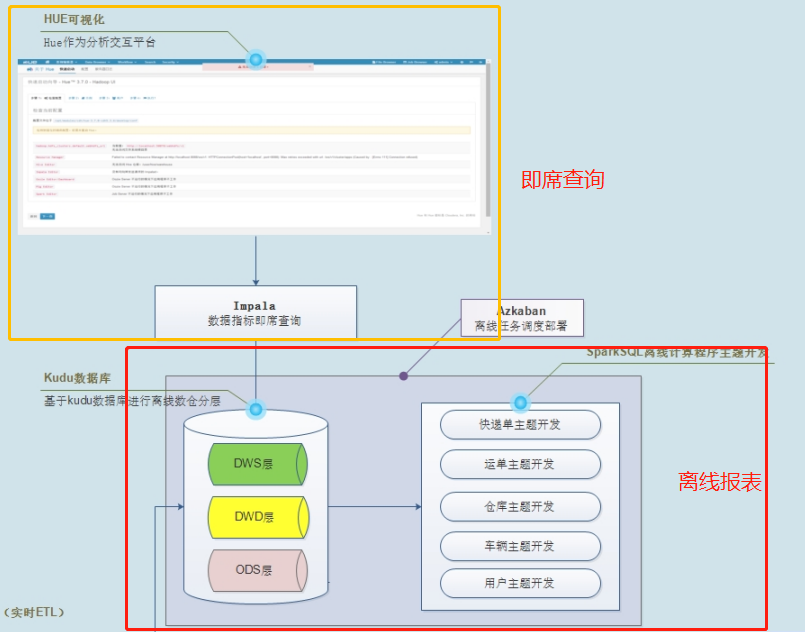
> 离线报表分析按照数仓分层架进行管理和划分数据:
>
> - 1)、第一层:`ODS`层,原始数据存储层,
> - 结构化流实时增量ETL存储的数据
> - 2)、第二层:`DWD`层,数据仓库明细层
> - 此层数据来源于ODS层数据,[对ODS层事实表数据与相关维度表数据进行关联JOIN,拉宽操作数据]()
> - 事实表(业务表),大表,数据量多
> - 维度表,小表
> - 关联JOIN:左外连接,大表在左,小表在右,`big-table.leftJoin(small-table, xx)`
> - 3)、第三层:`DWS`层,数据服务层
> - 此层数据来源于DWD层数据,[按照业务指标需求,对DWD层宽表数据进行指标分析,存储指标结果]()
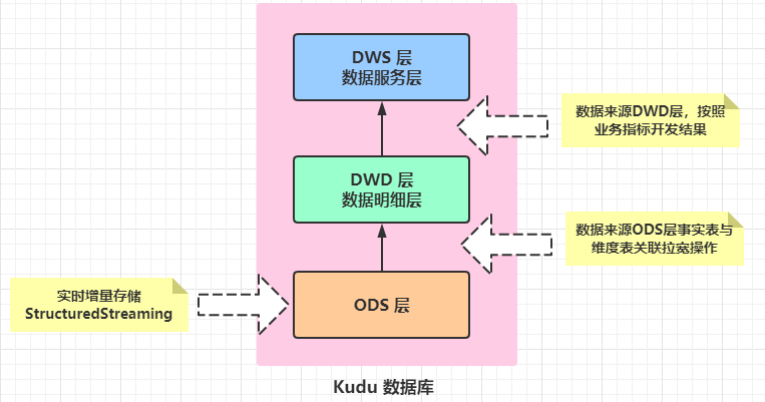
> 每个主题报表开发,分为三层管理数据,其中DWD层和DWS层需要编写SparkSQL程序,业务处理:
>
> - DWD层程序开发:
> - 从Kudu表加载ODS层事实表数据和维度表数据,按照关联字段,进行拉宽操作,最后存储到Kudu表
> - 技术:`Kudu -> SparkSQL -> Kudu`
> - DWS层程序开发:
> - 从Kudu表加载DWD层宽表数据,按照指标需要进行计算,最终存储到Kudu表中,以便使用
> - 技术:`Kudu -> SparkSQL -> Kudu`
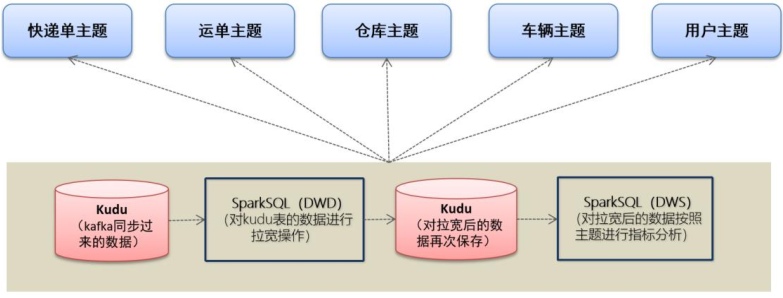
> 对于物流项目来说,目前给大家讲解`5个主题离`线报表开发,全部按照上述数仓分层开发。
## 07-[掌握]-主题及指标开发之离线模块初始化
> 在进行各个主题报表开发之前,首先进行初始化操作,分为如何几个方面:
- 1)、创建包结构
> 本次项目采用Scala编程语言,因此创建scala目录,在离线分析模块【`logistics-offline`】
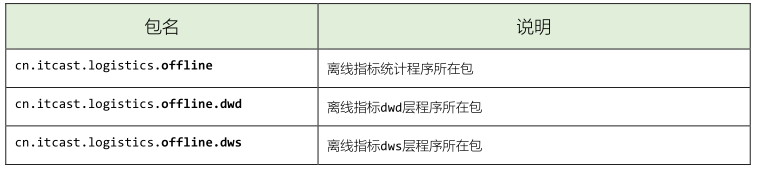
> 创建完成以后,包的结构如下所示:

- 2)、时间处理工具类
> 离线报表分析,往往都是每日报表分析,也就说:今天运行程序,处理的昨天数据。此时就需要获取当前日期时间和昨日日期时间,可以编写工具类,获取日期时间值;也可以使用SparkSQL提供函数。
>
> - 时间处理工具类:`DateHepler`

```java
package cn.itcast.logistics.common
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
/**
* 时间处理工具类
*/
object DateHelper {
/**
* 返回昨天的时间
*/
def getYesterday(format: String): String = {
val dateFormat = FastDateFormat.getInstance(format)
//当前时间减去一天(昨天时间)
dateFormat.format(new Date(System.currentTimeMillis() - 1000 * 60 * 60 * 24))
}
/**
* 返回今天的时间
*/
def getToday(format: String): String = {
//获取指定格式的当前时间
FastDateFormat.getInstance(format).format(new Date)
}
def main(args: Array[String]): Unit = {
println(s"Today: ${getToday(format = "yyyy-MM-dd HH:mm:ss:SSS")}")
println(s"Yesterday: ${getYesterday(format = "yyyy-MM-dd HH:mm:ss:SSS")}")
}
}
```
> - 直接SparkSQL中提供`日期函数`即可:
> - 日期函数,所在对象:`org.apache.spark.sql.functions`
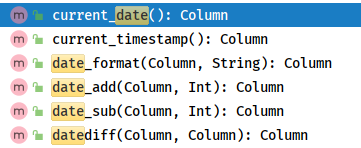
```markdown
1)、current_date()/ now() 获取当前日期
2)、current_timestamp() 获取当前日期时间
3)、date_format 格式化日期时间
4)、date_add、 date_sub
前N天,后N天
5)、datediff 日期之差
2个日期相差天数
```
- 3)、主题宽表及指标结果表名称
> 每个主题都需要拉宽操作,将拉宽后的数据存储到Kudu表中,同时指标计算的数据最终也需要落地到Kudu表,因此提前将各个主题相关表名定义出来。

```scala
package cn.itcast.logistics.common
/**
* 自定义离线计算结果表
*/
object OfflineTableDefine {
// 快递单明细表
val EXPRESS_BILL_DETAIL: String = "tbl_express_bill_detail"
// 快递单指标结果表
val EXPRESS_BILL_SUMMARY: String = "tbl_express_bill_summary"
// 运单明细表
val WAY_BILL_DETAIL: String = "tbl_waybill_detail"
// 运单指标结果表
val WAY_BILL_SUMMARY: String = "tbl_waybill_summary"
// 仓库明细表
val WAREHOUSE_DETAIL: String = "tbl_warehouse_detail"
// 仓库指标结果表
val WAREHOUSE_SUMMARY: String = "tbl_warehouse_summary"
// 网点车辆明细表
val DOT_TRANSPORT_TOOL_DETAIL: String = "tbl_dot_transport_tool_detail"
// 仓库车辆明细表
val WAREHOUSE_TRANSPORT_TOOL_DETAIL: String = "tbl_warehouse_transport_tool_detail"
// 网点车辆指标结果表
val DOT_TRANSPORT_TOOL_SUMMARY: String = "tbl_dot_transport_tool_summary"
// 仓库车辆指标结果表
val WAREHOUSE_TRANSPORT_TOOL_SUMMARY: String = "tbl_warehouse_transport_tool_summary"
// 客户明细表数据
val CUSTOMER_DETAIL: String = "tbl_customer_detail"
// 客户指标结果表数据
val CUSTOMER_SUMMERY: String = "tbl_customer_summary"
}
```
- 4)、物流字典码表数据类型定义
> 为了后续使用方便且易于维护,根据物流字典表的数据类型定义成枚举工具类,物流字典表的数据如下:
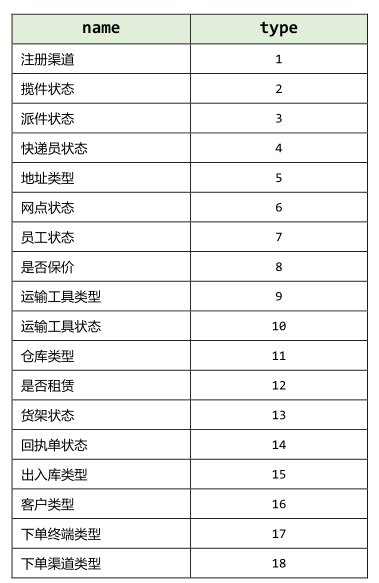
> 在公共模块的scala目录下的common程序包下创建`CodeTypeMapping`对象
```scala
package cn.itcast.logistics.common
/**
* 定义物流字典编码类型映射工具类
*/
object CodeTypeMapping {
//注册渠道
val REGISTER_CHANNEL: Int = 1
//揽件状态
val COLLECT_STATUS: Int = 2
//派件状态
val DISPATCH_STATUS: Int = 3
//快递员状态
val COURIER_STATUS: Int = 4
//地址类型
val ADDRESS_TYPE: Int = 5
//网点状态
val Dot_Status: Int = 6
//员工状态
val STAFF_STATUS: Int = 7
//是否保价
val IS_INSURED: Int = 8
//运输工具类型
val TRANSPORT_TYPE: Int = 9
//运输工具状态
val TRANSPORT_STATUS: Int = 10
//仓库类型
val WAREHOUSE_TYPE: Int = 11
//是否租赁
val IS_RENT: Int = 12
//货架状态
val GOODS_SHELVES_STATUE: Int = 13
//回执单状态
val RECEIPT_STATUS: Int = 14
//出入库类型
val WAREHOUSING_TYPE: Int = 15
//客户类型
val CUSTOM_TYPE: Int = 16
//下单终端类型
val ORDER_TERMINAL_TYPE: Int = 17
//下单渠道类型
val ORDER_CHANNEL_TYPE: Int = 18
}
```
## 08-[掌握]-主题及指标开发之公共接口【结构】
> 通过前面分析可以知道,每个主题离线报表开发,都需要开发2个SparkSQL程序,并且每个SparkSQL程序都是从Kudu表读取数据,进行处理,再保存数据到Kudu表,所以可以进行抽象公共接口,实现其中从Kudu表读取数据和向Kudu表保存数据,每个主题的DWD层和DWS层只需要实现其中处理数据代码即可。

```scala
package cn.itcast.logistics.offline
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 根据不同的主题开发,定义抽象方法
*- 1. 数据读取load:从Kudu数据库的ODS层读取数据,事实表和维度表
*- 2. 数据处理process:要么是拉链关联宽表,要么是依据业务指标分析得到结果表
*- 3. 数据保存save:将宽表或结果表存储Kudu数据库的DWD层或者DWS层
*/
trait BasicOfflineApp {
/**
* 读取Kudu表的数据,依据指定Kudu表名称
*
* @param spark SparkSession实例对象
* @param tableName 表的名
* @param isLoadFullData 是否加载全量数据,默认值为false
*/
def load(spark: SparkSession, tableName: String, isLoadFullData: Boolean = false): DataFrame = ???
/**
* 数据处理,如果是DWD层,事实表与维度表拉宽操作;如果是DWS层,业务指标计算
*/
def process(dataframe: DataFrame): DataFrame
/**
* 数据存储: DWD及DWS层的数据都是需要写入到kudu数据库中,写入逻辑相同
*
* @param dataframe 数据集,主题指标结果数据
* @param tableName Kudu表的名称
* @param isAutoCreateTable 是否自动创建表,默认为true,当表不存在时创建表
*/
def save(dataframe: DataFrame, tableName: String, isAutoCreateTable: Boolean = true): Unit = ???
}
```
## 09-[掌握]-主题及指标开发之公共接口【编程】
> 任务:将公共接口中load加载数据和save保存数据方法实现,都是与Kudu打交道,要么存储,要么加载。
```java
package cn.itcast.logistics.offline
import cn.itcast.logistics.common.{Configuration, KuduTools}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
/**
* 根据不同的主题开发,定义抽象方法
*- 1. 数据读取load:从Kudu数据库的ODS层读取数据,事实表和维度表
*- 2. 数据处理process:要么是拉链关联宽表,要么是依据业务指标分析得到结果表
*- 3. 数据保存save:将宽表或结果表存储Kudu数据库的DWD层或者DWS层
*/
trait BasicOfflineApp {
/**
* 读取Kudu表的数据,依据指定Kudu表名称
*
* @param spark SparkSession实例对象
* @param tableName 表的名
* @param isLoadFullData 是否加载全量数据,默认值为false
*/
def load(spark: SparkSession, tableName: String, isLoadFullData: Boolean = false): DataFrame = {
// 加载Kudu表数据,不考虑全量还是增量
var kuduDF: DataFrame = spark.read
.format(Configuration.SPARK_KUDU_FORMAT)
.option("kudu.master", Configuration.KUDU_RPC_ADDRESS)
.option("kudu.table", tableName)
.option("kudu.socketReadTimeoutMs", "60000")
.load()
// 如果是增量加载 数据,表示加载昨日数据,需要过滤操作
if(!isLoadFullData){
kuduDF = kuduDF
// 依据 每个表中字段:cdt = 2013-06-02 21:24:00,过滤数据
.filter(
date_sub(current_date(), 1) === date_format(col("cdt"), "yyyy-MM-dd")
)
}
// 返回数据
kuduDF
}
/**
* 数据处理,如果是DWD层,事实表与维度表拉宽操作;如果是DWS层,业务指标计算
*/
def process(dataframe: DataFrame): DataFrame
/**
* 数据存储: DWD及DWS层的数据都是需要写入到kudu数据库中,写入逻辑相同
*
* @param dataframe 数据集,主题指标结果数据
* @param tableName Kudu表的名称
* @param isAutoCreateTable 是否自动创建表,默认为true,当表不存在时创建表
*/
def save(dataframe: DataFrame, tableName: String, isAutoCreateTable: Boolean = true): Unit = {
// 如果允许创建表,并且表不存在,就创建表
if(isAutoCreateTable){
KuduTools.createKuduTable(tableName, dataframe, Seq("id"))
}
// 保存数据到Kudu表
dataframe.write
.mode(SaveMode.Append)
.format(Configuration.SPARK_KUDU_FORMAT)
.option("kudu.master", Configuration.KUDU_RPC_ADDRESS)
.option("kudu.table", tableName)
.option("kudu.operation", "upsert")
.save()
}
}
```
## 10-[理解]-快递单主题之数据调研及业务分析
```
大数据开发:数据分析
离线分析:85%
实时分析:10-15%
高级分析(机器学习和图计算):5%
业务需求
需要实现什么功能,获取什么结果
数据调研
有什么数据,数据含义(字段意思,数据如何产生)
技术实现
利用大数据分析引擎,编程分析数据
性能调优
海量数据,数据异常
完美结束。。。。。。。。。。。。。。。。。。。。。。。。。。。。
```
> 对于物流快递公司来说,其中最主要核心业务数据:`快递单数据(tbl_express_bill)`,依据不同维度统计分析。

> [快递单量的统计主要是从多个不同的维度计算快递单量,从而监测快递公司业务运营情况。]()

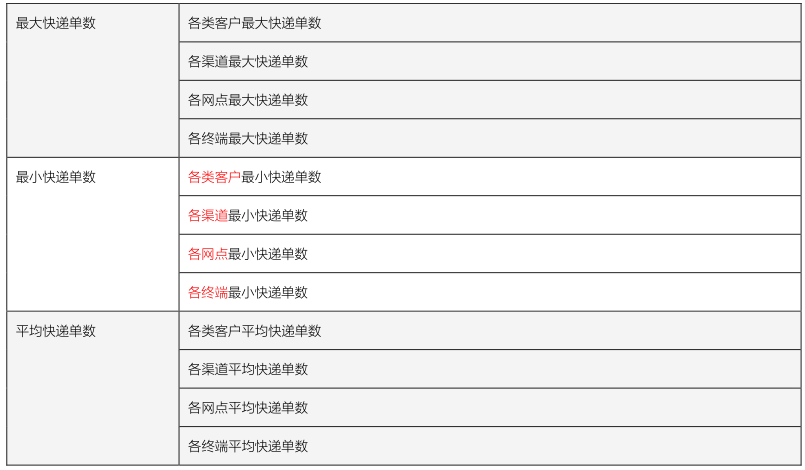
> 快递单量统计,维度如下:`客户类型、渠道、网点、终端`,分别计算快递最大、最小和平均快递量。
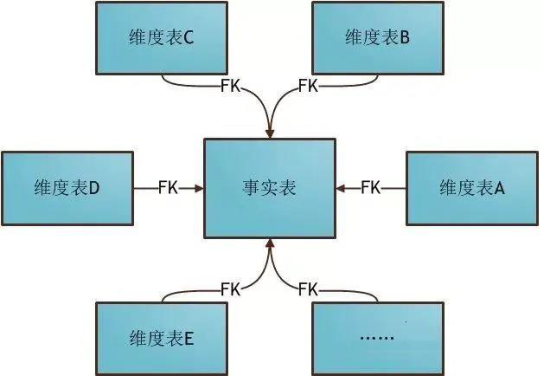
> 星型模型:是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(DimensionTable)组成。
- 1)、事实表:大表,业务数据表

- 2)、维度表:小表
- 3)、事实表与维度表关系
> 针对快递单主题指标开发,需要2个步骤:
>
> - 第一步、DWD层:将快递单表与相关维度表进行关联JOIN,进行拉宽操作
> - 第二步、DWS层:从宽表中读取数据数据,按照指标需要计算,存储到Kudu结果表中
## 11-[掌握]-快递单主题之数据拉宽【MAIN 方法】
> 对快递单主题进行数据拉宽操作,将事实表与维度表(ODS层)关联,选取字段,最后存储到Kudu表(DWD层),如下中:ODS -> DWD层程序开发

> 在`dwd`目录下创建 `ExpressBillDWD` 单例对象,继承自`BasicOfflineApp`特质:
```scala
package cn.itcast.logistics.offline.dwd
import cn.itcast.logistics.common.{Configuration, OfflineTableDefine, SparkUtils, TableMapping}
import cn.itcast.logistics.offline.BasicOfflineApp
import org.apache.spark.sql.{DataFrame, SparkSession}
/*
* 快递单主题开发:
* 将快递单事实表的数据与相关维度表的数据进行关联JOIN,然后将拉宽后的数据写入到快递单宽表中
* 采用DSL语义实现离线计算程序
* 最终离线程序需要部署到服务器,每天定时执行(Azkaban定时调度)
*/
object ExpressBillDWD extends BasicOfflineApp{
/**
* 数据处理,如果是DWD层,事实表与维度表拉宽操作
*/
override def process(dataframe: DataFrame): DataFrame = ???
// SparkSQL 应用程序入口:MAIN 方法
/*
数据处理,实现步骤:
step1. 创建SparkSession对象,传递SparkConf对象
step2. 加载Kudu中的事实表数据
step3. 加载维度表数据,与事实表进行关联
step4. 将拉宽后的数据再次写回到Kudu数据库中
*/
def main(args: Array[String]): Unit = {
// step1. 创建SparkSession对象,传递SparkConf对象
val spark: SparkSession = SparkUtils.createSparkSession(
SparkUtils.autoSettingEnv(SparkUtils.sparkConf()), this.getClass
)
import spark.implicits._
spark.sparkContext.setLogLevel(Configuration.LOG_OFF)
// step2. 加载Kudu中的事实表数据
val expressBillDF: DataFrame = load(
spark, TableMapping.EXPRESS_BILL, isLoadFullData = Configuration.IS_FIRST_RUNNABLE
)
expressBillDF.show(10, truncate = false)
// step3. 加载维度表数据,与事实表进行关联
val expressBillDetailDF: DataFrame = process(expressBillDF)
expressBillDetailDF.show(10, truncate = false)
// step4. 将拉宽后的数据再次写回到Kudu数据库中
save(expressBillDetailDF, OfflineTableDefine.EXPRESS_BILL_DETAIL)
// 程序结束,关闭资源
spark.close()
}
}
```
> 其中main方法,实现如何从Kudu加载数据,如何进行拉宽操作,最后保存数据到Kudu表中。
## 12-[掌握]-快递单主题之数据拉宽【process 方法】
> 任务:实现快递单主题报表开发中【数据拉宽】操作,对`process`方法编码实现。

> 按照步骤具体实现代码
```java
/**
* 数据处理,如果是DWD层,事实表与维度表拉宽操作
*/
override def process(dataframe: DataFrame): DataFrame = {
// dataframe 读取事实表数据,此处表示的就是快递单表数据
val spark: SparkSession = dataframe.sparkSession
import spark.implicits._
// step1. 加载Kudu中维度表数据,与快递单相关,维度表加载全局数据
// 1.1:加载快递员维度表的数据
val courierDF: DataFrame = load(spark, TableMapping.COURIER, isLoadFullData = true)
// 1.2:加载客户维度表的数据
val customerDF: DataFrame = load(spark, TableMapping.CUSTOMER, isLoadFullData = true)
// 1.3:加载物流码表的数据
val codesDF: DataFrame = load(spark, TableMapping.CODES, isLoadFullData = true)
// 1.4:客户地址关联表的数据
val addressMapDF: DataFrame = load(spark, TableMapping.CONSUMER_ADDRESS_MAP, isLoadFullData = true)
// 1.5:加载地址表的数据
val addressDF: DataFrame = load(spark, TableMapping.ADDRESS, isLoadFullData = true)
// 1.6:加载包裹表的数据
val pkgDF: DataFrame = load(spark, TableMapping.PKG, isLoadFullData = true)
// 1.7:加载网点表的数据
val dotDF: DataFrame = load(spark, TableMapping.DOT, isLoadFullData = true)
// 1.8:加载公司网点表的数据
val companyDotMapDF: DataFrame = load(spark, TableMapping.COMPANY_DOT_MAP, isLoadFullData = true)
// 1.9:加载公司表的数据
val companyDF: DataFrame = load(spark, TableMapping.COMPANY, isLoadFullData = true)
// 1.10:获取终端类型码表数据
val orderTerminalTypeDF: DataFrame = codesDF
.where($"type" === CodeTypeMapping.ORDER_TERMINAL_TYPE)
.select(
$"code".as("OrderTerminalTypeCode"),
$"codeDesc".as("OrderTerminalTypeName")
)
// 1.11:获取下单渠道类型码表数据
val orderChannelTypeDF: DataFrame = codesDF
.where($"type" === CodeTypeMapping.ORDER_CHANNEL_TYPE)
.select(
$"code".as("OrderChannelTypeCode"),
$"codeDesc".as("OrderChannelTypeName")
)
// step2. 将事实表与维度表数据关联join:leftJoin
val expressBillDF: DataFrame = dataframe
val joinType: String = "left_outer"
val joinDF: DataFrame = expressBillDF
// 快递单表与快递员表进行关联
.join(courierDF, expressBillDF("eid") === courierDF("id"), joinType)
// 快递单表与客户表进行关联
.join(customerDF, expressBillDF("cid") === customerDF("id"), joinType)
// 下单渠道表与快递单表关联
.join(
orderChannelTypeDF,
orderChannelTypeDF("OrderChannelTypeCode") === expressBillDF("orderChannelId"),
joinType
)
// 终端类型表与快递单表关联
.join(
orderTerminalTypeDF,
orderTerminalTypeDF("OrderTerminalTypeCode") === expressBillDF("orderTerminalType"),
joinType
)
// 客户地址关联表与客户表关联
.join(addressMapDF, addressMapDF("consumerId") === customerDF("id"), joinType)
// 地址表与客户地址关联表关联
.join(addressDF, addressDF("id") === addressMapDF("addressId"), joinType)
// 包裹表与快递单表关联
.join(pkgDF, pkgDF("pwBill") === expressBillDF("expressNumber"), joinType)
// 网点表与包裹表关联
.join(dotDF, dotDF("id") === pkgDF("pwDotId"), joinType)
// 公司网点关联表与网点表关联
.join(companyDotMapDF, companyDotMapDF("dotId") === dotDF("id"), joinType)
// 公司网点关联表与公司表关联
.join(companyDF, companyDF("id") === companyDotMapDF("companyId"), joinType)
// step3. 选择字段(依据需求而定,所有字段)及添加字段day:表示数据属于哪一天)
val expressBillDetailDF: DataFrame = joinDF
.select(
expressBillDF("id"), // 快递单id
expressBillDF("expressNumber").as("express_number"), //快递单编号
expressBillDF("cid"), //客户id
customerDF("name").as("cname"), //客户名称
addressDF("detailAddr").as("caddress"), //客户地址
expressBillDF("eid"), //员工id
courierDF("name").as("ename"), //员工名称
dotDF("id").as("dot_id"), //网点id
dotDF("dotName").as("dot_name"), //网点名称
companyDF("companyName").as("company_name"), //公司名称
expressBillDF("orderChannelId").as("order_channel_id"), //下单渠道id
orderChannelTypeDF("OrderChannelTypeName").as("order_channel_name"), //下单渠道id
expressBillDF("orderDt").as("order_dt"), //下单时间
orderTerminalTypeDF("OrderTerminalTypeCode").as("order_terminal_type"), //下单设备类型id
orderTerminalTypeDF("OrderTerminalTypeName").as("order_terminal_type_name"), //下单设备类型id
expressBillDF("orderTerminalOsType").as("order_terminal_os_type"), //下单设备操作系统
expressBillDF("reserveDt").as("reserve_dt"), //预约取件时间
expressBillDF("isCollectPackageTimeout").as("is_collect_package_timeout"), //是否取件超时
expressBillDF("timeoutDt").as("timeout_dt"), //超时时间
customerDF("type"), //客户类型
expressBillDF("cdt"), //创建时间
expressBillDF("udt"), //修改时间
expressBillDF("remark") //备注
)
.sort($"cdt".asc)
// 添加day日期字段,表示这条数据属于哪一天
.withColumn("day", regexp_replace(substring($"cdt", 0, 10), "-", ""))
// 返回宽表数据
expressBillDetailDF
}
```
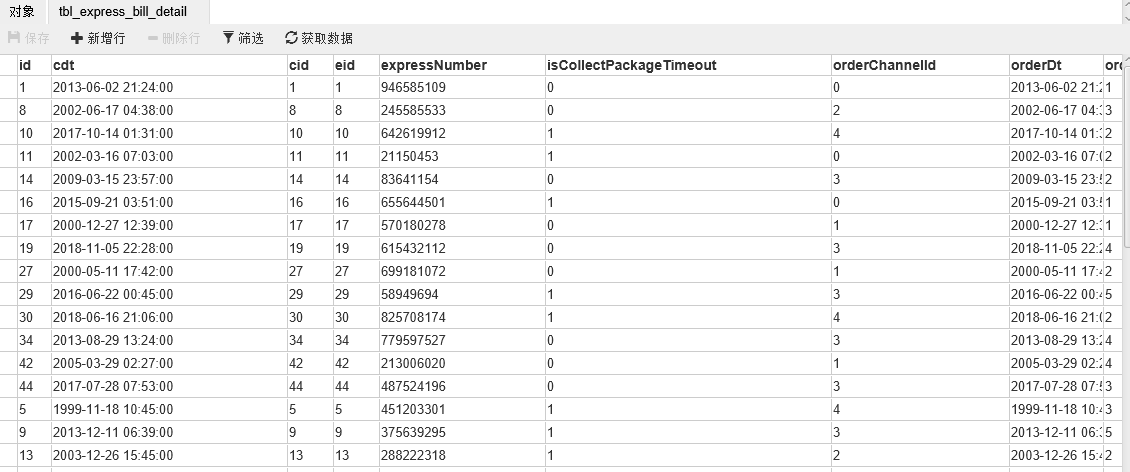
> 运行编写拉宽程序,查看Kudu表数据
## 13-[掌握]-快递单主题之指标计算【MAIN 方法】
> 任务:==指标计算,属于DWS层数据,编写SparkSQL程序,继承公共接口【BasicOfflineApp】,实现其中process方法。==
> 指标计算的字段:首先计算某天总的快递单数,然后按照不同维度计算。
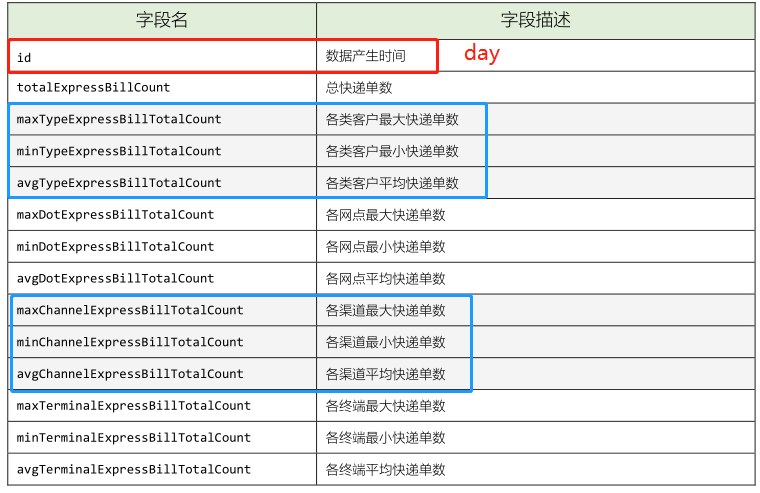
> 创建`ExpressBillDWS`对象,继承`BasicOfflineApp`,编写`MAIN`方法
```java
package cn.itcast.logistics.offline.dws
import cn.itcast.logistics.common.{Configuration, OfflineTableDefine, SparkUtils}
import cn.itcast.logistics.offline.BasicOfflineApp
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 快递单主题开发:
* 加载Kudu中快递单宽表:dwd_tbl_express_bill_detail 数据,按照业务进行指标统计
*/
object ExpressBillDWS extends BasicOfflineApp{
/**
* 数据处理,如果是DWS层,业务指标计算
*/
override def process(dataframe: DataFrame): DataFrame = ???
// SparkSQL 应用程序入口:MAIN 方法
/*
数据处理,实现步骤:
step1. 创建SparkSession对象,传递SparkConf对象
step2. 加载Kudu中的宽表数据
step3. 按照业务指标进行计算
step4. 将指标结果写回到Kudu数据库中
*/
def main(args: Array[String]): Unit = {
// step1. 创建SparkSession对象,传递SparkConf对象
val spark: SparkSession = SparkUtils.createSparkSession(
SparkUtils.autoSettingEnv(SparkUtils.sparkConf()), this.getClass
)
spark.sparkContext.setLogLevel(Configuration.LOG_OFF)
// step2. 加载Kudu中的宽表数据
val expressBillDetailDF: DataFrame = load(
spark, OfflineTableDefine.EXPRESS_BILL_DETAIL, isLoadFullData = Configuration.IS_FIRST_RUNNABLE
)
expressBillDetailDF.show(10, truncate = false)
// step3. 按照业务指标进行计算
val expressBillSummaryDF: DataFrame = process(expressBillDetailDF)
expressBillSummaryDF.show(10, truncate = false)
// step4. 将拉宽后的数据再次写回到Kudu数据库中
save(expressBillSummaryDF, OfflineTableDefine.EXPRESS_BILL_SUMMARY)
// 程序结束,关闭资源
spark.close()
}
}
```
> 快递单主题指标开计算程序开始时,`MAIN方法与数据拉宽程序中MAIN基本一致,仅仅表名称不一样与process方法实现不一样而已`。
## 14-[掌握]-快递单主题之指标计算【process 方法】
> 任务:==按照业务指标需求,编写代码,对指标进行计算,实现process方法==。
```
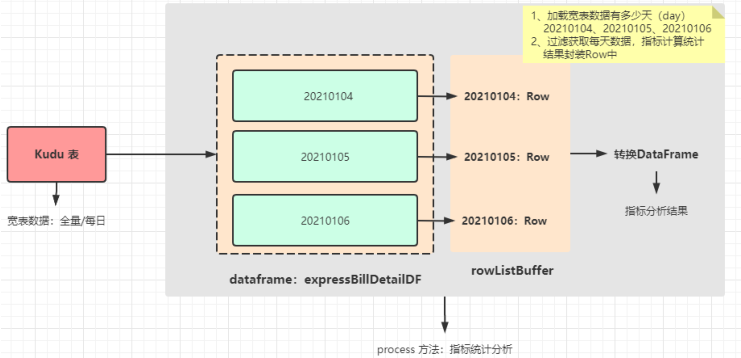
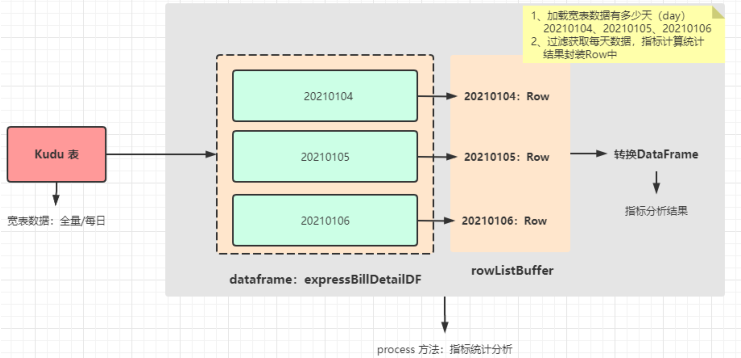
/*
如果加载全量数据,按照day日期划分数据,再进行每日快递单数据指标统计
如果是增量数据,也就是昨日数据,直接计算即可
TODO:无论是全量数据还是增量数据,直接按照全量数据处理,首先获取数据中day值,按照day划分数据,每天数据指标计算
*/
```
```scala
/**
* 数据处理,如果是DWS层,业务指标计算
*/
override def process(dataframe: DataFrame): DataFrame = {
// dataframe,宽表数据,此处表示的就是tbl_express_bill_detail
val spark: SparkSession = dataframe.sparkSession
import spark.implicits._
/*
如果加载全量数据,按照day日期划分数据进行每日快递单数据指标统计
如果是增量数据,也就是昨日数据,直接计算即可
TODO:无论是全量数据还是增量数据,直接按照全量数据处理,首先获取数据中day值,按照day划分数据,每天数据指标计算
*/
// step1. 获取宽表数据中,有哪些日期
val days: Array[Row] = dataframe.select($"day").distinct().collect()
// step2. 遍历每一天,获取日期值,过滤出每天快递单数据,进行指标计算
days.map{row =>
// a. 获取日期值
val dayValue: String = row.getString(0)
// b. 过滤获取日期的所有快递单数据
val expressBillDetailDF: Dataset[Row] = dataframe.filter($"day" === dayValue)
// c. 对每日数据指标计算,将指标结果封装到Row对象中
// 指标一:总快递单数
// 指标二:各类客户快递单数,最大、最小和平均
// 指标三:各网点快递单数,最大、最小和平均
// 指标四:各渠道快递单数,最大、最小和平均
// 指标五:各终端快递单数,最大、最小和平均
null
}
null
}
```
> 对每天数据进行指标计算,计算完成之后,需要将指标封装到Row对象中,以便后续处理
```ini
回顾一下:SparkSQL中Row对象创建方式:
1)、方式一
val row = Row(v1, v2, v3, v4, ...)
2)、方式二
val row = Row.fromSeq(Seq(v1, v2, v3, ....))
本项目中,采用方式二,创建Row对象
```
```scala
/**
* 数据处理,如果是DWS层,业务指标计算
*/
override def process(dataframe: DataFrame): DataFrame = {
// dataframe,宽表数据,此处表示的就是tbl_express_bill_detail
val spark: SparkSession = dataframe.sparkSession
import spark.implicits._
/*
如果加载全量数据,按照day日期划分数据进行每日快递单数据指标统计
如果是增量数据,也就是昨日数据,直接计算即可
TODO:无论是全量数据还是增量数据,直接按照全量数据处理,首先获取数据中day值,按照day划分数据,每天数据指标计算
*/
// step1. 获取宽表数据中,有哪些日期
val days: Array[Row] = dataframe.select($"day").distinct().collect()
// step2. 遍历每一天,获取日期值,过滤出每天快递单数据,进行指标计算
val aggRows: Array[Row] = days.map{ row =>
// a. 获取日期值
val dayValue: String = row.getString(0)
// b. 过滤获取日期的所有快递单数据
val expressBillDetailDF: Dataset[Row] = dataframe.filter($"day" === dayValue)
// c. 对每日数据指标计算,将指标结果封装到Row对象中
// 指标一:总快递单数, SELECT COUNT("id") AS total FROM tbl_express_bill_detail
//expressBillDetailDF.count()
val totalDF: DataFrame = expressBillDetailDF.agg(count($"id").as("total"))
// 指标二:各类客户快递单数,最大、最小和平均
val typeTotalDF: DataFrame = expressBillDetailDF.groupBy($"type").count()
val typeTotalAggDF: DataFrame = typeTotalDF.agg(
max($"count").as("typeMaxTotal"),
min($"count").as("typeMinTotal"),
round(avg($"count"), 0).as("typeAvgTotal")
)
// 指标三:各网点快递单数,最大、最小和平均
val dotTotalDF: DataFrame = expressBillDetailDF.groupBy($"dot_id").count()
val dotTotalAggDF: DataFrame = dotTotalDF.agg(
max($"count").as("dotMaxTotal"),
min($"count").as("dotMinTotal"),
round(avg($"count"), 0).as("dotAvgTotal")
)
// 指标四:各渠道快递单数,最大、最小和平均
val channelTotalDF: DataFrame = expressBillDetailDF.groupBy($"order_channel_id").count()
val channelTotalAggDF = channelTotalDF.agg(
max($"count").as("channelMaxTotal"),
min($"count").as("channelMinTotal"),
round(avg($"count"), 0).as("channelAvgTotal")
)
// 指标五:各终端快递单数,最大、最小和平均
val terminalTotalDF: DataFrame = expressBillDetailDF.groupBy($"order_terminal_type").count()
val terminalTotalAggDF= terminalTotalDF.agg(
max($"count").as("terminalMaxTotal"),
min($"count").as("terminalMinTotal"),
round(avg($"count"), 0).as("terminalAvgTotal")
)
// 将所有指标结果封装到Row对象中
val aggRow: Row = Row.fromSeq(
Seq(dayValue) ++
totalDF.first().toSeq ++
typeTotalAggDF.first().toSeq ++
dotTotalAggDF.first().toSeq ++
channelTotalAggDF.first().toSeq ++
terminalTotalAggDF.first().toSeq
)
// 返回Row数据
aggRow
}
null
}
```
## 15-[掌握]-快递单主题之指标计算【转换DataFrame】
> 计算指标时,针对每天数据进行统计的,指标结果封装到Row中,所以最后得到集合列表,存储都是Row,也就是每日指标结果。
>
> [process方法,最终返回DataFrame数据集,所以需要将列表List转换为DataFrame]()
```
如何将列表List转换为DataFrame呢???
1)、可以将列表List转换为RDD
采用并行化方式
2)、将RDD转换为DataFrame
- 方式一:反射方式,RDD[CaseClass]
- 方式二:自定义Schema
RDD[Row] + schema
```
> 实现功能:将列表List转换为DataFrame,具体代码如下:
```java
// step3. 转换列表List为DataFrame
// a. 将列表List转换为RDD
val rowRDD: RDD[Row] = spark.sparkContext.parallelize(aggRows)
// b. 将RDD转换为DataFrame
val rowSchema = new StructType()
.add("id", StringType, nullable = false)
.add("total", LongType, nullable = true)
.add("typeMaxTotal", LongType, nullable = true)
.add("typeMinTotal", LongType, nullable = true)
.add("typeAvgTotal", DoubleType, nullable = true)
.add("dotMaxTotal", LongType, nullable = true)
.add("dotMinTotal", LongType, nullable = true)
.add("dotAvgTotal", DoubleType, nullable = true)
.add("channelMaxTotal", LongType, nullable = true)
.add("channelMinTotal", LongType, nullable = true)
.add("channelAvgTotal", DoubleType, nullable = true)
.add("terminalMaxTotal", LongType, nullable = true)
.add("terminalMinTotal", LongType, nullable = true)
.add("terminalAvgTotal", DoubleType, nullable = true)
val aggDF: DataFrame = spark.createDataFrame(rowRDD, rowSchema)
```
> 整个指标计算完整代码如下:
```java
package cn.itcast.logistics.offline.dws
import cn.itcast.logistics.common.{Configuration, OfflineTableDefine, SparkUtils}
import cn.itcast.logistics.offline.BasicOfflineApp
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{DoubleType, LongType, StringType, StructType}
/**
* 快递单主题开发:
* 加载Kudu中快递单宽表:dwd_tbl_express_bill_detail 数据,按照业务进行指标统计
*/
object ExpressBillDWS extends BasicOfflineApp{
/**
* 数据处理,如果是DWS层,业务指标计算
*/
override def process(dataframe: DataFrame): DataFrame = {
// dataframe,宽表数据,此处表示的就是tbl_express_bill_detail
val spark: SparkSession = dataframe.sparkSession
import spark.implicits._
// 首先判断加载宽表是否有数据,如果没有数据,直接结束程序
if(dataframe.isEmpty){
println(s"Kudu数据库DWD层[${OfflineTableDefine.EXPRESS_BILL_DETAIL}]表,没有加载到数据,请确认有数据在执行......")
System.exit(-1)
}
/*
如果加载全量数据,按照day日期划分数据进行每日快递单数据指标统计
如果是增量数据,也就是昨日数据,直接计算即可
TODO:无论是全量数据还是增量数据,直接按照全量数据处理,首先获取数据中day值,按照day划分数据,每天数据指标计算
*/
// step1. 获取宽表数据中,有哪些日期
val days: Array[Row] = dataframe.select($"day").distinct().collect()
// step2. 遍历每一天,获取日期值,过滤出每天快递单数据,进行指标计算
val aggRows: Array[Row] = days.map{ row =>
// a. 获取日期值
val dayValue: String = row.getString(0)
// b. 过滤获取日期的所有快递单数据
val expressBillDetailDF: Dataset[Row] = dataframe.filter($"day" === dayValue)
// c. 对每日数据指标计算,将指标结果封装到Row对象中
// 指标一:总快递单数, SELECT COUNT("id") AS total FROM tbl_express_bill_detail
//expressBillDetailDF.count()
val totalDF: DataFrame = expressBillDetailDF.agg(count($"id").as("total"))
// 指标二:各类客户快递单数,最大、最小和平均
val typeTotalDF: DataFrame = expressBillDetailDF.groupBy($"type").count()
val typeTotalAggDF: DataFrame = typeTotalDF.agg(
max($"count").as("typeMaxTotal"),
min($"count").as("typeMinTotal"),
round(avg($"count"), 0).as("typeAvgTotal")
)
// 指标三:各网点快递单数,最大、最小和平均
val dotTotalDF: DataFrame = expressBillDetailDF.groupBy($"dot_id").count()
val dotTotalAggDF: DataFrame = dotTotalDF.agg(
max($"count").as("dotMaxTotal"),
min($"count").as("dotMinTotal"),
round(avg($"count"), 0).as("dotAvgTotal")
)
// 指标四:各渠道快递单数,最大、最小和平均
val channelTotalDF: DataFrame = expressBillDetailDF.groupBy($"order_channel_id").count()
val channelTotalAggDF = channelTotalDF.agg(
max($"count").as("channelMaxTotal"),
min($"count").as("channelMinTotal"),
round(avg($"count"), 0).as("channelAvgTotal")
)
// 指标五:各终端快递单数,最大、最小和平均
val terminalTotalDF: DataFrame = expressBillDetailDF.groupBy($"order_terminal_type").count()
val terminalTotalAggDF= terminalTotalDF.agg(
max($"count").as("terminalMaxTotal"),
min($"count").as("terminalMinTotal"),
round(avg($"count"), 0).as("terminalAvgTotal")
)
// 将所有指标结果封装到Row对象中
val aggRow: Row = Row.fromSeq(
Seq(dayValue) ++
totalDF.first().toSeq ++
typeTotalAggDF.first().toSeq ++
dotTotalAggDF.first().toSeq ++
channelTotalAggDF.first().toSeq ++
terminalTotalAggDF.first().toSeq
)
// 返回Row数据
aggRow
}
// step3. 转换列表List为DataFrame
// a. 将列表List转换为RDD
val rowRDD: RDD[Row] = spark.sparkContext.parallelize(aggRows)
// b. 将RDD转换为DataFrame
val rowSchema = new StructType()
.add("id", StringType, nullable = false)
.add("total", LongType, nullable = true)
.add("typeMaxTotal", LongType, nullable = true)
.add("typeMinTotal", LongType, nullable = true)
.add("typeAvgTotal", DoubleType, nullable = true)
.add("dotMaxTotal", LongType, nullable = true)
.add("dotMinTotal", LongType, nullable = true)
.add("dotAvgTotal", DoubleType, nullable = true)
.add("channelMaxTotal", LongType, nullable = true)
.add("channelMinTotal", LongType, nullable = true)
.add("channelAvgTotal", DoubleType, nullable = true)
.add("terminalMaxTotal", LongType, nullable = true)
.add("terminalMinTotal", LongType, nullable = true)
.add("terminalAvgTotal", DoubleType, nullable = true)
val aggDF: DataFrame = spark.createDataFrame(rowRDD, rowSchema)
// 返回聚合指标结果
aggDF
}
// SparkSQL 应用程序入口:MAIN 方法
/*
数据处理,实现步骤:
step1. 创建SparkSession对象,传递SparkConf对象
step2. 加载Kudu中的宽表数据
step3. 按照业务指标进行计算
step4. 将指标结果写回到Kudu数据库中
*/
def main(args: Array[String]): Unit = {
// step1. 创建SparkSession对象,传递SparkConf对象
val spark: SparkSession = SparkUtils.createSparkSession(
SparkUtils.autoSettingEnv(SparkUtils.sparkConf()), this.getClass
)
spark.sparkContext.setLogLevel(Configuration.LOG_OFF)
// step2. 加载Kudu中的宽表数据
val expressBillDetailDF: DataFrame = load(
spark, OfflineTableDefine.EXPRESS_BILL_DETAIL, isLoadFullData = Configuration.IS_FIRST_RUNNABLE
)
expressBillDetailDF.show(10, truncate = false)
// step3. 按照业务指标进行计算
val expressBillSummaryDF: DataFrame = process(expressBillDetailDF)
expressBillSummaryDF.show(10, truncate = false)
// step4. 将拉宽后的数据再次写回到Kudu数据库中
save(expressBillSummaryDF, OfflineTableDefine.EXPRESS_BILL_SUMMARY)
// 程序结束,关闭资源
spark.close()
}
}
```
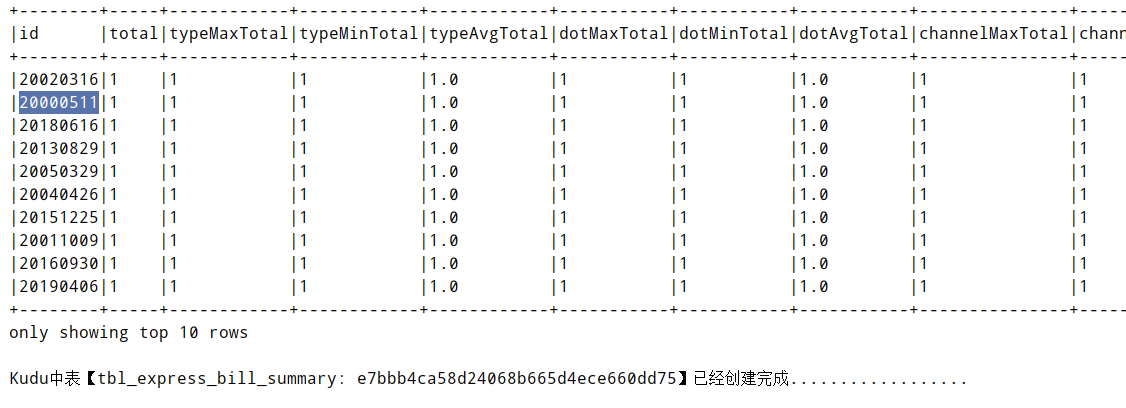
> 运行计算程序,到Kudu中查看结果:

- 点赞
- 收藏
- 关注作者
评论(0)