Nebula Graph - 全文索引

一、Nebula Graph - 全文索引
Nebula Graph 的全文索引,需要依靠于 Elasticsearch ,并且还存在着较多的限制,比如:
- 全文索引当前仅支持
LOOKUP语句。 - 定长字符串长度超过 256 字节,将无法创建全文索引。
- 如果
Tag/Edge type上存在全文索引,无法删除或修改Tag/Edge type。 - 一个
Tag/Edge type只能有一个全文索引。 - 属性的类型必须为String。
- 全文索引不支持多个
Tag/Edge type的搜索。 - 不支持排序全文搜索的返回结果,而是按照数据插入的顺序返回。
- 全文索引不支持搜索属性值为NULL的属性。
- 不支持修改
Elastic Search中的索引,只能删除重建。 - 不支持管道符。
WHERE子句只能用单个条件进行全文搜索。- 全文索引不会与图空间一起删除。
- 确保同时启动了
Elasticsearch集群和Nebula Graph,否则可能导致Elasticsearch集群写入的数据不完整。 - 在点或边的属性值中不要包含
'或\,否则会导致Elasticsearch集群存储时报错。 - 从写入
Nebula Graph,到写入listener,再到写入Elasticsearch并创建索引可能需要一段时间。如果访问全文索引时返回未找到索引,可等待索引生效(但是,该等待时间未知,也无返回码检查)。 - 使用
K8s方式部署的Nebula Graph集群不支持全文索引。
了解上面的限制了就可以使用 Nebula Graph 的全文索引了,否则的话,可能就要自己操控 es 实现全文索引了。
在开始前,需要安装好 Nebula Graph 环境 和 Elasticsearch 环境,可以参考下面来那个我的博客:
Nebula Graph 集群搭建:https://blog.csdn.net/qq_43692950/article/details/124802962
Elasticsearch 7.X 集群搭建:https://blog.csdn.net/qq_43692950/article/details/122244793
二、创建全文索引模板
Elasticsearch 环境搭建好后,需要创建全文索引模板,向 es 服务器发送 POST 请求:
http://192.168.40.128:9200/_template/nebula_index_template
- 1
请求体内容:
{
"template": "nebula*",
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"properties" : {
"tag_id" : { "type" : "long" },
"column_id" : { "type" : "text" },
"value" :{ "type" : "keyword"}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

进入 Nebula Graph 登录 Elasticsearch 客户端:
可以使用SIGN IN语句登录。必须使用 Elasticsearch 配置文件中的 IP 地址和端口才能正常连接,同时登录多个客户端,请在多个elastic_ip:port之间用英文逗号(,)分隔。
SIGN IN TEXT SERVICE (192.168.40.128:9200, HTTP);
- 1

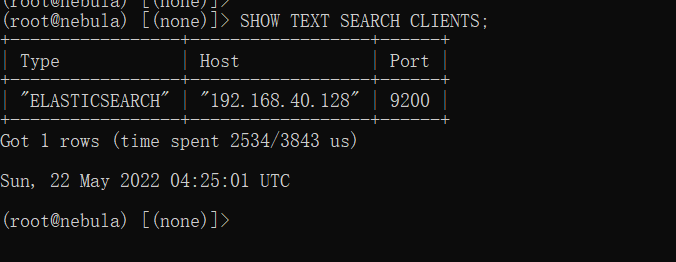
查看文本搜索客户端:
SHOW TEXT SEARCH CLIENTS;
- 1
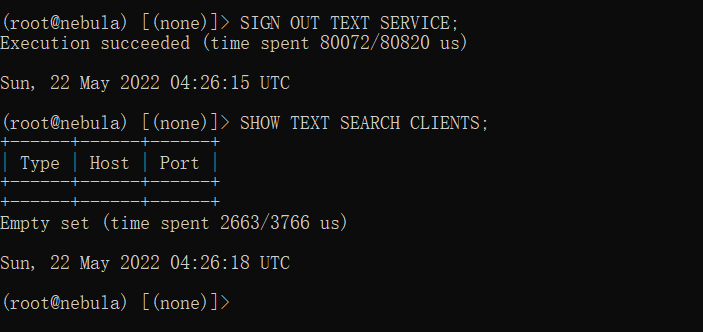
退出文本搜索客户端
SIGN OUT TEXT SERVICE;
- 1
三、部署 Raft listener
全文索引的数据是异步写入 Elasticsearch 的。流程是通过 Storage 服务的 Raft listener(简称 listener)这个单独部署的进程,从 Storage 服务读取数据,然后将它们写入 Elasticsearch 中。
下面需要准备一台或者多台额外的服务器,来部署 Raft listener。注意请保证 Nebula 各组件(Metad、Storaged、Graphd、listener)有相同的版本。
注意:只能为一个图空间“一次性添加所有的 listener 机器”。尝试向已经存在有 listener 的图空间再添加新 listener 会失败。因此,需在一个命令语句里完整地添加全部的 listener。
listener 进程与 storaged 进程使用相同的二进制文件,但是二者配置文件不同,进程使用端口也不同,可以在所有需要部署 listener 的服务器上都安装 Nebula Graph,但是仅使用 Storage 服务。安装 Nebula Graph 的可以参考上面的两个链接。
下面可以在安装路径下的etc目录下找到 listener 的配置文件,文件名称必须为nebula-storaged-listener.conf 。
官方提供的模板地址:https://github.com/vesoft-inc/nebula/blob/master/conf/nebula-storaged-listener.conf.production
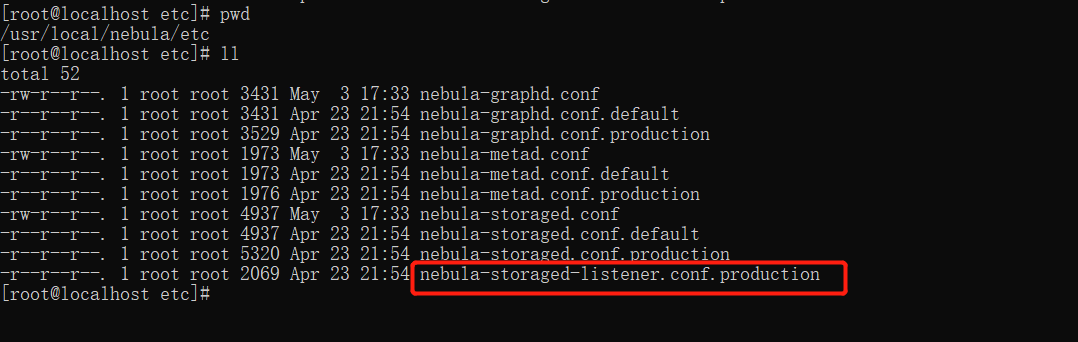
重命名:
mv nebula-storaged-listener.conf.production nebula-storaged-listener.conf
- 1
修改配置文件:
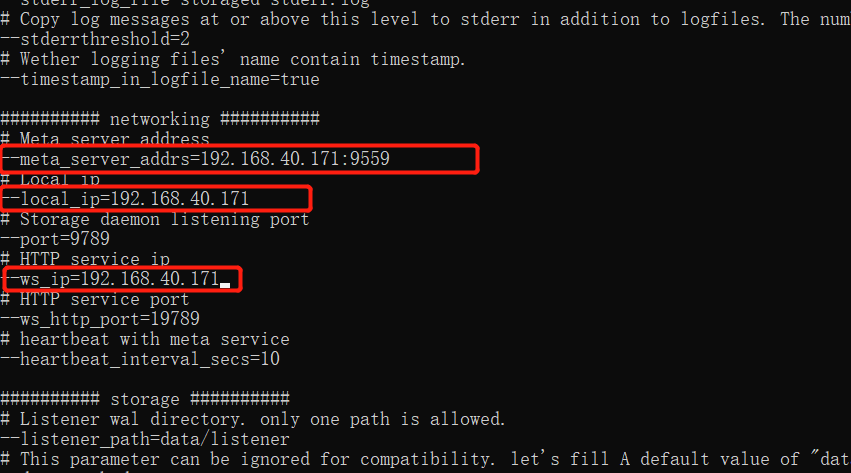
启动 listener:
./bin/nebula-storaged --flagfile /usr/local/nebula/etc/nebula-storaged-listener.conf
- 1

进入 Nebula Graph,添加 listener ,多个 listener 服务用逗号隔开 ,注意添加前需要选中一个 space:
ADD LISTENER ELASTICSEARCH 192.168.40.171:9789;
- 1
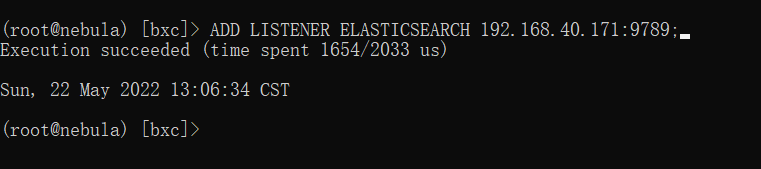
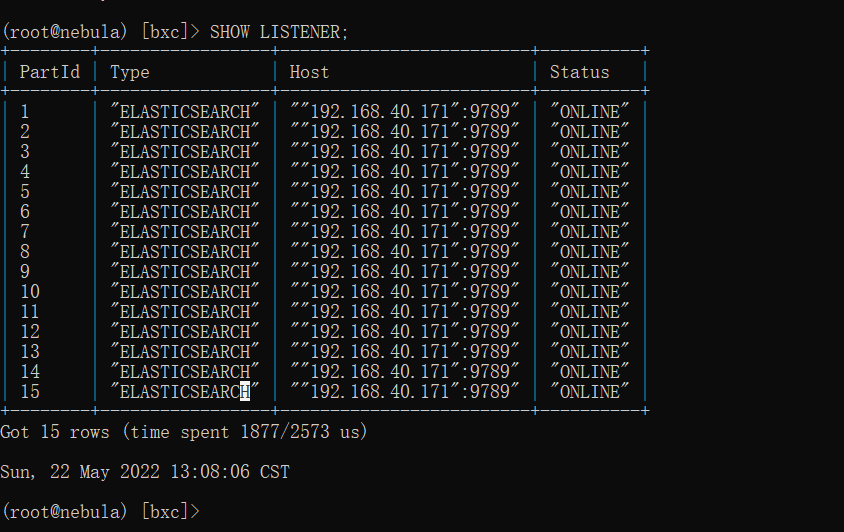
查看 listener:
SHOW LISTENER;
- 1
补充:删除图空间的所有 listener(谨慎操作)
注意:删除 listener 后,将不能重新添加 listener,因此也无法继续向 ES 集群同步,文本索引数据将不完整。如果确实需要,只能重新创建图空间。
REMOVE LISTENER ELASTICSEARCH;
- 1
四、全文搜索
进入上面添加 listener space 中。
创建测试 tag :
create tag team(team_name string, persion_num int);
- 1
添加测试数据:
insert vertex team(team_name, persion_num) values "team_1":("小明的团队", 42);
insert vertex team(team_name, persion_num) values "team_2":("小明的第二个团队", 42);
insert vertex team(team_name, persion_num) values "team_3":("小明的第三个团队", 42);
insert vertex team(team_name, persion_num) values "team_4":("小红的测试团队", 42);
insert vertex team(team_name, persion_num) values "team_5":("小红的开发团队", 42);
- 1
- 2
- 3
- 4
- 5
创建原生索引进行测试:
create tag index if not exists team_index on team(team_name(20));
- 1
重建索引:
rebuild tag index team_index;
- 1
使用原生索引查询
lookup on team where team.team_name == "小红的开发团队" yield id(vertex),properties(vertex);
- 1

下面创建全文索引:
注意:索引名称需要以 nebula 开头,原因就是上面创建 es 模板的时候就是指定的 以 nebula 开头。
create fulltext tag index nebula_team_full_index on team(team_name);
- 1

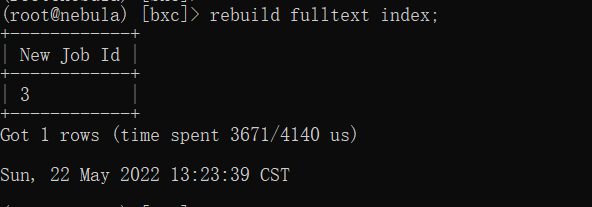
重建全文索引:
rebuild fulltext index;
- 1
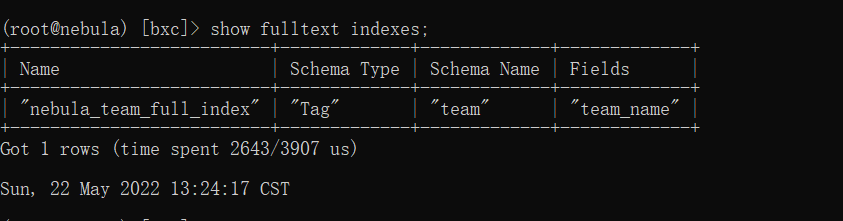
查看全文索引:
show fulltext indexes;
- 1
使用全文索引:
PREFIX 前缀匹配
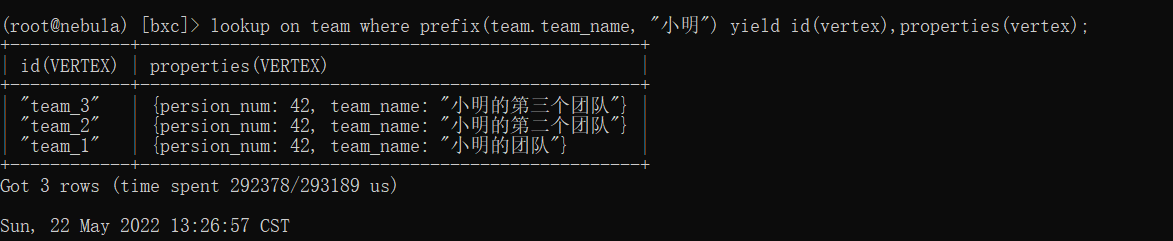
lookup on team where prefix(team.team_name, "小明") yield id(vertex),properties(vertex);
- 1
WILDCARD 通配符匹配
lookup on team where wildcard(team.team_name, "*测试*") yield id(vertex),properties(vertex);
- 1

REGEXP 正则匹配:
lookup on team where regexp(team.team_name, ".*开发.*") yield id(vertex),properties(vertex);
- 1

FUZZY 模糊查询:
fuzzy(schema_name.prop_name, fuzzy_string, fuzziness, operator, row_limit, timeout)
- fuzziness:可选项。允许匹配的最大编辑距离。默认值为auto。查看其他可选值和更多信息,请参见 Elasticsearch 官方文档。
- operator:可选项。解释文本的布尔逻辑。可选值为or(默认)和and。
lookup on team where fuzzy(team.team_name, "小明的开发团队",auto, or) yield id(vertex),properties(vertex);
- 1

扩展:补充:删除全文索引
drop fulltext index nebula_team_full_index ;
- 1
文章来源: blog.csdn.net,作者:小毕超,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_43692950/article/details/124908644

- 点赞
- 收藏
- 关注作者
评论(0)