mysql优化技巧点

一、EXPLAIN SQL分析工具
explain主要用于查看SQL语句的执行计划,可以看出SQL执行的详细信息。
EXPLAIN select * from user where id=1;
- 1
其中参数含义为:
- ID列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。MySQL将 select 查询分为简单查询(SIMPLE)和复杂查询(PRIMARY)。复杂查询分为三类:简单子查询、派生表(from语句中的子查询)、union 查询。id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。 - select_type
表示查询的类型:
(1) SIMPLE(简单查询。查询不包含子查询和union)
(2) PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select)
(6) SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
-
Table
这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,table列是 格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。当有 union 时,UNION RESULT 的 table 列的值为<union1,2>,1和2表示参与 union 的 select 行id。 -
type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref。
(1)ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
(2)index: Full Index Scan,index与ALL区别为index类型只遍历索引树
(3)range:只检索给定范围的行,使用一个索引来选择行
(4)ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
(5)eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
(6)const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
(7)NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。 -
possible_keys 和 key
possible_keys这一列显示查询可能使用哪些索引来查找,key是真正使用的索引。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。 如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。 -
key_len
索引的长度,计算规则:
(1)字符串
char(n):n字节长度
varchar(n):2字节存储字符串长度,如果是utf-8,则长度 3n + 2
(2)数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
(3)时间类型
date:3字节
timestamp:4字节
datetime:8字节
如果字段允许为 NULL,需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
- Extra
Extra表示附加信息,常见的有如下几种(也按查询效率从高到低排列):
Using where:
表示MySQL将对存储引擎层提取的结果进行过滤,过滤条件字段无索引, Using where本身其实和是否使用索引无关,它表示的是Server层对存储引擎层返回的数据所做的过滤。当然该过滤可能会回表,也可能不会回表,取决于查询字段是否被索引覆盖。
Using index:
表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表;
Using index condition:
在5.6版本后加入的新特性(Index Condition Pushdown);
Using index condition :
根据条件索引查询,但是需要回表查询数据;
注意:
Using filesort不是硬盘的排序,表示表示没有使用索引的排序,还是在内存中进行排序的。
二、总结使用索引注意点
- 全值匹配。
- 遵循最佳左前缀法则。
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描。
- 存储引擎不能使用索引中范围条件右边的列(范围之后全失效,不包括本身).若中间索引列用到了范围(>、<、like等),则后面的所以全失效。
- 尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select *语句。
- mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫。
- is null,is not null 也无法使用索引。
- like以通配符开头(’$abc…’)mysql索引失效会变成全表扫描操作。
- 字符串不加单引号索引失效。
- 少用or,用它连接时很多情况下索引会失效
三、排序注意点
- 1.使用explain分析时显示为using index,不需要额外的排序, 是指mysql扫描索引本身完成排序,操作效率较高。
- 通过对返回数据进行排序,即filesort,所有不通过索引直接返回排序结果的排序都是filesort排序。
四、设置事物的隔离级别
查看事物隔离级别
select @@tx_isolation;
- 1
- 读未提交 可能会产生脏读
set tx_isolation='read-uncommitted';
- 1
- 读已提交 避免脏读的问题
set tx_isolation='read-committed';
- 1
- 可重复读
set tx_isolation='repeatable-read';
- 1
- 串行化
set tx_isolation='serializable';
- 1
五、声明式事物注意点
需要加 rollbackFor = Exception.class
@Transactional(rollbackFor = Exception.class)
- 1
当我们使用@Transaction 时默认为RuntimeException(也就是运行时异常)异常才会回滚。
简单说下异常吧,异常分为检查异常,和非检查异常(也就是运行时异常)。
检查异常例如IOException异常等,在你写代码时编译提示你必须try catch 或向上抛,反正就是必须处理。
而运行时异常,就是在运行时的产生异常,例如/by zero异常。
所以当我们抛出java.io.FileNotFoundException检查异常时导致了数据的不回滚
六、事物传播行为
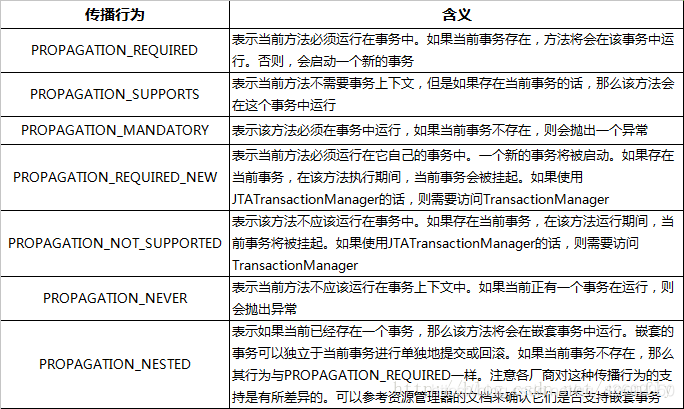
七、查看所有未提交的事物
//查看所有事物信息
select * from information_schema.innodb_trx t
//查看所有线程
show full processlist;
//清除事物线程
kill 5472
- 1
- 2
- 3
- 4
- 5
- 6
八、数据插入速度优化
1、innodb_flush_log_at_trx_commit 提交事务的时候将 redo 日志写入磁盘中的策略
show variables like '%innodb_flush_log_at_trx_commit%';
- 1
innodb_flush_log_at_trx_commit 设置为 0,log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行.该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。(提交事务的时候,不立即把 redo log buffer 里的数据刷入磁盘文件的,而是依靠 InnoDB 的主线程每秒执行一次刷新到磁盘。此时可能你提交事务了,结果 mysql 宕机了,然后此时内存里的数据全部丢失。)
innodb_flush_log_at_trx_commit设置为 1,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去。(提交事务的时候,就必须把 redo log 从内存刷入到磁盘文件里去,只要事务提交成功,那么 redo log 就必然在磁盘里了。注意,因为操作系统的“延迟写”特性,此时的刷入只是写到了操作系统的缓冲区中,因此执行同步操作才能保证一定持久化到了硬盘中。)
innodb_flush_log_at_trx_commit设置为 2,每次事务提交时MySQL都会把log buffer的数据写入log file.但是flush(刷到磁盘)操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。(提交事务的时候,把 redo 日志写入磁盘文件对应的 os cache 缓存里去,而不是直接进入磁盘文件,可能 1 秒后才会把 os cache 里的数据写入到磁盘文件里去。)
set global innodb_flush_log_at_trx_commit = 2;
- 1
2、sync_binlog binlog刷入磁盘的策略
show variables like '%sync_binlog%';
- 1
当 sync_binlog =0,像操作系统刷其他文件的机制一样,MySQL不会同步到磁盘中去而是依赖操作系统来刷新binary log。
当 sync_binlog =N (N>0) ,MySQL 在每写 N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
set global sync_binlog = 2000;
- 1
3、在做数据迁移时可做下面优化处理
set global innodb_flush_log_at_trx_commit = 2;
set global sync_binlog = 2000;
mysql -uroot -pxxxxxx testdb < testdb.sql
set global innodb_flush_log_at_trx_commit = 1;
set global sync_binlog = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
九、共享锁和排它锁
-- 会等待行锁释放之后,返回查询结果。
select * from stock where id = 1 for update
-- 不等待行锁释放,提示锁冲突,不返回结果
select * from stock where id = 1 for update nowait
-- 等待5秒,若行锁仍未释放,则提示锁冲突,不返回结果
select * from stock where id = 1 for update wait 5
-- 查询返回查询结果,但忽略有行锁的记录
select * from stock for update skip locked
-- 共享锁
select * from stock where id = 1 lock in share mode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
十、数据存在就更新,避免再判断数据是否存在
有时候我们再做数据操作的时候,如果数据不存在需要进行写入,存在的话就进行更新,一般都是先进行一次count 统计,如果大于0则表示数据库中存在,但这种情况下,对于并发操作极有可能造成冲突,比如两个线程同时执行这串逻辑,由于其mysql行锁的原因,必定有一个会先写入成功,另一个再次写入就会造成数据库的重复,或者主键或唯一键的冲突。
然而mysql 为我们提供了 on duplicate key update 机制,如果主键或唯一键存在,则执行后面的更新操作,比如:
INSERT INTO lock_table(lockid,lockcount) values('003',1) on duplicate key update lockcount = lockcount + 1
- 1
其中lockid为主键,使用 on duplicate key update 必须要包含一个主键或唯一键。
另外mysql 还为我们提供了 replace into 机制, 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据,否则,直接插入新数据,格式如下:
replace into `table_name`(`col_name`, ...) values (...);
replace into `table_name` (`col_name`, ...) values ...;
replace into `table_name` set `col_name`='value';
- 1
- 2
- 3
两者在数据量不大的情况下,速度相差不大,在大数据的情况下,由于replace into发现重复会做删除再插入操作,因此速度较 on duplicate key update 慢,因次首先on duplicate key update进行使用。
文章来源: blog.csdn.net,作者:小毕超,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_43692950/article/details/113483640

- 点赞
- 收藏
- 关注作者
评论(0)