GIF验证码分析

【摘要】
GIF验证码 和 普通验证码 的区别是图片上的文字是时隐时现的,如果按帧数查看,每帧都会缺失文字。
GIF验证码图片示例:
所以现在有如下思路:
方案一:对图片多次截图,然后把所有图片的数组合并...
GIF验证码 和 普通验证码 的区别是图片上的文字是时隐时现的,如果按帧数查看,每帧都会缺失文字。
GIF验证码图片示例:
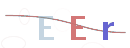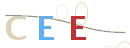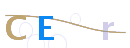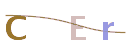

所以现在有如下思路:
- 方案一:对图片多次截图,然后把所有图片的数组合并覆盖到一张图中,再识别得到完整图片。
- 方案二:对图片多次抽帧,然后对每张图片单独识别,每个位置出现字符频率最高的则为正确结果。
方案一代码:
from PIL import Image
import numpy as np
import cv2
path = r"C:\Users\lixi\Desktop\p1.gif"
image =Image.open(path)
shapes = []
for i in range(1,4):
image.seek(i)
image.save(f'image/{i}.png')
shapes.append(np.array(image))
result = np.subtract(shapes[0], shapes[2])
result2 = np.subtract(shapes[0], shapes[1])
result3 = np.subtract(shapes[1], shapes[2])
cv2.imwrite("image/result.png", shapes[0] + result+result2+result3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
合并后的图片:

方案二代码:(代码转自 https://juejin.cn/post/6855483334512869389)
# -*- coding: utf-8 -*-
# @Software: PyCharm
import requests
import time
import json
from PIL import Image
from io import BytesIO
from collections import Counter
def get_max_char(str):
'''
获取频率最高字符
:param str:
:return:
'''
count = Counter(str)
count_list = list(count.values())
max_value = max(count_list)
max_list = []
for k, v in count.items():
if v == max_value:
max_list.append(k)
return max_list[0]
def recogition(yzm_data):
'''
验证码识别
:param yzm_data:
:return:
'''
resp = requests.post('http://127.0.0.1:8080', data=yzm_data)
return resp.text
def img_to_text(yzmdatas):
'''
图片转字符
:param length:
:return:
'''
yzm1 = ""
yzm2 = ""
yzm3 = ""
yzm4 = ""
for data in yzmdatas:
text = recogition(data)
json_obj = json.loads(text)
yzm_text = json_obj.get("code","")
#本文中的验证码长度为4 实际测试中只要长度大于等于4的都可以统计进去,不影响识别准确率
if len(yzm_text) == 4:
l_yzm = list(yzm_text)
yzm1 = yzm1 + l_yzm[0]
yzm2 = yzm2 + l_yzm[1]
yzm3 = yzm3 + l_yzm[2]
yzm4 = yzm4 + l_yzm[3]
yzm1 = get_max_char(yzm1)
yzm2 = get_max_char(yzm2)
yzm3 = get_max_char(yzm3)
yzm4 = get_max_char(yzm4)
return yzm1+yzm2+yzm3+yzm4
def download():
'''
下载验证码
:return:
'''
#验证码地址
url = 'http://credit.customs.gov.cn/ccppserver/verifyCode/creator'
resp = requests.get(url)
data = resp.content
return data
def gif_to_png(length,image):
'''
gif抽帧
:param length:
:param image:
:return:
'''
try:
yzm_list = []
for i in range(1, length):
image.seek(i)
stream = BytesIO()
image.save(stream, 'PNG')
s = stream.getvalue()
yzm_list.append(s)
return yzm_list
except Exception as e:
print(e)
return None
def handle_yzm(length):
'''
处理验证码
:return:
'''
gif = download()
start = time.time()
if gif:
data = BytesIO(gif)
image = Image.open(data)
png_list = gif_to_png(length, image)
if png_list:
yzm_text = img_to_text(png_list)
with open("./Gif_IMG/{}_{}.gif".format(yzm_text, str(time.time())),"wb") as fw:
fw.write(gif)
end = time.time()
print("抽帧length:{}-花费时间:{}".format(length, end - start))
def run():
#抽帧长度:具体抽帧多少可以依据实际的gif识别准确率来调整。
#抽帧越少识别率可能会低,但是识别所需的时间会减少。23帧准确率98%,时间1s; 6帧准确率85%,时间0.5s左右
#在识别速度和精度之间找一个平衡点即可
length = 10
#识别图片个数
num = 20
for i in range(num):
handle_yzm(length)
if __name__ == '__main__':
run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
方案一比较简单粗暴,但是会把其他干扰元素也合并到一块,所以合并后还需要其他处理方法。
方案二代码转别人的,效果会好一点,先识别再合成,但是效率不高,需要自己改。
两个方案的代码在使用时都需要优化和调整,大家根据自己的需求选择对应的方案。
文章来源: blog.csdn.net,作者:考古学家lx(李玺),版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_43582101/article/details/125277680

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)