用ModelArts带你快速完成花卉图像分类【玩转华为云】

本文的主要内容有:
- 一 图像分类必须掌握的知识点
-
二 ModelArts简单了解下
- 三 用ResNet_v1_50模型重训练
- 四 部署训练的模型
- 五 发起预测请求

一 图像分类必须掌握的知识点
1.1 定义是啥?
顾名思义就是识别图片属于什么分类。图片分类技术是计算机视觉中重要的基本问题,也是目标检测,图像分割,物体追踪等视觉任务的基础。图像分类有广泛的应用,如网盘图片自动分类,卡片类别识别,动植物识别等;

数据集类型分为两种:一是学术研究的数据集,一般不使用自己构建的数据集,而是使用公开数据集。因为学术的目的它是促进该领域的进步与发展,这样只有在相同的数据集上进行训练测试才能说明新的模型是否更加优秀。常用的分类公开数据集有mnist,cifar10,cifar100,ImageNet等;二是产业型数据集往往需要收集业务数据,并做数据标注,大致流程如下:
- 在业务场景下采集图像
- 确定图像分类信息
- 标注人员对图像进行标注;(可以直接将图片放到以类别命名的文件夹下)
如果业务场景数据量有限时,可以结合开源数据集来构造数据集
1.2 数据集如何划分呢
咱们一般把数据集划分成训练集,验证集,以及测试集,一般是9:1:1即可。训练集用以训练模型,验证集是用以在模型训练满足一定迭代条件,对当前的模型进行评估。测试集是在模型训练完毕后再对得到的模型进行测试评估。为了得到泛化能力好的模型,训练集,测试集和验证集的数据不能有重叠地方;
1.3 模型该如何训练?
首先预处理
数据预处理是在模型训练之前,对数据进行增强,譬如说图像归一化,resize等,可以参考imgaug图像增强库;
然后模型构建
当前很多深度学习框架都有典型模型实现,可以直接拿来用,也可以在这些模型基础上进行修改,当然也可以自己实现;
最后是才是训练
这里说下你必须掌握的名词,也就是一些常用的超参数
- 迭代轮数:迭代次数要根据数据规模来定,一般而言,过大的迭代轮数可能导致模型过拟合,这里需要根据loss,acc等因素作出是否earlystop;
- 学习率:学习率不宜过大,一般0.001。或者使用学习率衰减策略,如余弦衰减策略等;
- 批大小:批大小需要根据自己的机器进行设置,一般批大小过大会导致训练挂掉,因为现存不足,调小就可以了。可以使用nvidia-smi查看显存使用情况;
- 定义及假设:
- T(True)代表正确、F(False)代表错误、P(Positive)代表1、N(Negative)代表0;
- TP:预测为1,实际为1,预测正确
- FP:预测为1,实际为0,预测错误
- FN:预测为0,实际为1,预测错误
- TN:预测为0,实际为0,预测正确
-
准确率
即:预测正确的结果占总样本的百分比;
公式为:准确率=
![[公式]](https://res-hd.hc-cdn.cn/ecology/9.3.209/v2_resources/ydcomm/libs/images/loading.gif)
虽然准确率能够判断总的正确率,但是在样本不均衡的情况下,并不能作为很好的指标来衡量结果。比如在样本集中,正样本有900个,负样本有10个,样本是严重的不均衡。对于这种情况,我们只需要将全部样本预测为正样本,就能得到99%的准确率,但完全没有意义。对于新数据,完全体现不出准确率。因此,在样本不平衡的情况下,得到的高准确率没有任何意义,此时准确率就会失效;
-
精确率
精确率(Precision)是针对预测结果而言的,其含义是在被所有预测为正的样本中实际为正样本的概率;
公式为:精确率=
下面通过一个例子来说明精确率和召回率有啥差别呢?假设一共有10篇文章,里面4篇是你要找的。根据算法模型,找到了5篇,但实际上在这5篇之中,只有3篇是你真正要找的;
那么算法的精确率是3/5=60%,也就是你找的这5篇,有3篇是真正对的。算法的召回率是3/4=75%,也就是需要找的4篇文章,你找到了其中三篇;
二 ModelArts简单了解下
ModelArts 是面向开发者的一站式AI平台,是给机器学习与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力,能够快速创建和部署模型,管理全周期AI工作流;

2.1 特色功能有这些
说白了一站式帮你解决AI工具安装配置、数据准备、模型训练慢这些问题的,最后把模型部署起来,集成到生产环境。
- 数据治理
支持数据筛选、标注等数据处理,提供数据集版本管理,特别是深度学习的大数据集,让训练结果可重现
- 极“快”致“简”模型训练
自研的MoXing深度学习框架,更高效更易用,大大提升训练速度
- 云边端多场景部署
支持模型部署到多种生产环境,可部署为云端在线推理和批量推理,也可以直接部署到端和边
- 自动学习
支持多种自动学习能力,通过“自动学习”训练模型,用户不需编写代码即可完成自动建模、一键部署
- AI Gallery
预置常用算法,支持模型在企业内部共享或者公开共享
2.2 支持哪些AI框架呢
- ModelArts的开发环境、训练作业、模型推理(即AI应用管理和部署上线)支持的AI框架,不同模块的呈现方式存在细微差异;注意的是开发环境的Notebook,根据不同Python版本,对应支持的镜像和版本有所不同;


当前ModelArts同时存在新版训练和旧版训练,也就是新版训练和旧版训练的预置训练引擎存在差异。ModelArts推荐您使用新版训练创建训练作业,如果您需要的引擎仅在旧版支持,也支持您在新版训练中使用旧版预置引擎,更多详情:https://support.huaweicloud.com/productdesc-modelarts/modelarts_01_0019.html;
2.3 ModelArts权限咋样
一般情况下,管理员创建的IAM用户是没有任何权限的,需要把它加入用户组,并给用户组授予策略或角色,这样才能使得用户组中的用户获得对应的权限,这一过程称为授权。授权后,用户就可以基于授予的权限对云服务进行操作;
我们在部署时通过物理区域划分,给项目级服务,授权的时候,“作用范围”需要你选择“区域级项目”,然后在其指定区域(如华北-北京1)对应的项目(cn-north-1)中设置相关权限,并且该权限仅对此项目生效;如果在“所有项目”中设置权限,那么该权限在所有区域项目中都能生效。访问ModelArts时,需要先切换至授权区域;
- 角色:IAM最初提供的一种根据用户的工作职能定义权限的粗粒度授权机制。该机制以服务为粒度,提供有限的服务相关角色用于授权。由于华为云各服务之间存在业务依赖关系,因此给用户授予角色时,可能需要一并授予依赖的其他角色,才能正确完成业务。角色并不能满足用户对精细化授权的要求,无法完全达到企业对权限最小化的安全管控要求;
- 策略:IAM最新提供的一种细粒度授权的能力,可以精确到具体服务的操作、资源以及请求条件等。基于策略的授权是一种更加灵活的授权方式,能够满足企业对权限最小化的安全管控要求。例如:针对ECS服务,管理员能够控制IAM用户仅能对某一类云服务器资源进行指定的管理操作;
下面列出了ModelArts常用操作与系统策略的授权关系,您可以参照该表选择合适的系统策略;

三 用ResNet_v1_50模型重训练
3.1 首先了解OBS?
也就是对象存储服务,它是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力,包括:创建、修改、删除桶,上传、下载、删除对象等;更多来这里看下:https://support.huaweicloud.com/obs/index.html
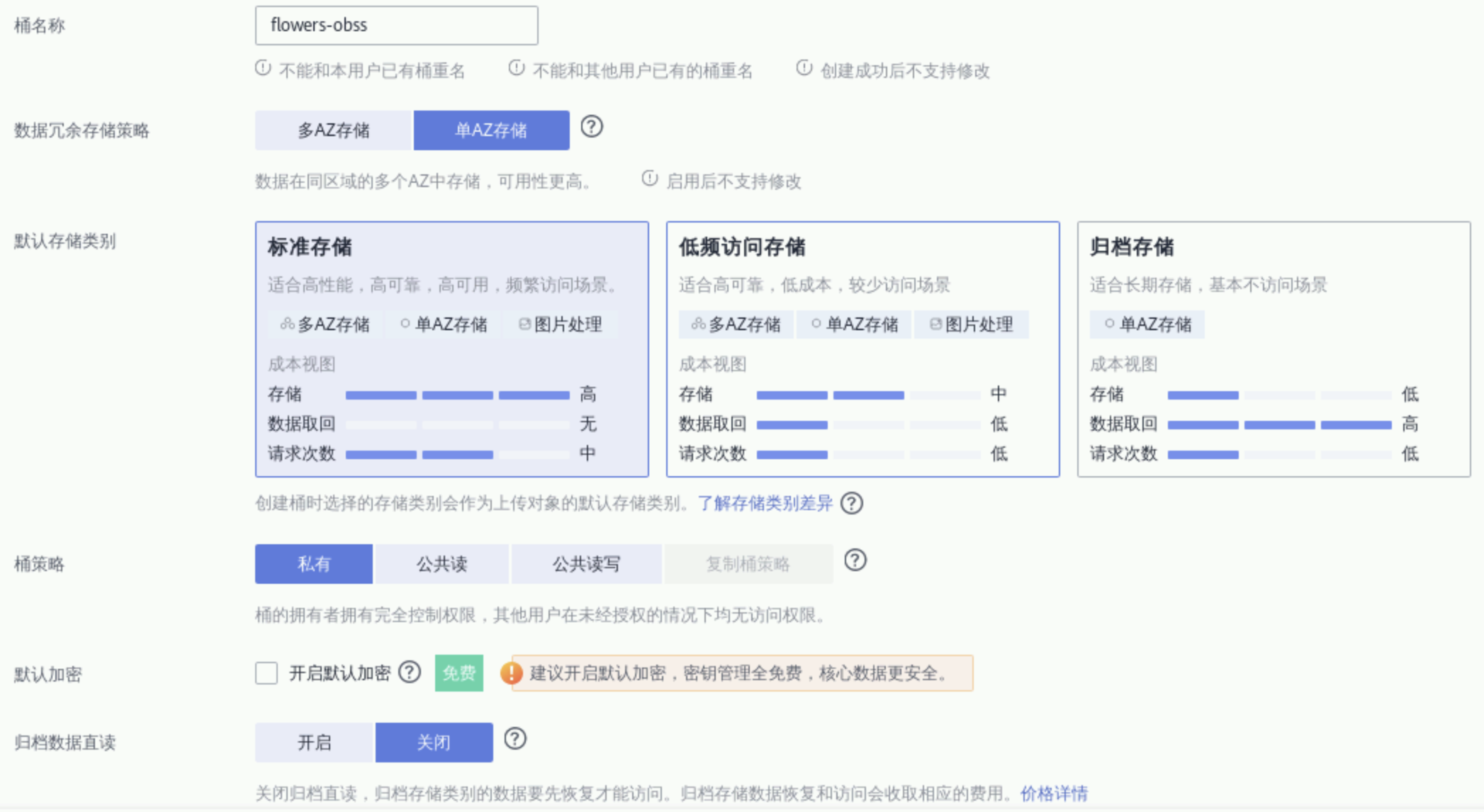
看上面填,完成回到对象存储服务列表,然后点击刚刚创建的OBS桶名称进入详情页,选择左侧“对象”->“新建文件夹”(存放后续步骤的数据文件),名称任意(请记住此名称以备后续相关步骤使用),点击“确定”,如下图:
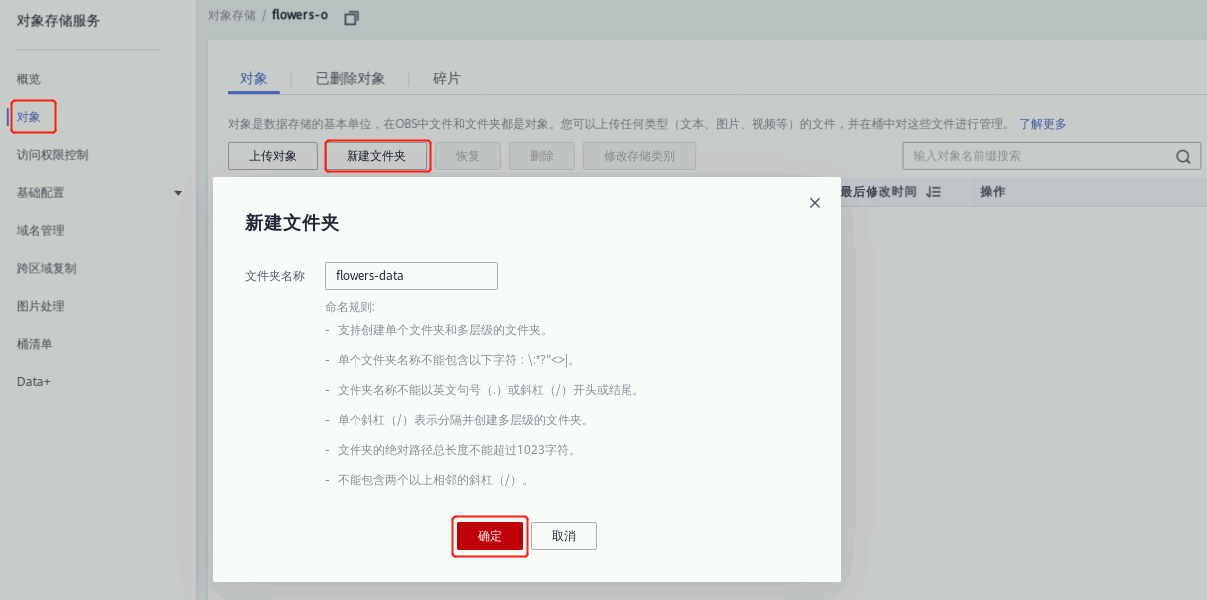
3.2 创建NoteBook复制数据
在服务列表中找到并进入人工智能服务 ModelArts,然后点击ModelArts 页面中左侧的【开发环境】选项一点击【notebook】 进入notebook 页面。点击【创建】按钮进入创建页面,并按下面参数来配:
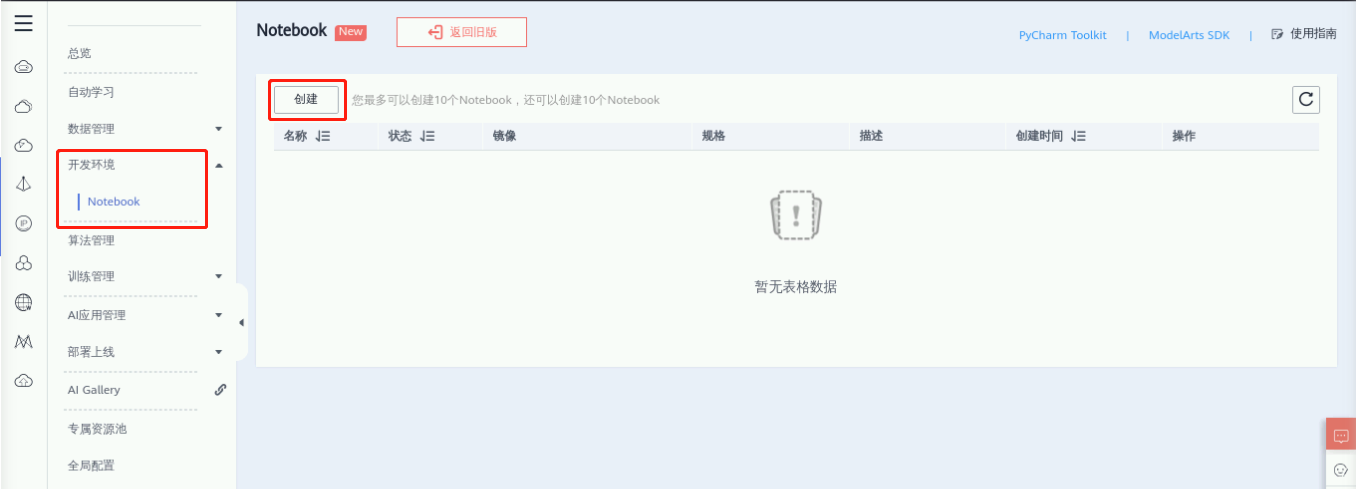
然后进入到创建页面里面,参数要求下面这些:
① 名称:任意,如flowers-notebook
② 自动停止:2小时后
③ 镜像:公共镜像:在第二页选择tensorflow1.13-cuda10.0-cudnn7-ubuntu18.0.4-GPU算法开发和训练基础镜像,预置AI引擎Tensorflow1.13.1
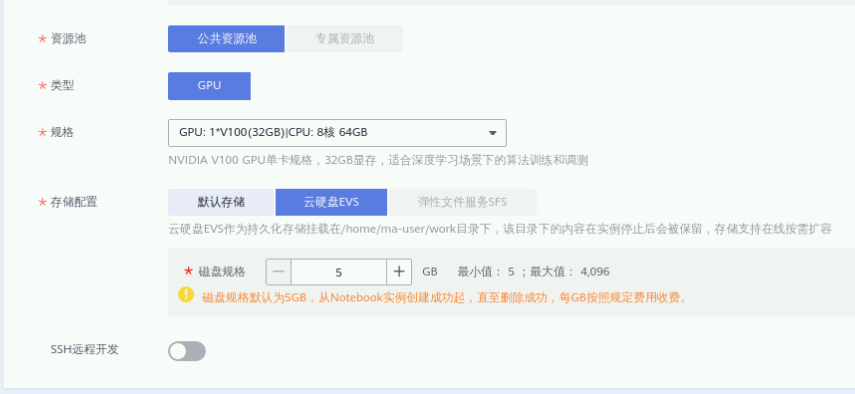
④ 资源池:公共资源池
⑤ 类型:GPU
⑥ 规格:8核64GB
⑦ 储存配置:云硬盘(5GB)
其它参数默认,点击“立即创建”->“提交”
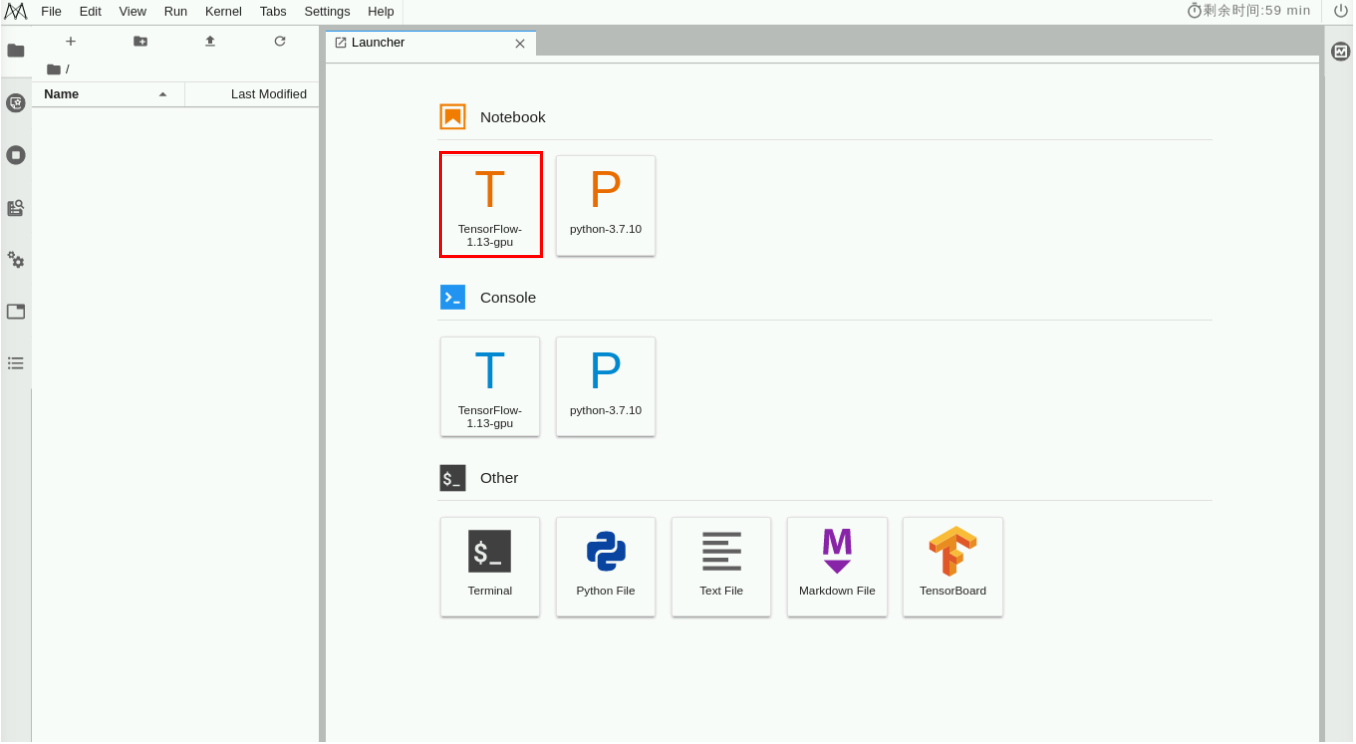
创建成功,然后返回NoteBook列表,等待状态变为“运行中”【约等待3分钟】,然后点击“打开”,进入NoteBook详情页,在页面中选择“TensorFlow-1.13.1”,如下图所示:
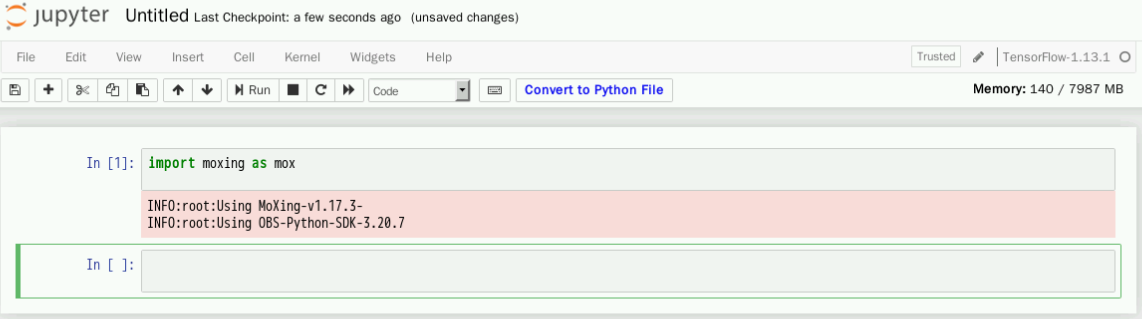
进入Python命令输入界面,输入如下命令后,点击“Run”:
import moxing as mox执行成功后如图所示:
复制如下命令,粘贴至Python命令输入第二行(命令需修改后执行)
修改说明:将代码中的“your_bucket_name”替换为创建的OBS桶名称;将代码中的“your_folder_name”替换为OBS桶中创建的文件夹名称(1.1步骤中要求记住的任意名称)
mox.file.copy_parallel('s3://sandbox-experiment-resource-north-4/flowers-data/flowers-100', 's3://your_bucket_name/your_folder_name')点击“Run”运行代码,等待运行成功【需要30s左右】,运行成功,意味着数据文件已成功复制到OBS桶内,运行成功如下图:

说明:进入华为云控制台,鼠标移动到云桌面浏览器页面中左侧菜单栏,然后点击“服务列表”-> 选择“存储”的“对象存储服务”,点击桶名,点击文件夹可以查看复制的文件,即训练所需的数据集;
3.3 创建训练作业
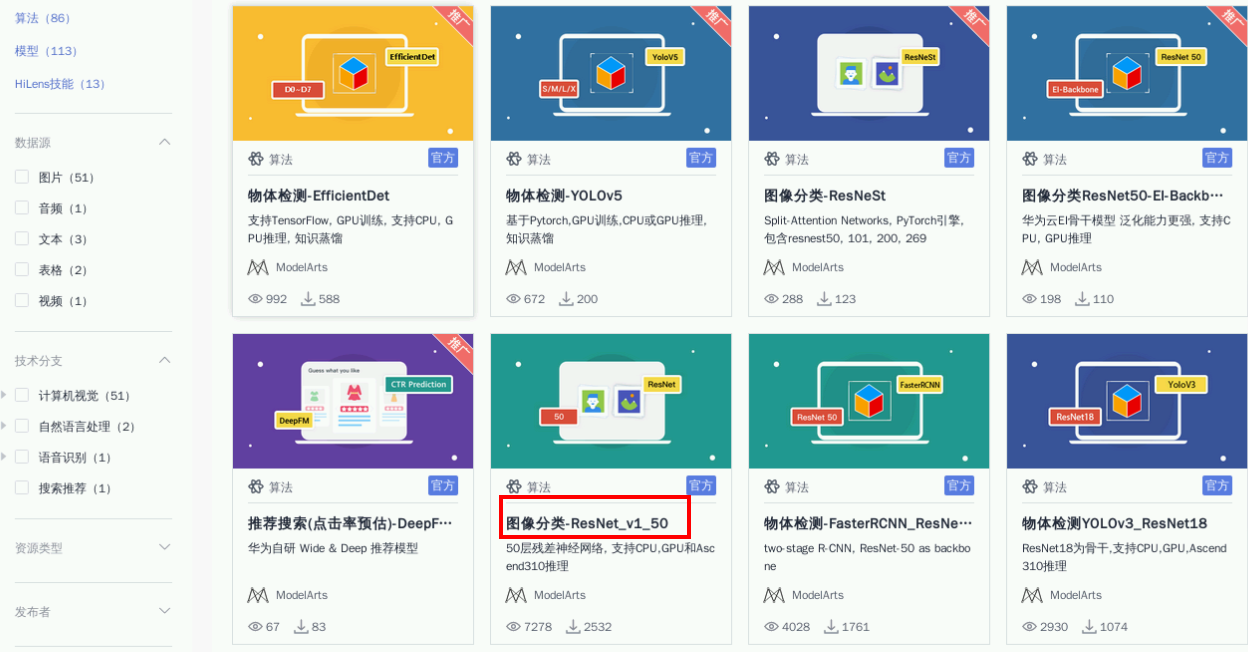
回到ModelArts界面上来,然后进入左侧导航栏的【AI Gallery】在【AI Gallery】页面点击顶部【算法】进入算法页面,然后选算法【图像分类-ResNet_v1_50】
(也可在谷歌浏览器新建1个新页签,然后输入链接【https://marketplace.huaweicloud.com/markets/aihub/modelhub/detail/?id=40b66195-5bbe-463d-b8a2-03e57073538d】进入也行)
点击“订阅”,如果显示“已订阅”则无需操作,如下图所示
点击“前往控制台”,如下图所示:
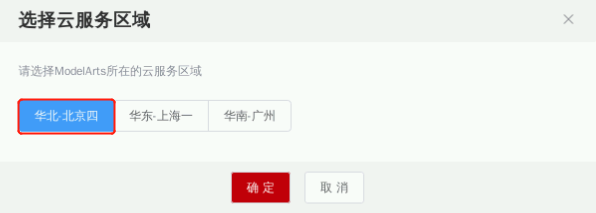
若出现以下弹窗内容,请务必选择“华北-北京四”区域
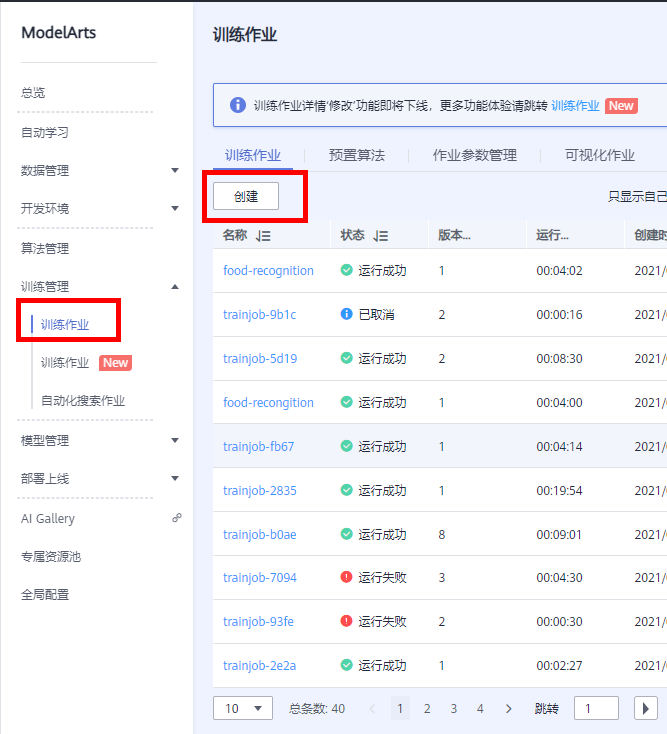
然后接下来回到在ModelArts主界面,在【训练管理】选择训练作业,点击【创建】,如下图所示
在创建训练作业页面中选择算法
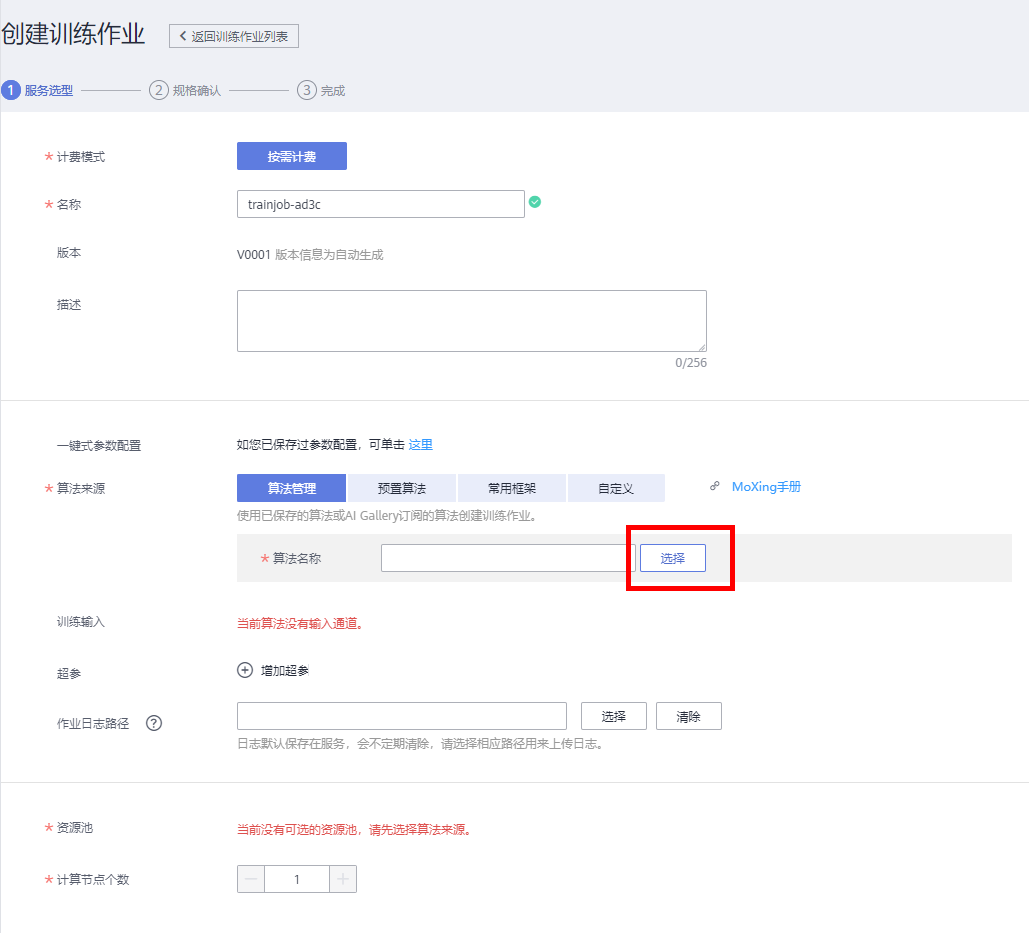
点击【选择】后在选择算法框中,点击【我的订阅】,在我的订阅算法中找到算法【图像分类-ResNet_v1_50】,点击算法名称,在弹出下拉框中选择【10.0.0】(算法是按订阅时间显示的,若之前已订阅则需往前查找该算法‘图像分类-ResNet_v1_50’)
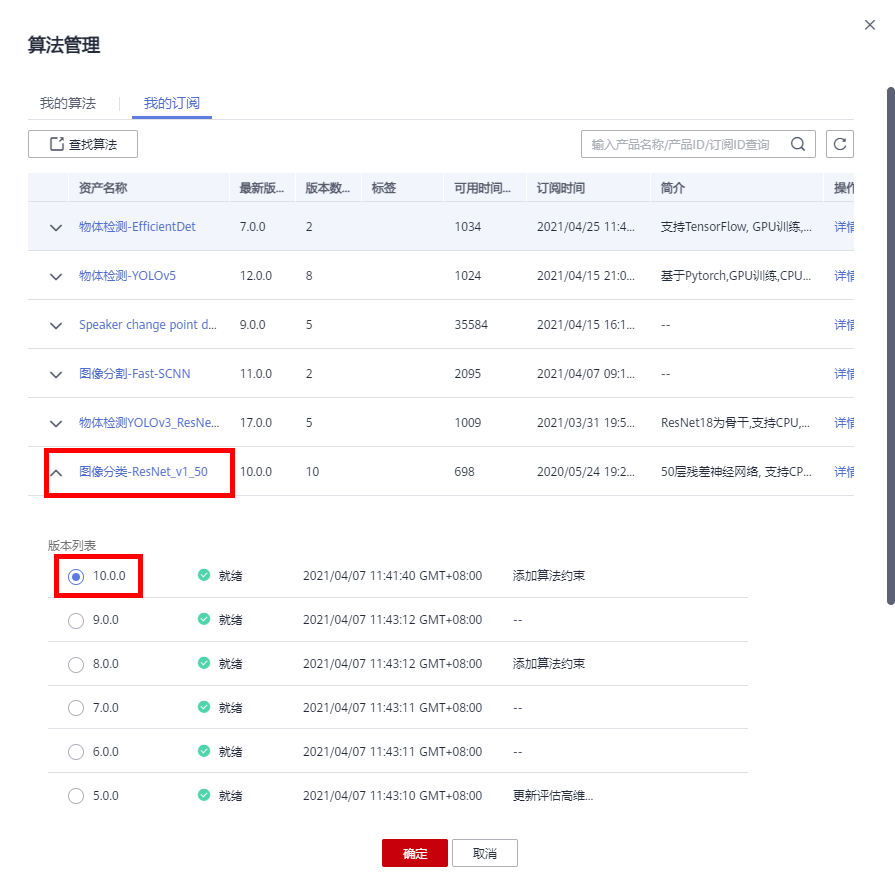
填写参数:
① “名称”和“描述”可以随意填写;
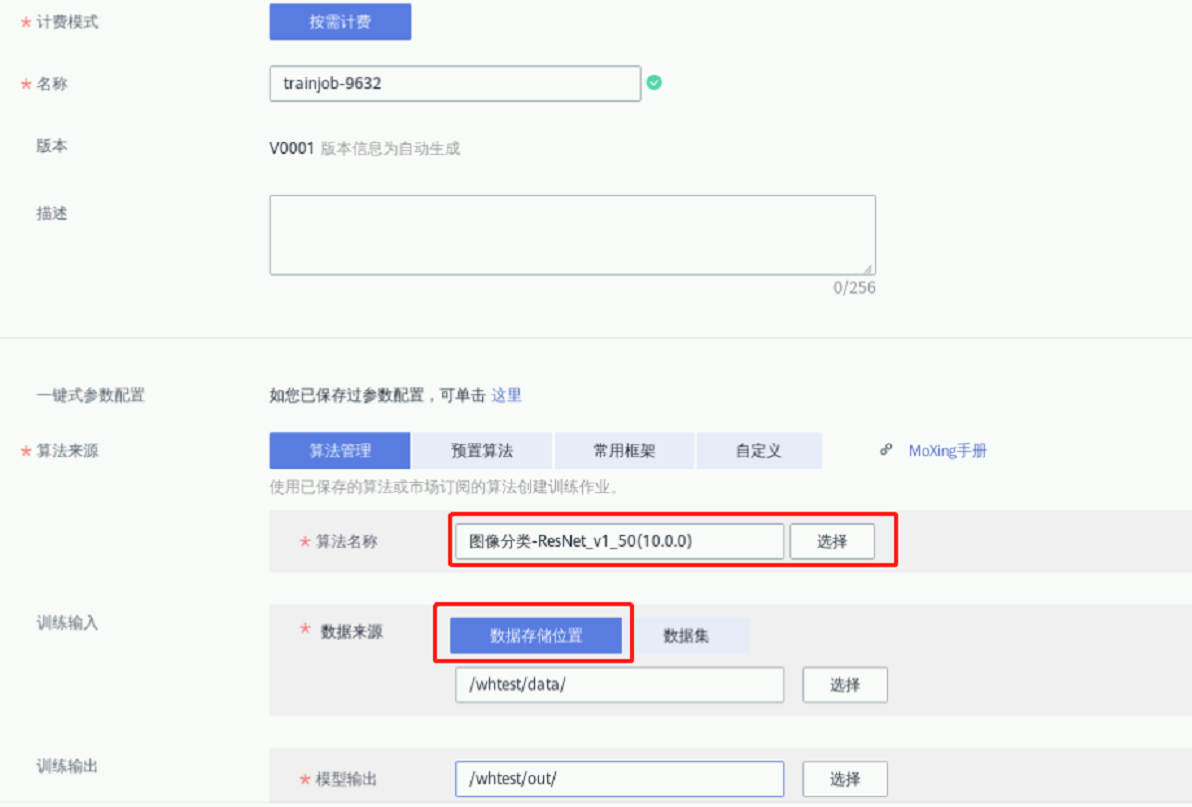
② “算法来源”中的“算法管理”,算法名称默认为之前选择的算法
③ “训练输入”->“数据来源”点击“数据存储位置”,选择1.2步骤中创建的存放数据的文件夹;
④ “训练输出”->“模型输出”点击“选择”,选择1.2创建的OBS桶,并选择新建文件夹,创建一个输出文件夹 如:out
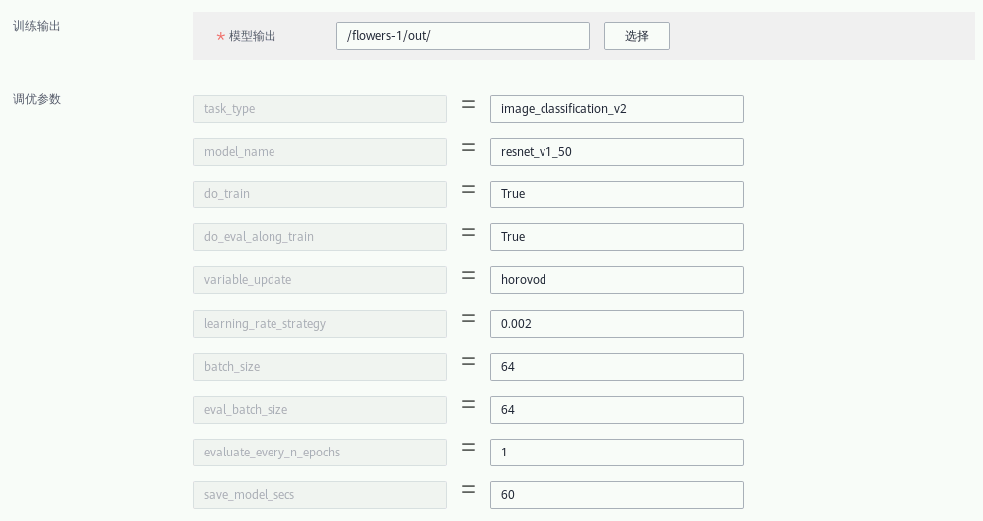
⑤ “调优参数”:默认;
⑥ 作业日志路径:默认;
⑦ 资源池:公共资源池;
⑧ 规格:GPU:1*NVIDIA-V100(32GB) | CPU:8核64GB;
⑨ 计算节点个数:1;

其他参数默认,参数确认无误后,单击“下一步”->“提交”完成训练作业创建。
返回作业列表,创建成功需要等待训练完成【约等待4分钟】(点击右侧刷新按钮可以查看训练时间),任务状态变为“运行成功”即可进行下一步操作。
当训练作业运行成功后,可以在创建训练作业选择的训练输出位置OBS(参考1.1步骤可以进入OBS查看)路径下看到新的模型文件。
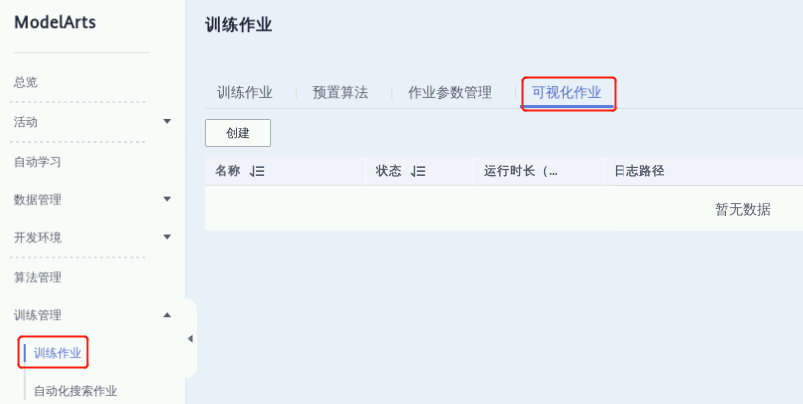
2.2.通过可视化作业查看模型训练信息
在模型训练的过程完成后,通过创建可视化作业查看一些参数的统计信息,如loss, accuracy等
操作如下:
① 在“训练作业”界面,点击“可视化作业”,再点击“创建”按钮;
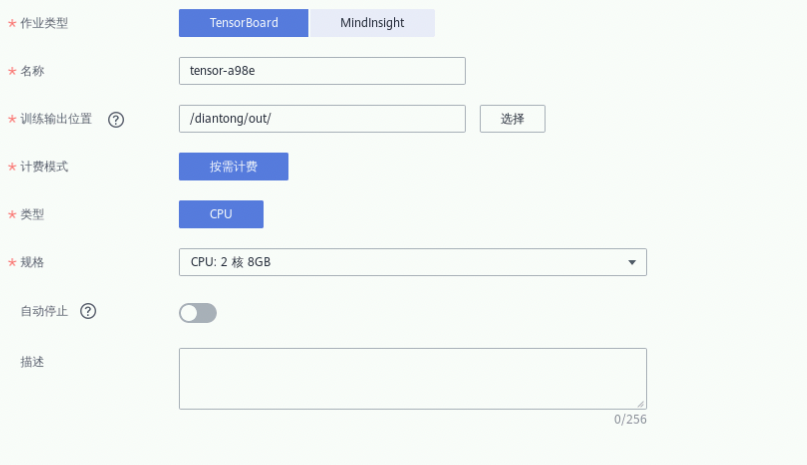
② 参数“名称”,可随意填写;
③ 规格:默认;
④ “训练输出位置”选择2.2步骤中的训练输出位置;
⑤ “自动停止”不设置(关闭);
点击“下一步”确认规格无误后点击“提交”完成此步。此步骤创建时间较长【约等待5分钟】,建议直接继续下一步实验,无需等待。
四 部署训练的模型
3.1.导入模型
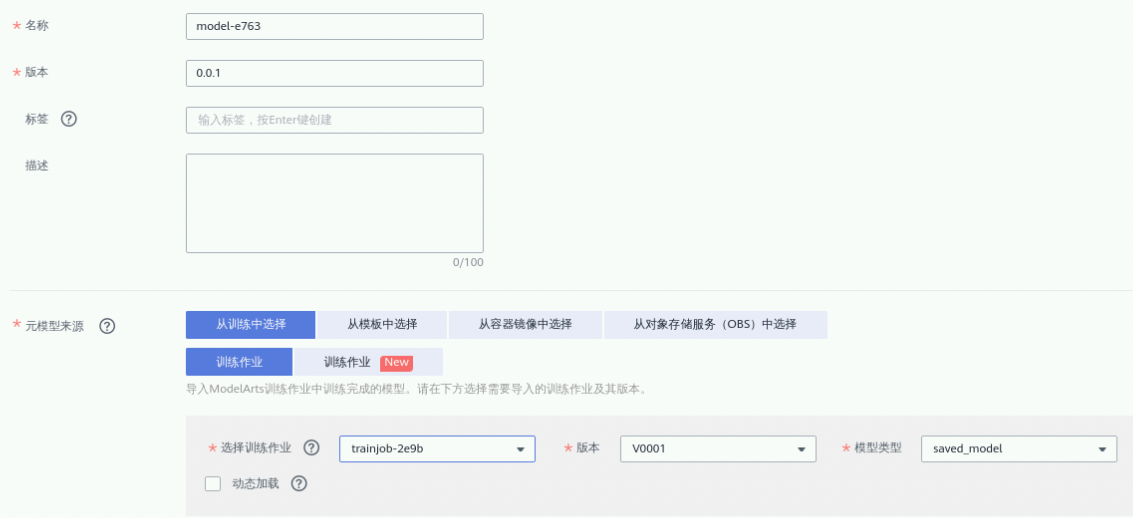
在左侧ModelArts菜单栏点击“AI应用管理”->“AI应用”,单击页面中的“创建”,参考填写请参考下图
名称:自定义
版本:默认
云模型来源:选择【从训练中选择】、【训练作业】,然后选择2.1步骤训练的模型
其他参数默认即可,参数确认无误后,单击“立即创建”,完成模型创建
当模型状态为“正常”时,就表示已经创建成功
说明:导入模型约需【3分钟,希望稍微等待下】
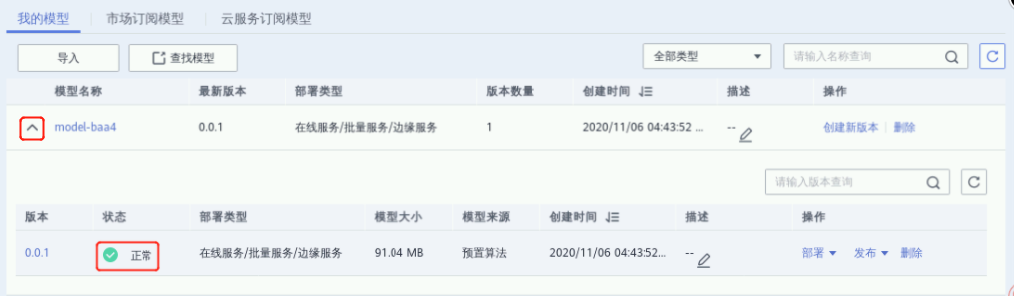
3.2.部署在线服务
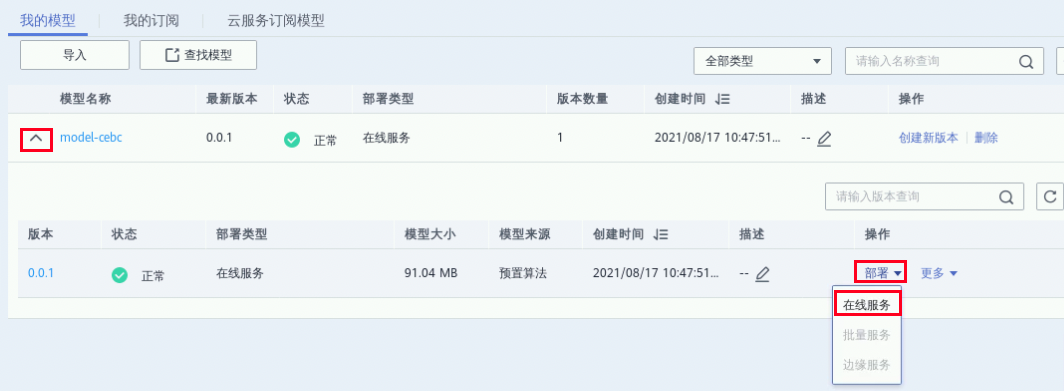
点击已创建模型名称前的下拉箭头,点击操作列中【部署】,选择部署菜单栏中的【在线服务】。或点击模型名称进入模型详情页,点击详情页右上角的【部署】,在部署菜单中选择【在线服务】;
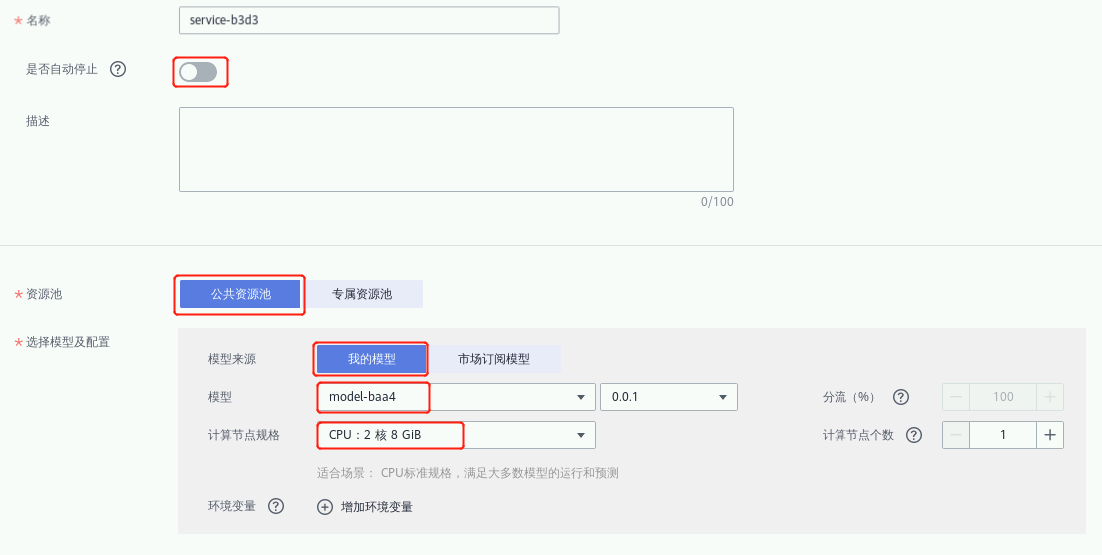
参数有这些:
① 计费模式:按需计费
② 名称:自定义
③ 是否自动停止:关闭
④ 描述:自定义
⑤ 资源池:公共资源池
⑥ 服务流量限制:关闭
⑦ 选择模型及配置:
⑧ 模型来源:我的模型
⑨ 模型:默认已选择所创建的模型名称及版本
⑩ 计算节点规格:CPU:2核8GB
其他配置默认即可,听我的没错
点击“下一步”->“提交”完成部署,我要说下:部署模型为导入的模型。部署创建完成后,返回列表需要等待部署成功【约等待2分钟】,部署服务状态显示“运行中”,即可进行下一步操作;
五 发起预测请求
最后点刚刚部署上线(已完成部署)的在线服务名称,然后进入服务详情,点击“预测”标签,你就能在这里进行在线预测,如下图这样,是不是很神奇?
操作:选择预测图片文件,点击左侧“上传”选择pic文件夹内的图片资源,点击“预测”完成操作;
说明:测试图片存放于桌面pic文件夹内。尝试更多图片预测,可点击桌面sunflower.sh脚本进行快捷搜索;
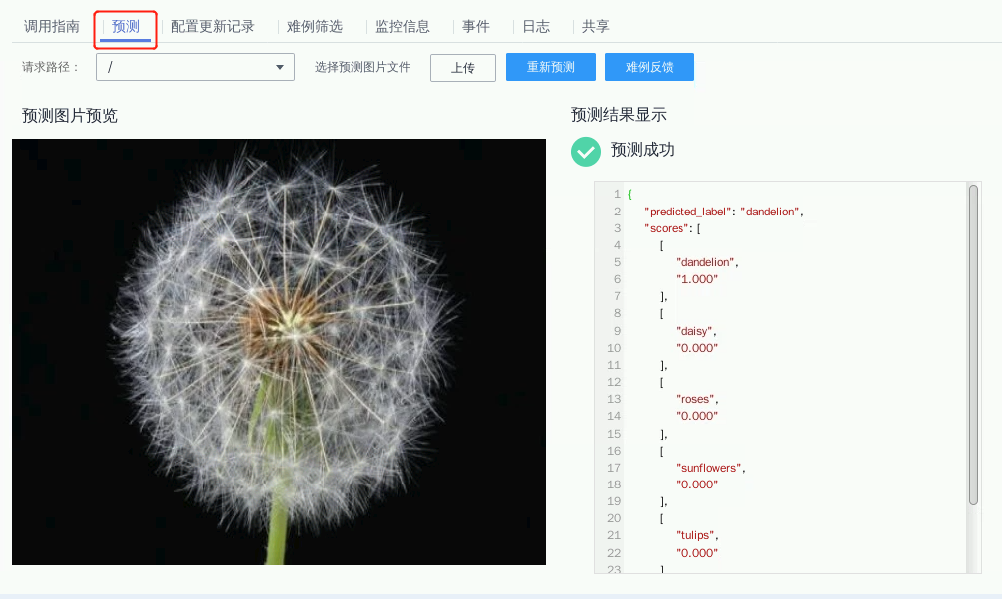
我们可以看到,返回值如下图所示,并且预测结果也显示,所选图片与五种类型花卉的匹配程度为:
dandelion:1.000(匹配度为100%)
tulip:0.000(匹配度为0%)
rose:0.000(匹配度为0%)
sunflower:0.000(匹配度为0%)
daisy:0.000(匹配度为0%)
写在最后
- 实现花卉图像分类实验操作:https://lab.huaweicloud.com/testdetail_287
- 对象存储服务平台:https://www.huaweicloud.com/product/obs.html
- 一站式AI平台ModelArts官网::https://www.huaweicloud.com/product/modelarts.html

- 点赞
- 收藏
- 关注作者
评论(0)