告别宽表,用 DQL 成就新一代 BI

BI商业智能这个概念已经提出好几十年了,这个概念本身比较宽泛,不同人也有不同的理解和定义,但落实到技术环节,特别是面向业务用户的环节,所称的BI,基本就是指的多维分析或者自助报表
不管是叫自助报表还是多维分析,也都是一回事,都是让用户自己去通过拖拽的方式查询数据或制作报表

用户想通过BI,实现查询和报表自由,也就是可以灵活地分析自己想要的数据,挖掘出更大的价值
厂商想通过BI,给用户赋能,盘活用户数据价值的同时,也能体现出BI产品本身的价值
那实际的情况如何呢,BI有没有发挥出它预期的作用呢,我们就来探究一下
BI多维分析的本质
做技术的都清楚,要查询分析数据,其实就是编写SQL语句去查询(我们假设要分析的数据都在关系数据库中,这是绝大多数BI的实际场景),那给业务人员使用的BI多维分析的技术本质,其实就是通过页面拖拽出这个SQL
对于单表的查询,并不是很难理解和实施,选出字段再配上过滤条件及排序,和用Excel差不太多,分组汇总会稍复杂些,但也不是多难懂
但是,有业务意义的查询经常涉及多表关联,比如查询存储余额10万元以上的储户中本地人的比例,看看某月回款额与发票额的对比。这些都需要多表关联,也就是要用到SQL的JOIN
业务人员很难理解SQL的JOIN,多个表及其关系是个网状形式,要指定关联字段,还会涉及自关联、递归关联还有子查询再关联的复杂情况。三五个关联表之间的数据关系连技术人员都可能会晕,就更别说业务人员了,这时候,界面再炫丽、操作再流畅都没有什么意义了
分析被禁锢在宽表内
多表的JOIN拖拽把用户难住了,BI厂商就只能绕路解决,总不能和用户说我们的分析只能基于单表进行吧(毕竟相当多有业务意义的分析都是多表的,世界是普遍关联的嘛),目前采用的变通手段就是建模,当前市场上的产品,基本都是这么做的
所谓建模,就是把表间关联运算做成逻辑视图或物理宽表,这样业务人员在查询时相当于面对的还是逻辑上的单表,这就又变的简单了,又可以拖拽了
问题完美解决?不,并没有,宽表并不是一个好的解决方案
宽表的局限性很明显,数据冗余,维护麻烦这些就不说了
单单是:分析也只能基于宽表现有的关联去做这一条,就让用户和厂商都无法忍受了
用户分析需求超出范围,或者有变化,就得技术人员修改或者重新再做一次宽表,用户不自由,啥也得厂商帮忙,今天想做的分析,可能得一周以后才能做;厂商更不乐意,每一次修改和重做,都是人工成本,可是自己产品提供的自助关联又不好用,也只能任用户摆布了
当然有的BI厂商的建模,不叫宽表,事实上他们也确实比宽表做了更多的准备和优化,但归根结底,不管是CUBE,还是立方体,还是其他名字,本质都还是一个宽表,逻辑上并没有脱离宽表的范畴,分析需求变动时,还是得技术人员去改
在一个数据系统中,BI的作用本来就有限,然后还被死死的限制在了需要技术人员介入的宽表上,所谓的自由灵活就更得打折扣了
BI厂商为什么做不好JOIN
那为什么这么多厂商都做不好多表的JOIN,提供的JOIN功能,用户根本不会用,只能被迫用宽表呢?
造成这些难题的根本原因是,SQL 本身对于 JOIN 的定义过于简单了,用来描述复杂的关联场景时,就会很难理解,容易犯晕,就像用加法来描述乘法一样
我们通过两个例子来看下
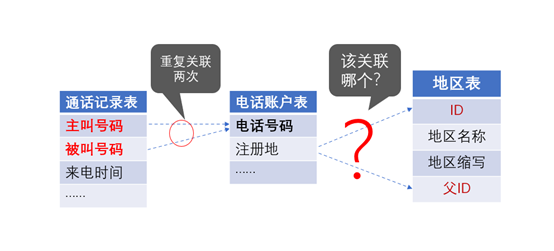
查询:北京号码打给上海号码的通话记录
涉及通话记录表和电话帐户表以及地区表的多次关联
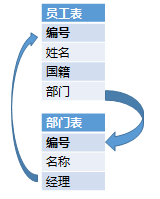
查询:中国经理的美国员工
人事系统里员工表,还有部门表。员工表中有所属部门的字段与部门表关联,部门会有经理,而经理也是个员工,部门表中的经理字段会再和员工表关联。这就发生互相关联的情况,转圈了
这俩例子是很正常,很普遍的查询,但是即使是技术人员来写这个SQL,也得费点劲儿,这是SQL本身的局限性造成的
BI 厂商们也没有在数据模型层面针对这个难题进行优化封装,只是简单的把表对业务人员做了可视,把技术人员都觉得难的问题丢给了没有技术能力的业务人员,那当然没人能用的起来了
更多的关于BI厂商做不好JOIN的分析,可以参考:
为什么 BI 软件都搞不定关联分析
重新定义JOIN的DQL
要解决这个难题,就需分析研究SQL的JOIN运算,突破SQL的局限才可以
我们发现,BI多维分析中需要的JOIN,都属于这么3+1种情况:
-
外键关联,多对1的JOIN和LEFT JOIN
-
同维表关联,1对1的LEFT JOIN或FULL JOIN
-
主子表关联,1对多的JOIN和LEFT JOIN
-
按维对齐,1对1的FULL JOIN或JOIN,LEFT JOIN较少见
第四种维度对齐,稍有特殊,但也并没有超出前三种情况的范围,所以我们说成3+1
这里说的是BI中的JOIN,并不是SQL中全部的JOIN,有些关联计算仍然需要原始的JOIN定义来描述,比如做矩阵乘法,但在BI中碰不到
我们针对这3+1种情况,重新定义JOIN运算,改造SQL语法形成另一种类似的查询语言,也就是这里所说的DQL,它是润乾开发出的新一代BI多维分析引擎,D是即Dimensional维度的意思
我们来分别看一下这几种情况下的SQL的复杂度以及DQL是怎么解决的
外键属性化
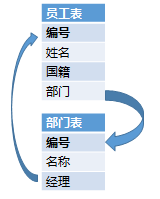
我们用前面提到的那个查询中国经理的美国员工的例子来看一下SQL要怎么写,员工表里有个部门外键字段指向部门表的主键,部门表里又有经理外键字段指回员工表,这是很常见的数据结构设计
SQL写出来是这样的:
SELECT A.*
FROM 员工表 A
JOIN 部门表 ON A.部门 = 部门表.编号
JOIN 员工表 C ON 部门表.经理 = C.编号
WHERE A.国籍 = '美国' AND C.国籍 = '中国'
员工表和部门表JOIN,再JOIN回员工表,也就是同一个表要连接两次,这就起个别名。在WHERE中写上JOIN的条件和最终我们希望的条件。整个句子要看一会才能明白
使用DQL会写成这样:
SELECT *
FROM 员工表
WHERE 国籍='美国' AND 部门.经理.国籍='中国'
这个句子中,美国员工好理解,中国经理的条件稍复杂一点,字段有了子属性,子属性又有子属性,但并不难理解,也就是部门的经理的国籍是中国
在DQL的语法体系中,外键被看成了属性,外键指向表的字段可直接用子属性的方式引用,也允许多层和递归引用
同维表等同化
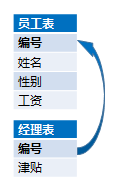
这是两个一比一的表,主键相同,在数据库设计中经常有这种情况,字段的业务分类不同,不适合都放在一个表里,太宽的表在各字段丰满度相差较大时还会造成空间冗余浪费,访问性能也下降,因此常常会分到多个主键相同的表中
现在我们要查询计算所有员工的收入
SQL中需要做JOIN:
SELECT 员工表.姓名, 员工表.工资 + 经理表.津贴
FROM 员工表
LEFT JOIN 经理表 ON 员工表.编码 = 经理表.编号
DQL则可以把这两个表看成一个表访问:
SELECT 姓名,工资+津贴
FROM 员工表
"工资+津贴”的的部分实际上来自两个表,DQL把主键同维的表等同化,视为一个宽表,访问其中任何一个均可引用其它表的字段
子表集合化
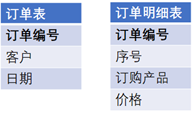
订单及订单明细是典型的主子表,前者的主键是后者的一部分
现在我们想计算每张订单的总金额
用 SQL 写出来会是这样:
SELECT T1.订单编号,T1.客户,SUM(T2.价格)
FROM 订单表 T1
JOIN 订单明细表 T2 ON T1.订单编号=T2.订单编号
GROUP BY T1.订单编号,T1.客户
要完成这个运算,不仅要用到 JOIN,还需要做一次 GROUP BY,否则选出来的记录数太多。
如果我们把子表中与主表相关的记录看成主表的一个字段,那么这个问题也可以不再使用 JOIN 以及 GROUP BY:
SELECT 订单编号,客户,订单明细表.SUM(价格)
FROM 订单表
与普通字段不同,订单明细被看成订单表的字段时,其取值将是一个集合,因为两个表是一对多的关系。所以要在这里使用聚合运算把集合值计算成单值。这种简化方式称为子表集合化
这样看待主子表关联,不仅理解书写更为简单,而且不容易出错
如果有多个子表时,SQL需要分别先做GROUP,然后在一起和主表JOIN才行,会写成子查询的形式,但是DQL则仍然很简单,SELECT后直接再加字段就可以了
按维对齐
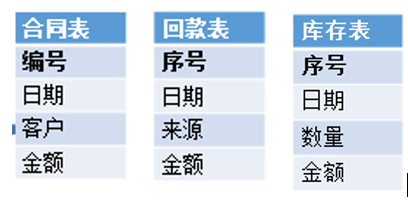
这里有三个表:合同表、回款表和库存表
我们希望按日期统计合同额、回款额和库存金额
用SQL写出来是这样的:
SELECT T1.日期,T1.金额,T2.金额
FROM (SELECT 日期, SUM(金额) 金额 FROM 合同表 GROUP BY 日期)T1
LEFT JOIN (SELECT 日期, SUM(金额) 金额 FROM 回款表 GROUP BY 日期)T2
ON T1.日期 = T2.日期
LEFT JOIN (SELECT 日期, SUM(金额) 金额 FROM 库存表 GROUP BY 日期 ) T3
ON T2.日期=T3.日期
用子查询把每个表分组汇总后再JOIN起来,如果偷懒不用子查询先JOIN后GROUP,那结果是错误的,统计值会变多。这个问题必须使用子查询
这里涉及的三个子查询都要连接上,SQL的JOIN关系要写成若干个两表关联,在表比较多时,增删关联表有可能把某个表漏掉而没有连接条件,出现完全叉乘
用DQL写出来是这样的:
SELECT 合同表.SUM(金额),回款表.SUM(金额),库存表.SUM(金额) ON 日期
FROM 合同表 BY 日期
LEFT JOIN 回款表 BY 日期
LEFT JOIN 库存表 BY 日期
在DQL中,只要把这几个表分别按日期对齐分别汇总就行了,而不必关心这些表之间的关系,在增删表时也不容易发生遗漏
如果按维对齐再与外键搅到一起,情况就会更复杂:
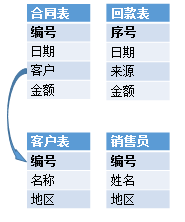
我们希望按地区统计销售员人数和合同额
用SQL写出来是这样:
SELECT T1.地区,T1.数量,T2.金额
FROM (SELECT 地区,COUNT(1) 数量 FROM 销售员 GROUP BY 地区)T1
LEFT JOIN (SELECT 客户表.地区 地区,SUM(合同.金额) 金额
FROM 客户表,合同表
WHERE 客户表.编号=合同表.客户
GROUP BY 客户表.地区 ) T2
ON T1.地区 = T2.地区
这个子查询很复杂
而在DQL中,可以和外键属性化结合,这样查询会写成:
SELECT 销售员.count(1),合同表.sum(金额) ON 地区
FROM 销售员 BY 地区
JOIN 合同表 BY 客户表.地区
这里又出现了子属性,但整个句子仍然很简单,DQL允许每个表独立设定统计维度,无须关心表间关联,还可以与属性化的外键配合使用
对这些JOIN更深入的探讨,可以参考连接运算 1-SQL 中的 JOIN
解决关联
前面讲的这几个JOIN的例子,都是在实际应用中常见的,具有业务意义的查询需求,
这些例子都是可以用来检验BI产品的“自助”灵活程度的,能否不需要技术人员更新模型就由完成这些查询。结果会发现,业内的大部分BI产品,无论界面多炫丽、操作多流畅,都经不起这个检验
原因就在于,低层模型上,并没有解决好JOIN问题
有了DQL之后,我们就能解决BI中的JOIN问题了
从前面的DQL例子中可以明显的看出,前3个查询用SQL的JOIN都没有了,多表变成单表了,只是字段变成有子属性了,而这并不难理解,业务人员可以轻车熟路地搞定。最后一个按维对齐的情况虽然还有JOIN,但也很简单,用户无需关心这些表之间的关联关系,只要向统一的目标维度对齐就行了
重新定义JOIN后,就彻底把不易于理解和拼写的JOIN变的简单易懂了,再做一个拖拽的前端界面,能让业务人员做JOIN的BI就做成了
有人可能会问,多表变一表,那不还是宽表吗?那不也还得技术人员做吗?
DQL和宽表大有不同!!!
DQL当然也需要技术人员提前定义好元数据,但是用到技术人员的地方也仅此一次
元数据中预先定义好了各种关联关系,但并没有做实际关联,当用户在前端拖拽分析的时候,才实时生成关联查询,不需要像宽表一样预先关联,占用数据库资源
它的关联关系只要数据表本身结构不变,就不用修改元数据,不需要像宽表一样总得重新生成,相当于一次定义可以适应无数次不同的分析需求,它拥有宽表的优势但从根本上解决了宽表的各种弊端
这就是所谓的非按需建模,建模只要考虑数据结构本身,而与用户需求无关。宽表(无论逻辑还是物理的)则是按需建模,需求一变就要再建模
用DQL语法还能降低出错率
很多程序员习惯用 WHERE 来写 JOIN 运算的过滤条件,表少的时候没有问题,表多的时候漏写了 JOIN 条件意味着将发生多对多的完全叉乘,而这个 SQL 却还可以正常执行,一方面计算结果会出错,另一方面,如果漏写条件的表很大,笛卡尔积的规模将是平方级的,这极有可能把数据库直接“跑死”!
采用DQL的 JOIN 语法,就不可能发生漏写 JOIN 条件的情况了。因为对 JOIN 的理解不再是以笛卡尔积为基础,而且设计这些语法时已经假定了多对多关联没有业务意义,这个规则下写不出完全叉乘的运算
对于多个子表分组后与主表对齐的运算,在 SQL 中要写成多个子查询的形式。但如果只有一个子表时,可以先 JOIN 再 GROUP,这时不需要子查询。有些程序员没有仔细分析,会把这种写法推广到多个子表的情况,也先 JOIN 再 GROUP,可以避免使用子查询,但计算结果是错误的
使用维度对齐的写法就不容易发生这种错误了,无论多少个子表,都不需要子查询,一个子表和多个子表的写法完全相同
DQL还能让数据结构显得更为清晰
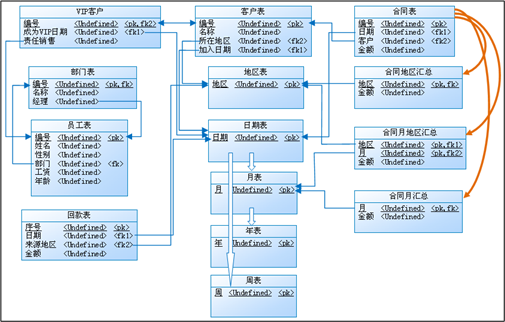
这是我们平时看到的E-R图,它是个网状结构的,表与表之间可能都有关联,表多了就会显得很零乱,增删表的时间很容易遗漏或重复表间的关联。
而在DQL体系下看到的表间关联是总线式的:
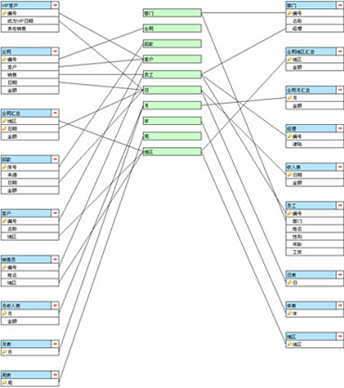
表与表之间没有直接的关联,都只处在中间地位的维度关联,增删表的时候不会影响到其它表,数据结构耦合度低
不过,要说明的是,无论是E-R图还是后面的总线图,其中连线的数量都是相当的,这是数据关系本身决定的,不会因为改变了看待方法而变少,只是总线式看着更清晰些
DQL让BI告别了宽表,实现了更大程度的自由自助;也拓宽了BI分析的边界,让分析可以应对更多的数据场景,让BI成了更自由更好用的新一代的BI
告别宽表的新一代BI
DQL从低层模型上解决了JOIN的问题后,前端的界面要怎么来做其实也就变的简单了,不需要再费心去想怎么样设计才能让用户更好的理解数据了,因为不管怎么做,都能轻松理解拖拽了
下面是润乾基于DQL实现的一套界面,我们还是按前面的例子,挨个看看每个JOIN是怎么呈现给业务人员,怎么拖拽的
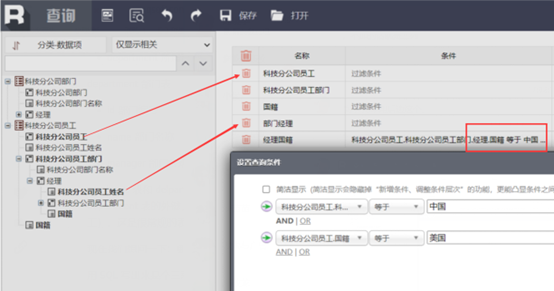
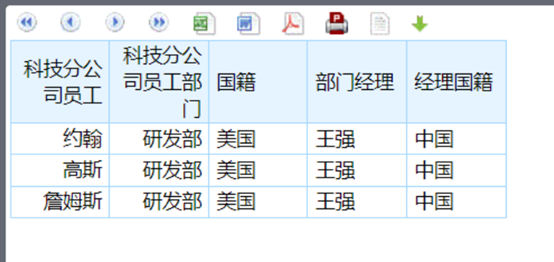
外键关联---中国经理的美国员工
经过DQL解析后,数据就都变成业务人员可以理解的清晰的树状结构了
原先的两个表变到一个表里了,业务人员已经完全不用去管后台是几个表,怎么关联了,直接拖拽员工姓名,再拖拽部门经理姓名,然后再设置一下两个的国籍,就可以了
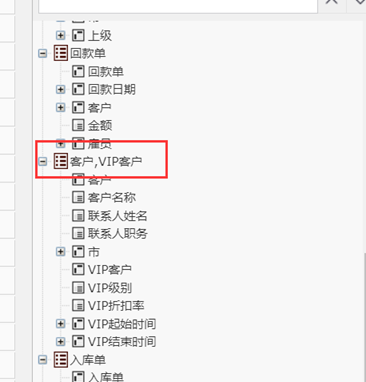
同维表关联
同样的,多表变一表,主键相同的表,像员工表,经理表;客户表,VIP客户表,直接同化到一个表中了
主子表关联---每个订单的总金额
主子表,被视为一个表了,拖出订单,再选择求和方式拖出明细金额就可以了,不操心怎么关联的
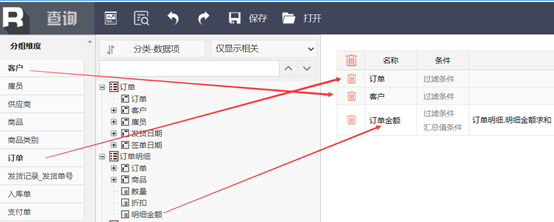
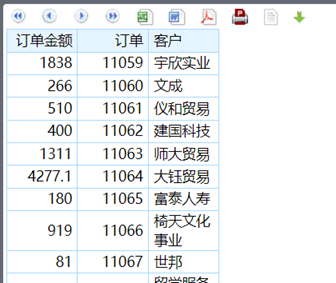
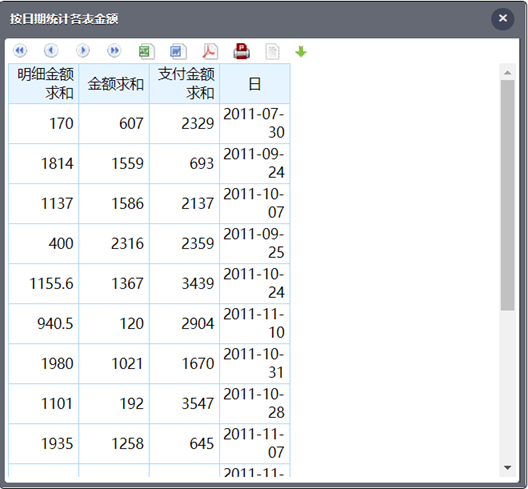
按维对齐汇总---按日期统计3个不同表的汇总金额
这个虽然还是三个表,但业务人员也不用管各个表之间有什么关联关系,找到对应的金额指标,选择求和,然后直接拖拽就可以,再选一个“日”当做共同的统计条件,那就是按日期汇总了
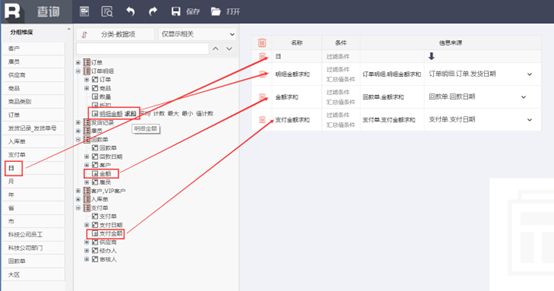
而且查询控件还会自动把和已选择数据不匹配的数据项过滤隐藏掉,有汇总的还会自动建立汇总项与统计维度之间的匹配关系,使用起来就更加智能了,不仅避免了出错,保证了拖拽分析的业务正确性,也使得查询分析更加流畅了
润乾基于DQL引擎的全新一代BI,突破宽表的限制,真正做到自由灵活分析,让业务人员能能轻松应对各种数据JOIN场景的BI
DQL引擎会把DQL语句翻译成SQL执行,所以可以基于任何关系数据库工作。这款DQL引擎目前是免费提供的哦,前端界面部分还开源,你可以轻松把这些强大的功能集成到自己的BI应用中
总结
BI的定位是自由的分析,它可以隐忍一时的因为技术限制而带来的不自由,但它绝不会永远这样逆来顺受,技术是需要革新的,也会有人去革新,当新的技术突破瓶颈,捅破限制它的天花板以后,新一代的BI就到来了
润乾报表资料
欢迎对润乾报表有兴趣的加小助手(VX号:RUNQIAN_RAQSOFT),进技术交流群

- 点赞
- 收藏
- 关注作者
评论(0)