金鱼哥RHCA回忆录:DO447使用过滤器和插件转换器--使用过滤器处理变量

🎹 个人简介:大家好,我是 金鱼哥,CSDN运维领域新星创作者,华为云·云享专家,阿里云社区·专家博主
📚个人资质:CCNA、HCNP、CSNA(网络分析师),软考初级、中级网络工程师、RHCSA、RHCE、RHCA、RHCI、ITIL😜
💬格言:努力不一定成功,但要想成功就必须努力🔥
官网:
https://docs.ansible.com/ansible/latest/user_guide/playbooks_filters.html
https://docs.ansible.com/ansible/latest/user_guide/playbooks_templating.html
📜1.1 ANSIBLE过滤器
Ansible使用Jinja2表达式将变量值应用于剧本和模板。例如,下面的Jinja2表达式将双花括号括起来的变量名替换为其值:
{{ variable }}
Jinja2表达式也支持过滤器。过滤器用于修改或处理剧本或模板中放置的变量的值。一些过滤器是由Jinja2语言提供的,而另一些则是由Red Hat Ansible引擎作为插件提供的。也可以创建自定义过滤器,尽管这超出了本课程的范围。过滤器在准备数据以便在剧本或模板中使用时非常有用。
要理解过滤器,您必须首先更多地了解Ansible是如何处理变量值的。
📜1.2 变量类型
Ansible将运行时数据存储在变量中。YAML结构或值的内容定义了确切的数据类型。一些值类型包括
-
字符串(字符序列)
-
数字(数值)
-
布尔值(真/假)
-
日期(ISO-8601日历日期)
-
Null(设置变量为未定义的变量)
-
列表或数组(值的排序集合)
-
字典(键值对的集合)
📑字符串
字符串是一个字符序列,是Ansible中的默认数据类型。字符串不需要用引号或双引号来包装。Ansible从未加引号的字符串中删除后面的空格。
my_string: Those are the contents of the string
YAML格式允许您定义多行字符串。使用pipe操作符( | )来保留换行符,或者使用大于操作符(>)来抑制换行符。
string_with_breaks: |
This string
has several
line breaks
string_without_breaks: >
This string will not
contain any line breaks.
Separated lines are joined
by a space character.
📑数字
当变量内容符合数字时,Ansible(准确地说,是YAML)解析字符串并生成一个数字值,可以是整数,也可以是浮点数。
整数包含十进制字符,前面可以有+或-符号:
answer: 42
如果小数点(.)包含在一个整型值中,它将被解析为浮点数。
float_answer: 42.0
科学记数法也可以用来写大整数或浮点数
scientific_answer: 0.42e+2
16进制数以0x开头,后面只有16进制字符。例如,16进制数2A(十进制42)。
hex_answer: 0x2A
如果将数字放在引号中,它将被视为字符串
string_not_number: "20"
📑布尔值
布尔值包含yes、no、y、n、on、off、true或false字符串。值不区分大小写,但是为了保持一致性,Jinja2文档建议您使用小写。
📑日期
如果字符串符合Iso-8601标准,Ansible将字符串转换为日期类型的值。
my_date_time: 2019-05-30T21:15:32.42+02:00
my_simple_date: 2019-05-30
📑Null
特殊的空值将变量声明为未定义。空字符串,或波浪线(~)字符,将空值分配给变量。
my_undefined: null
📑列表或数组
列表,也称为数组,是值的排序集合。列表是数据收集和循环的基本结构。
用逗号分隔的值序列编写列表,用方括号包装,或者每行一个元素,以破折号(-)作为前缀。下面的例子是等价的:
my_list: ['Douglas', 'Marvin', 'Arthur']
my_list:
- Douglas
- Marvin
- Arthur
就像大多数编程语言中的数组一样,可以使用从0开始的索引号来访问列表中的特定元素:
- name: Confirm that the second list element is "Marvin"
assert:
that:
- my_list[1] == 'Marvin'
📑字典
字典(在其他上下文中也称为映射或散列)是一种将字符串键与值链接起来以便直接访问的结构。像列表,字典可以写成一行,也可以写成多行,用冒号(:)表示:
my_dict: { Douglas: Human, Marvin: Robot, Arthur: Human }
my_dict:
Douglas: Human
Marvin: Robot
Arthur: Human
通过键来访问字典中的项,在字典名后面立即提供键,并用方括号括起来:
assert:
that:
- my_dict['Marvin'] == 'Robot'
📜1.3 用过滤器处理数据
过滤器允许您处理变量的值,以便提取信息、转换它或使用它来计算新值。要应用过滤器,在变量名后面加上管道( | )
字符和要应用的过滤器的名称。有些过滤器可能需要括号中的可选参数或选项。可以将多个过滤器链接到一个表达式中。
例如,下面的表达式对变量myname的值进行过滤,通过使用标准的Jinja2过滤器确保值的第一个字母大写:
{{ myname | capitalize }}
这个表达式还可以用来将变量转换为不同的类型。下面的示例表达式确保了结果是一个字符串,而不是整数或浮点数:
{{ mynumber | string }}
下一个示例更复杂,显示了一个完整的任务。assert模块会测试表达式是否为真和假。测试开始处的Jinja2表达式接受列表[1,4,2,2 1],并使用unique(唯一)过滤器删除重复的元素,然后使用sort(排序)过滤器对它们进行排序。注意,这个示例使用过滤器来操作硬编码的数据,而不是变量的值。
- name: Test to see if the assertion is true, fail if not
assert:
that:
- "{{ [ 1, 4, 2, 2 ] | unique | sort }} is eq( [ 1, 2, 4 ] )"
使用eq Jinja2测试比较sort过滤器的输出是否与预期列表相等。由于结果和期望值相等,assert模块就成功了。
重要:过滤器不会改变存储在变量中的值。Jinja2表达式处理该值并使用结果,而不改变变量本身。
📜1.4 所选过滤器概述
有大量可用的过滤器,既可以作为Jinja2的标准过滤器,也可以作为Red Hat Ansible Engine提供的附加过滤器。本节提供了一些有用过滤器的概述,但不是一个详尽的列表。
参考资料部分中的链接包含了Ansible和Jinja2中正式可用的过滤器。特别是,http://jinja.pocoo.org/docs/2.10/templates/#builtinfilters上记录的Jinja2过滤器提供了大量有用的实用函数。(https://jinja.palletsprojects.com/en/2.10.x/templates/#builtinfilters)(http://docs.jinkan.org/docs/jinja2/templates.html#id2)
📑检查是否定义了变量
前两个特定于ansible的过滤器作用于输入是否被定义。这些过滤器在确保变量有合理的值方面很有用。
📑mandatory
如果变量没有定义值,则会失败并中止Ansible剧本。
{{ my_value | mandatory }}
📑default
如果变量没有定义值,那么这个过滤器将把它设置为括号中指定的值。如果括号中的第二个参数是True,那么如果变量的初始值是空字符串或布尔值False,过滤器也会将该变量设置为默认值。
{{ my_value | default(my_default, True) }}
default过滤器还可以接受omit(省略)的特殊值,如果这个值最初没有值,那么它将保持未定义。如果变量已经有一个值,omit不会改变值。
下面的任务是确保jonfoo用户存在的一个示例的default(omit)过滤器。如果已经定义了变量supplementary_groups[‘jonfoo’],那么任务将确保用户是这些组的成员。如果它还没有定义,那么user模块的groups参数将不会在此任务中设置。
- name: Ensure user jonfoo exists.
user:
name: jonfoo
groups: "{{ supplementary_groups['jonfoo'] | default(omit) }}"
📑执行数学计算
Jinja2提供了许多可以对数字进行操作的数学过滤器。你也可以对数字进行一些基本的数学计算:
算术运算
+ :把两个对象加到一起。通常对象是数字。 {{ 1 + 1 }} 等于 2 。
-:用第一个数减去第二个数。 {{ 3 - 2 }} 等于 1 。
/ :对两个数做除法。返回值会是一个浮点数。 {{ 1 / 2 }} 等于 {{ 0.5 }} 。
//* :对两个数做除法,返回整数商。 {{ 20 // 7 }} 等于 2 。
% :计算整数除法的余数。 {{ 11 % 7 }} 等于 4 。
* :用右边的数乘左边的操作数。 {{ 2 * 2 }} 会返回 4 。也可以用于重 复一个字符串多次。 {{ ‘=’ * 80 }} 会打印 80 个等号的横条。
**:取左操作数的右操作数次幂。 {{ 2**3 }} 会返回 8 。
在某些情况下,您可能首先需要使用int过滤器将值转换为整数。或者用浮动过滤器来浮动。例如,下面的Jinja2表达式将1添加到当前小时数,该小时数作为事实收集并存储为字符串,而不是整数:
{{ ( ansible_facts['date_time']['hour'] | int ) + 1 }}
还有一些过滤器可以对数字执行数学操作:log、pow、root、abs和round都是示例。
{{ 1764 | root }}
📑操作列表
您可以使用许多过滤器来分析和操作列表。
如果列表由数字组成,您可以使用max、min或sum来查找所有列表项的最大数字、最小数字和总和。
{{ [2, 4, 6, 8, 10, 12] | sum }}
提取列表元素
可以获得关于列表内容的信息,比如列表的第一个或最后一个元素,或者列表的长度:
- name: All three of these assertions are true
assert:
that:
- "{{ [ 2, 4, 6, 8, 10, 12 ] | length }} is eq( 6 )"
- "{{ [ 2, 4, 6, 8, 10, 12 ] | first }} is eq( 2 )"
- "{{ [ 2, 4, 6, 8, 10, 12 ] | last }} is eq( 12 )"
random(随机)过滤器从列表中返回一个随机元素:
{{ ['Douglas', 'Marvin', 'Arthur'] | random }}
修改列表元素的顺序
列表可以通过几种方式重新排序。sort排序过滤器按照元素的自然顺序对列表进行排序。reverse反向过滤器返回一个顺序与原始顺序相反的列表。shuffle过滤器返回一个具有相同元素的列表,但顺序是随机的。
- name: reversing and sorting lists
assert:
that:
- "{{ [ 2, 4, 6, 8, 10 ] | reverse | list }} is eq( [ 10, 8, 6, 4, 2] )"
- "{{ [ 4, 8, 10, 6, 2 ] | sort | list }} is eq( [ 2, 4, 6, 8, 10 ] )"
合并列表
有时将几个列表合并为一个列表可以简化迭代。flatten过滤器递归地接受输入列表值中的任何内部列表,并将内部值添加到外部列表中。
- name: Flatten turns nested lists on the left to list on the right
assert:
that:
- "{{ [ 2, [4, [6, 8]], 10 ] | flatten }} is eq( [ 2, 4, 6, 8, 10] )"
使用flatten合并来自父列表的列表值。
将列表作为集合进行操作
使用unique唯一过滤器确保列表中没有重复的元素。如果您正在操作所收集的事实列表(例如可能有重复条目的用户名或主机名),这可能会很有用。

如果两个列表没有重复的元素,那么你可以对它们使用集合理论操作。
-
union联合过滤器返回一个集合,其中包含来自两个输入集合的元素。
-
intersect过滤器返回一个集合,该集合具有两个集合共有的元素。
-
difference过滤器返回一个集合,其中包含第一个集合中不存在于第二个集合中的元素。

使用集合操作时,使用symmetric_difference过滤器获取要寻址的项。
📑操纵字典
不像列表,字典是没有任何顺序的。它们只是键值对的集合。但是您可以使用过滤器来构造字典,并且您可以将它们转换为列表,或者将列表转换为字典。
加入字典
两个字典可以通过combine组合过滤器联接起来。第二个字典中的条目比第一个字典中的条目具有更高的优先级,如下面的任务所示:

重塑字典
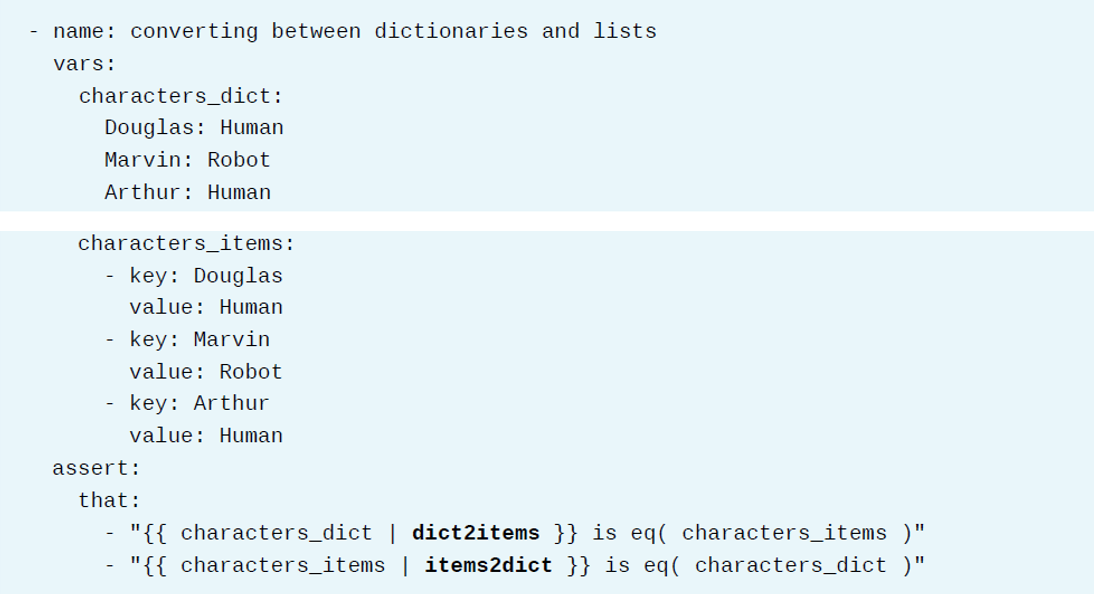
使用dict2items过滤器可以将一个字典重新塑造成一个条目列表,使用items2dict过滤器也可以将一个条目列表重新塑造成一个字典:
📑对字符串进行哈希、编码和操作
有许多过滤器可用来操作值的文本。您可以使用各种校验和、创建密码散列,并将文本转换为Base64编码,许多应用程序都在使用这种编码。
哈希字符串和密码
hash哈希过滤器使用提供的哈希算法返回输入字符串的哈希值:

使用password_hash过滤器来生成密码散列

编码的字符串
二进制数据可以通过b64encode过滤器转换成base64,再通过b64decode过滤器转换回二进制格式:

在将字符串发送到底层shell之前,为了避免解析或代码注入问题,最好使用quote过滤器来清理字符串:

格式化文本
使用lower、upper或capitalize过滤器来强制输入字符串的大小写:

替换文本
当你需要替换输入字符串中出现的所有子字符串时,replace过滤器很有用:

更复杂的搜索和替换可以通过使用正则表达式和regex_search和regex_replace过滤器来实现。

📑处理JSON数据
Ansible使用的许多数据结构都是JSON格式的。JSON与YAML符号密切相关,Ansible数据结构可以作为JSON处理。同样,Ansible剧本可能与之交互的许多api使用或提供JSON格式的信息。由于这种格式被广泛使用,因此JSON过滤器特别有用。
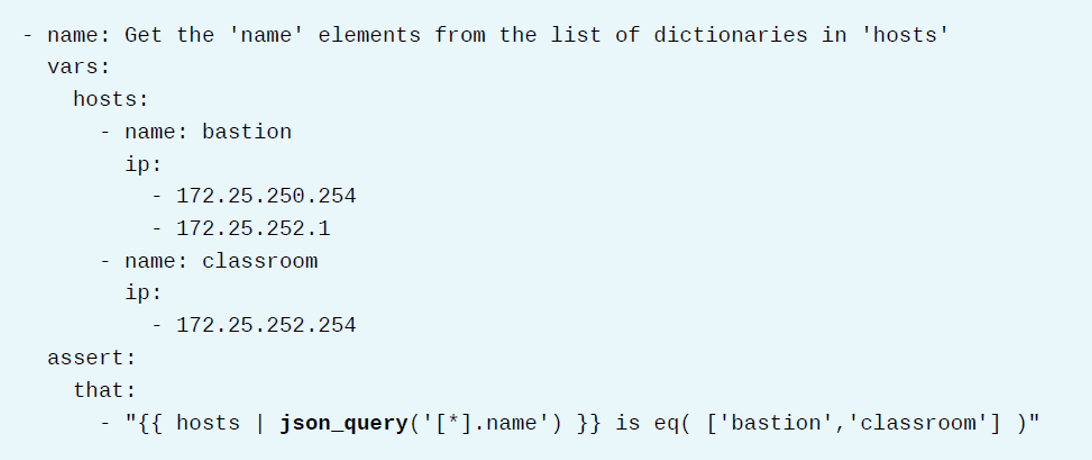
JSON查询
使用json_query过滤器从Ansible数据结构中提取信息。
📑解析和编码数据结构
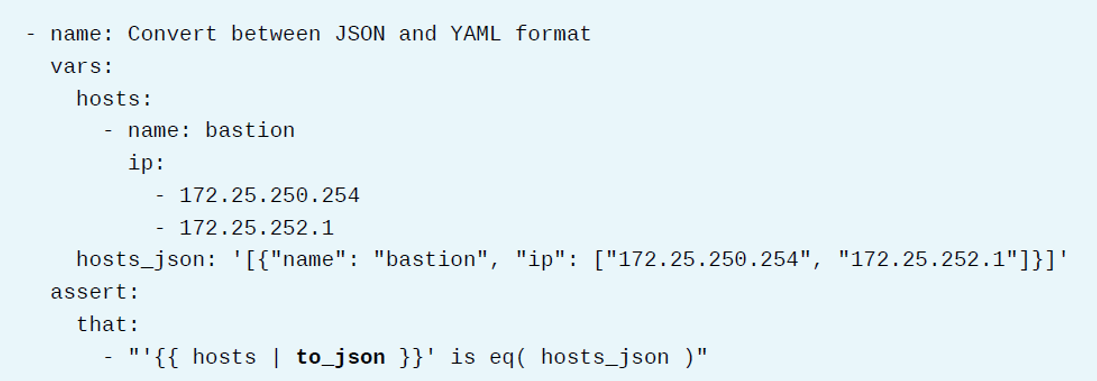
在文本和数据结构之间进行转换对于调试和通信是很有用的。数据结构通过to_json和to_yaml过滤器序列化为JSON或YAML格式。使用to_nice_json和to_nice_yaml过滤器来获得格式化的人类可读输出。
在接下来的小节和章节中,将介绍其他适用于特定场景的过滤器。查看官方的Ansible和Jinja2文档,以发现更多有用的过滤器来满足您的需求。
📜1.5 课本练习
[student@workstation ~]$ lab data-filters start
📑拉取实验代码
[student@workstation ~]$ cd /home/student/git-repos
[student@workstation git-repos]$ git clone http://git.lab.example.com:8081/git/data-filters.git
[student@workstation git-repos]$ cd data-filters
📑执行部署负载均衡器
因为还没有部署web服务器,所以对服务器的请求会导致一个503 HTTP状态码。
[student@workstation data-filters]$ ansible-playbook deploy_haproxy.yml
…………
[student@workstation data-filters]$ curl servera
<html><body><h1>503 Service Unavailable</h1>
No server is available to handle this request.
</body></html>
📑查看apache角色的任务列表和变量
[student@workstation data-filters]$ cat roles/apache/tasks/main.yml
---
# tasks file for apache
- name: Calculate the package list
set_fact:
# TODO: Combine the apache_base_packages and
# apache_optional_packages variables into one list.
apache_package_list: "{{ apache_base_packages }}"
- name: Ensure httpd packages are installed
yum:
name: "{{ apache_package_list }}"
state: present
# TODO: omit the 'enablerepo' directive
# below if the apache_enablerepos_list is empty;
# otherwise use the list as the value for the
# 'enablerepo' directive.
#enablerepo: "{{ apache_enablerepos_list }}"
apache_package_list应该是安装httpd服务的基础包和可选包的组合列表。您可以在后面的步骤中编辑并更正这个变量的定义。
角色的apache_base_packages变量被定义为包含一个包httpd的列表。为了防止主组变量覆盖这个值,变量在vars/main.yml文件定义:
[student@workstation data-filters]$ cat roles/apache/vars/main.yml
# Below variable contains the minimal
# required packages for apache.
apache_base_packages:
- httpd
apache_optional_packages变量在角色的defaults/main中定义为一个空列表:
[student@workstation data-filters]$ cat roles/apache/vars/main.yml
# The 'apache_additional_packages' variable
# allows you to specify additional
# optional packages that must be present on
# the web server.
#
# As an example, to enable a web server
# to clone a source code repository, and execute a
# PHP application that connects to a MySQL database:
#
# apache_optional_packages:
# - php
# - git
# - php-mysqlnd
#
# By default, no optional packages are installed.
apache_optional_packages: []
apache_enabledrepos_list变量包含YUM存储库id的列表。此列表中的任何存储库ID都临时支持安装任何包。默认值是一个空列表,就像角色/apache/defaults/main.yml中定义的那样:
# Use the 'apache_enablerepos_list'
# variable to enable additional yum
# repositories for package installation.
#
# By default, no additional
# repositories are enabled.
apache_enablerepos_list: []
📑纠正在apache角色的第一个任务中定义apache_package_list变量的jinj2表达式。
删除TODO注释部分并保存角色的任务文件
为web_servers主机组定义apache_optional_packages变量,以包含值的列表:git、php和php-mysqlnd。
在apache角色定义apache_package_list变量的第一个任务中编辑jinj2表达式。添加union联合过滤器,从apache_base_packages和apache_optional_packaqes列表创建一个列表。
[student@workstation data-filters]$ vim roles/apache/tasks/main.yml
- name: Calculate the package list
set_fact:
# TODO: Combine the apache_base_packages and
# apache_optional_packages variables into one list.
apache_package_list: "{{ apache_base_packages | union(apache_optional_packages) }}"
编写主机组变量
[student@workstation data-filters]$ vim group_vars/web_servers/apache.yml
apache_optional_packages:
- git
- php
- php-mysqlnd
📑使用default过滤器
从apache角色的第二个任务中的enablerepo指令中删除注释。将指令的jinj2表达式修改为使用默认过滤器来省略该指令,如果该变量的计算结果是布尔值False。删除第二个任务的TODO注释部分,并保存任务文件。第二个任务的内容如下:
(如果apache的enablerepos列表为空,则省略下面的’enablerepo’指令;否则使用列表作为’enablerepo’指令的值)
[student@workstation data-filters]$ vim roles/apache/tasks/main.yml
- name: Ensure httpd packages are installed
yum:
name: "{{ apache_package_list }}"
state: present
# TODO: omit the 'enablerepo' directive
# below if the apache_enablerepos_list is empty;
# otherwise use the list as the value for the
# 'enablerepo' directive.
enablerepo: "{{ apache_enablerepos_list | default(omit, true) }}"
📑执行剧本
[student@workstation data-filters]$ ansible-playbook deploy_apache.yml -v
TASK [apache : Calculate the package list] ********************************
ok: [webserver_01] => {"ansible_facts": {"apache_package_list": ["httpd", "git", "php", "php-mysqlnd"]}, "changed": false}
ok: [webserver_02] => {"ansible_facts": {"apache_package_list": ["httpd", "git", "php", "php-mysqlnd"]}, "changed": false}
📑查看webapp角色的任务列表和变量定义
webapp角色确保在每个主机上存在正确的web应用程序内容。当正确实现时,该角色将从根web目录中删除不属于web应用程序的任何内容。
编辑webapp角色中有TODO注释的三个任务。使用过滤器来实现每个注释中指示的功能
[student@workstation data-filters]$ vim roles/webapp/tasks/main.yml
替换中webapp_deployed_files变量的空列表,webapp角色的第三个任务是jinj2表达式。从webapp_find_files[‘files’]变量开始,应用map映射过滤器,然后是list列表过滤器。为映射过滤器提供attribute='path’参数,以便从列表中的每个条目检索路径属性。
- name: Compute the webapp file list
set_fact:
# TODO: Use the map filter to extract
# the 'path' attribute of each entry
# in the 'webapp_find_files'
# variable 'files' list.
webapp_deployed_files: "{{ webapp_find_files['files'] | map(attribute='path') | list }}"
替换webapp_rel_deployed_files变量的空列表在webapp角色的第四个任务中使用jinj2表达式。从webapp_deployed_files变量开始,应用map映射过滤器,然后是list列表过滤器。
map函数的第一个参数是’relpath’字符串,它对webapp_deployed_files列表中的每一项执行relpath函数。map函数的第二个参数是webapp_content root_dir变量。这个变量作为参数传递给relpath函数。
- name: Compute the relative webapp file list
set_fact:
# TODO: Use the 'map' filter, along with
# the 'relpath' filter, to create the
# 'webapp_rel_deployed_files' variable
# from the 'webapp_deployed_files' variable.
#
# Files in the 'webapp_rel_deployed_files'
# variable should have a path relative to
# the 'webapp_content_root_dir' variable.
webapp_rel_deployed_files: "{{ webapp_deployed_files | map('relpath', webapp_content_root_dir) | list }}"
用jinj2表达式替换webapp角色的第五个任务中的空循环列表。从webapp_rel_deployed_files变量开始,应用difference过滤器。提供webapp_file_list变量作为difference过滤器的参数。
- name: Remove Extraneous Files
file:
path: "{{ webapp_content_root_dir }}/{{ item }}"
state: absent
# TODO: Loop over a list of files
# that are in the 'webapp_rel_deployed_files'
# list, but not in the 'webapp_file_list' list.
# Use the difference filter.
loop: "{{ webapp_rel_deployed_files | difference(webapp_file_list) }}
📑执行剧本
[student@workstation data-filters]$ ansible-playbook deploy_webapp.yml -v
📑验证
[student@workstation data-filters]$ curl servera
Hello from webserver_01. (version v1.1)
[student@workstation data-filters]$ curl servera
Hello from webserver_02. (version v1.1)
📑清除实验
[student@workstation data-filters]$ lab data-filters finish
💡总结
RHCA认证需要经历5门的学习与考试,还是需要花不少时间去学习与备考的,好好加油,可以噶🤪。

以上就是【金鱼哥】对 第四章 使用过滤器和插件转换器–使用过滤器处理变量 的简述和讲解。希望能对看到此文章的小伙伴有所帮助。
💾红帽认证专栏系列:
RHCSA专栏:戏说 RHCSA 认证
RHCE专栏:戏说 RHCE 认证
此文章收录在RHCA专栏:RHCA 回忆录
如果这篇【文章】有帮助到你,希望可以给【金鱼哥】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点。
如果有对【运维技术】感兴趣,也欢迎关注❤️❤️❤️ 【金鱼哥】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!


- 点赞
- 收藏
- 关注作者
评论(0)