金鱼哥RHCA回忆录:DO447利用推荐做法进行开发--使用GIT管理ANSIBLE项目材料

🎹 个人简介:大家好,我是 金鱼哥,CSDN运维领域新星创作者,华为云·云享专家,阿里云社区·专家博主
📚个人资质:CCNA、HCNP、CSNA(网络分析师),软考初级、中级网络工程师、RHCSA、RHCE、RHCA、RHCI、ITIL😜
💬格言:努力不一定成功,但要想成功就必须努力🔥
📜1. 基础设施代码
DeyOps的一个关键概念是将基础设施作为代码,而不是手动管理你的基础设施,你通过运行自动化代码来定义和构建你的系统。Red Hat Ansible automation是一个可以帮助你实现这种方法的关键工具。
如果Ansible项目是用来定义基础设施的代码,那么应该使用Git这样的版本控制系统来跟踪和控制代码的更改。
版本控制还允许您为基础架构代码的不同阶段(如开发、QA和生产)实现生命周期。您可以提交您的更改分支并在非关键的开发和QA环境中测试这些更改。一旦您对更改有了信心,您就可以将它们合并到主要的生产代码中,并将更改应用到您的生产基础设施中。
📜2. 介绍GIT
Git是一个分布式版本控制系统(DVCS),它允许开发人员以协作的方式管理项目中文件的更改。文件的每次修订都提交到系统。可以恢复旧版本的文件,并维护谁做了更改的日志。
📜2. 自用笔记内容整理:(课外)
📑2.1 Git的简史
同生活中的许多伟大事物一样,Git 诞生于一个极富纷争大举创新的年代。
Linux 内核开源项目有着为数众广的参与者。 绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。 到 2002 年,整个项目组开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码。
到了 2005 年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了Linux 内核社区免费使用 BitKeeper 的权力。 这就迫使 Linux 开源社区(特别是 Linux 的缔造者Linux Torvalds)基于使用 BitKcheper 时的经验教训,开发出自己的版本系统。 他们对新的系统制订了若干目标:
- 速度
- 简单的设计
- 对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
- 完全分布式
有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
自诞生于 2005 年以来,Git 日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。 它的速度飞快,极其适合管理大项目,有着令人难以置信的非线性分支管理系统。
Git迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。
📑2.2 Git是什么?
Git是一款免费、开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
最原始的版本控制是纯手工的版本控制:修改文件,保存文件副本。有时候偷懒省事,保存副本时命名比较随意,时间长了就不知道哪个是新的,哪个是老的了,即使知道新旧,可能也不知道每个版本是什么内容,相对上一版作了什么修改了,当几个版本过去后,很可能就是下面这个老土的样子了:

📑2.3 Git特点
分布式相比于集中式的最大区别在于开发者可以提交到本地,每个开发者通过克隆(git clone),在本地机器上拷贝一个完整的Git仓库。
- 直接记录快照,而非差异比较 : Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。
- 近乎所有操作都是本地执行 :在 Git 中的绝大多数操作都只需要访问本地文件和资源,不用连网。
- 时刻保持数据完整性 :在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。
- 多数操作仅添加数据 :常用的 Git 操作大多仅仅是把数据添加到数据库。
开发流程示意图:

1)分布式
2)存储快照而非差异
3)本地有完全的版本库,几乎所有操作都在本地
4)有内在的一致性,SHA1
5)优秀的分支管理
6)支持各种协同模式
7)开源,有一些第三方软件可整合使用,几乎所有操作都是
与CVS/SVN,Git 的优势
1)支持离线开发,离线Repository(仓库)
2)强大的分支功能,适合多个独立开发者协作
3)速度块
📑2.4 为什么选择Git来控制版本,理由如下:
✉1)快速
如果你每移动一下鼠标都要等待五秒,是不是很受不了?版本控制也是一样的,每一个命令多那么几秒钟,一天下来也会浪费你不少时间。Git的操作非常快速,你可以把时间用在别的更有意义的地方。
✉2)离线工作
在没有网络的情况下如何工作?如果你用SVN或者CVS的话就很麻烦。而Git可以让你在本地做所有操作,提交代码,查看历史,合并,创建分支等等。
✉3)回退
人难免犯错。我很喜欢Git的一点就是你可以“undo”几乎所有的命令。你可以用这个功能来修正你刚刚提交的代码中的一个问题或者回滚整个代码提交操作。你甚至可以恢复一个被删除的提交,因为在后端,Git几乎不做任何删除操作。
✉4)省心
你有没有丢失过版本库?我有,而那种头疼的感觉现在还记忆犹新。而用Git的话,我就不必担心这个问题,因为任何一个人机器上的版本都是一个完整的备份。
✉5)选择有用的代码提交
当你把纽带,冰块还有西红柿一起扔进搅拌机的时候至少有两个问题。第一,搅拌过后,没有人知道之前扔进去了些什么东西。第二,你不能回退,重新把西红柿拿出来。同样的,当你提交了一堆无关的更改,例如功能A加强,新增功能B,功能C修复,想要理清这一堆代码到底干了什么是很困难的。当然,当发现功能A出问题的时候,你无法单独回滚功能A。Git可以通过创建“颗粒提交”,帮你解决这个问题。“staging area”的概念可以让你决定到底那些东西需要提交,或者更新,精确到行。
✉6)自由选择工作方式
使用Git,你可以同时和多个远程代码库连接,“rebase”而不是"merge"甚至只连接某个模块。但是你也可以选择一个中央版本库,就像SVN那样。你依然可以利用Git的其他优点。
✉7)保持工作独立
把不同的问题分开处理将有助于跟踪问题的进度。当你在为功能A工作的时候,其他人不应该被你还没有完成的代码所影响。分支是解决这个问题的办法。虽然其他的版本控制软件业有分支系统,但是Git是第一个把这个系统变得简单而快速的系统。
✉8)随大流
虽然只有死于才随着波浪前进,但是很多时候聪明的程序员也是随大流的。越来越多的公司,开源项目使用Git,包括Ruby On Rails,jQuery,Perl,Debian,Linux Kernel等等。拥有一个强大的社区是很大的优势,有很多教程、工具。
📑2.5 集中版本控制
CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统。
集中式版本控制系统,版本库是集中存放在中央服务器的,一起工作的人需要用自己的电脑从服务器上同步更新或上传自己的修改。

但是,所有的版本数据都存在服务器上,用户的本地设备就只有自己以前所同步的版本,如果不连网的话,用户就看不到历史版本,也无法切换版本验证问题,或在不同分支工作。
而且,所有数据都保存在单一的服务器上,有很大的风险这个服务器会损坏,这样就会丢失所有的数据,当然可以定期备份。
📑2.6 分布式版本控制
那分布式版本控制系统与集中式版本控制系统有何不同呢?
分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,不需要联网就可以工作。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你和同事在各自电脑修改相同文件,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库。大家之间可以相互复制。
分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。

📑2.7 Git原理
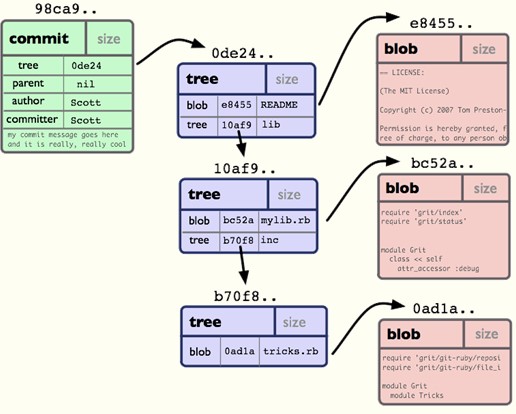
✉1)四种基本类型
BLOB: 每个blob代表一个(版本的)文件,blob只包含文件的数据,而忽略文件的其他元数据,如名字、路径、格式等。
TREE: 每个tree代表了一个目录的信息,包含了此目录下的blobs,子目录(对应于子trees),文件名、路径等元数据。因此,对于有子目录的目录,git相当于存储了嵌套的trees。
COMMIT:每个commit记录了提交一个更新的所有元数据,如指向的tree,父commit,作者、提交者、提交日期、提交日志等。每次提交都指向一个tree对象,记录了当次提交时的目录信息。一个commit可以有多个(至少一个)父commits。
TAG: tag用于给某个上述类型的对象指配一个便于开发者记忆的名字, 通常用于某次commit。
✉2)三种工作区域
工作区(Working Dir),提交区/暂存区(stage/index),版本库
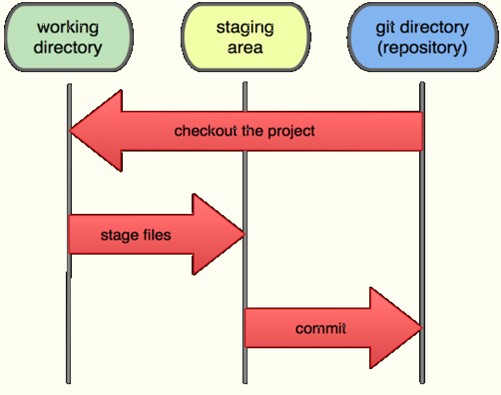

✉3)三种状态
-
已提交(committed):该文件已经被安全地保存在本地仓库中
-
已修改(modified):修改了某个文件,但还没有提交保存
-
已暂存(staged):把已修改的文件放在下次提交时要保存的清单中
📑2.8 GitLab Flow(GitLab工作流)
参考官网说明:https://docs.gitlab.com/ee/topics/gitlab_flow.html

git 工作流主要的问题是:
一、默认的 master 分支只是用于发布,开发都在其他分支上。
二、对于多数应用来说过于复杂,特别是 release 和 hotfix 分支的不可部署导致使用上的复杂。
✉GitHub flow是一个更简单的选择

GitHub 工作流十分简单,只有两个分支,master 和 feature。Atlassian 公司推荐的工作流也基本类似。
GitHub 工作流的主要问题是过于简单,没有对于常见的工作场景中的问题提出解决办法。
✉GitLab 工作流中的生产分支(Production branch)
GitHub 工作流隐含一个假定:每次合并 feature,主分支的代码是立即发布的。然而,实际中常常不能满足这个假定,例如:你无法控制代码发布时间,例如 App 发布要等审核通过。再例如:发布时间窗口限制,合并分支的时候也许并不在发布时间窗口。
GitLab 推荐用生产分支来解决上述问题:

Gitlab flow 的最大原则叫做"上游优先"(upsteam first),即只存在一个主分支master,它是所有其他分支的"上游"。只有上游分支采纳的代码变化,才能应用到其他分支。
对于"持续发布"的项目,它建议在master分支以外,再建立不同的环境分支。比如,"开发环境"的分支是master,"预发环境"的分支是pre-production,"生产环境"的分支是production。
开发分支是预发分支的"上游",预发分支又是生产分支的"上游"。代码的变化,必须由"上游"向"下游"发展。比如,生产环境出现了bug,这时就要新建一个功能分支,先把它合并到master,确认没有问题,再cherry-pick到pre-production,这一步也没有问题,才进入production。
只有紧急情况,才允许跳过上游,直接合并到下游分支。
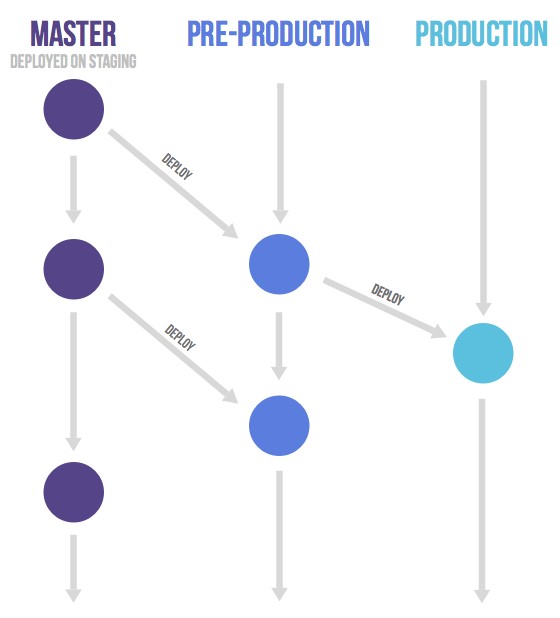
✉版本发布
对于"版本发布"的项目,建议的做法是每一个稳定版本,都要从master分支拉出一个分支,比如2-3-stable、2-4-stable等等。
以后,只有修补bug,才允许将代码合并到这些分支,并且此时要更新小版本号。

📑2.9 常用命令流程图


✉git的工作流:

你的本地仓库由 git 维护的三棵"树"组成。第一个是你的 工作目录,它持有实际文件;第二个是 暂存区(staging),它像个缓存区域,临时保存你的改动;最后是 HEAD,它指向你最后一次提交的结果。
你可以提出更改(把它们添加到暂存区),使用如下命令:
git add <filename>
git add *
这是 git 基本工作流程的第一步;使用如下命令以实际提交改动:
git commit -m "代码提交信息"
现在,你的改动已经提交到了 HEAD,但是还没到你的远端仓库。
📑2.10 工作区和暂存区
Git和其他版本控制系统如svn不同之处是有暂存区的概念
先弄清楚这几个名词
✉工作区:
就是在你的电脑里能看到的目录,比如咱们创建的git_test
✉版本库:
工作区中有一个隐藏目录 .git,它不算工作区,而是git的版本库。
git的版本库里面存放了很多的东西,其中最重要的就是称为stage(index)的暂存区,还有git为我们自动创建的第一个分支master,以及指向master的一个指针叫head。

当我们在工作区创建了文件后,执行add后,再来看这个图

当你执行commit后,暂存区的内容就没有

📑2.11 安装Git
最早Git是在Linux上开发的,很长一段时间内,Git也只能在Linux和Unix系统上跑。不过,慢慢地有人把它移植到了Windows上。现在,Git可以在Linux、Unix、Mac和Windows这几大平台上正常运行了。
在Linux上安装Git,首先,你可以试着输入git,看看系统有没有安装Git:
$ git
像上面的命令,有很多Linux会友好地告诉你Git没有安装,还会告诉你如何安装Git。
如果你碰巧用Debian或Ubuntu Linux,通过一条sudo apt-get install git就可以直接完成Git的安装,非常简单。如果想查看是否安装成功,通过git --version。
如果是其他Linux版本,可以直接通过源码安装。先从Git官网下载源码,然后解压,依次输入:./config,make,sudo make install这几个命令安装就好了。
安装完成后,还需要最后一步设置,在命令行输入:
$ git config --global user.name "Your Name"
$ git config --global user.email "email@example.com"
因为Git是分布式版本控制系统,所以,每个机器都必须自报家门:你的名字和Email地址。你也许会担心,如果有人故意冒充别人怎么办?这个不必担心,首先我们相信大家都是善良无知的群众,其次,真的有冒充的也是有办法可查的。
注意:git config命令的–global参数,用了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址。
📑2.12 常用命令
📝初始化一个本地的git仓库:
$ git init
📝跟踪文件:
$git add index.html(跟踪完文件之后,这个文件被存放在暂存区中)
跟踪多个文件:
$ git add *.html 或者 $ git add .
如果文件在暂存区中,此时对文件进行修改,则需要再次将文件添加到暂存区中(add)
如果对本地版本库中的文件进行修改,还没有添加到暂存区,可以查看文件的修改内容: $git diff index.html
📝把跟踪好的文件提交到版本库中:
$ git commit -m “add a html file” 参数-m的作用:告诉git提交解释信息为add a html file
(提交完文件之后,这个文件就被保存到本地版本库中)
📝查看提交记录:
$ git log (简洁版:$git log --pretty=oneline)
📝查看工作区目前的状态:
$ git status
📝如果多次修改文件,并提交到本地版本库中,如果想回退到上一个版本,则:
Git必须知道当前版本是哪个版本,在Git中,用HEAD表示当前版本,也就是最新的提交1094adb…(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。
$ git reset --hard HEAD^//表示回到上个版本
📝现在回到了老版本,如果现在又想回到新版本,则:
只要上面的命令行窗口还没有被关掉,你就可以顺着往上找,找到那个最新版本的commit id是6e1f7…,于是就可以指定回到未来的某个版本:
$ git reset --hard 6e1f7
如果命令行窗口被关掉了,则可以使用$git reflog来查看每一次命令(历史命令)。这时找到最新版本的commit id,再使用上个命令就可以回到最新版本了。
📝撤销修改:
$git checkout --read.txt(就是让这个文件回到最近一次git commit或git add时的状态。)
如果修改完一个文件,并将这个文件保存到暂存区中了,但是这个时候发现修改有问题,这时可以用**$git reset HEAD read.txt** 命令把暂存区的修改回退到工作区。(这时相当于修改完文件,没有执行add命令,这时可以执行上个命令撤销修改。)
📝创建分支:
$ git branch testing //这会在当前commit对象上新建一个分支指针
📝显示当前的分支:
$ git branch
📝切换到其他分支:
$ git checkout testing //转换到testing分支
📝Bug分支:
软件开发中,bug就像家常便饭一样。有了bug就需要修复,在Git中,由于分支是如此的强大,所以,每个bug都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临时分支删除。
📝功能分支:
添加一个新功能时,你肯定不希望因为一些实验性质的代码,把主分支搞乱了,所以,每添加一个新功能,最好新建一个feature分支,在上面开发,完成后,合并,最后,删除该feature分支。
📝克隆远程仓库:
git clone git@远程仓库url(如:$git clone git@github.com:XXXXX/XXXXX.git)
当从远程库clone时,默认情况下,你只能看到本地的master分支。现在,你要在dev分支上开发,就必须创建远程origin的dev分支到本地,于是用这个命令创建本地dev分支:$git checkout -b dev origin/dev
📝推送数据到远程仓库:
$ git push -u [远程仓库名] [本地推送的分支名]
(如:$ git push -u origin master,把本地的master分支推送给了远程仓库,并且在远程仓库origin中创建了一个远程的master分支,远程的master分支和本地master分支关联;如果你推送的是bcy分支:$ git push -u origin bcy,那么远程库会自动创建bcy分支,并与本地的bcy分支进行关联)
(如果将本地的test分支推送到远程的master分支上:$git push -u origin test:master)
📝推送本地仓库的所有分支到远程仓库上去:
$ git push -u [远程仓库名] --all
📝查看本地分支与远程分支的联系:
$ git branch -vv
📝查看当前远程仓库:
$ git remote -v
📝查看远程的分支:
$ git branch -r
📝从远程仓库抓取数据:
$ git fetch [远程仓库名](如:$git fetch origin,抓取下来之后,对本地没有任何影响)
📝在本地分支上,合并远程分支:
$ git merge 远程仓库名/分支名
只有在所克隆的服务器上有写权限,并且同一时刻没有其他人在推送数据,这条命令才会如期完成任务。如果你在推送数据前,已经有其他人推送了若干更新,那你的推送操作会被驳回,你必须先把他们的更新抓取到本地,合并到自己的项目中,然后才可以再次推送。
当从远程仓库把别人的更新抓取到本地之后,可以看看在我们推送之前,别人做了什么,
$ git log --no-merges origin/master。
$ git pull 相当于 $ git fetch 和 $ git merge 远程仓库名/分支名,抓取远程数据,并在本地分支上合并远程分支。若合并有冲突,则需手动解决冲突,若合并无冲突,则本地就跟远程数据一样了。
如果本地有一个master分支和远程的origin/master分支没有建立跟踪关联,需要使用 $ git branch --set-upstream-to=origin/master
📝查看远程仓库信息:
$ git remote show origin
📝重命名远程仓库名:
$ git remote rename 原名 新名
📝远程仓库的删除:
$ git remote rm 远程仓库名
📝将本地仓库与远程仓库进行关联:
$ git remote add origin git@远程服务器地址
(如:$git remote add origin git@github.com:michaelliao/learngit.git)
(关联之后,一般要将本地master分支与远程master进行关联:$git branch --set-upstream-to=origin/master,在关联master分支之前,先git pull一下,然后再关联master分支。关联之后如果pull代码,如果报错: refusing to merge unrelated histories,就这样pull:$git pull origin master --allow-unrelated-histories)
📑2.13 课本练习
[student@workstation ~]$ lab development-git start
[student@workstation ~]$ git config --global user.name 'Daniel George'
[student@workstation ~]$ git config --global user.email daniel@lab.example.com
[student@workstation ~]$ git config --global push.default simple
[student@workstation ~]$ git config --global -l
user.name=Daniel George
user.email=daniel@lab.example.com
push.default=simple
credential.helper=store
[student@workstation ~]$ cat .gitconfig
[user]
name = Daniel George
email = daniel@lab.example.com
[push]
default = simple
[credential]
helper = store
[student@workstation ~]$ mkdir git-repos && cd git-repos
[student@workstation git-repos]$ git clone http://git@git.lab.example.com:8081/git/my_webservers_DEV.git
Cloning into 'my_webservers_DEV'...
remote: Enumerating objects: 6, done.
remote: Counting objects: 100% (6/6), done.
remote: Compressing objects: 100% (6/6), done.
remote: Total 6 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (6/6), done.
[student@workstation git-repos]$ cd my_webservers_DEV
[student@workstation my_webservers_DEV]$ tree
.
├── apache-setup.yml
└── templates
├── httpd.conf.j2
└── index.html.j2
1 directory, 3 files
[student@workstation my_webservers_DEV]$ git branch
* master
[student@workstation my_webservers_DEV]$ git branch development
[student@workstation my_webservers_DEV]$ git branch
development
* master
[student@workstation my_webservers_DEV]$ git checkout development
Switched to branch 'development'
[student@workstation my_webservers_DEV]$ git branch
* development
master
📝按要求修改文件
[student@workstation my_webservers_DEV]$ cat templates/index.html.j2
{{ apache_test_message }} {{ ansible_distribution }} {{ ansible_distribution_version }} <br>
Current Host: {{ ansible_hostname }} <br>
Server list: <br>
{% for host in groups['all'] %}
{{ host }} <br>
{% endfor %}
HELLO WORLD <br>
[student@workstation my_webservers_DEV]$ git status
On branch development
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: templates/index.html.j2
no changes added to commit (use "git add" and/or "git commit -a")
[student@workstation my_webservers_DEV]$ git add templates/index.html.j2
[student@workstation my_webservers_DEV]$ git status
On branch development
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: templates/index.html.j2
[student@workstation my_webservers_DEV]$ git commit -m "My first commit"
[development 793b329] My first commit
1 file changed, 1 insertion(+)
[student@workstation my_webservers_DEV]$ git status
On branch development
nothing to commit, working tree clean
[student@workstation my_webservers_DEV]$ git push --set-upstream origin development
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Delta compression using up to 4 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 428 bytes | 428.00 KiB/s, done.
Total 4 (delta 1), reused 0 (delta 0)
remote:
remote: To create a merge request for development, visit:
remote: http://git.lab.example.com:8081/git/my_webservers_DEV/merge_requests/new?merge_request%5Bsource_branch%5D=development
remote:
To http://git.lab.example.com:8081/git/my_webservers_DEV.git
* [new branch] development -> development
Branch 'development' set up to track remote branch 'development' from 'origin'.
[student@workstation my_webservers_DEV]$ git checkout master
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
[student@workstation my_webservers_DEV]$ git branch
development
* master
[student@workstation my_webservers_DEV]$ cat templates/index.html.j2
{{ apache_test_message }} {{ ansible_distribution }} {{ ansible_distribution_version }} <br>
Current Host: {{ ansible_hostname }} <br>
Server list: <br>
{% for host in groups['all'] %}
{{ host }} <br>
{% endfor %}
[student@workstation my_webservers_DEV]$ git merge development
Updating 93d0e87..793b329
Fast-forward
templates/index.html.j2 | 1 +
1 file changed, 1 insertion(+)
[student@workstation my_webservers_DEV]$ cat templates/index.html.j2
{{ apache_test_message }} {{ ansible_distribution }} {{ ansible_distribution_version }} <br>
Current Host: {{ ansible_hostname }} <br>
Server list: <br>
{% for host in groups['all'] %}
{{ host }} <br>
{% endfor %}
HELLO WORLD <br>
[student@workstation my_webservers_DEV]$ git push
Total 0 (delta 0), reused 0 (delta 0)
To http://git.lab.example.com:8081/git/my_webservers_DEV.git
93d0e87..793b329 master -> master
[student@workstation my_webservers_DEV]$ git revert --no-edit HEAD
[master 3c8b13e] Revert "My first commit"
Date: Tue Apr 6 16:03:10 2021 +0800
1 file changed, 1 deletion(-)
[student@workstation my_webservers_DEV]$ cat templates/index.html.j2
{{ apache_test_message }} {{ ansible_distribution }} {{ ansible_distribution_version }} <br>
Current Host: {{ ansible_hostname }} <br>
Server list: <br>
{% for host in groups['all'] %}
{{ host }} <br>
{% endfor %}
[student@workstation my_webservers_DEV]$ git push
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Delta compression using up to 4 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 432 bytes | 432.00 KiB/s, done.
Total 4 (delta 1), reused 0 (delta 0)
To http://git.lab.example.com:8081/git/my_webservers_DEV.git
793b329..3c8b13e master -> master
📝完成实验
[student@workstation my_webservers_DEV]$ lab development-git finish
💡总结
RHCA认证需要经历5门的学习与考试,还是需要花不少时间去学习与备考的,好好加油,可以噶🤪。

以上就是【金鱼哥】对 第一章 利用推荐做法进行开发–使用GIT管理ANSIBLE项目材料 的简述和讲解。希望能对看到此文章的小伙伴有所帮助。
💾红帽认证专栏系列:
RHCSA专栏:戏说 RHCSA 认证
RHCE专栏:戏说 RHCE 认证
此文章收录在RHCA专栏:RHCA 回忆录
如果这篇【文章】有帮助到你,希望可以给【金鱼哥】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点。
如果有对【运维技术】感兴趣,也欢迎关注❤️❤️❤️ 【金鱼哥】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!


- 点赞
- 收藏
- 关注作者
评论(0)