皮尔逊、斯皮尔曼、肯德尔等级应用场景及代码实现(附Python代码)

【摘要】
本文结合Python的scipy.stats,简单梳理皮尔逊Pearson、斯皮尔曼Spearman、肯德尔等级Kendallta三个相关系数的运用场景;及Python中如何计算三个相关系数。
1、统计学中常见变量类型
方便下文理解,先简单梳理下统计学中常用的变量类别,
统计学中常用的变量类别
2、皮尔逊相关系数(Pea...
本文结合Python的scipy.stats,简单梳理皮尔逊Pearson、斯皮尔曼Spearman、肯德尔等级Kendallta三个相关系数的运用场景;及Python中如何计算三个相关系数。
1、统计学中常见变量类型
方便下文理解,先简单梳理下统计学中常用的变量类别,
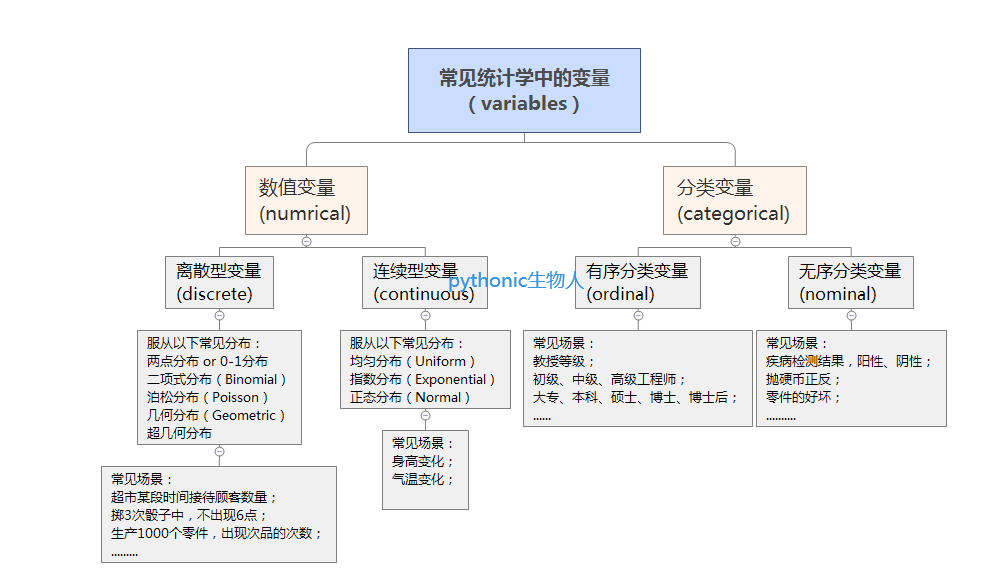
统计学中常用的变量类别
2、皮尔逊相关系数(Pearson)
使用前提:大小一致、连续、服从正态分布的数据集,以下为scipy中描述:
scipy.stats.pearsonr(x, y)
The Pearson correlation coefficient measures the linear relationship between two datasets 「衡量两组数据的线性相关性」.
The calculation of the p-value relies on the assumption that each dataset is normally distributed「假设两组数据服从正态分布,即数据必须是连续型数据(continuous)」.
Like other correlation coefficients, this one varies between -1 and +1
文章来源: wenyusuran.blog.csdn.net,作者:文宇肃然,版权归原作者所有,如需转载,请联系作者。
原文链接:wenyusuran.blog.csdn.net/article/details/122534828

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)