金鱼哥RHCA回忆录:RH236使用Nagios监控Red Hat Gluster存储

🎹 个人简介:大家好,我是 金鱼哥,CSDN运维领域新星创作者,华为云·云享专家,阿里云社区·专家博主
📚个人资质:CCNA、HCNP、CSNA(网络分析师),软考初级、中级网络工程师、RHCSA、RHCE、RHCA、RHCI、ITIL😜
💬格言:努力不一定成功,但要想成功就必须努力🔥
原理是安装一台Nagios的服务器,服务端通过NRPE组件与被监控端交互,glusterfs已自带安装了NRPE组件,只要基本配置下即可:
安装nagios服务器
环境只提供了rhel6的安装包,所以要提前安装一台rhel6机器,并且安装监控glusterfs的相关插件:
yum源:rhs-nagios-3-for-rhel-6-server-rpms
# yum install nagios-server-addons
配置所有gluster节点
添加nrpe服务允许访问的IP:
# vim /etc/nagios/nrpe.cfg
allowed_hosts=127.0.0.1,nagios-server-ip
重启nrpe及glusterpmd服务:
# systemctl restart nrpe
# systemctl restart glusterpmd
在nagios服务器配置监控
# configure-gluster-nagios -c cluster-name -H HostName-or-IPaddress
#只需指定一个gluster集群中的一台机器,其它机器自动添加
打开nagios图形
https://nagios-server-ip/nagios
默认账号密码都为:nagiosadmin
开启报警
打开host报警,services报警同理
点击红框内的链接,进入节点配置:
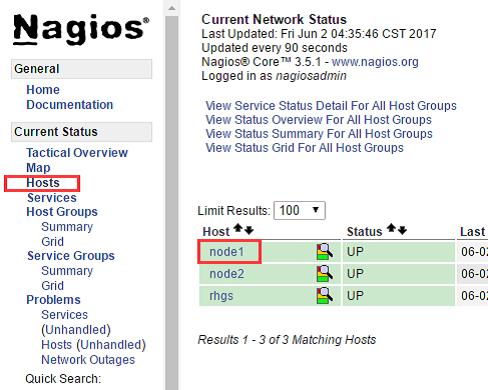
点击“Enablenotificationforallserviceonthishost”,开启服务通知选项。
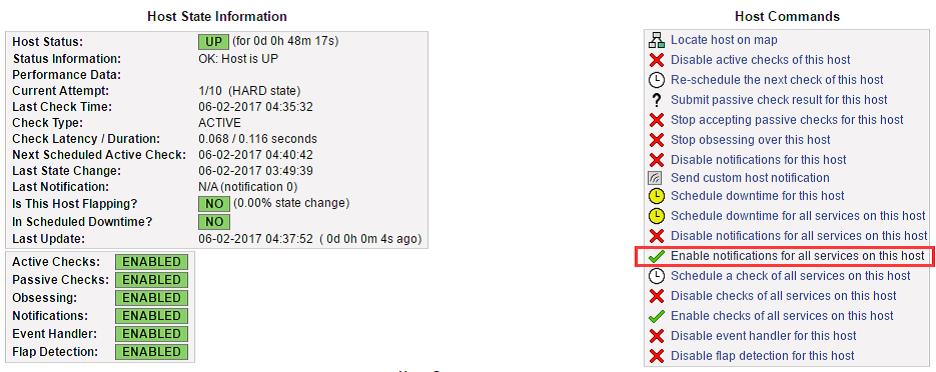
点击commit完成设置

邮件报警
# vim /etc/nagios/gluster/gluster-contacts.cfg
修改contact_name,alias,email,定义联系人或联系人组
define contact { #定义联系人
contact_name Contact1 #联系人名称
alias contack1 #别名
email test@example.com #邮箱
service_notification_period 24x7 #服务报警时间
service_notification_options w,u,c,r #服务报警选项,服务处于什么状态才报警
service_notification_commands notify-service-by-email #服务报警方式
服务状态有多种:w:警告(warning)、u:未知(unkown)、c:严重(critical)、r:恢复(recover)、f:闪断(flapping)、s:计划内宕机(scheduled downtime events)
设置主机报警配置:
define hosts {
host_notification_period 24x7
host_notification_options d,u,r
host_notification_commands notify-host-to-ovirt
can_submit_commands 1
_ovirt_rest_api http://ovirt.com:8080/ovirt-engine/api
_ovirt_user admin@internal
}
主机状态也有多种:d:宕机(down)、u:主机不能到达(unreachable)、r:恢复(recover)、f:闪断(flapping)、s:计划内宕机(scheduled downtime events)
define contactgroup{ #定义联系人组
contactgroup_name Group1 #组名
alias GroupAlias #别名
members Contact1,Contact2 #组成员
}
PS:组设置有模板,请参考/etc/nagios/objects/contacts.cfg
# vim /etc/nagios/gluster/gluster-templates.cfg
#在模板中定义
#在指定主机或服务定义中,指定联系人或联系人组,此主机或服务的所有报警都会发给这个联系人或联系人组
define host{
name gluster-generic-host
use linux-server notifications_enabled 1
notification_period 24x7
notification_interval 120
notification_options d,u,r,f,s
register 0
contact_groups Group1 #添加联系人组
contacts user1,user2 #添加联系人
}
define host{
name gluster-generic-host
use linux-server
notifications_enabled 1
notification_period 24x7
notification_interval 120
notification_options d,u,r,f,s
register 0
contacts +snmp, Contact1
}
define service {
name gluster-service
use generic-service
notifications_enabled 1
notification_period 24x7
notification_options w,u,c,r,f,s
notification_interval 120
register 0
contacts +snmp, Contact1
_gluster_entity Service
}
重启服务
# service nagios restart
课本练习(以练习来进行了解)
[root@workstation ~]# lab rhsc-nagios setup
1. 配置servera防火墙规则。
[root@servera ~]# firewall-cmd --permanent --add-port=5666/tcp
success
[root@servera ~]# firewall-cmd --reload
success
2. 配置serverb防火墙规则。
[root@serverb ~]# firewall-cmd --permanent --add-port=5666/tcp
success
[root@serverb ~]# firewall-cmd --reload
success
3. 配置servera和serverb以允许对NRPE的访问。
# vim /etc/nagios/nrpe.cfg
# ALLOWED HOST ADDRESSES
# This is an optional comma-delimited list of IP address or hostnames
# that are allowed to talk to the NRPE daemon. Network addresses with a bit mask
# (i.e. 192.168.1.0/24) are also supported. Hostname wildcards are not currently
# supported.
#
# Note: The daemon only does rudimentary checking of the client's IP
# address. I would highly recommend adding entries in your /etc/hosts.allow
# file to allow only the specified host to connect to the port
# you are running this daemon on.
#
# NOTE: This option is ignored if NRPE is running under either inetd or xinetd
allowed_hosts=127.0.0.1,manager.lab.example.com
# systemctl restart nrpe
4. 配置nagios以监视gluster-cluster。
[root@manager ~]# configure-gluster-nagios -c gluster-cluster -H servera.lab.example.com
Cluster configurations changed
Changes :
Hostgroup gluster-cluster - ADD
Host gluster-cluster - ADD
Service - Volume Utilization - prod-vol -ADD
Service - Volume Split-brain status - prod-vol -ADD
Service - Volume Status - prod-vol -ADD
Service - Cluster Utilization -ADD
Service - Cluster - Quorum Status -ADD
Service - Cluster Auto Config -ADD
Host servera.lab.example.com - ADD
Service - Brick Utilization - /bricks/brick-a1/brick -ADD
Service - Brick - /bricks/brick-a1/brick -ADD
Host serverb.lab.example.com - ADD
Service - Brick Utilization - /bricks/brick-b1/brick -ADD
Service - Brick - /bricks/brick-b1/brick -ADD
Are you sure, you want to commit the changes? (Yes, No) [Yes]:
Enter Nagios server address [manager.lab.example.com]:
Cluster configurations synced successfully from host servera.lab.example.com
Do you want to restart Nagios to start monitoring newly discovered entities? (Yes, No) [Yes]:
Nagios re-started successfully
5. 验证Nagios配置。
[root@manager ~]# nagios -v /etc/nagios/nagios.cfg
Nagios Core 3.5.1
Copyright (c) 2009-2011 Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 08-30-2013
License: GPL
…………
Total Warnings: 13
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
6. 配置nagios将glusterd的电子邮件通知发送给student用户。
[root@manager ~]# vim /etc/nagios/gluster/gluster-contacts.cfg
define contact {
contact_name student
alias student
email student@manager.lab.example.com
service_notification_period 24x7
service_notification_options w,u,c,r,f,s
service_notification_commands notify-service-by-email
host_notification_period 24x7
host_notification_options d,u,r,f,s
host_notification_commands notify-host-by-email
}
[root@manager ~]# vim /etc/nagios/gluster/gluster-templates.cfg
define host{
name gluster-generic-host
use linux-server
notifications_enabled 1
notification_period 24x7
notification_interval 120
notification_options d,u,r,f,s
register 0
contacts +snmp,student
}
define service {
name gluster-service
use generic-service
notifications_enabled 1
notification_period 24x7
notification_options w,u,c,r,f,s
notification_interval 120
register 0
contacts +snmp,student
_gluster_entity Service
}
添加配置用于通过电子邮件的通知服务和通过电子邮件的通知主机
[root@manager ~]# cat /etc/nagios/objects/commands.cfg (在 | /bin/mail -s 前添加)
$NOTIFICATIONCOMMENT$\n
$NOTIFICATIONCOMMENT$\n
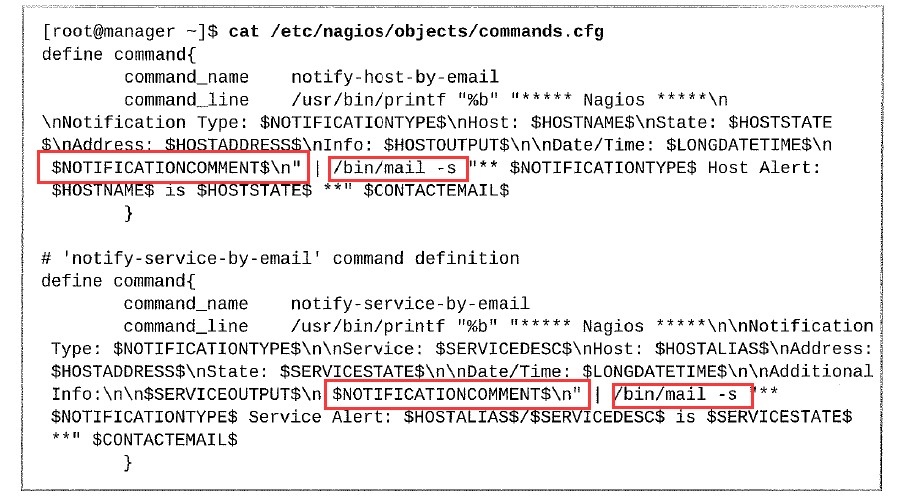
[root@manager ~]# service nagios restart
7. 配置MTA以侦听远程连接。
[root@manager ~]# cat /etc/mail/sendmail.mc
dnl # The following causes sendmail to only listen on the IPv4 loopback address
dnl # 127.0.0.1 and not on any other network devices. Remove the loopback
dnl # address restriction to accept email from the internet or intranet.
dnl # DAEMON_OPTIONS(`Port=smtp,Addr=127.0.0.1, Name=MTA')dnl
dnl #
[root@manager ~]# chkconfig sendmail on
[root@manager ~]# service sendmail restart
可去图形界面手动再点击启用告警通知,具体可看课程笔记。
可进行邮件发送测试:
[root@manager ~]# echo test |mail -s test student@manager.lab.example.com
按课本要求对serverb进行关机后,可收到邮件
[student@manager ~]$ mail
Heirloom Mail version 12.4 7/29/08. Type ? for help.
"/var/spool/mail/student": 10 messages 4 unread
1 nagios@manager.lab.e Mon Dec 14 16:28 35/1149 "** PROBLEM Service Alert: gluster-cluster/Cl"
>U 2 nagios@manager.lab.e Mon Dec 14 16:28 35/1148 "** PROBLEM Service Alert: gluster-cluster/Cl"
U 3 nagios@manager.lab.e Mon Dec 14 16:28 36/1161 "** PROBLEM Service Alert: servera.lab.exampl"
U 4 nagios@manager.lab.e Mon Dec 14 16:28 36/1161 "** PROBLEM Service Alert: serverb.lab.exampl"
U 5 root Mon Dec 14 16:32 21/829 "test"
6 nagios@manager.lab.e Mon Dec 14 16:45 30/1111 "** PROBLEM Host Alert: serverb.lab.example.c"
& 6
Message 6:
From nagios@manager.lab.example.com Mon Dec 14 16:45:32 2020
Return-Path: <nagios@manager.lab.example.com>
From: nagios@manager.lab.example.com
Date: Mon, 14 Dec 2020 16:45:32 +0800
To: student@manager.lab.example.com
Subject: ** PROBLEM Host Alert: serverb.lab.example.com is DOWN **
User-Agent: Heirloom mailx 12.4 7/29/08
Content-Type: text/plain; charset=us-ascii
Status: RO
***** Nagios *****
Notification Type: PROBLEM
Host: serverb.lab.example.com
State: DOWN
Address: serverb.lab.example.com
Info: CRITICAL: NRPE service on the host is down or not responding
Date/Time: Mon Dec 14 16:45:32 CST 2020
8. 脚本评分。
[root@workstation ~]# lab rhsc-nagios grade
总结
RHCA认证需要经历5门的学习与考试,还是需要花不少时间去学习与备考的,好好加油,可以噶🤪。

以上就是【金鱼哥】对 第十四章 使用Nagios监控Red Hat Gluster存储 的简述和讲解。希望能对看到此文章的小伙伴有所帮助。
💾红帽认证专栏系列:
RHCSA专栏:戏说 RHCSA 认证
RHCE专栏:戏说 RHCE 认证
此文章收录在RHCA专栏:RHCA 回忆录
如果这篇【文章】有帮助到你,希望可以给【金鱼哥】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点。
如果有对【运维技术】感兴趣,也欢迎关注❤️❤️❤️ 【金鱼哥】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!


- 点赞
- 收藏
- 关注作者
评论(0)