requests爬虫实战:某基金信息爬取

一、请求探索
网页分析:
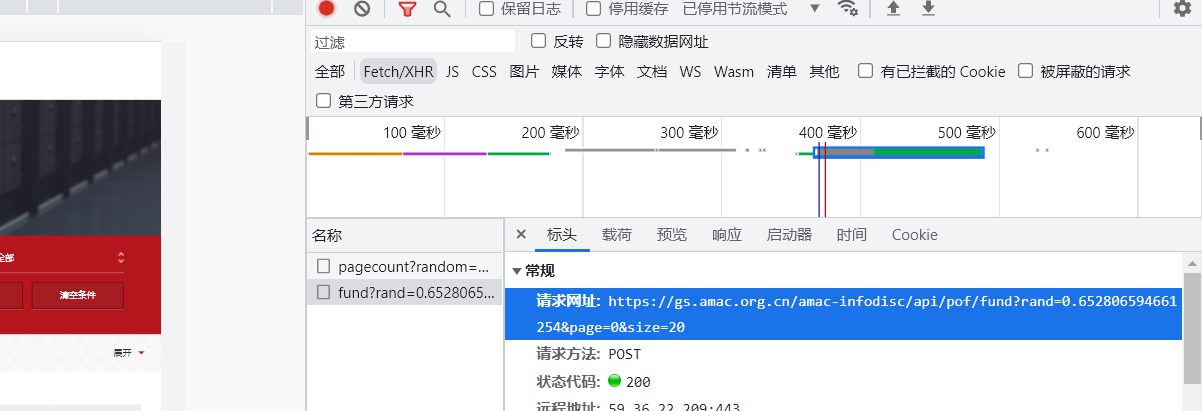
页码分析:
1.第一页:https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.652806594661254&page=0&size=20
2. 第二页: https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.652806594661254&page=1&size=20
3. https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.652806594661254&page=2&size=20
单数刷新一下rand发生变化:似乎就是是一个随机数
https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.16767992415199218&page=0&size=20
规律变化:页码部分需要调整,rand部分随机的。
https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand={}&page={}&size=20
也可以通过JS查看确定一下就是用的一个随机函数:
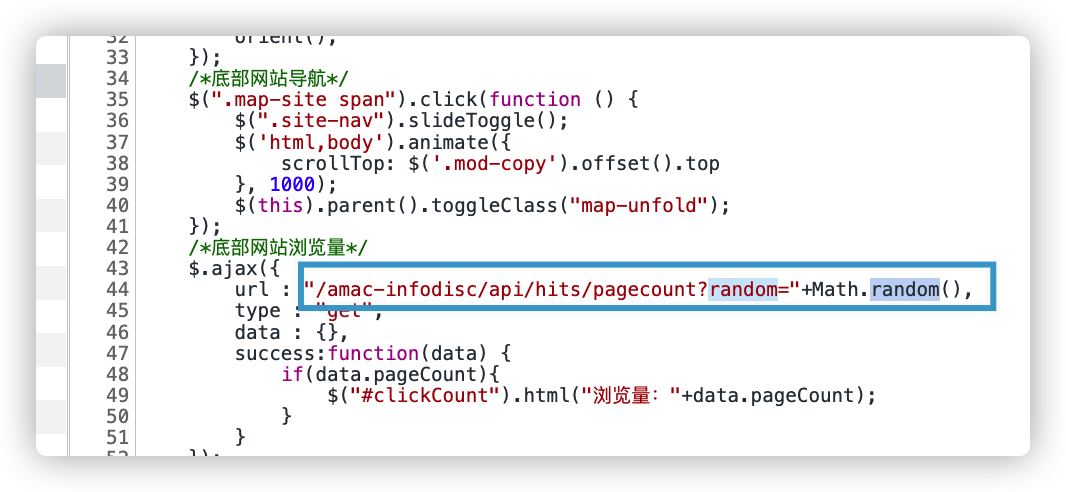
写段代码产生随机数:
import random
r=random.random()
print(str(r))
- 1
- 2
- 3
完整请求一个页面如下所示:
import requests
import random
import json
import time
headers = {
"Accept-Language": "zh-CN,zh;q=0.9",
'Content-Type': 'application/json',
'Origin': 'http://gs.amac.org.cn',
'Referer': 'https://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Mobile Safari/537.36'
}
r = random.random()
num = 1
url = "https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=" + str(r) + "&page=" + str(num) + "&size=20"
data = {}
data = json.dumps(data)
response = requests.post(url=url, data=data, headers=headers)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
二、分析详情页面
2.1 基本解析
例如分析这一个详情页面:https://gs.amac.org.cn/amac-infodisc/res/pof/fund/351000128956.html
我们使用Beautiful Soup来解析它。
response = requests.get(url2, headers=headers) # 请求详情页面
html = requests.get(url=url, headers=headers).content.decode('utf-8') # 获取详情页面的url
# print(html)
soup = BeautifulSoup(html, 'lxml') # 接卸
- 1
- 2
- 3
- 4
- 5
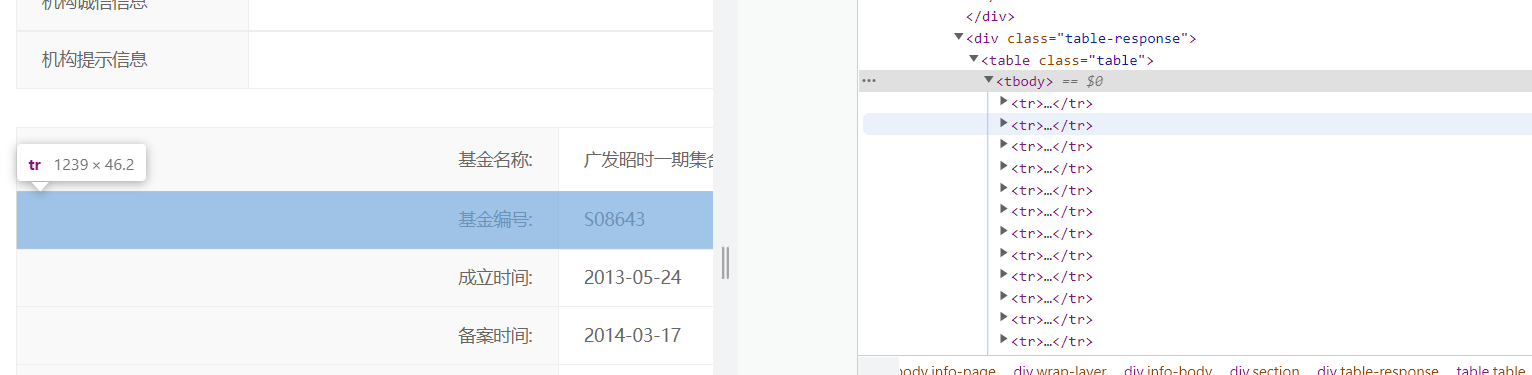
分析具体内容:上面一个表内容都在一个table里面
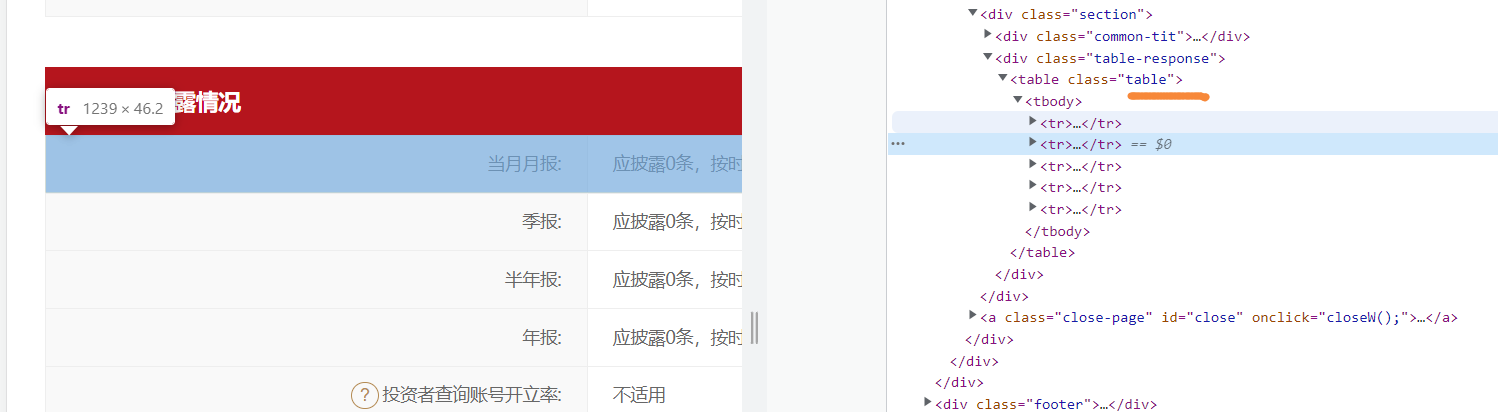
下面一个表信息透露情况:单独又在另外一个table里面
2.2 内容定位获取
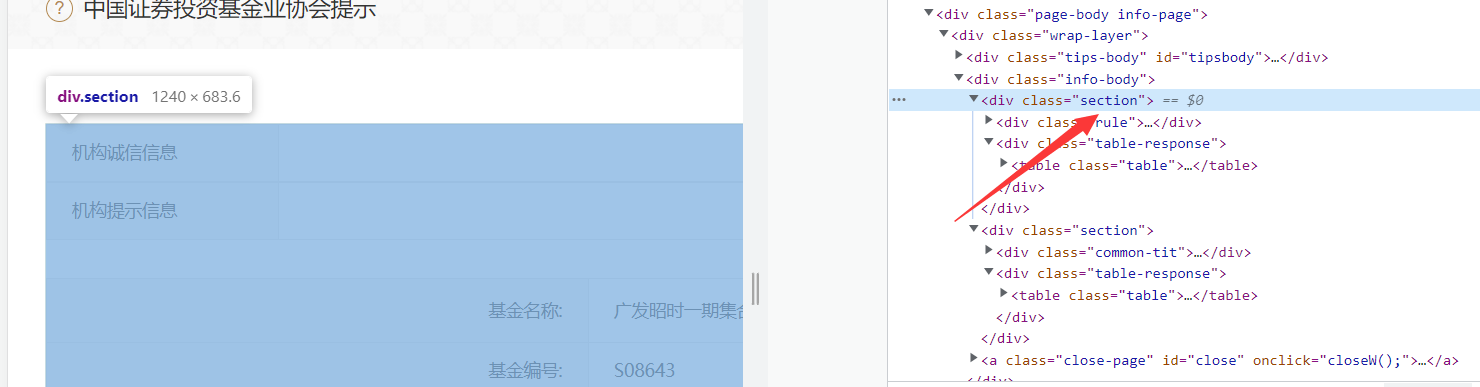
比如定位基金名称,最简单的做法就是直接复制xpath:
num1 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[1]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 基金名称
- 1
- 2
- 3
三、完整源码
# coding: utf-8
import requests
import random
import json
from lxml import etree
import codecs
import csv
count = 0
rows = []
for i in range(1, 15):
headers = {
"Accept-Language": "zh-CN,zh;q=0.9",
'Content-Type': 'application/json',
'Origin': 'http://gs.amac.org.cn',
'Referer': 'https://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Mobile Safari/537.36'
}
r = random.random()
num = 1
url = "https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=" + str(r) + "&page=" + str(i) + "&size=20"
data = {}
data = json.dumps(data)
response = requests.post(url=url, data=data, headers=headers)
# print(response)
datas = json.loads(response.text)["content"]
''':cvar
获取每一个页面的链接
'''
for data1 in datas:
jjid = data1['id'] # 基金ID
managerurl = data1['managerUrl'] # 经理页url
# print(managerurl)
fundName = data1['fundName'] # 基金名称
# print(fundName)
managename = data1['managerName'] # 基金管理人名称
# print(managename)
url = data1['url'] # 获取分支url
# print(url)
url2 = 'https://gs.amac.org.cn/amac-infodisc/res/pof/fund/' + url # 构造完整url,根据每一个链接获取详情页面
# print(url2)
count += 1
print("正在爬取第" + str(count) + "条数据")
''':cvar
开始解析详情页面
'''
html = requests.get(url=url2, headers=headers).text.encode('utf-8') # 请求详情页面的url
# print(html)
tree = etree.HTML(html) # 标准化
# encode('ISO-8859-1').decode('utf-8')解决乱码问题:βҳ转换为正常的中文:
num1_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[1]/td[2]/text()',
encoding="utf-8")
if len(num1_0) == 0:
num1 = num1_0
else:
num1 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[1]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 基金名称
num2 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[2]/td[2]/text()',
encoding="utf-8") # 基金编号
# print(num2)
num3_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[3]/td[2]/text()',
encoding="utf-8")
if len(num3_0) == 0:
num3 = num3_0
else:
num3 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[3]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "") # 成立时间
num4_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[4]/td[2]/text()',
encoding="utf-8")
if len(num4_0) == 0:
num4 = num4_0
else:
num4 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[4]/td[2]/text()',
encoding="utf-8")[0].replace(" ", "").replace("\t", "") # 备案时间
num5_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[5]/td[2]/text()',
encoding="utf-8")
if len(num5_0) == 0:
num5 = num5_0
else:
num5 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[5]/td[2]/text()',
encoding="utf-8")[0].encode(
'ISO-8859-1').decode('utf-8') # 基金类型
num6_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[6]/td[2]/text()',
encoding="utf-8")
if len(num6_0) == 0:
num6 = num6_0
else:
num6 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[6]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 基金类型
num7_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[7]/td[2]/a',
encoding="utf-8")
# print(num7_0)
# print(len(num7_0))
if len(num7_0) == 0:
num7 = num7_0
else:
num7 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[7]/td[2]/a/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 币种
# /html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[7]/td[2]/a
num8_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[7]/td[2]/a/text()',
encoding="utf-8")
if len(num8_0) == 0:
num8 = num8_0
else:
num8 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[8]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 基金管理人名称
num9_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[9]/td[2]/text()',
encoding="utf-8")
if len(num9_0) == 0:
num9 = num9_0
else:
num9 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[9]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 管理类型
num10_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[10]/td[2]/text()',
encoding="utf-8") # 托管人名称
if len(num10_0) == 0:
num10 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[10]/td[2]/text()',
encoding="utf-8") # 托管人名称
else:
num10 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[10]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 托管人名称
num11_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[11]/td[2]/text()',
encoding="utf-8")
if len(num11_0) == 0:
num11 = num11_0
else:
num11 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[11]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 运作状态
num12 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[12]/td[2]/text()',
encoding="utf-8") # 基金信息最后更新时间
num13_0 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[13]/td[2]/text()',
encoding="utf-8") # 基金业协会特别提示
if len(num13_0) == 0:
num13 = num13_0
else:
num13 = tree.xpath('/html/body/div[3]/div/div[2]/div[1]/div[2]/table/tbody/tr[13]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8')
xian = tree.xpath('/html/body/div[3]/div/div[2]/div[2]/div[2]/table/tbody/tr[1]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 当月月报
# print(xian)
xian2 = tree.xpath('/html/body/div[3]/div/div[2]/div[2]/div[2]/table/tbody/tr[2]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 季报
xian3 = tree.xpath('/html/body/div[3]/div/div[2]/div[2]/div[2]/table/tbody/tr[3]/td[3]/text()',
encoding="utf-8") # 半年报
xian4 = tree.xpath('/html/body/div[3]/div/div[2]/div[2]/div[2]/table/tbody/tr[4]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 年报
xian5 = tree.xpath('/html/body/div[3]/div/div[2]/div[2]/div[2]/table/tbody/tr[5]/td[2]/text()',
encoding="utf-8")[0].replace('\r\n', '').replace(" ", "").replace("\t", "").encode(
'ISO-8859-1').decode('utf-8') # 账号开立率
# print(xian5)
row = (
num1, num2, num3, num4, num5, num6, num7, num8, num9, num10, num11, num12, num13, xian, xian2, xian3, xian4,
xian5)
rows.append(row)
# time.sleep(1) # 设置休眠
with codecs.open('基金.csv', 'wb', encoding='gbk', errors='ignore') as f:
writer = csv.writer(f)
writer.writerow(
["基金名称", "基金编号", "成立时间", "备案时间", "X1", "X2", "X3", "X4", "X5", "x6", 'X7', 'X8', 'X9'
, '当月月报', '季报', '半年报', '年报', '账号开立率'])
writer.writerows(rows)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
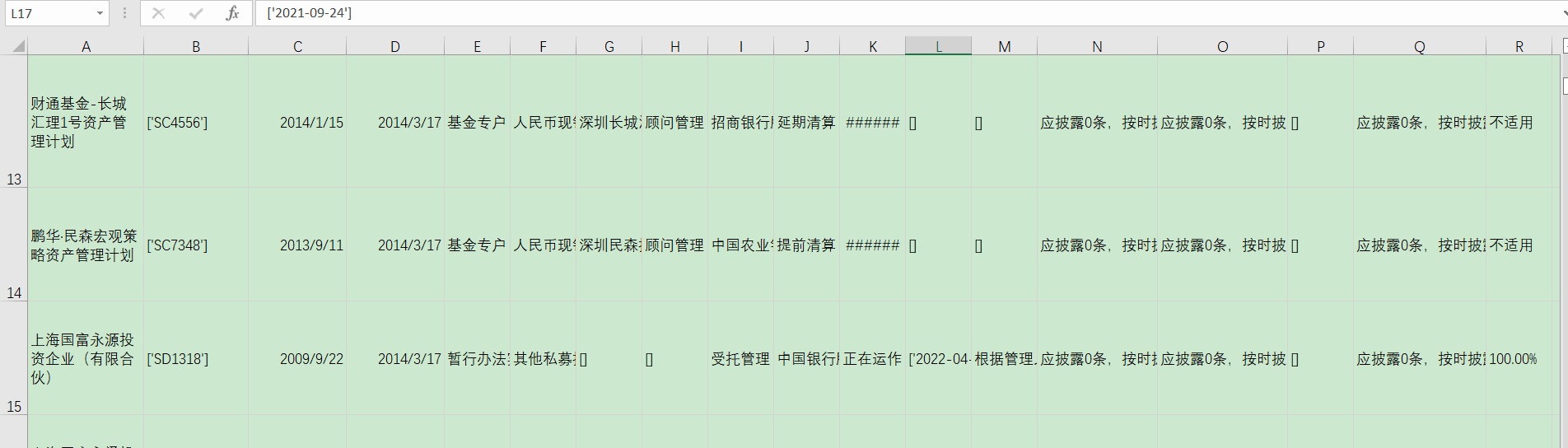
效果如下:
四、总结
设计有些欠妥,代码也有些冗余,但是已经写了一下午了,感兴趣的自行优化。
推荐刷题网站,一定要多练习题:牛客网
转载请注明转载来源,CSDN:川川菜鸟。联系我:点击查看
文章来源: chuanchuan.blog.csdn.net,作者:川川菜鸟,版权归原作者所有,如需转载,请联系作者。
原文链接:chuanchuan.blog.csdn.net/article/details/125063171

- 点赞
- 收藏
- 关注作者
评论(0)