头条系web RPC案例

【摘要】
以头条系某短视频(dy)web页面搜索为例,通过RPC的逻辑实现数据采集。
目前方案通用于头条系web页面。因为其当前产品大都基于XMLHttpRequest的send方法做一些校验,我们可以自启一个浏...
以头条系某短视频(dy)web页面搜索为例,通过RPC的逻辑实现数据采集。
目前方案通用于头条系web页面。因为其当前产品大都基于XMLHttpRequest的send方法做一些校验,我们可以自启一个浏览器去完成XMLHttpRequest请求,直接获取返回的responseText。
话虽如此,此方案仅是为了配合书中的教程供大家学习,并不代表是最优选择,主要是给大家提供一种思路和方法。
代码逻辑很简单,只有50行代码,有不懂的问题可私信或留言。
更多精彩内容:《爬虫逆向进阶实战》
调试分析
因受版权影响,我会避开关键词。
先找一下其发送逻辑,堆栈第一个点进去。
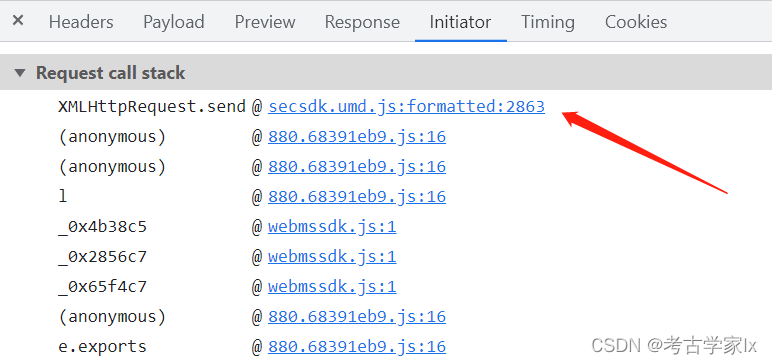
断点后调试,可看到t即是XMLHttpRequest。
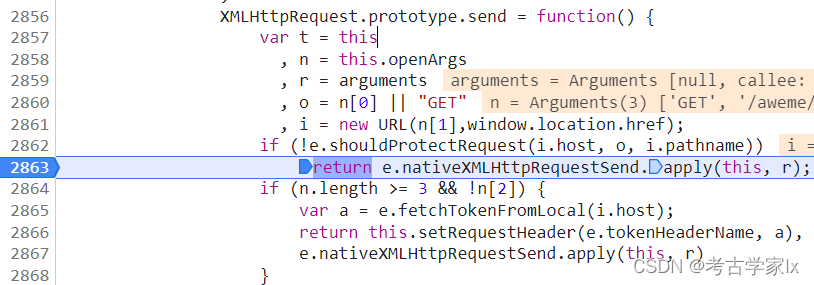
查看t对象。
文章来源: blog.csdn.net,作者:考古学家lx,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_43582101/article/details/125086670

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)