大数据物流项目:概述及Docker入门(一)

Logistics_Day01:项目概述及Docker入门

01-[理解]-客快物流大数据项目概述
大数据分析中,主要分析引擎:
- 1)、MapReduce 分析引擎,更多使用Hive编写SQL,底层转换为MR程序
- 2)、Spark 分析引擎,物流项目,主要使用Spark 分析引擎处理分析数据:离线分析和实时分析
- DataFrame/Dataset = RDD + Schema
- 离线分析:SparkSQL、实时分析:StructuredStreaming
- 3)、Flink 分析引擎

大数据项目:==业务数据量大(传统数据库RDBMS无法满足需求)和数据分析复杂性提高==。
课程安排如下所示:主要分为3个部分内容
- 1)、项目概述和环境准备(数据采集)
- 2)、数据实时ETL存储和离线报表与即席查询、快速检索
- 3)、OLAP分析,使用ClickHouse数据库存储和查询

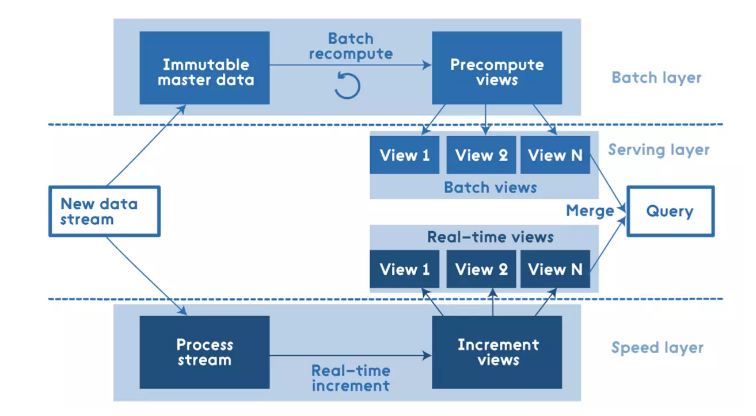
整个项目来说,属于Lambda架构项目,既有离线分析,又有实时分析,使用SparkSQL和Structured
- 1)、批处理层:
Batch Layer,离线分析- 2)、速度层:
Speed Layer,实时分析- 3)、服务层:
Server Lay,提供离线分析和实时分析结果数据,便于查询和使用
整个物流项目技术亮点:

02–[了解]-第1天课程内容提纲
主要讲解2个方面的内容:物流项目概述
- 1)、物流项目概述
- 项目整体介绍,比如项目背景、项目功能实现盈利(针对物流快递公司)等等
- 物流项目中,实时大屏展示
项目业务核心流程,物流快递行业发送快递流程项目逻辑架构项目数据流转图和核心业务剖析- ==项目中非功能新说明,开发周期,服务器配置,软件版本,技术选项等等==

03–[掌握]-项目整体介绍
在整个中,最后给大家展示:实时大屏统计分析,实时性要求不是很高,分钟基本延迟。

1)、行业背景介绍:
自从国内电商购物节开始以后,每年用户电商APP购买物品增加,快递数量指数级别增长。

- 2)、物流行业特点:属于复合型产业,实时产生大量的业务数据,需要关联性分析处理。

- 3)、项目背景介绍:基于上述诉求,需要将快递物流产生相关业务数据,存储到大数据平台引擎中,进行分析(离线报表和实时查询检索)。
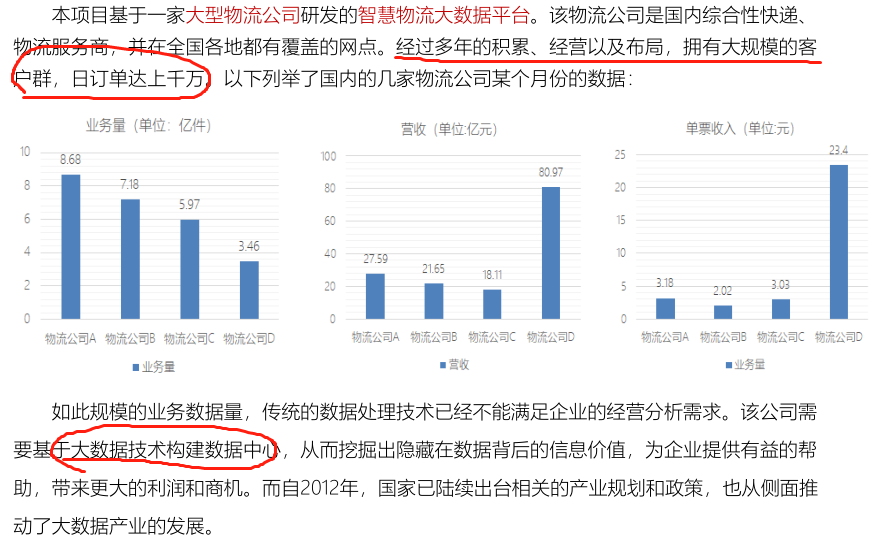
- 4)、物流大数据作用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RadClEeU-1625444773065)(/img/1615516690862.png)]
- 5)、物流大数据应用案例
- 传统物流行业报表分析,依然需要完成的,统计
- 大数据应用主要体现在==车货匹配、运输路线优化、库存预测、设备修理预测、供应链协同管理==等方面
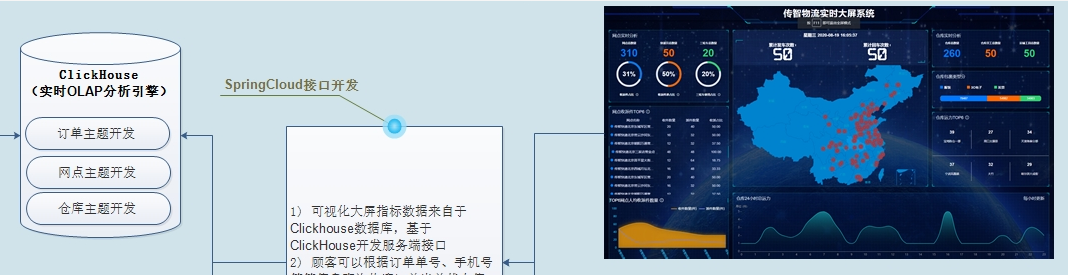
04–[理解]-物流实时大屏系统
从实时OLAP数据库
ClickHouse表中读取数据,大屏每隔10秒查询数据库表,将数据展示前端大屏,具体如下图所示:
1615517773800
针对实时大屏来说:
- 1)、大屏展示,如何做的??NodeJS和Vue
- 2)、数据实时查询,存储在哪里???ClickHouse数据库
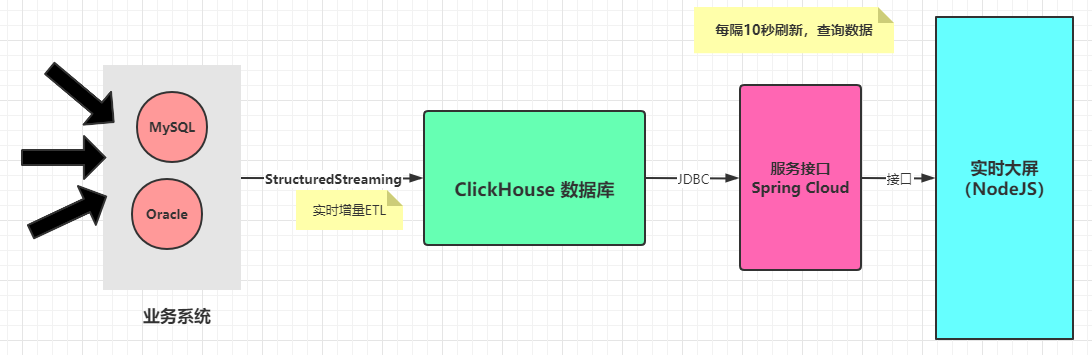
上述为整个实时大屏展示技术流程图,大家务必记清楚。
05–[理解]-项目核心业务流程
了解针对物流快递行业来说,业务流程是如何进行的:从客户A下单开始,一直到,客户B收到快件结束。
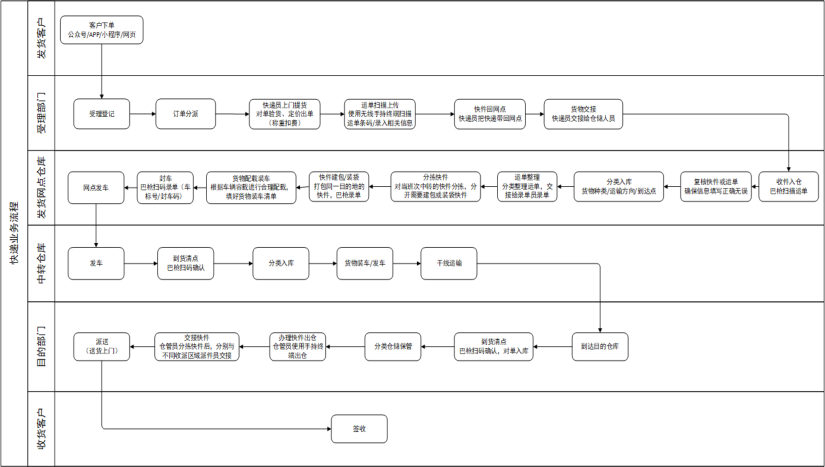
快递业务流程:
- 1)、发货客户:客户下单
- 2)、受理部分:快递员上门取货
- 3)、发货网点仓库:将快递放到网点仓库,其中需要分类处理,等到运输配送
- 4)、中转仓库:可选,只有不能直接送到,经过中转仓库,需要再次配送
- 5)、目的部门:快递经过运输,已经送达到目的地网点,分配给相应派送人员
- 6)、收货客户:收取快递。
06–[理解]-项目逻辑架构
接下来,看一下整个物流项目:逻辑技术架构图,项目中每个步骤使用什么技术,技术选项(为什么选这个技术框架)。

==即席查询,在大数据领域中,比较普遍需求,随时依据用户的需求,查询分析海量数据。==
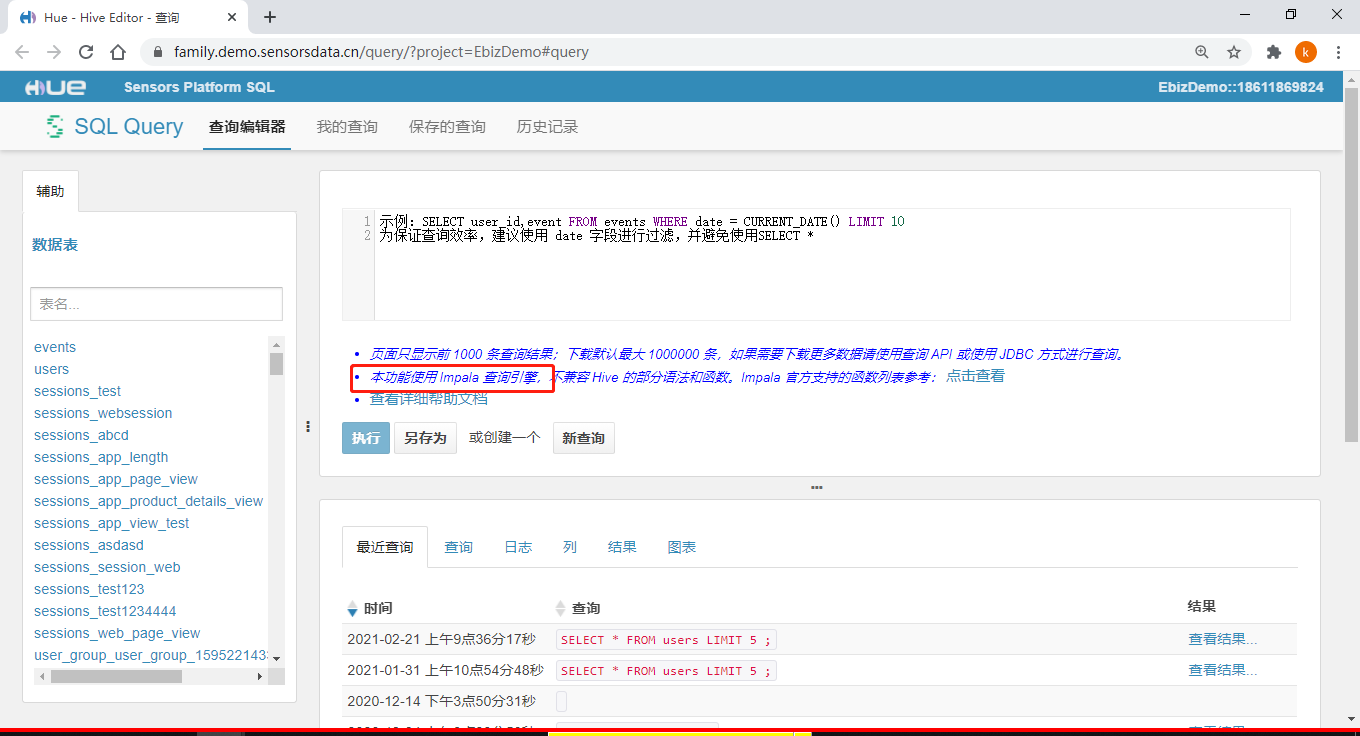
在神策数据产品中,用户自定义查询,就是所说的即席查询,底层使用Impala分析引擎。
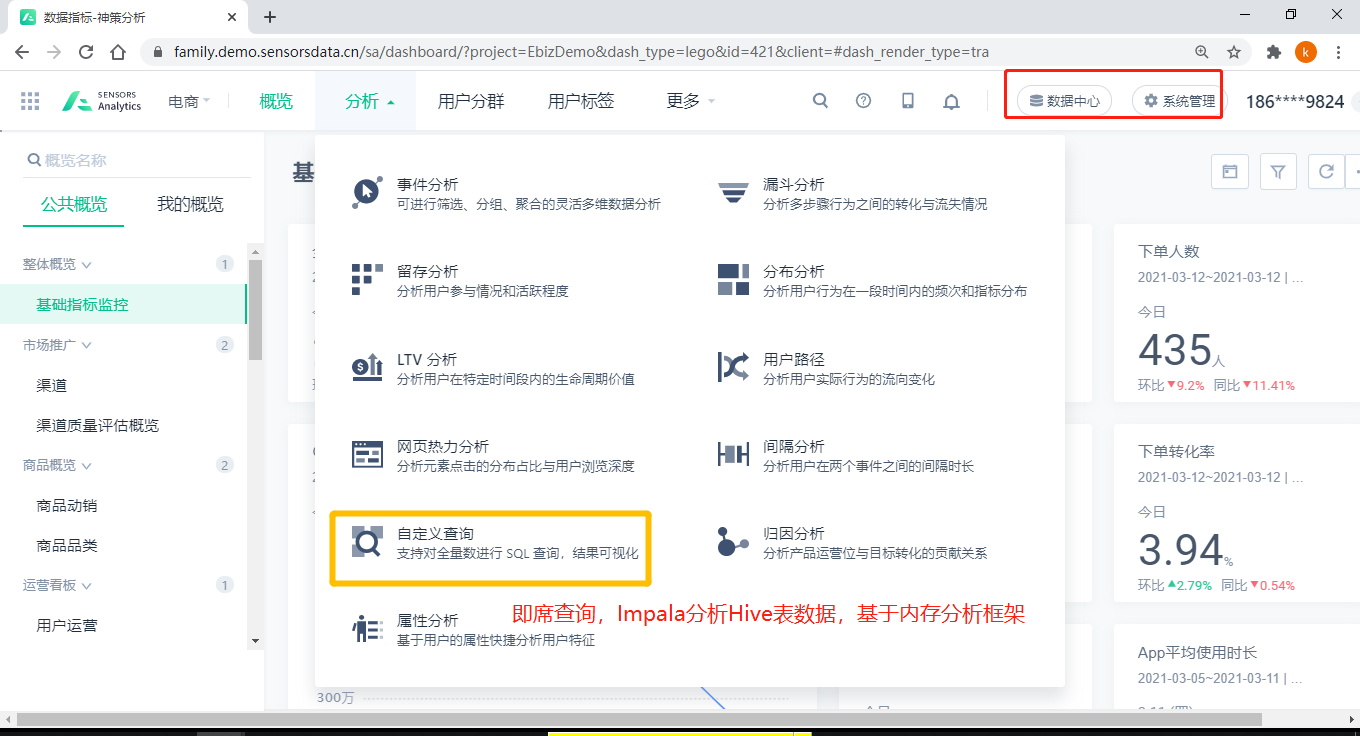
==思考==:为什么选择这些技术框架,原因是什么???
- 1)、异构数据源:表示业务数据存储到不同系统中,此处仅仅演示2个数据库

- 2)、数据采集平台:物流项目数据采集属于实时增量采集,类似Flume日志数据。

- 3)、数据存储平台

- 4)、数据计算平台:实时查询(Impala和StructuredStreaming、ES)和离线分析(SparkSQL)

- 5)、大数据平台应用
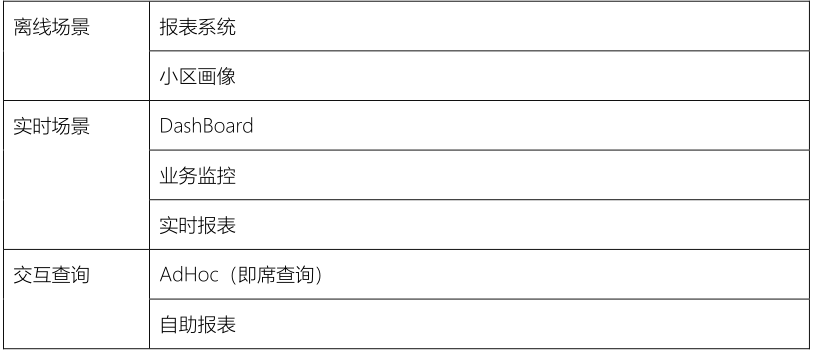
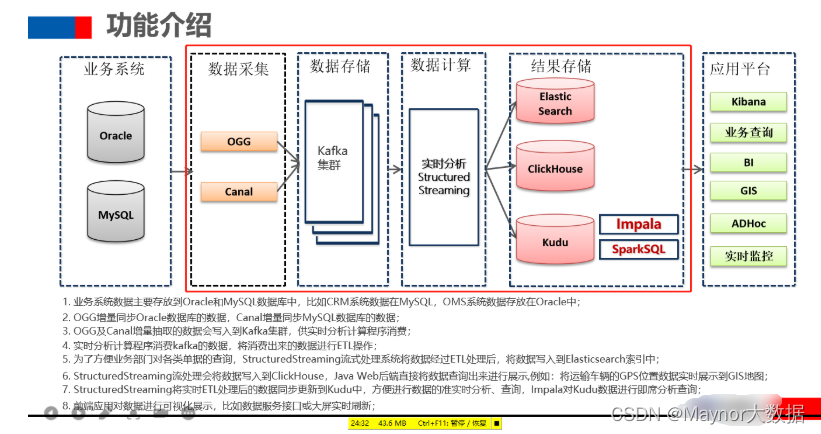
07–[掌握]-项目数据流转及核心业务
任何一个大数据项目,首先数据流转图:项目数据从哪里来的,存储到哪里去,进行什么应用分析。
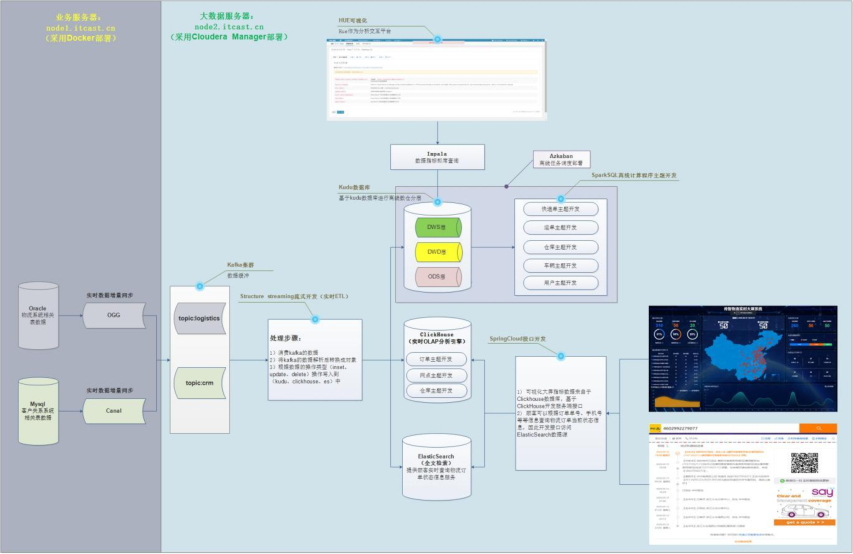
- 1)、业务服务器(存储业务数据)
- 物流项目来说,需要将多个业务系统数据,实时采集到大数据框架Kafka中
- ==物流系统Logistics业务数据,存储Oracle数据库==
- ==CRM客户关系管理系统业务数据,存储MySQL数据库==
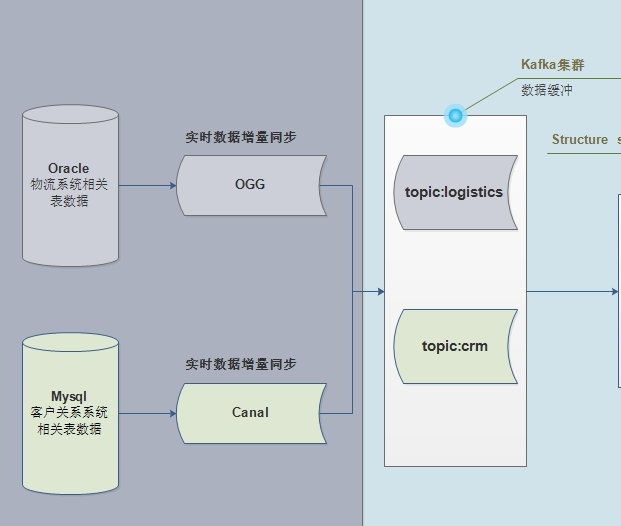
2)、大数据服务器(存储业务数据、分析数据和调度执行)
- 第一部分功能、离线报表和即席查询
- 将业务数据实时增量存储数据库:Kudu(类比HBase数据库)
- SparkSQL分析Kudu表数据,进行离线报表统计
Impala查询Kudu表数据,进行即席查询,一对CP组合
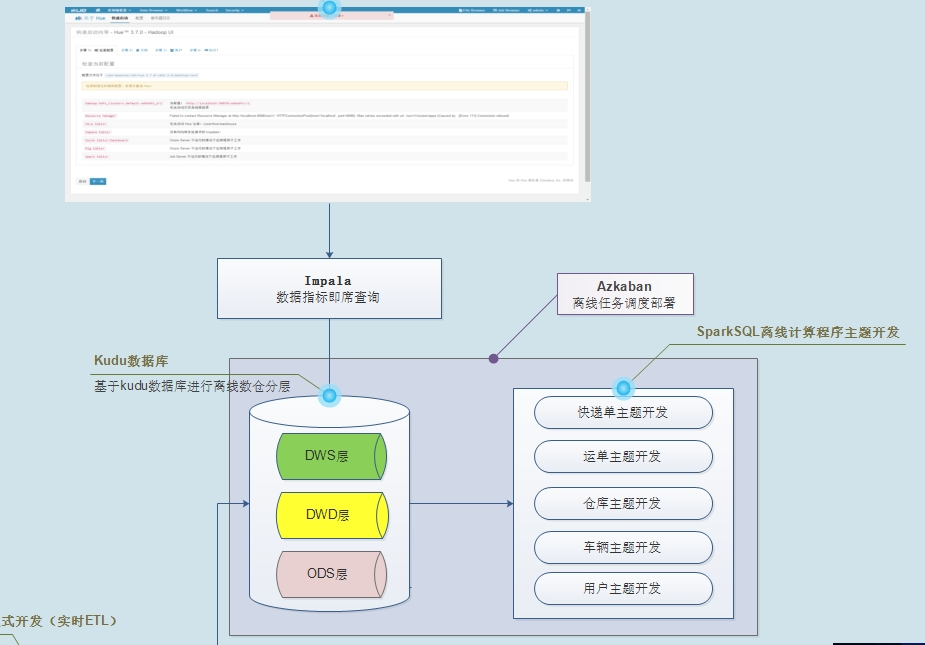
- 第二部分功能:实时大屏展示
- 将业务数据存储到ClickHouse表中,需要实时查询 ,快速的查询(分组,聚合和排序)
- 通过服务接口对外提供数据查询功能及数据导出。
- 第三部分功能:物流信息检索
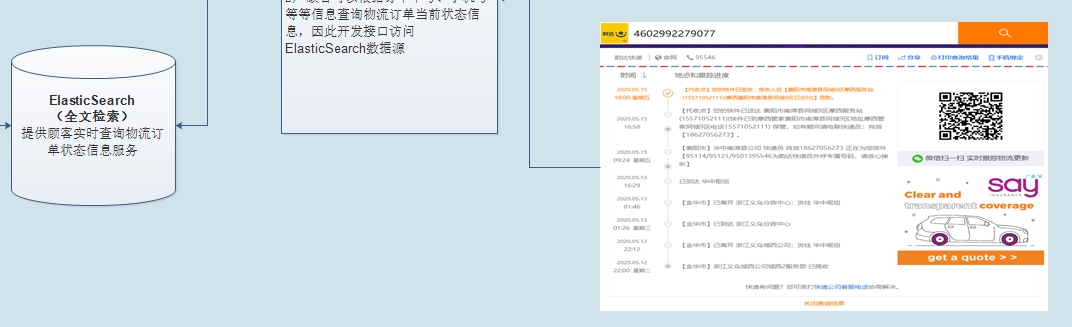
- 将核心业务数据(快递单数据和运单数据)存储至Elasticsearch索引中,可以快速检索物流
3)、如何将业务数据实时ETL存储到Es、CK或Kudu中呢??
- 编写
结构化流应用程序,实时从Kafka消费数据,进行ETL转换后,存储到各种存储引擎。val spark: SparkSession spark.readStream.format("kafka").option().load streamDF.writeStream.format("es/clickhouse/kudu").option().start
08–[理解]-项目技术选型及软件版本
针对每个项目来说,要清楚一点,技术框架选择(为什么选择)。
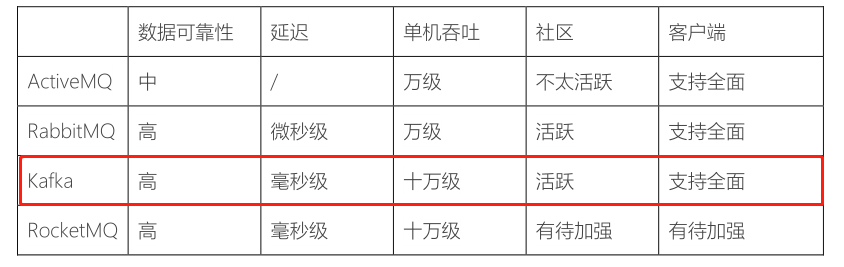
1)、流式处理平台:==采用Kafka作为消息传输中间介质==
2)、分布式计算平台:==分布式计算采用Spark生态==
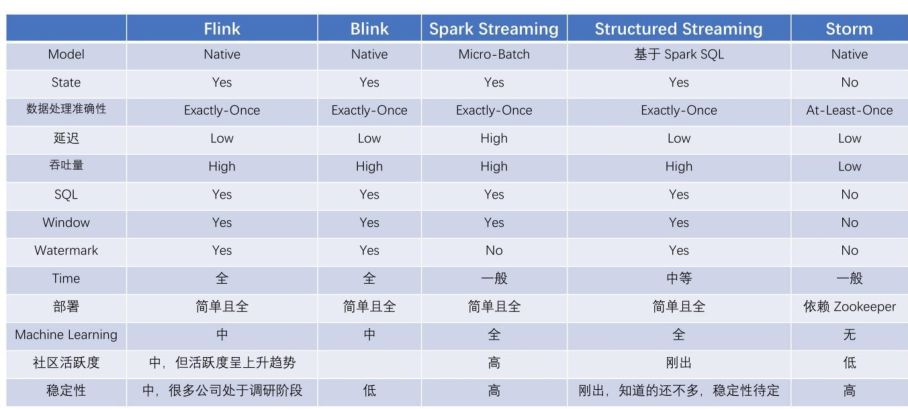
本项目使用Structured Streaming开发实时部分,同时离线计算使用到SparkSQL,而Spark的生态相对于Flink更加成熟,因此采用Spark开发。
为什么不使用SparkStreaming进行实时数据ETL转换存储呢??而是使用StructuredStreaming...
3)、海量数据存储
ETL后的数据存储到Kudu中,供实时、准实时查询、分析

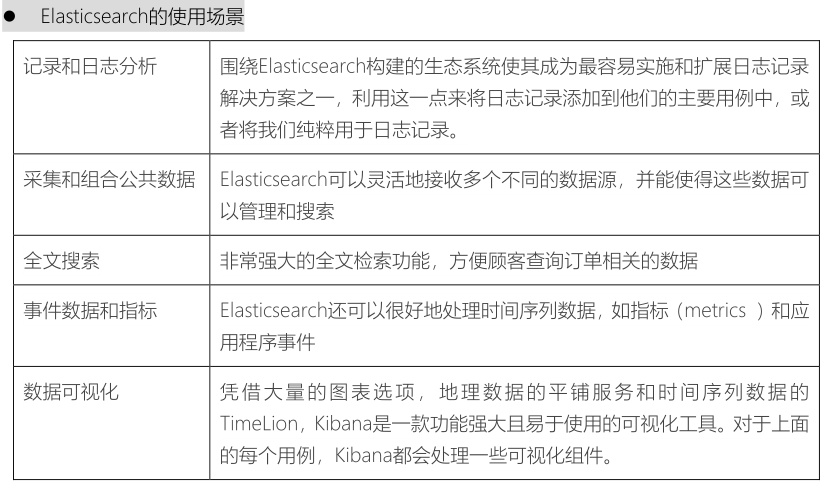
- Elastic Search作为单据数据的存储介质,==供顾客查询订单信息==
ClickHouse作为实时数据的指标计算存储数据库,进行大屏展示数据查询和数据接口
- ClickHosue数据库目前国内使用最为广泛之一OLAP分析数据库,诞生5年时间
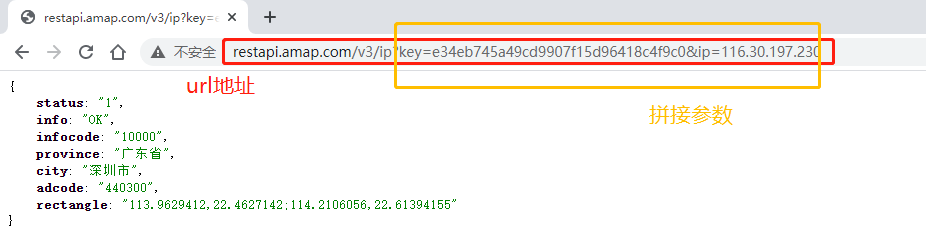
- 接口:往往就是URL地址,拼接参数数据,进行HTTP请求,将数据以JSON格式返回。
- 比如:获取用户访问网站IP地址,解析IP地址,获取省份和城市信息,需要请求高德地主APL
http://restapi.amap.com/v3/ip?key=e34eb745a49cd9907f15d96418c4f9c0&ip=116.30.197.230
框架软件版本:主要基于
CDH 6.2.1版本(版本较新),将来编写简历时,此版本不可用==使用CM安装CDH,采集单机部署,提供
node2.itcast.cn虚拟机上,全部安装完毕,无需到操作。==

新框架:Kudu和Impala都属于CDH产品,由于都是Cloudera公司开发的框架。
09–[理解]-项目非功能描述
在实际项目开发中,除了依据业务开发应用(实时ETL数据转换、报表分析、即席查询等)之外,比如集群规模、业务数据量、开发团队人员配置等等。
- 1)、框架版本选型

- 2)、服务器选型
不差钱,金融相关公司,使用物理机最好。

- 3)、集群规模
数据量:物流项目来说,核心数据【快递单】和【运单】等相关数据

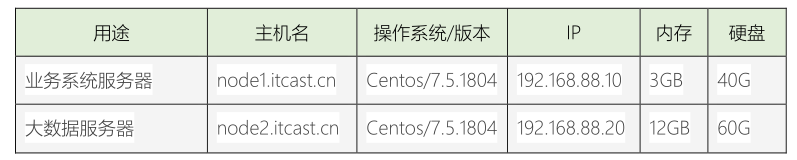
- 4)、集群资源如下图所示
在实际项目,服务器来说,系统盘(安装操作系统)和数据盘(存储数据)时分开的,

- 5)、人员配置参考

- 6)、开发周期

10–[了解]-技术亮点及服务器规划
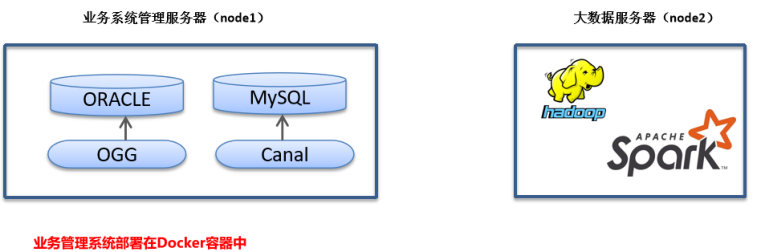
在项目该物流项目时,有哪些技术亮点:技术框架属于目前大数据技术中比较新的框架,使用较多的

客快物流大数据项目学习中,需要2台服务器(虚拟机)分别构建服务器环境,拓扑图如下:
因服务器资源有限,该项目采用两台服务器进行演示学习,每台服务器配置如下:
需要在windows映射配置文件,配置上述主机名和IP地址隐射:
C:\Windows\System32\drivers\etc\hosts


- 点赞
- 收藏
- 关注作者
评论(0)