咱用容器完成一分钟自动化部署 香!【玩转华为云】

本文的主要内容有:
- 一 CCE是有啥优势呢
- 二 容器引擎应用在哪
- 三 资源准备好
- 四 来完成自动化部署
一 🙈 CCE有啥优势呢
1.1 如何定义
彦祖你好,你听过云容器引擎没有?了解之后觉得这服务老厉害了,因为它要深度整合高性能的计算(ECS/BMS)、网络(VPC/EIP/ELB)、存储(EVS/OBS/SFS)等基础服务,并能够支持GPU、NPU、ARM、FPGA等异构计算架构,实现高可用,多区域容灾等技术帮你简化部署。管理构建K8s集群,这太香了吧!

2.2 优势在哪里
首先简单易用
- 通过WEB界面一键创建Kubernetes集群,支持管理虚拟机节点或裸金属节点,支持虚拟机与物理机混用场景
- 一站式自动化部署和运维容器应用,整个生命周期都在容器服务内一站式完成
- 通过Web界面轻松实现集群节点和工作负载的扩容和缩容,自由组合策略以应对多变的突发浪涌
- 通过Web界面一键完成Kubernetes集群的升级
- 深度集成应用服务网格和Helm标准模板,真正实现开箱即用
其次是高性能
- 基于在计算、网络、存储、异构等方面多年的行业技术积累,提供业界领先的高性能云容器引擎,支撑您业务的高并发、大规模场景
- 采用高性能裸金属NUMA架构和高速IB网卡,AI计算性能提升3-5倍以上
最后是安全可靠
- 高可靠:集群控制面支持3 Master HA高可用,3个Master节点可以处于不同可用区,保障您的业务高可用。集群内节点和工作负载支持跨可用区(AZ)部署,帮助您轻松构建多活业务架构,保证业务系统在主机故障、机房中断、自然灾害等情况下可持续运行,获得生产环境的高稳定性,实现业务系统零中断

- 高安全:私有集群,完全由用户掌控,并深度整合IAM和Kubernetes RBAC能力,支持用户在界面为子用户设置不同的RBAC权限。

其次是开放兼容
- 云容器引擎在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性;
- 云容器引擎基于业界主流的Kubernetes实现,完全兼容Kubernetes/Docker社区原生版本,与社区最新版本保持紧密同步,完全兼容Kubernetes API和Kubectl;
云容器引擎与自己建Kubernetes集群的差别在哪

二 😘 容器引擎应用在哪
2.1 应用一:基础容器的管理上面
CCE集群支持管理X86资源池和ARM资源池,方便你的创建Kubernetes集群、部署您的容器化应用,以及方便的管理和维护;

其中的价值
通过容器化改造,使应用部署资源成本降低,提升应用的部署效率和升级效率,可以实现升级时业务不中断以及统一的自动化运维

2.2 应用二:高性能调度上面
2.2.1 场景1:多类型作业混合部署
随着各行各业的发展,涌现出越来越多的领域框架来支持业务的发展,这些框架都在相应的业务领域有着不可替代的作用,例如Spark,Tensorflow,Flink等。在业务复杂性能不断增加的情况下,单一的领域框架很难应对现在复杂的业务场景,因此现在普遍使用多种框架达成业务目标。但随着各个领域框架集群的不断扩大,以及单个业务的波动性,各个子集群的资源浪费比较严重,越来越多的用户希望通过统一调度系统来解决资源共享的问题;

Volcano在Kubernetes之上抽象了一个批量计算的通用基础层,向下弥补Kubernetes调度能力的不足,向上提供灵活通用的Job抽象。Volcano通过提供多任务模板功能实现了利用Volcano Job描述多种作业类型(Tensorflow、Spark、MPI、PyTorch等),并通过Volcano统一调度系统实现多种作业混合部署,解决集群资源共享问题;
2.2.2 场景2:多队列场景调度优化
用户在使用集群资源的时候通常会涉及到资源隔离与资源共享,Kubernetes中没有队列的支持,所以它在多个用户或多个部门共享一个机器时无法做资源共享。但不管在HPC还是大数据领域中,通过队列进行资源共享都是基本的需求;
在通过队列做资源共享时,我们提供了多种机制。可以为队列设置weight值,集群通过计算该队列weight值占所有weight总和的比例来给队列划分资源;另外也可以为队列设置资源的Capability值,来确定该队列能够使用的资源上限;

例如上图中,通过这两个队列去共享整个集群的资源,一个队列获得40%的资源,另一个队列获得60%的资源,这样可以把两个不同的队列映射到不同的部门或者是不同的项目中。并且在一个队列里如果有多余的空闲资源,可以把这些空闲资源分配给另外一个队列里面的作业去使用;
2.2.3 场景3:多种高级调度策略
当用户向Kubernetes申请容器所需的计算资源(如CPU、Memory、GPU等)时,调度器负责挑选出满足各项规格要求的节点来部署这些容器。通常,满足各项要求的节点并非唯一,且水位(节点已有负载)各不相同,不同的分配方式最终得到的分配率存在差异,因此,调度器的一项核心任务就是以最终资源利用率最优的目标从众多候选机器中挑出最合适的节点。
下图为Volcano scheduler调度流程,首先将API server中的Pod、PodGroup信息加载到scheduler cache中。Scheduler周期被称为session,每个scheduler周期会经历OpenSession,调用Action,CloseSession三个阶段。其中OpenSession阶段加载用户配置的scheduler plugin中实现的调度策略;调用Action阶段逐一调用配置的action以及在OpenSession阶段加载的调度策略;CloseSession为清理阶段;
- Volcano scheduler通过插件方式提供了多种调度Action(例如enqueue,allocate,preempt,reclaim,backfill)以及调度策略(例如gang,priority,drf,proportion,binpack等),用户可以根据实际业务需求进行配置。通过实现Scheduler提供的接口也可以方便灵活的进行定制化开发;
2.3.4 场景4:高精度资源调度
Volcano 在支持AI,大数据等作业的时候提供了高精度的资源调度策略,例如在深度学习场景下计算效率非常重要。以TensorFlow计算为例,配置“ps”和“worker”之间的亲和性,以及“ps”与“ps”之间的反亲和性,可使“ps”和“worker”尽量调度到同一台节点上,从而提升“ps”和“worker”之间进行网络和数据交互的效率,进而提升计算效率。然而Kubernetes默认调度器在调度Pod过程中,仅会检查Pod与现有集群下所有已经处于运行状态Pod的亲和性和反亲和性配置是否冲突或吻合,并不会考虑接下来可能会调度的Pod造成的影响;
Volcano提供的Task-topology算法是一种根据Job内task之间亲和性和反亲和性配置计算task优先级和Node优先级的算法。通过在Job内配置task之间的亲和性和反亲和性策略,并使用task-topology算法,可优先将具有亲和性配置的task调度到同一个节点上,将具有反亲和性配置的Pod调度到不同的节点上。同样是处理亲和性和反亲和性配置对Pod调度的影响,task-topology算法与Kubernetes默认调度器处理的不同点在于,task-topology将待调度的Pods作为一个整体进行亲和性和反亲和性考虑,在批量调度Pod时,考虑未调度Pod之间的亲和性和反亲和性影响,并通过优先级施加到Pod的调度进程中;
- 价值
面向AI计算的容器服务,采用高性能GPU计算实例,并支持多容器共享GPU资源,在AI计算性能上比通用方案提升3~5倍以上,并大幅降低了AI计算的成本,同时帮助数据工程师在集群上轻松部署计算应用,您无需关心复杂的部署运维,专注核心业务,快速实现从0到1快速上线。
- 优势
CCE通过集成Volcano,在高性能计算、大数据、AI等领域有如下优势:
- 多种类型作业混合部署:支持AI、大数据、HPC作业类型混合部署
- 多队列场景调度优化:支持多队列用于多租资源共享与分组规划,支持优先级与分时复用
- 多种高级调度策略:支持gang-scheduling、公平调度、资源抢占、GPU拓扑等高级调度策略
- 多任务模板:支持单一Job多任务模板定义,打破Kubernetes原生资源束缚,Volcano Job描述多种作业类型(Tensorflow、MPI、PyTorch等)
- 作业扩展插件配置:在提交作业、创建Pod等多个阶段,Controller支持配置插件用来执行自定义的环境准备和清理的工作,比如常见的MPI作业,在提交前就需要配置SSH插件,用来完成Pod资源的SSH信息配置
建议搭配使用
GPU加速云服务器 + 弹性负载均衡ELB + 对象存储服务OBS;

三 ⛳ 资源准备好先
3.1 创建安全组、VPC
鼠标移动到【实验操作桌面】浏览器页面中左侧菜单栏,点击“服务列表” ->“网络” > “虚拟私有云VPC”,进入网络控制台, 在左侧菜单栏中点击“访问控制”->“安全组”进入安全组页面,点击“创建安全组”,参数如下图所示:
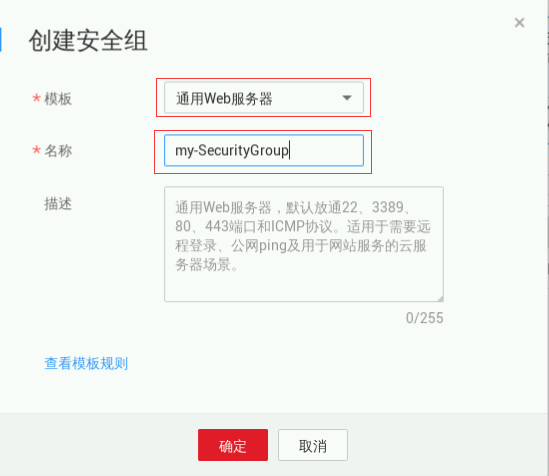
点击“确定”完成创建,如下图所示

点击“my-SecurityGroup”进入安全组设置页面,点击“入方向规则”,添加一条规则:
① 优先级:1
② 策略:允许
③ 协议端口:全部放通
其他配置默认,点击“确定”,配置如下图所示:
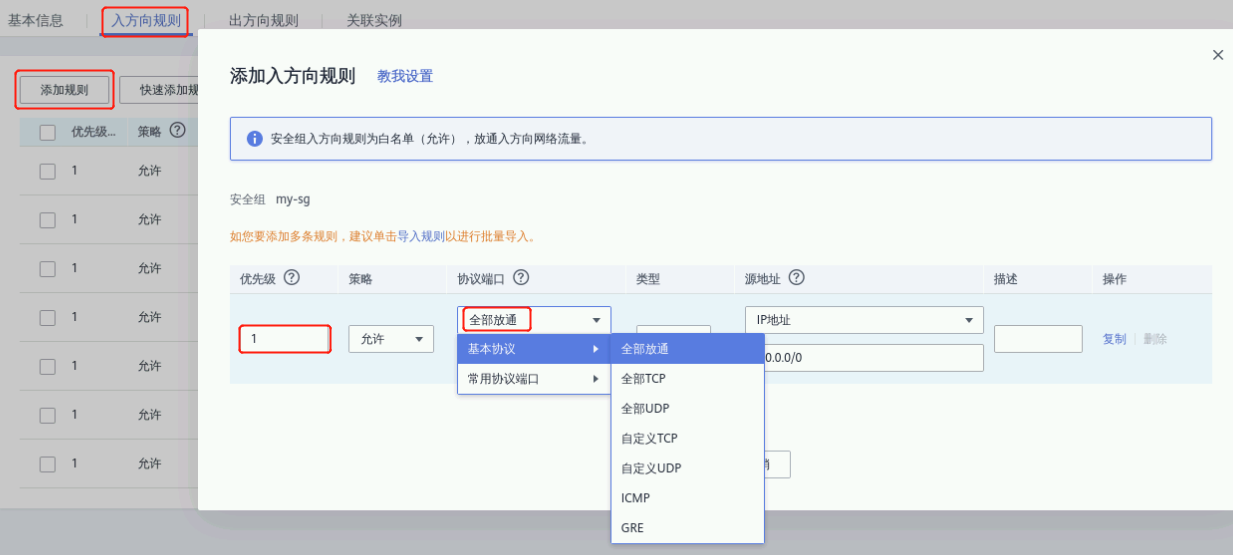
点击“确定”完成入方向规则添加
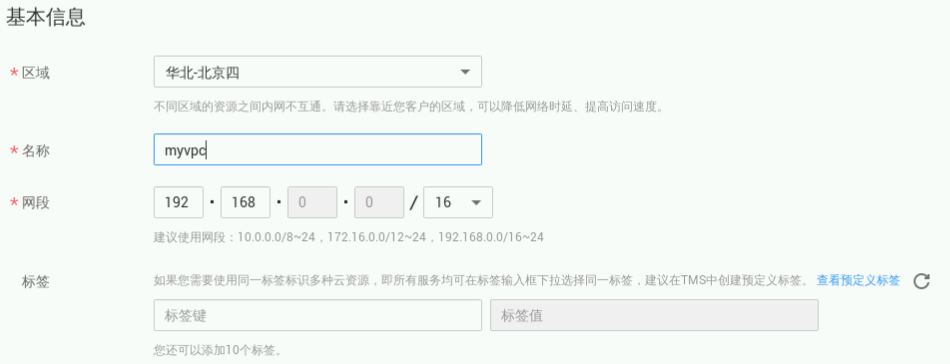
点击左侧菜单“虚拟私有云”-> “创建虚拟私有云”进入创建虚拟私有云页面,如下图所示:

基本信息:
① 当前区域:华北-北京四
② 名称:myvpc
③ 网段:192.168.0.0/16
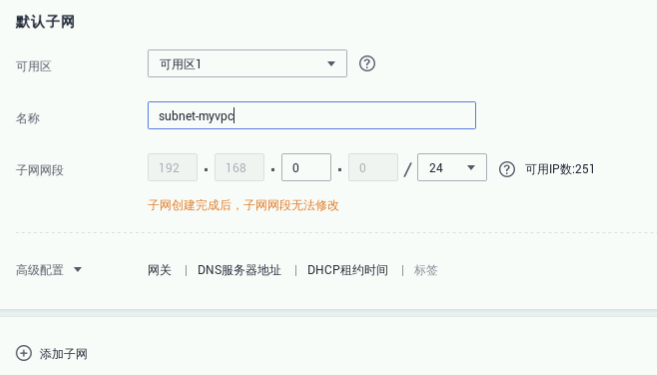
子网配置:
① 可用分区:可用区1
② 子网名称:subnet-myvpc
③ 子网网段:192.168.0.0/24
④ 高级配置:默认配置
单击“立即创建”
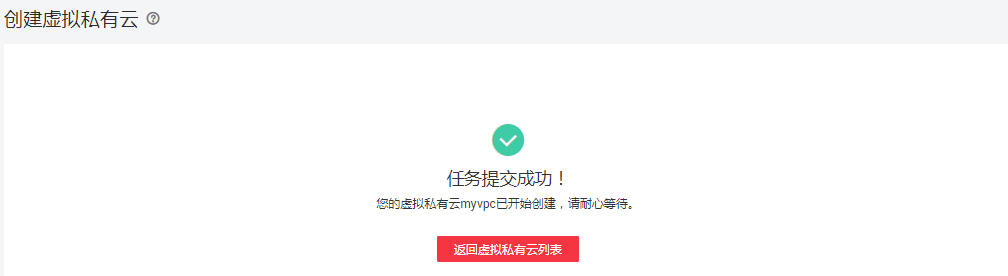
点击“返回虚拟私有云列表”界面,进入自己创建的虚拟私有云界面,可查看到已创建好的虚拟私有云myvpc
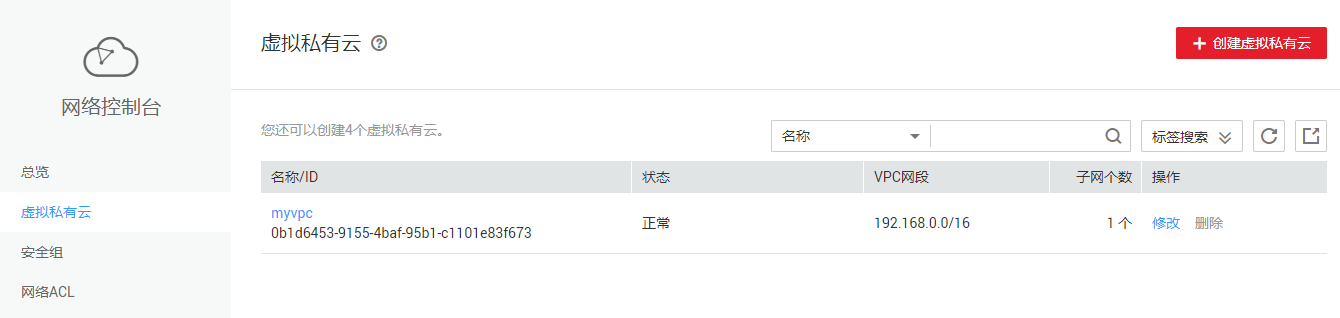
3.2 创建项目
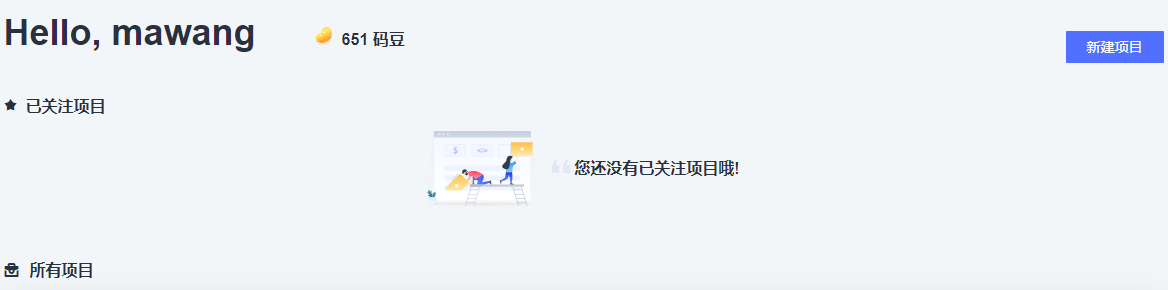
鼠标移动到浏览器页面中左侧菜单栏,点击 "服务列表" -> "软件开发服务DevCloud" -> "项目管理" 进入项目列表页面,如下图所示

点击“立即使用”,进入项目创建页面,如下图所示
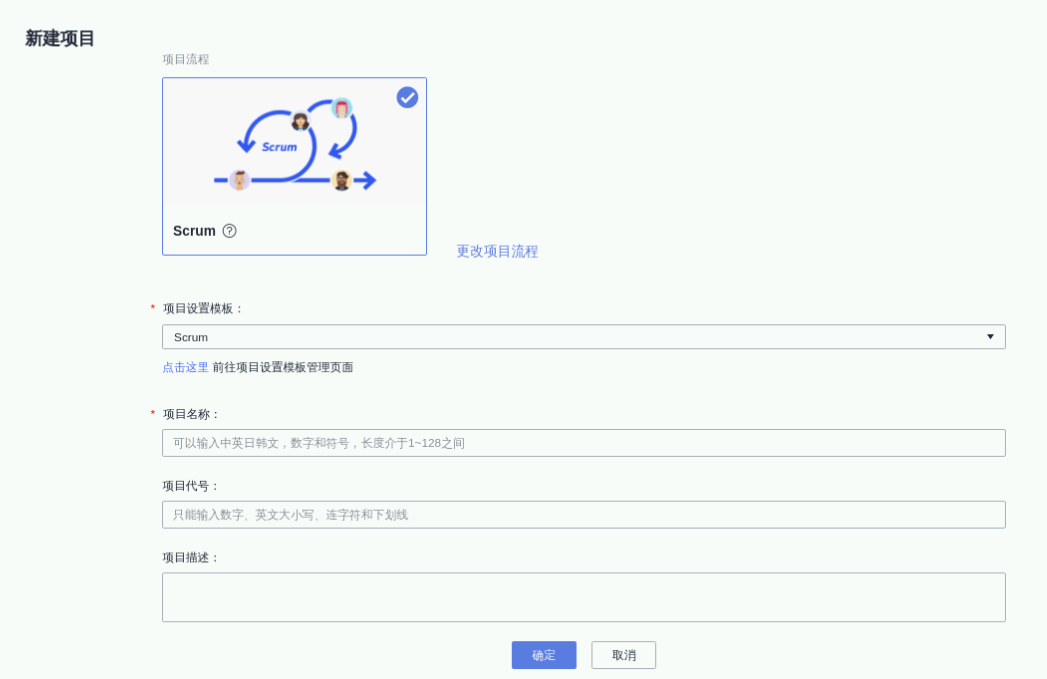
点击“新建项目”,选择空白项目“Scrum”,在新建项目弹窗中,设置项目名称为“demo”,输入项目信息,点击“确定”,如下图所示
创建完成跳转如下图页面

3.3 如何创建集群呢
鼠标移动到【实验操作桌面】浏览器页面中左侧菜单栏,点击"服务列表”-> "容器服务”-> "云容器引擎CCE”进入CCE总览页面
点击【CCE集群】选项卡中的【创建】,进入CCE集群创建页面
① 计费模式:按需计费
② 区域:华北-北京四
③ 集群名称:test
④ 版本:v1.17.17
⑤ 集群管理规模:50节点
⑥ 控制节点数:1、勾选“我已知晓如下约束”

① 虚拟私有云:myvpc (1.1步骤创建的)
② 所在子网:subnet-myvpc (1.1步骤创建的)
③ 网络模型:容器隧道网络
④ 容器网段:172.16.0.0/16
⑤ 服务网段:使用默认网段
⑥ 鉴权方式:RBAC
参数设置如下图所示


设置完成点击“下一步 创建节点”。
创建节点:现在添加,设置参数参考如下:
① 计费方式:按需计费
② 当前区域:华北-北京四
③ 可用区:默认

① 节点类型:虚拟机节点
② 节点名称:test-node
③ 节点规格:通用型|sn3.large.2|2核|4GB
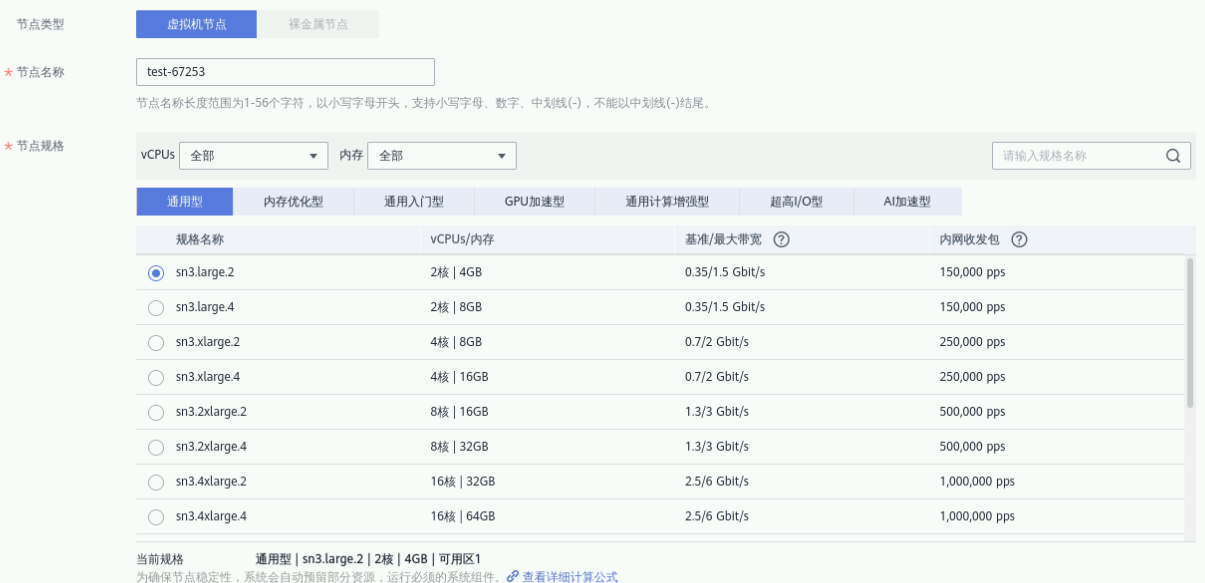
① 操作系统:公共镜像 EulerOS 2.5
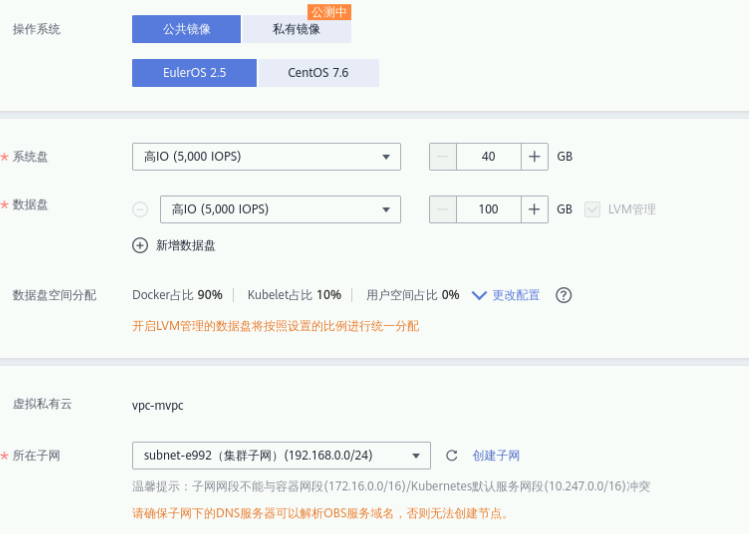
② 系统盘:高IO、40GB
③ 数据盘:高IO、100GB
④ 虚拟私有云:myvpc(1.1步骤创建的)
⑤ 所在子网:subnet-myvpc (1.1步骤创建的)
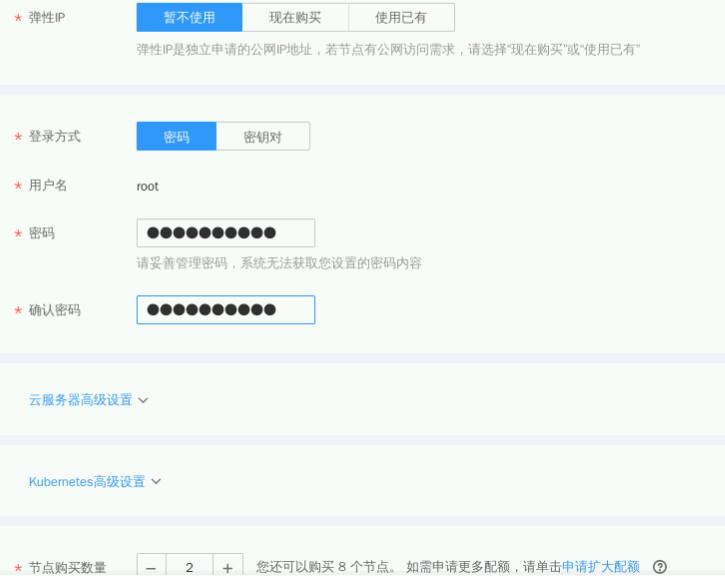
① 弹性IP:暂不使用
② 登录方式:密码
③ 用户名:root
④ 密码:自定义,如:HRHe7moV$F
⑤ 节点购买数量:2
点击”下一步 安装插件”安装插件选择保持默认,点击“下一步 配置确认”,勾选协议,确认规格无误后点击”提交”,如下图所示:

创建过程大概6-10min,点击”返回集群管理”,可查看到已创建的集群和已添加的节点;
3.4 如何获取应用镜像呢
切到【实验操作桌面】,双击“Xfce终端”打开Terminal分别执行以下命令下载应用镜像
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/devcloud-cce-deploy/nginx.tarwget https://sandbox-experiment-resource-north-4.obs.myhuaweicloud.com/devcloud-cce-deploy/nginx-1.1.tar下载成功如下图这样

- 切回浏览器,"服务列表" -> "容器" -> "容器镜像服务SWR"进入容器镜像管理列表页,说明:第一次进入容器镜像管理页面需要点击“同意授权”

- 在容器镜像服务页面中,点击【我的镜像】进入我的镜像页面,进入页面后,点击右上角【页面上传】,说明:若提示没有组织数据,点击弹出页“创建组织”,填入组织名称,点击“确定”,组织名称一般为手册上方“账号名”小写,如:sandbox-voyager063

选择组织(实验为您分配的账号名),点击“选择镜像文件”选择下载的镜像文件,如下面这样

选中文件点击”open”,分别点击“上传”,等待应用镜像上传成功,如下图这样

关闭弹窗,刷新“我的镜像”列表页即可看到已上传的镜像,如下面这样

至此镜像上传成功完成,下个任务走起
3.5 怎么创建弹性负载均衡ELB
鼠标移动到云桌面浏览器页面中左侧菜单栏,点击 "服务列表" -> "网络" -> "弹性负载均衡ELB" 进入负载均衡列表页,如下图这样
进入负载均衡器页面后,点击右上角【购买弹性负载均衡】进入购买配置页面,在购买配置页面中,点击【共享型负载均衡】选项卡中的【选择】后,进入配置页,参数设置参考如下
① 实例规格类型:性能共享型
② 区域:华北-北京四
③ 网络类型:公网
④ 所属VPC:myvpc(选择已创建的)
⑤ 子网:默认 (自动分配IPv4地址)
⑥ 私有IP地址:默认
⑦ 弹性公网IP:新创建
⑧ 弹性公网IP类型:全动态BGP
⑨ 计费方式:按带宽计费
⑩ 宽带:5Mbit/s
⑪ 名称:elb-docker
其他参数默认就好了哈
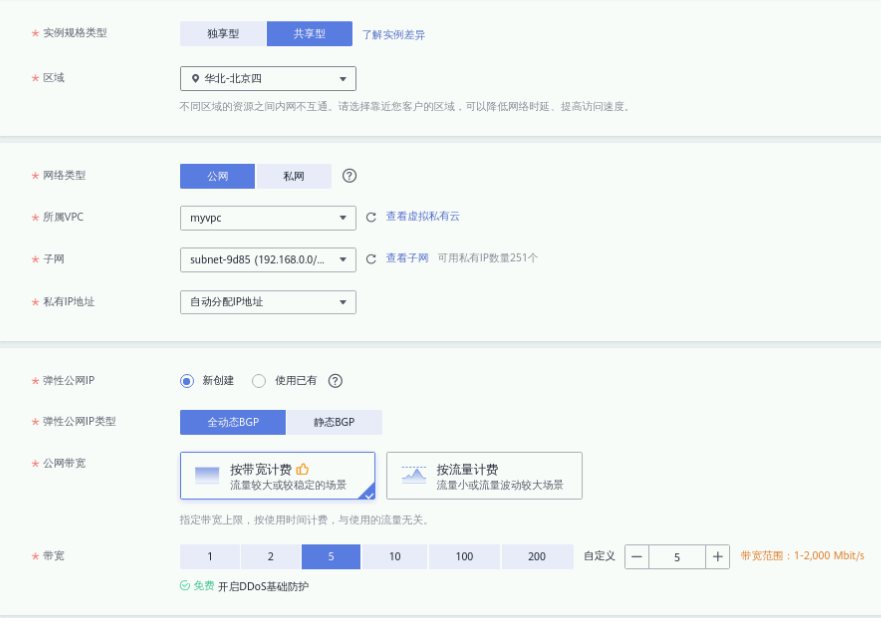

点击“立即购买”,进行规格确认,最后再点击“提交”
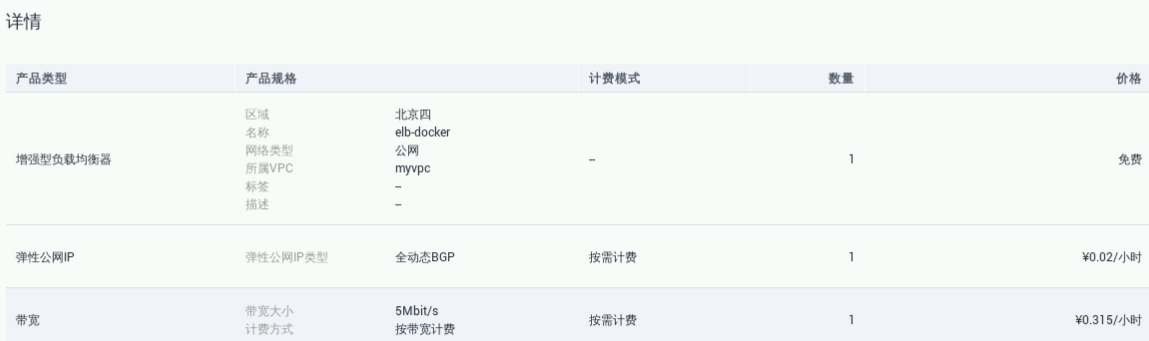
返回弹性负载均衡列表后,可以查看到已创建好的弹性负载均衡ELB。

完成以上资源准备后,根据以下步骤进行容器自动化部署的操作;
四 🚀 来完成自动化部署
4.1 在CCE集群上创建工作负载
切换至【实验操作桌面】的浏览器界面,鼠标移动到浏览器页面中左侧菜单栏,点击"服务列表”-> "容器服务”-> "云容器引擎CCE”进入CCE总览页面
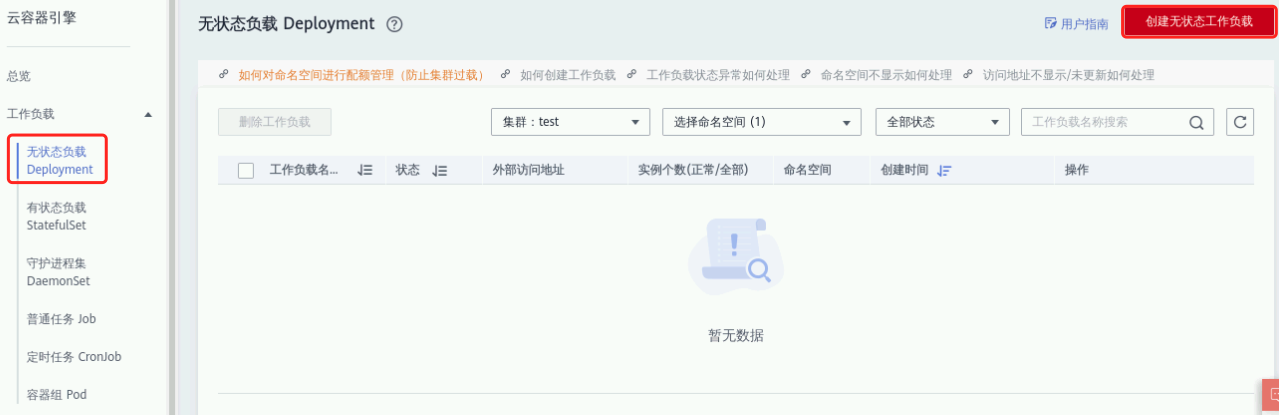
在左侧菜单栏选择“工作负载”-> “无状态负载 Deployment”,点击右上角“创建无状态工作负载”;
① 工作负载名称:自定义,如workload;
② 集群名称:选择1.3步骤创建的集群;
③ 命名空间:default;
④ 实例数量:1;
其他默认,如下图这样
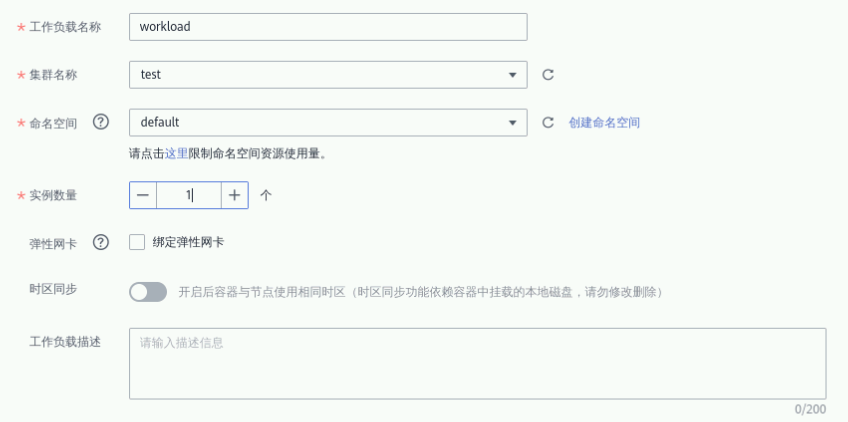
点击“下一步:容器设置”,点击“添加容器”。在弹出的窗口选择“我的镜像” -> “nginx”,版本选择“v1.0”

点击“确定”,根据以下提示进行参数配置,如下面这样
镜像:v1.0
容器名称:container-1
特权容器:关
容器规格:
CPU配额:默认
内存配额:全选,大小均为256MB
其他参数默认
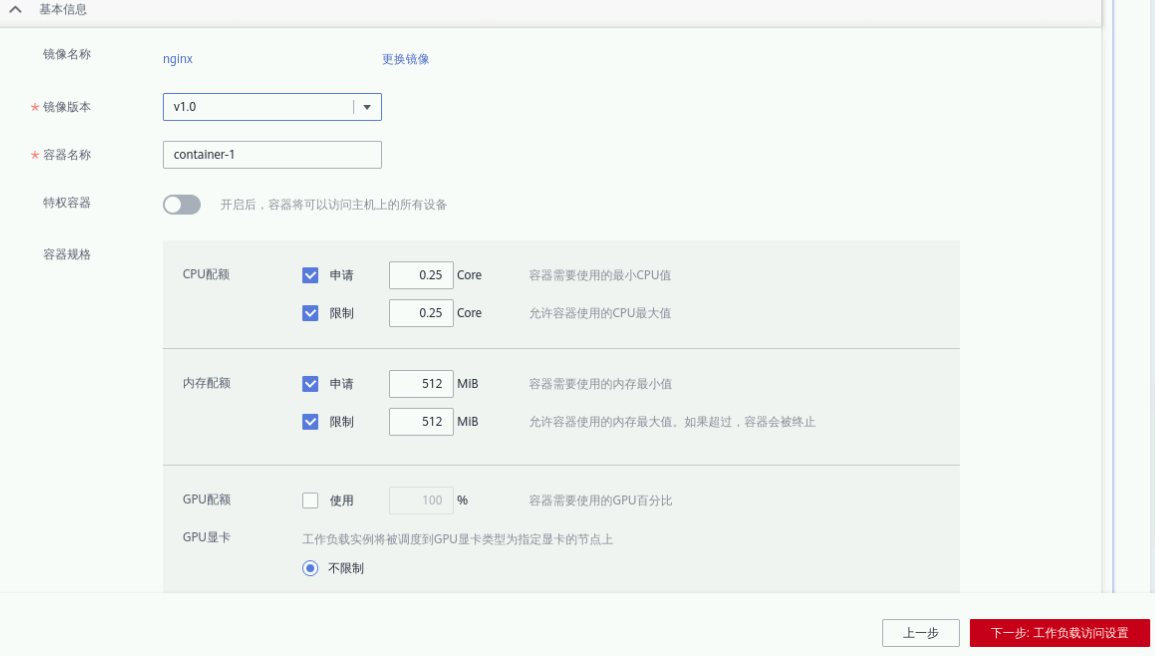
确认无误后点击“下一步:工作负载访问设置”,点击“添加服务”在弹出页面填写参数
① 访问类型:负载均衡(Loadbalance);
② Service名称:自定义,默认即可;
③ 服务亲和:集群级别;
负载均衡配置:
④ 负载均衡:共享型 - 公网 - 选择1.5步骤创建的ELB名称;
⑤ 分配策略类型:加权轮询算法;
⑥ 会话保持:不启用;
⑦ 健康检查:关闭;
⑧ 端口配置: 协议(TCP), 容器端口(80),访问端口(8082)
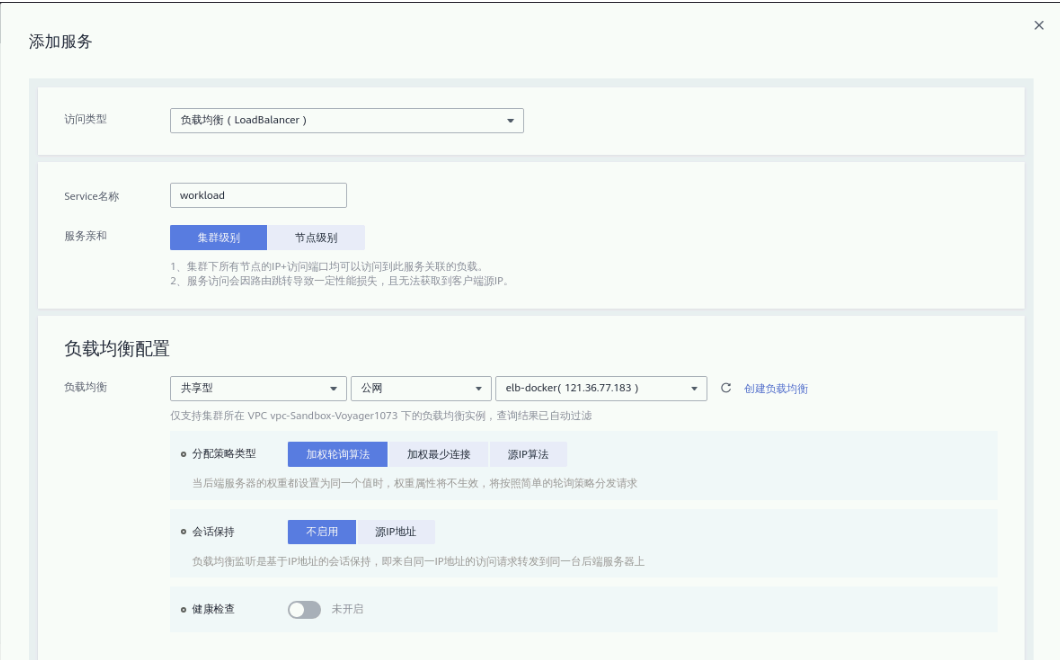

点击“确定”。点击“下一步:高级设置”进入高级设置页面
升级方式选择“滚动升级”,其他参数默认
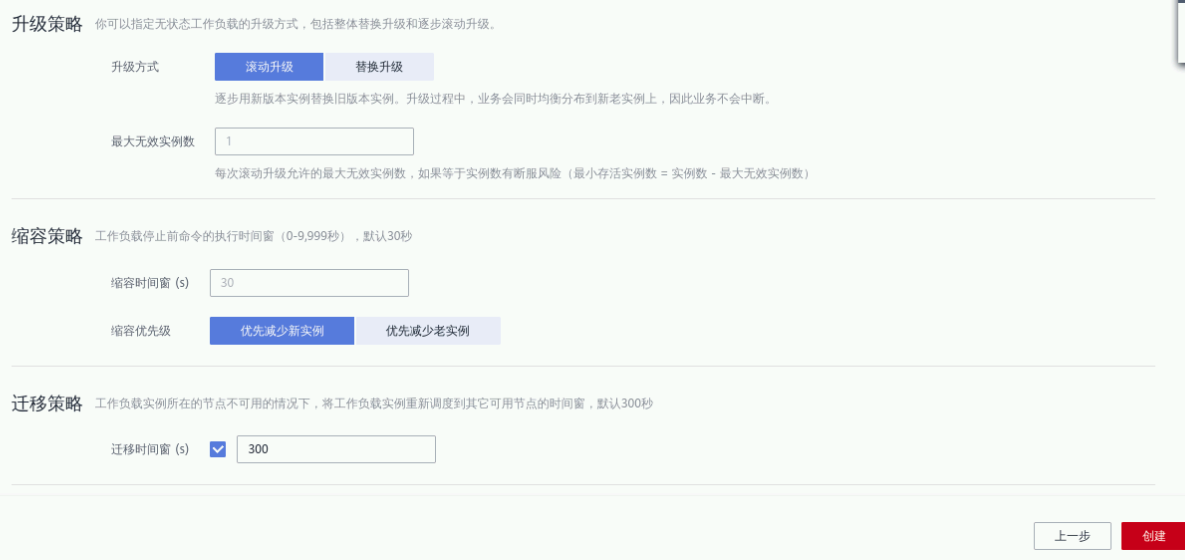
点击“创建”,完成负载任务的创建。返回无状态负载列表页,等待负载部署完成,然后点击外部访问地址即可访问应用;

打开成功页面如下图,说明镜像已经成功部署

4.2 完成部署任务创建
鼠标移动到【实验操作桌面】浏览器页面中左侧菜单栏,点击“服务列表”->“软件开发服务DevCloud”->“部署 CloudDeploy”,进入“软件开发云”控制台后,在部署界面下,点击“立即使用”;
进入DevCloud平台部署首页,点击“新建任务”,如面这样子
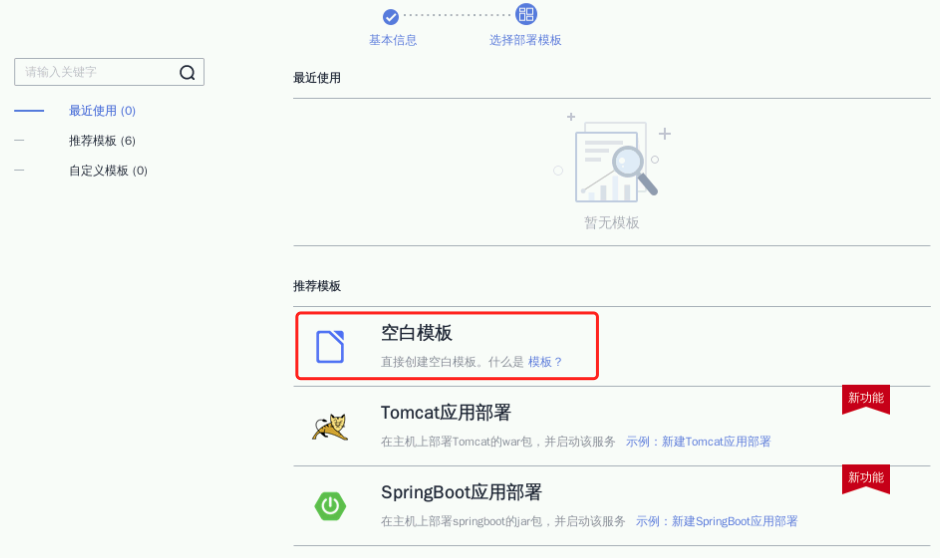
选择“空白模板”,点击“下一步”,选择“容器类” -> “Kubernetes部署”
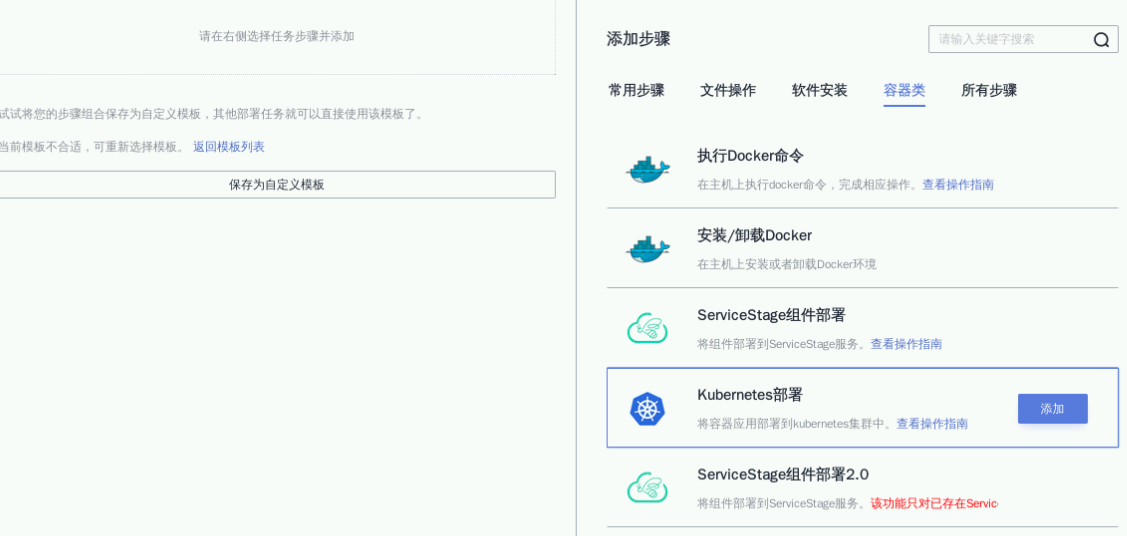
4.3 部署并执行
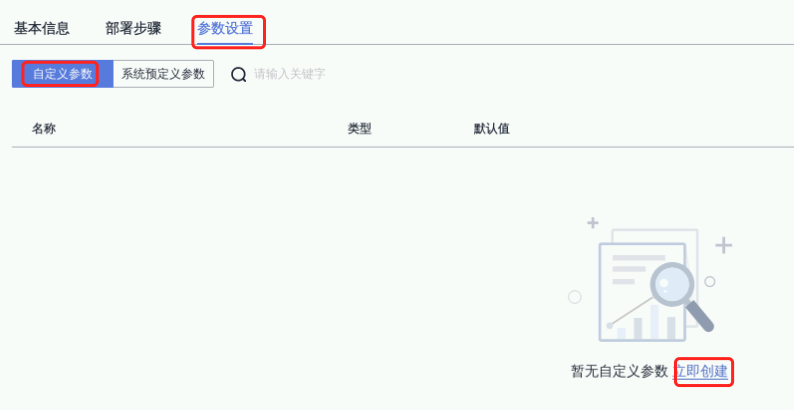
选择“参数设置”->“自定义参数”,点击“立即创建”,参数如下
① 名称:image_tag;
② 默认值:v1.1;
③ 运行时设置:打开;
其他参数默认就行了哈

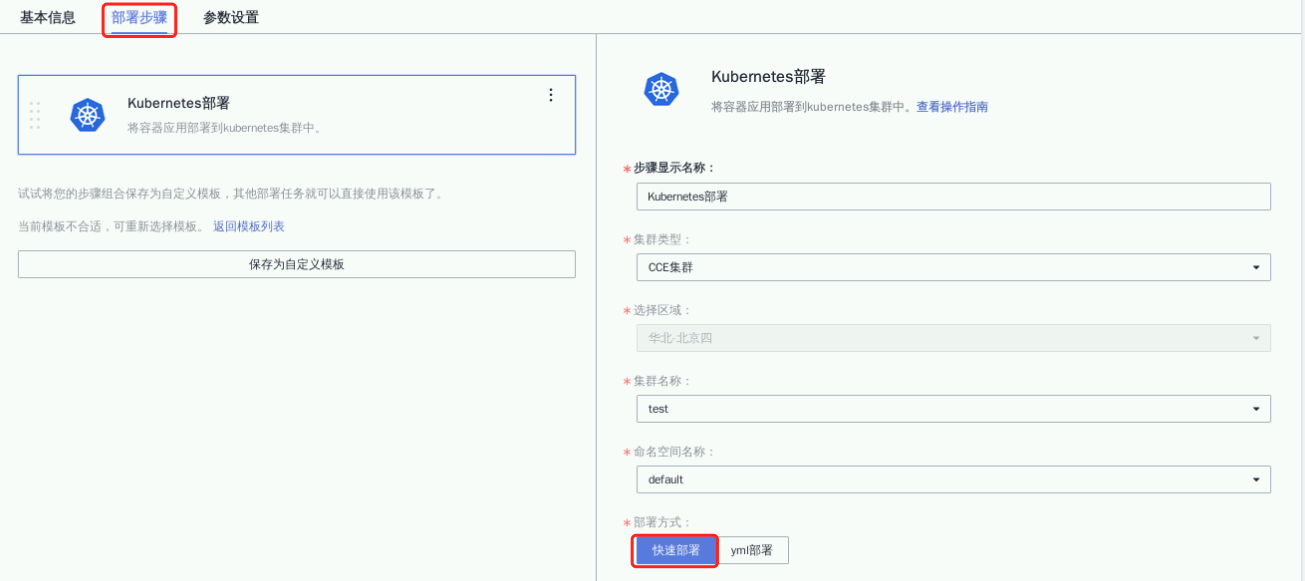
点击“部署步骤”选择参数如下
① 步骤显示名称:默认;
② 集群类型:CCE集群;
③ 集群名称:1.3步骤创建的CCE集群名称;
④ 命名空间名称:default;
⑤ 部署方式:快速部署;
⑥ 工作负载名称:2.1步骤创建测工作负载名称;
⑦ 容器名称:默认(container-0)
⑧ 镜像版本:下拉输入“${” 搜索,选择“image_tag”;
其他参数默认就行了哈

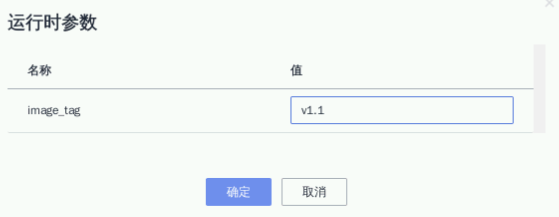
确认无误后,然后点击“保存并执行”在弹出框选择“v1.1”版本,然后点“确定”运行部署任务,如下面这样
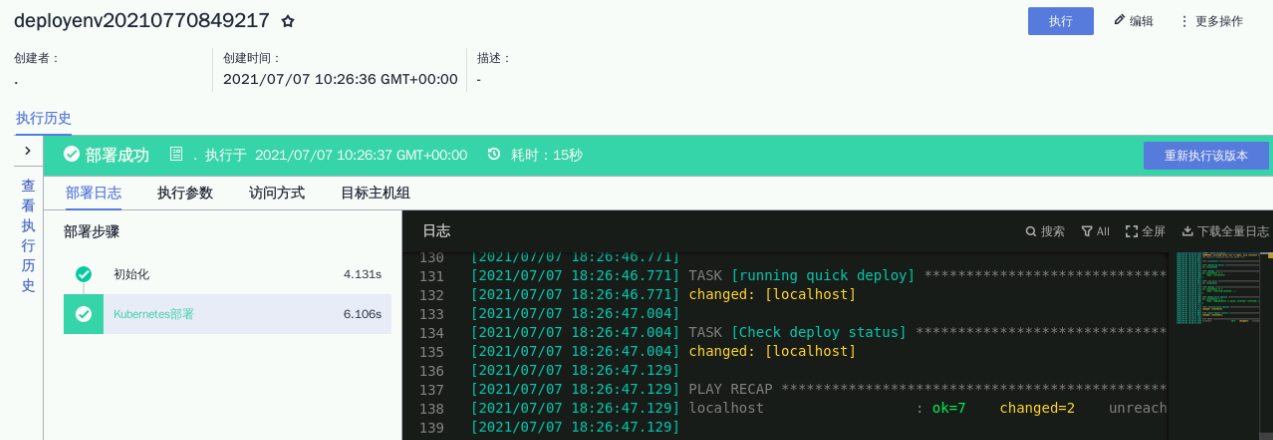
部署任务执行成功如下面这样
4.4 然后我们访问应用
鼠标移到【实验操作桌面】浏览器页面中左侧菜单栏,点击“服务列表”->“容器服务”->“云容器引擎CCE”进入CCE总览页面,点击“工作负载”->“无状态负载 Deployment”然后点击外部访问地址即可访问应用,如下面这样子


打开成功面如上图这样子哈,说明咱们镜像已经成功升级部署了哦,总算整完了先人板板的

- 点赞
- 收藏
- 关注作者
评论(0)