机器学习之算法案例公共自行车使用量预测

【摘要】 公共自行车使用量预测公共自行车低碳、环保、健康,并且解决了交通中“最后一公里”的痛点,在全国各个城市越来越受欢迎。本练习赛的数据取自于两个城市某街道上的几处公共自行车停车桩。我们希望根据时间、天气等信息,预测出该街区在一小时内的被借取的公共自行车的数量。train.csv 训练集,文件大小 273kbtest.csv 预测集, 文件大小 179kb公共自行车使用量预测训练集中共有10000...
公共自行车使用量预测
公共自行车低碳、环保、健康,并且解决了交通中“最后一公里”的
痛点,在全国各个城市越来越受欢迎。本练习赛的数据取自于两个城市某
街道上的几处公共自行车停车桩。我们希望根据时间、天气等信息,预测
出该街区在一小时内的被借取的公共自行车的数量。
train.csv 训练集,文件大小 273kb
test.csv 预测集, 文件大小 179kb
公共自行车使用量预测
训练集中共有10000条样本,预测集中有7000条样本。
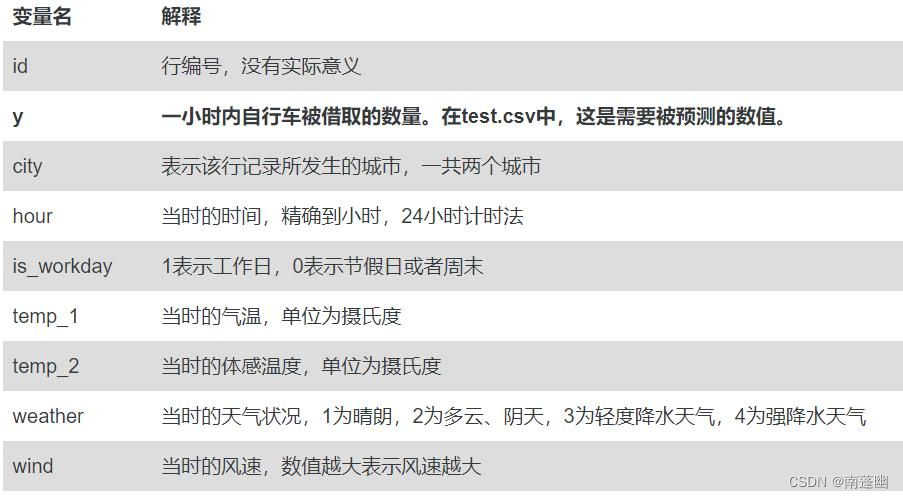
代码实现
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error,r2_score
train = pd.read_csv('train.csv') #读取数据
test = pd.read_csv('test.csv')
train = train.drop('id',axis=1) #删除无关的数据 id列
test = test.drop('id',axis=1)
train_x = train.iloc[:,train.columns != 'y'] #从数据集中取出训练的x
train_y = train.iloc[:,train.columns == 'y'] #从数据集中取出训练的y
train_y = np.array(train_y).flatten() #将y展平
std = StandardScaler() #对数据进行标准化
train_x = std.fit_transform(train_x)
test_x = std.transform(test)
svr = SVR() #选择模型
svr.fit(train_x,train_y) #训练
ms = mean_squared_error(svr.predict(train_x),train_y) #进行模型评估
print("在训练集上的均方误差是:",ms)
r2 = r2_score(svr.predict(train_x),train_y)
print("在训练集上的r2值是:",r2)
test_y = svr.predict(test_x) #在测试集上对数据进行预测
print(test_y)
结果


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)