【人工智能】机器学习之暴力调参案例

【摘要】 暴力调参案例 首先引入所需库 编码问题显示 获取数据 自动调参 选择算法调参 可视化 代码整合: 结果: 暴力调参案例使用的数据集为from sklearn.datasets import fetch_20newsgroups因为在线下载慢,可以提前下载保存到 首先引入所需库import numpy as npimport pandas as pddefaultencoding = 'ut...
暴力调参案例
使用的数据集为
from sklearn.datasets import fetch_20newsgroups
因为在线下载慢,可以提前下载保存到

首先引入所需库
import numpy as np
import pandas as pd
defaultencoding = 'utf-8'
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import GridSearchCV
from sklearn.feature_selection import SelectKBest,chi2
import sklearn.metrics as metrics
from sklearn.datasets import fetch_20newsgroups
import sys
编码问题显示
if sys.getdefaultencoding() != defaultencoding:
reload(sys)
sys.setdefaultencoding(defaultencoding)
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
如果报错的话可以改为
import importlib,sys
if sys.getdefaultencoding() != defaultencoding:
importlib.reload(sys)
sys.setdefaultencoding(defaultencoding)
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
用来正常显示中文
mpl.rcParams[‘font.sans-serif’]=[u’simHei’]
用来正常正负号
mpl.rcParams[‘axes.unicode_minus’]=False
获取数据
#data_home="./datas/"下载的新闻的保存地址subset='train'表示从训练集获取新闻categories获取哪些种类的新闻
datas=fetch_20newsgroups(data_home="./datas/",subset='train',categories=['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc'])
datas_test=fetch_20newsgroups(data_home="./datas/",subset='test',categories=['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc'])
train_x=datas.data#获取新闻X
train_y=datas.target#获取新闻Y
test_x=datas_test.data#获取测试集的x
test_y=datas_test.target#获取测试集的y
自动调参
import time
def setParam(algo,name):
gridSearch = GridSearchCV(algo,param_grid=[],cv=5)
m=0
if hasattr(algo,"alpha"):
n=np.logspace(-2,9,10)
gridSearch.set_params(param_grid={"alpha":n})
m=10
if hasattr(algo,"max_depth"):
depth=[2,7,10,14,20,30]
gridSearch.set_params(param_grid={"max_depth":depth})
m=len(depth)
if hasattr(algo,"n_neighbors"):
neighbors=[2,7,10]
gridSearch.set_params(param_grid={"n_neighbors":neighbors})
m=len(neighbors)
t1=time.time()
gridSearch.fit(train_x,train_y)
test_y_hat=gridSearch.predict(test_x)
train_y_hat=gridSearch.predict(train_x)
t2=time.time()-t1
print(name, gridSearch.best_estimator_)
train_error=1-metrics.accuracy_score(train_y,train_y_hat)
test_error=1-metrics.accuracy_score(test_y,test_y_hat)
return name,t2/5*m,train_error,test_error
选择算法调参
朴素贝叶斯,随机森林,KNN
algorithm=[("mnb",MultinomialNB()),("random",RandomForestClassifier()),("knn",KNeighborsClassifier())]
for name,algo in algorithm:
result=setParam(algo,name)
results.append(result)
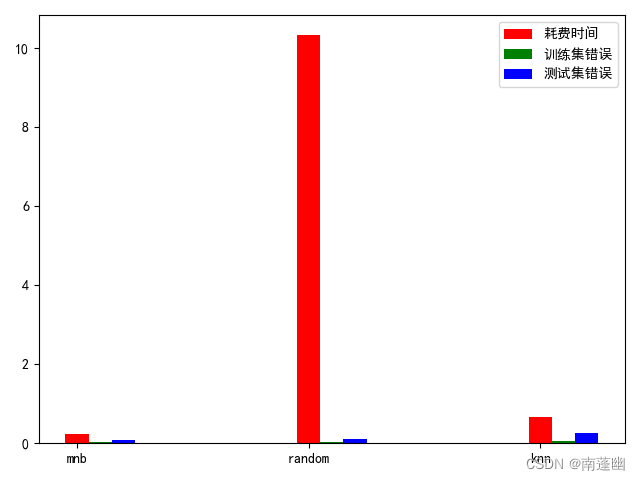
可视化
#把名称,花费时间,训练错误率,测试错误率分别存到单个数组
names,times,train_err,test_err=[[x[i] for x in results] for i in range(0,4)]
axes=plt.axes()
axes.bar(np.arange(len(names)),times,color="red",label="耗费时间",width=0.1)
axes.bar(np.arange(len(names))+0.1,train_err,color="green",label="训练集错误",width=0.1)
axes.bar(np.arange(len(names))+0.2,test_err,color="blue",label="测试集错误",width=0.1)
plt.xticks(np.arange(len(names)), names)
plt.legend()
plt.show()
代码整合:
#coding=UTF-8
import numpy as np
import pandas as pd
defaultencoding = 'utf-8'
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import GridSearchCV
from sklearn.feature_selection import SelectKBest,chi2
import sklearn.metrics as metrics
from sklearn.datasets import fetch_20newsgroups
import sys
import importlib,sys
if sys.getdefaultencoding() != defaultencoding:
# reload(sys)
importlib.reload(sys)
sys.setdefaultencoding(defaultencoding)
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
#data_home="./datas/"下载的新闻的保存地址subset='train'表示从训练集获取新闻categories获取哪些种类的新闻
datas=fetch_20newsgroups(data_home="./datas/",subset='train',categories=['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc'])
datas_test=fetch_20newsgroups(data_home="./datas/",subset='test',categories=['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc'])
train_x=datas.data#获取新闻X
train_y=datas.target#获取新闻Y
test_x=datas_test.data#获取测试集的x
test_y=datas_test.target#获取测试集的y
tfidf=TfidfVectorizer(stop_words="english")
train_x=tfidf.fit_transform(train_x,train_y)#向量转化
test_x=tfidf.transform(test_x)#向量转化
print(train_x.shape)
best=SelectKBest(chi2,k=1000)#降维变成一千列
train_x = best.fit_transform(train_x,train_y)#转换
test_x = best.transform(test_x)
import time
def setParam(algo,name):
gridSearch = GridSearchCV(algo,param_grid=[],cv=5)
m=0
if hasattr(algo,"alpha"):
n=np.logspace(-2,9,10)
gridSearch.set_params(param_grid={"alpha":n})
m=10
if hasattr(algo,"max_depth"):
depth=[2,7,10,14,20,30]
gridSearch.set_params(param_grid={"max_depth":depth})
m=len(depth)
if hasattr(algo,"n_neighbors"):
neighbors=[2,7,10]
gridSearch.set_params(param_grid={"n_neighbors":neighbors})
m=len(neighbors)
t1=time.time()
gridSearch.fit(train_x,train_y)
test_y_hat=gridSearch.predict(test_x)
train_y_hat=gridSearch.predict(train_x)
t2=time.time()-t1
print(name, gridSearch.best_estimator_)
train_error=1-metrics.accuracy_score(train_y,train_y_hat)
test_error=1-metrics.accuracy_score(test_y,test_y_hat)
return name,t2/5*m,train_error,test_error
results=[]
plt.figure()
algorithm=[("mnb",MultinomialNB()),("random",RandomForestClassifier()),("knn",KNeighborsClassifier())]
for name,algo in algorithm:
result=setParam(algo,name)
results.append(result)
#把名称,花费时间,训练错误率,测试错误率分别存到单个数组
names,times,train_err,test_err=[[x[i] for x in results] for i in range(0,4)]
axes=plt.axes()
axes.bar(np.arange(len(names)),times,color="red",label="耗费时间",width=0.1)
axes.bar(np.arange(len(names))+0.1,train_err,color="green",label="训练集错误",width=0.1)
axes.bar(np.arange(len(names))+0.2,test_err,color="blue",label="测试集错误",width=0.1)
plt.xticks(np.arange(len(names)), names)
plt.legend()
plt.show()
结果:


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)