【人工智能】机器学习介绍以及机器学习流程

机器学习
机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及 概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技 能,重新组织已有的知识结构使之不断改善自身的性能。
普遍认为,机器学习的处理系统和算法是主要通过找出数据里隐藏 的模式进而做出预测的识别模式,它是人工智能的一个重要子领域。
机器学习分类
按照训练样本提供的信息以及反馈方式的不同,将机器学习算法分
为有监督学习和无监督学习。
有监督学习:训练数据集是有标签的;包括分类算法和回归算法。
无监督学习:训练数据集是完全没有标签的;包括聚类算法。
回归算法
回归实际上就是“最佳拟合;
回归算法(Regression),根据已有的数据拟合出一条最佳的直线、
曲线、超平面或函数等,用于预测其它数据的目标值。
回归算法最终预测出一个连续而具体的值。
常见的回归算法:线性回归、KNN回归、支持向量机回归、决策树回
归、随机森林回归。
分类算法
分类就是向事物分配标签;
分类算法(Classification),是求取一个从输入变量(特征)到离散
的输出变量(类别)之间的映射函数。
分类算法中算法(函数)的最终结果是一个离散的数据值。
常见的分类算法:KNN、逻辑回归、朴素贝叶斯、决策树、支持向量
机、随机森林等。
聚类算法
“物以类聚,人以群分”
聚类就是将数据集划分为互不相交的子集;
聚类算法(Clustering),是对大量未知标注的数据集,按数据的内
在相似性,将数据集划分为多个互不相交的子集,每个子集称为一个簇,
使簇内数据的相似度较大而簇间数据的相似度较小。
聚类算法属于无监督机器学习,只有数据x,没有标签y。
常见的聚类算法:k-Means、 spectral clustering、mean-shift等。
聚类的应用:数据分析、图像处理等。
数据
数据来源
用户访问行为数据
业务数据
外部第三方数据
学习过程中,使用公开的数据集进行开发。
数据清洗和转换
实际生产环境中机器学习比较耗时的一部分
大部分情况下 ,收集得到的数据需要经过预处理后才能够为算法所使用,
预处理的操作主要包括以下几个部分:
数据过滤
处理数据缺失
处理可能的异常、错误或者异常值
合并多个数据源数据
数据汇总
特征工程
大部分的机器学习模型所处理的都是 特征,特征通常是输入变量所对应
的可用于模型的数值表示。
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习
算法上发挥更好的作用的过程。
特征工程会直接影响机器学习的效果。
特征工程包括:
特征提取
特征预处理
特征降维
特征提取
特征提取是将任意数据(如文本或图像)转换为可用于机器学习的数字
特征。
特征提取API
sklearn.feature_extraction
对字典数据进行特征提取
sklearn.feature_extraction.DictVectorizer(sparse=True,…)
对文本数据进行特征提取
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
特征预处理
特征预处理是通过一些转换函数将特征数据转换成更加适合算法模型特
征数据的过程。
数值型数据的无量纲化:
归一化
标准化
特征预处理API
sklearn.preprocessing
归一化
sklearn实现归一化API:
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
标准化
sklearn实现标准化API:
sklearn.preprocessing.StandardScaler( )
StandardScaler.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
特征降维
特征降维是指在某些限定条件下,降低特征个数,得到一组“不相关”
特征的过程。
特征降维的两种方式
特征选择
主成分分析
数据集划分
机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
训练集:70% 80% 75%
测试集:30% 20% 30%
数据集划分api
sklearn.model_selection.train_test_split(arrays, *options)
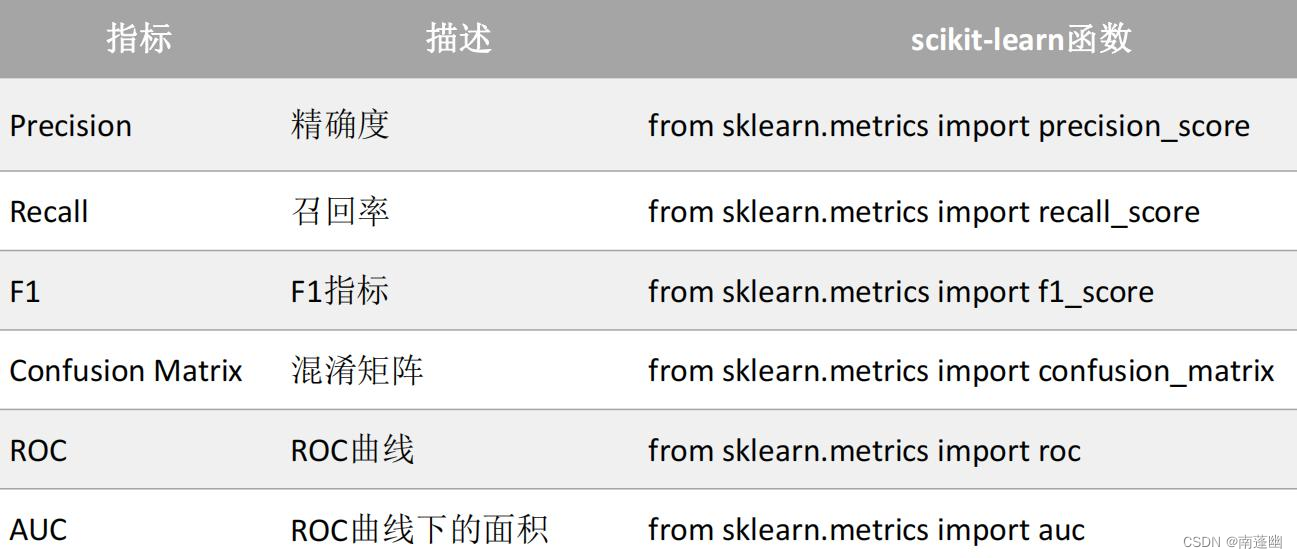
分类模型评估
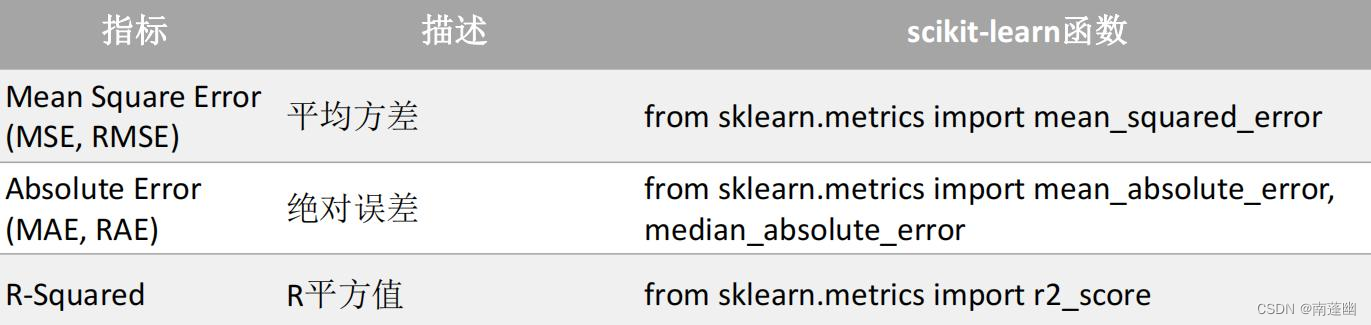
回归模型评估
聚类模型评估
轮廓系数 :from sklearn.metrics import silhouette_score,
Calinski-Harabasz Index :fromsklearn.metricsimportcalinski_harabasz_score
戴维森堡丁指数(DBI):from sklearn.metrics import davies_bouldin_score
模型保存
模型保存和加载
joblib
模型保存:
joblib.dump
模型加载:
joblib.load
为了更好的理解机器学习的工作流程,接下来看个案例
案例介绍
引入所需的库和数据集
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error,r2_score
from sklearn.linear_model import Lasso,Ridge,ElasticNet,BayesianRidge
from sklearn.neighbors import KNeighborsRegressor,RadiusNeighborsRegressor
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
import joblib
1、加载数据集
data = load_boston()
2、数据集划分
train_x,test_x,train_y,test_y = train_test_split(data['data'],data['target'])
3、进行特征工程 (进行数据标准化)
std = StandardScaler()
train_x = std.fit_transform(train_x)
test_x = std.transform(test_x)
4、选择模型训练
# lr = LinearRegression() # y = w x +b
# lr.fit(train_x,train_y)
# lr = KNeighborsRegressor()
# lr.fit(train_x,train_y)
# lr = RadiusNeighborsRegressor()
# lr.fit(train_x,train_y)
# lr = SVR()
# lr.fit(train_x,train_y)
# lr = DecisionTreeRegressor()
# lr.fit(train_x,train_y)
lr = RandomForestRegressor()
lr.fit(train_x,train_y)
5、模型评估
#训练集上的表现
error = mean_squared_error(train_y,lr.predict(train_x))
r2 = r2_score(train_y,lr.predict(train_x))
print("训练集上的表现误差:",error,"\nr2的值:",r2)
error = mean_squared_error(test_y,lr.predict(test_x))
r2 = r2_score(test_y,lr.predict(test_x))
print("测试集上的表现误差:",error,"\nr2的值:",r2)
# w = lr.coef_ #获取w
# b = lr.intercept_ #获取b
# print("线性回归的w",w)
# print("线性回归的b",b)
6.模型保存
joblib.dump(std,'std.pkl') #标准化的模型进行保存
joblib.dump(lr,'lr.pkl')#线性回归模型进行保存

- 点赞
- 收藏
- 关注作者
评论(0)