【情感识别】基于matlab BP神经网络语音情感识别【含Matlab源码 349期】

一、BP神经网络语音情感识别简介
0 引言
随着科技的迅速发展, 人机交互显得尤为重要。语音是语言的载体, 是人与人之间交流的重要媒介。相较于其它交流方式而言, 语音交流更加直接、便捷。近年来, 随着人机交互研究的不断深入, 语音情感识别更成为了学术界研究的热点, 其涉及到信号处理、模式识别、人工智能等相关领域。语音中除了能够传达语义信息外, 还包含了一些情感信息, 然而这些情感信息往往被人们所忽略。语音情感识别实际上是利用计算机所提取的语音信号特征来判断其属于哪一类情感。利用模式识别方法研究语音情感识别的文献较多, 朱菊霞等使用SVM算法对语音情感进行识别, 并取得了86% 的识别率。余华等使用粒子群算法优化神经网络来进行语音情感识别, 识别率较高。BP神经网络是神经网络的一种, 属于多层前馈神经网络, 与其它神经网络算法所不同的是采用了反向传播的学习算法, 不断地计算输出端的误差向回传递来进行权值调整, 从而达到误差最小的效果。
1 BP神经网络
BP神经网络算法由Rumelhart等于1988年提出, 它是一种用于前向神经网络学习训练的误差反向传播算法, 简称BP算法。它是前向神经网络的核心和精华部分, 因其网络结构容易构造, 对输入的数据没有特别要求, 同时相关理论的研究也已经成熟, 因而已经被广泛地应用于模式识别中。目前, 人工神经网络中研究最多的就是BP神经网络及其改进算法。该网络同样由输入层、隐含层、输出层组成, 典型的BP神经网络如图1所示。
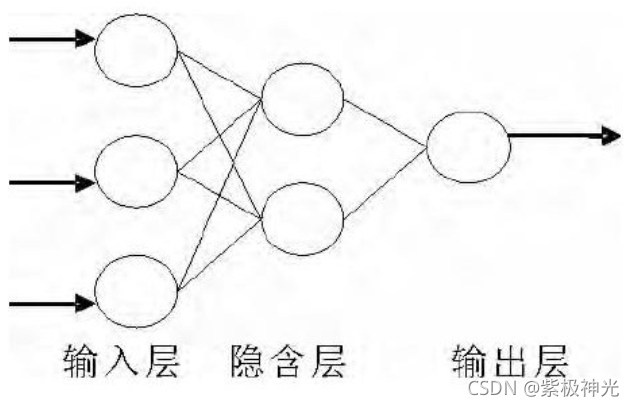
图1 典型的BP神经网络结构
该算法主要由两个阶段组成, 分别是正向传播过程和误差的反向传播过程。正向传播过程是指输入特征向量, 经过输入层、隐含层和输出层逐层计算权值。误差的反向传播过程是指输出层计算出误差之后, 再由输出层传到输入层来进行权值调整。一个标准的BP神经网络流程如图2所示。
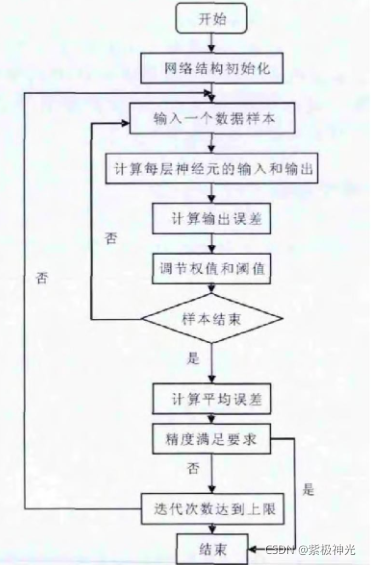
图2 BP神经网络流程
(1) 正向传播过程。从样本数据集中选择一个样本Xi, 将其输入到神经网络, 并计算其实际输出Yi。该过程就是数据样本从输入层输入, 然后经过隐含层和输出层的逐层计算, 得到的输出结果。
(2) 误差的反向传播过程。计算实际输出Yi与理想的输出结果Ai之间的误差, 根据相应的规则不断地调整权值, 并对BP神经网络进行不断训练使得误差能够满足要求。
2 语音情感特征
如何选择有效的语音情感特征, 直接影响到语音情感识别结果的好坏。首先要明确研究哪几类情感, 从心理学的角度来看, 总共包括以下7类情感, 即高兴、生气、悲伤、害怕、惊讶、厌恶、中性。本文主要研究生气、高兴、悲伤和惊讶这四类情感。目前, 很多研究中都是把语音情感识别问题转化为模式识别问题进行研究。其本质就是先对语音信号特征进行预处理, 再提取相关特征, 从而进行分类。选取语音持续时间、短时能量、基音频率、共振峰和MFCC等语音信号特征进行相关研究。
2.1 语音持续时间
语音持续时间实际上就是说话过程中所持续的时间, 其往往与所表达的情感有着直接的关联。一般来说, 人生气时说话速度较快, 语音持续时间较短;而处于悲伤或者害怕时说话的语速就会较慢, 语音持续时间较长。因此, 选择带有情感的语音持续时间与正常状态下的语音持续时间的比值作为一个特征参数。
2.2 短时能量
短时能量直接反映了声音音量的大小。一般来说, 清音的能量较小, 浊音的能量较高。当一个人的情感为生气或者是惊讶的时候, 其说话的音量就会变大, 短时能量往往也比较高。当一个人的情感为害怕或者悲伤的时候, 说话的音量就会变低, 短时能量往往也比较低。因此, 本文选择短时能量的均值、最大值、最小值、变化范围这4个特征参数。
2.3 基音频率
基音频率简称基频, 它直接反映了声道的特征, 已经在多个领域被广泛应用, 如语音识别、语音合成等。一般来说, 男性的基频较低, 女性的基频较高。不同情感状态下基频的大小不同。相关研究表明, 生气、高兴和惊讶时的基频变化范围和均值较高, 相反悲伤时基频的均值和变化范围较小。因此, 本文选取了基频的均值、最大值、最小值和变化范围这4个特征参数。
2.4 共振峰
共振峰指发声的气流经过声道时, 与声道发生共振的频率。其与情感有着很大的关联, 情感状态不同, 共振峰频率也随之发生变化。目前, 大多数的研究都是利用线性预测法来提取语音信号中的共振峰频率。共振峰参数的选择对语音情感识别有着重要意义。因此, 本文选取第一共振峰频率的均值、第二共振峰频率的均值、第三共振峰频率的均值和第四共振峰频率的均值作为特征参数。
2.5 MFCC
即便是同一句话, 同一个人在不同的情感状态下说出来也是不一样的, 让听者听起来感觉更是不一样。MFCC是梅尔频率倒谱系数的简称, 它是模拟人耳听觉特性所提取的特征参数, 已经被广泛应用于语音识别和语音合成的研究中。因而选取12维MFCC均值作为特征参数。
二、部分源代码
%实验要求:基于神经网络的语音情感识别
clc
close all
clear all
load A_fear fearVec;
load F_happiness hapVec;
load N_neutral neutralVec;
load T_sadness sadnessVec;
load W_anger angerVec;
trainsample(1:30,1:140)=angerVec(:,1:30)';
trainsample(31:60,1:140)=hapVec(:,1:30)';
trainsample(61:90,1:140)=neutralVec(:,1:30)';
trainsample(91:120,1:140)=sadnessVec(:,1:30)';
trainsample(121:150,1:140)=fearVec(:,1:30)';
trainsample(1:30,141)=1;
trainsample(31:60,141)=2;
trainsample(61:90,141)=3;
trainsample(91:120,141)=4;
trainsample(121:150,141)=5;
testsample(1:20,1:140)=angerVec(:,31:50)';
testsample(21:40,1:140)=hapVec(:,31:50)';
testsample(41:60,1:140)=neutralVec(:,31:50)';
testsample(61:80,1:140)=sadnessVec(:,31:50)';
testsample(81:100,1:140)=fearVec(:,31:50)';
testsample(1:20,141)=1;
testsample(21:40,141)=2;
testsample(41:60,141)=3;
testsample(61:80,141)=4;
testsample(81:100,141)=5;
class=trainsample(:,141);
sum=bpnn(trainsample,testsample,class);
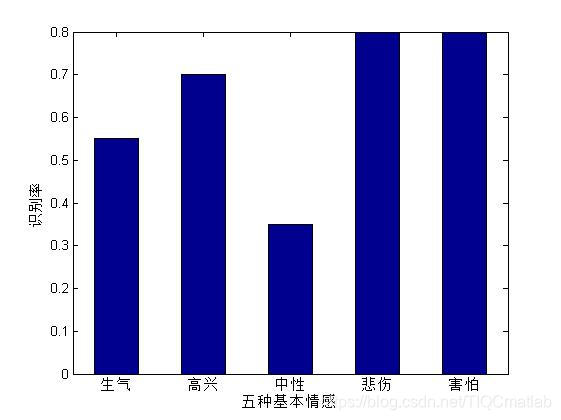
figure(1)
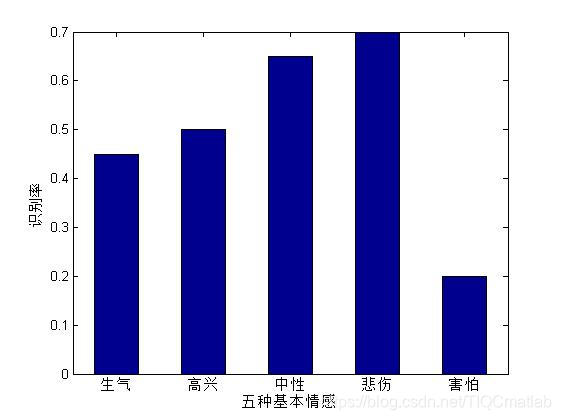
bar(sum,0.5);
set(gca,'XTickLabel',{'生气','高兴','中性','悲伤','害怕'});
ylabel('识别率');
xlabel('五种基本情感');
p_train=trainsample(:,1:140)';
t_train=trainsample(:,141)';
p_test=testsample(:,1:140)';
t_test=testsample(:,141)';
sumpnn=pnn(p_train,t_train,p_test,t_test);
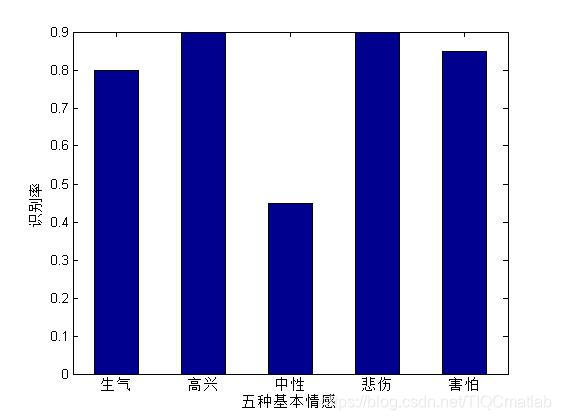
figure(2)
bar(sumpnn,0.5);
set(gca,'XTickLabel',{'生气','高兴','中性','悲伤','害怕'});
ylabel('识别率');
xlabel('五种基本情感');
sumlvq=lvq(trainsample,testsample,class);
function sum=bpnn(trainsample,testsample,class)
%输入参数:trainsample是训练样本,testsample是测试样本,class表示训练样本的类别,与trainsample中数据对应
%sum:五种基本情感的识别率
for i=1:140
feature(:,i)= trainsample(:,i);
end
%特征值归一化
[input,minI,maxI] = premnmx( feature') ;
%构造输出矩阵
s = length( class ) ;
output = zeros( s , 5 ) ;
for i = 1 : s
output( i , class( i ) ) = 1 ;
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
三、运行结果
四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
[3]徐照,松元建.基于BP神经网络的语音情感识别研究.[J]软件导刊. 2014,13(04)
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/113892143

- 点赞
- 收藏
- 关注作者
评论(0)