【预测模型】基于matlab RNN循环神经网络预测【含Matlab源码 363期】

一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【预测模型】基于matlab RNN循环神经网络预测【含Matlab源码 363期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、RNN循环神经网络简介
神经网络可以当做是能够拟合任意函数的黑盒子,只要训练数据足够,给定特定的x,就能得到希望的y,结构图如下:
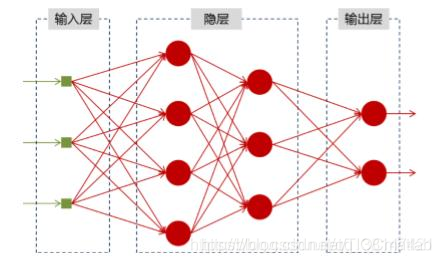
将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?
1 为什么需要RNN(循环神经网络)
他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
以nlp的一个最简单词性标注任务来说,将我 吃 苹果 三个单词标注词性为 我/nn 吃/v 苹果/nn。
那么这个任务的输入就是:
我 吃 苹果 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 苹果/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
2 RNN结构
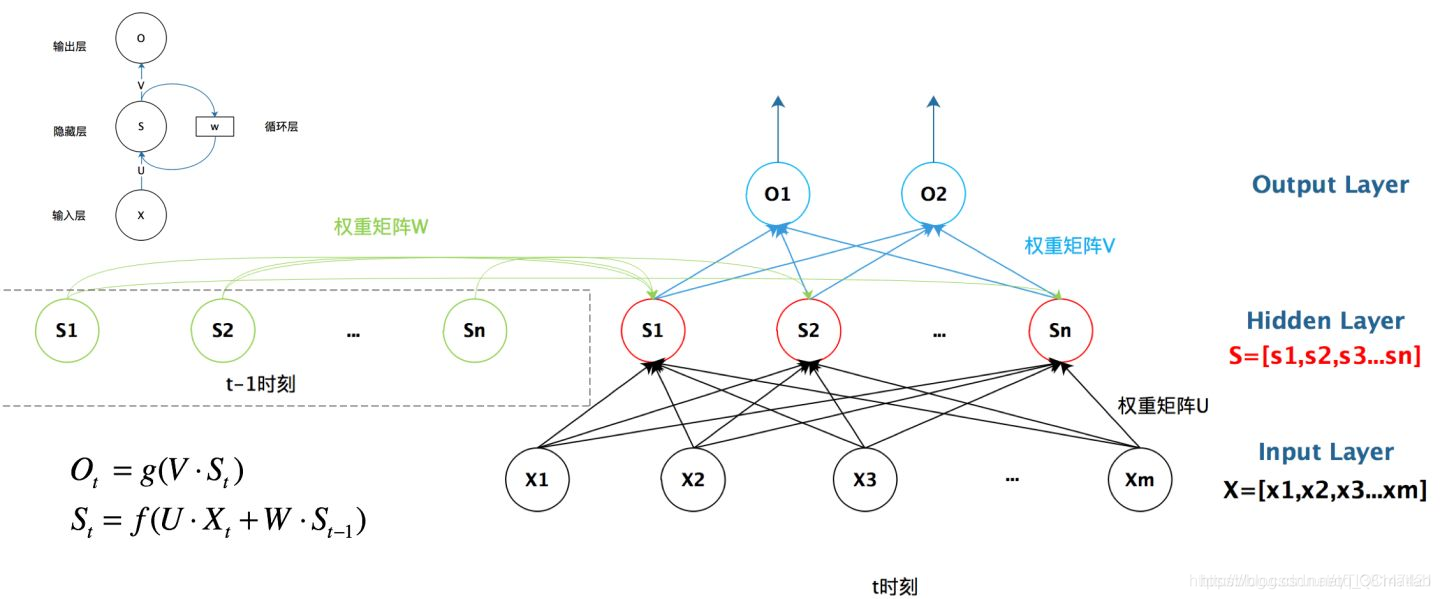
首先看一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:
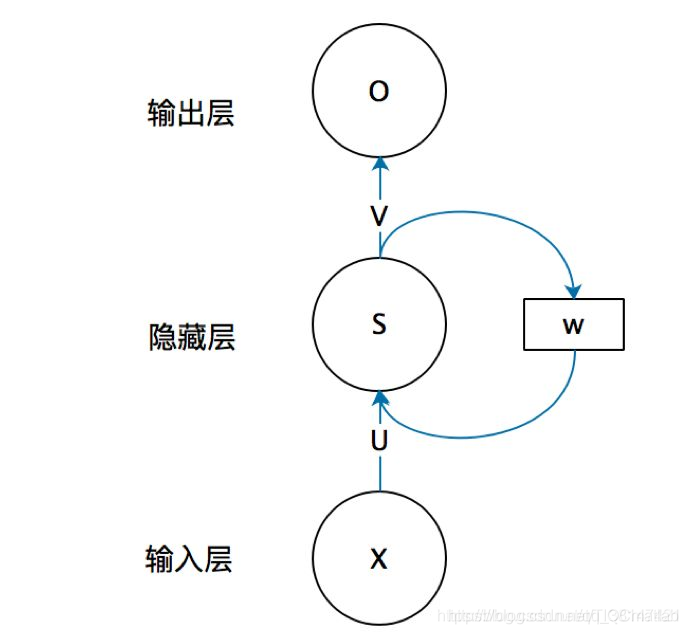
不知道初学的同学能够理解这个图吗,反正我刚开始学习的时候是懵逼的,每个结点到底代表的是一个值的输入,还是说一层的向量结点集合,如何隐藏层又可以连接到自己,等等这些疑惑~这个图是一个比较抽象的图。
我们现在这样来理解,如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网络。x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同);
U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。
那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
我们给出这个抽象图对应的具体图:
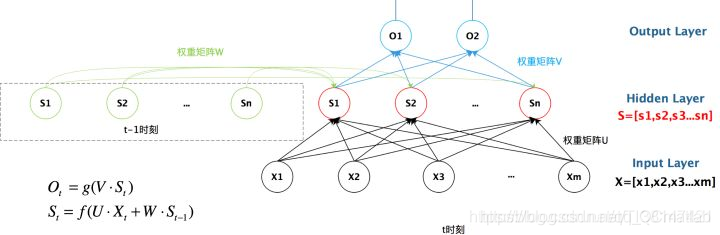
我们从上图就能够很清楚的看到,上一时刻的隐藏层是如何影响当前时刻的隐藏层的。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:
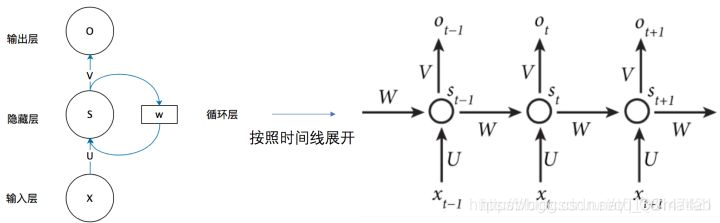

3 总结
好了,到这里大概讲解了RNN最基本的几个知识点,能够帮助大家直观的感受RNN和了解为什么需要RNN,后续总结它的反向求导知识点。
最后给出RNN的总括图:
三、部分源代码
clc;
clear all;
[train_data,test_data]=LSTM_data_process();
data_length=size(train_data,1);
data_num=size(train_data,2);
%% 网络参数初始化
% 结点数设置
input_num=data_length;
cell_num=5;
output_num=size(test_data,1);
% 网络中门的偏置
bias_input_gate=rand(1,cell_num);
bias_forget_gate=rand(1,cell_num);
bias_output_gate=rand(1,cell_num);
%网络权重初始化
ab=20;
weight_input_x=rand(input_num,cell_num)/ab;
weight_input_h=rand(output_num,cell_num)/ab;
weight_inputgate_x=rand(input_num,cell_num)/ab;
weight_inputgate_c=rand(cell_num,cell_num)/ab;
weight_forgetgate_x=rand(input_num,cell_num)/ab;
weight_forgetgate_c=rand(cell_num,cell_num)/ab;
weight_outputgate_x=rand(input_num,cell_num)/ab;
weight_outputgate_c=rand(cell_num,cell_num)/ab;
%hidden_output权重
weight_preh_h=rand(cell_num,output_num);
%网络状态初始化
cost_gate=0.25;
h_state=rand(output_num,data_num);
cell_state=rand(cell_num,data_num);
%% 网络训练学习
for iter=1:100
yita=0.01; %每次迭代权重调整比例
for m=1:data_num
%前馈部分
if(m==1)
gate=tanh(train_data(:,m)'*weight_input_x);
input_gate_input=train_data(:,m)'*weight_inputgate_x+bias_input_gate;
output_gate_input=train_data(:,m)'*weight_outputgate_x+bias_output_gate;
for n=1:cell_num
input_gate(1,n)=1/(1+exp(-input_gate_input(1,n)));
output_gate(1,n)=1/(1+exp(-output_gate_input(1,n)));
end
forget_gate=zeros(1,cell_num);
forget_gate_input=zeros(1,cell_num);
cell_state(:,m)=(input_gate.*gate)';
else
gate=tanh(train_data(:,m)'*weight_input_x+h_state(:,m-1)'*weight_input_h);
input_gate_input=train_data(:,m)'*weight_inputgate_x+cell_state(:,m-1)'*weight_inputgate_c+bias_input_gate;
forget_gate_input=train_data(:,m)'*weight_forgetgate_x+cell_state(:,m-1)'*weight_forgetgate_c+bias_forget_gate;
output_gate_input=train_data(:,m)'*weight_outputgate_x+cell_state(:,m-1)'*weight_outputgate_c+bias_output_gate;
for n=1:cell_num
input_gate(1,n)=1/(1+exp(-input_gate_input(1,n)));
forget_gate(1,n)=1/(1+exp(-forget_gate_input(1,n)));
output_gate(1,n)=1/(1+exp(-output_gate_input(1,n)));
end
cell_state(:,m)=(input_gate.*gate+cell_state(:,m-1)'.*forget_gate)';
end
pre_h_state=tanh(cell_state(:,m)').*output_gate;
h_state(:,m)=(pre_h_state*weight_preh_h)';
end
% 误差的计算
Error=h_state(:,m)-train_data(:,m);
% Error=h_state(:,:)-train_data(end,:);
Error_Cost(1,iter)=sum(Error.^2);
if Error_Cost(1,iter) < cost_gate
iter
break;
end
[ weight_input_x,...
weight_input_h,...
weight_inputgate_x,...
weight_inputgate_c,...
weight_forgetgate_x,...
weight_forgetgate_c,...
weight_outputgate_x,...
weight_outputgate_c,...
weight_preh_h ]=LSTM_updata_weight(m,yita,Error,...
weight_input_x,...
weight_input_h,...
weight_inputgate_x,...
weight_inputgate_c,...
weight_forgetgate_x,...
weight_forgetgate_c,...
weight_outputgate_x,...
weight_outputgate_c,...
weight_preh_h,...
cell_state,h_state,...
input_gate,forget_gate,...
output_gate,gate,...
train_data,pre_h_state,...
input_gate_input,...
output_gate_input,...
forget_gate_input);
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
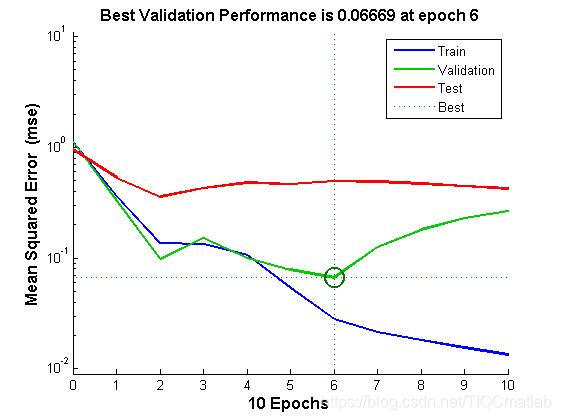
四、运行结果
五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
[3]周品.MATLAB 神经网络设计与应用[M].清华大学出版社,2013.
[4]陈明.MATLAB神经网络原理与实例精解[M].清华大学出版社,2013.
[5]方清城.MATLAB R2016a神经网络设计与应用28个案例分析[M].清华大学出版社,2018.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/113942670

- 点赞
- 收藏
- 关注作者
评论(0)