【车间调度】基于matlab多层编码遗传算法求解车间调度问题【含Matlab源码 035期】

一、车间调度简介
1 车间调度定义
车间调度是指根据产品制造的合理需求分配加工车间顺序,从而达到合理利用产品制造资源、提高企业经济效益的目的。车间调度问题从数学上可以描述为有n个待加工的零件要在m台机器上加工。问题需要满足的条件包括每个零件的各道工序使用每台机器不多于1次,每个零件都按照一定的顺序进行加工。
2 传统作业车间调度
传统作业车间带调度实例
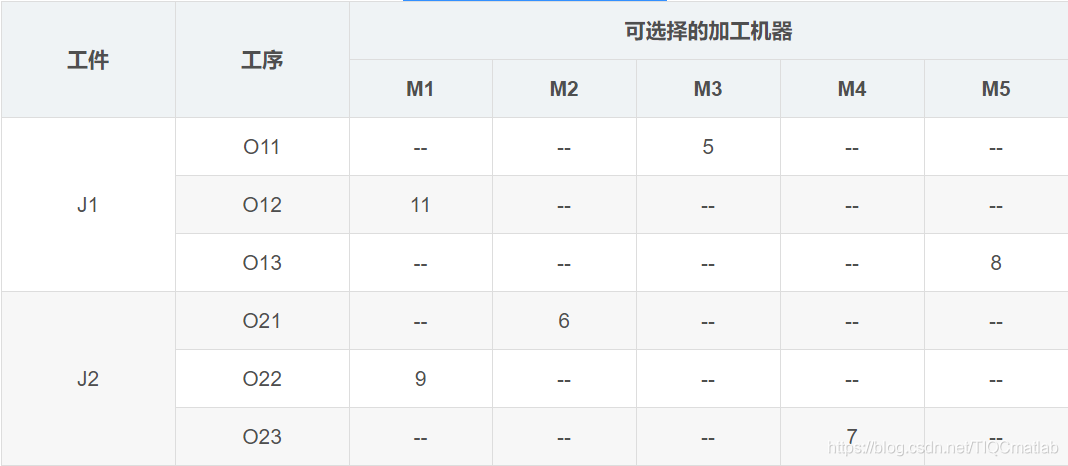
有若干工件,每个工件有若干工序,有多个加工机器,但是每道工序只能在一台机器上加工。对应到上面表格中的实例就是,两个工件,工件J1有三道工序,工序Q11只能在M3上加工,加工时间是5小时。
约束是对于一个工件来说,工序的相对顺序不能变。O11->O12->O13。每时刻,每个工件只能在一台机器上加工;每个机器上只能有一个工件。
调度的任务则是安排出工序的加工顺序,加工顺序确定了,因为每道工序只有一台机器可用,加工的机器也就确定了。
调度的目的是总的完工时间最短(也可以是其他目标)。举个例子,比如确定了O21->O22->O11->O23->O12->O13的加工顺序之后,我们就可以根据加工机器的约束,计算出总的加工时间。
M2加工O21消耗6小时,工件J2当前加工时间6小时。
M1加工O22消耗9小时,工件J2当前加工时间6+9=15小时。
M3加工O11消耗5小时,工件J1当前加工时间5小时。
M4加工O23消耗7小时,工件J2加工时间15+7=22小时。
M1加工O12消耗11小时,但是要等M1加工完O22之后才开始加工O12,所以工件J1的当前加工时间为max(5,9)+11=20小时。
M5加工O13消耗8小时,工件J2加工时间20+8=28小时。
总的完工时间就是max(22,28)=28小时。
2 柔性作业车间调度
柔性作业车间带调度实例(参考自高亮老师论文
《改进遗传算法求解柔性作业车间调度问题》——机械工程学报)
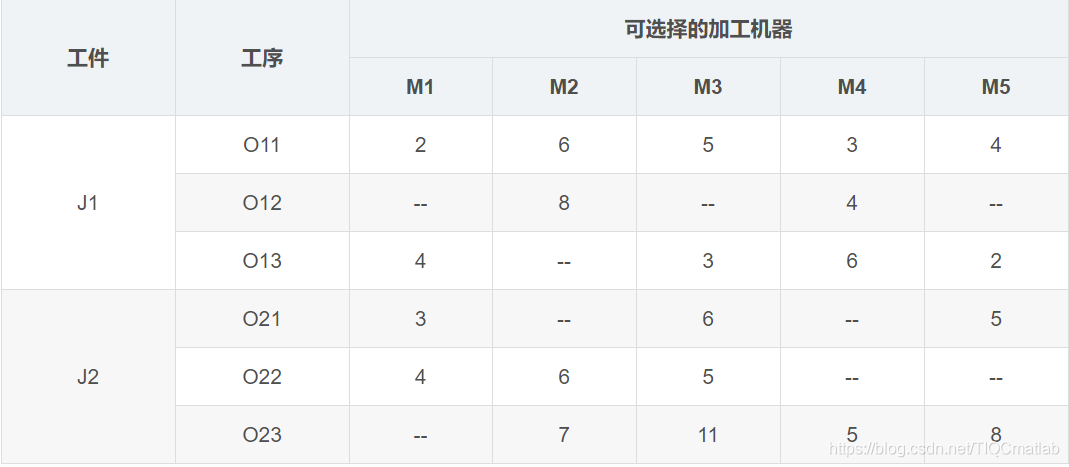
相比于传统作业车间调度,柔性作业车间调度放宽了对加工机器的约束,更符合现实生产情况,每个工序可选加工机器变成了多个,可以由多个加工机器中的一个加工。比如上表中的实例,J1的O12工序可以选择M2和M4加工,加工时间分别是8小时和4小时,但是并不一定选择M4加工,最后得出来的总的完工时间就更短,所以,需要调度算法求解优化。
相比于传统作业车间,柔性车间作业调度的调度任务不仅要确定工序的加工顺序,而且需要确定每道工序的机器分配。比如,确定了O21->O22->O11->O23->O12->O13的加工顺序,我们并不能相应工序的加工机器,所以还应该确定对应的[M1、M3、M5]->[M1、M2、M3]->[M1、M2、M3、M4、M5]->[M2、M3、M4、M5]->[M2、M4]->[M1、M3、M4、M5]的机器组合。调度的目的还是总的完工时间最短(也可以是其他目标,比如机器最大负荷最短、总的机器负荷最短)
二、遗传算法简介
1 遗传算法概述
遗传算法(Genetic Algorithm,GA)是进化计算的一部分,是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法简单、通用,鲁棒性强,适于并行处理。
2 遗传算法的特点和应用
遗传算法是一类可用于复杂系统优化的具有鲁棒性的搜索算法,与传统的优化算法相比,具有以下特点:
(1)以决策变量的编码作为运算对象。传统的优化算法往往直接利用决策变量的实际值本身来进行优化计算,但遗传算法是使用决策变量的某种形式的编码作为运算对象。这种对决策变量的编码处理方式,使得我们在优化计算中可借鉴生物学中染色体和基因等概念,可以模仿自然界中生物的遗传和进化激励,也可以很方便地应用遗传操作算子。
(2)直接以适应度作为搜索信息。传统的优化算法不仅需要利用目标函数值,而且搜索过程往往受目标函数的连续性约束,有可能还需要满足“目标函数的导数必须存在”的要求以确定搜索方向。遗传算法仅使用由目标函数值变换来的适应度函数值就可确定进一步的搜索范围,无需目标函数的导数值等其他辅助信息。直接利用目标函数值或个体适应度值也可以将搜索范围集中到适应度较高部分的搜索空间中,从而提高搜索效率。
(3)使用多个点的搜索信息,具有隐含并行性。传统的优化算法往往是从解空间的一个初始点开始最优解的迭代搜索过程。单个点所提供的搜索信息不多,所以搜索效率不高,还有可能陷入局部最优解而停滞;遗传算法从由很多个体组成的初始种群开始最优解的搜索过程,而不是从单个个体开始搜索。对初始群体进行的、选择、交叉、变异等运算,产生出新一代群体,其中包括了许多群体信息。这些信息可以避免搜索一些不必要的点,从而避免陷入局部最优,逐步逼近全局最优解。
(4) 使用概率搜索而非确定性规则。传统的优化算法往往使用确定性的搜索方法,一个搜索点到另一个搜索点的转移有确定的转移方向和转移关系,这种确定性可能使得搜索达不到最优店,限制了算法的应用范围。遗传算法是一种自适应搜索技术,其选择、交叉、变异等运算都是以一种概率方式进行的,增加了搜索过程的灵活性,而且能以较大概率收敛于最优解,具有较好的全局优化求解能力。但,交叉概率、变异概率等参数也会影响算法的搜索结果和搜索效率,所以如何选择遗传算法的参数在其应用中是一个比较重要的问题。
综上,由于遗传算法的整体搜索策略和优化搜索方式在计算时不依赖于梯度信息或其他辅助知识,只需要求解影响搜索方向的目标函数和相应的适应度函数,所以遗传算法提供了一种求解复杂系统问题的通用框架。它不依赖于问题的具体领域,对问题的种类有很强的鲁棒性,所以广泛应用于各种领域,包括:函数优化、组合优化生产调度问题、自动控制
、机器人学、图像处理(图像恢复、图像边缘特征提取…)、人工生命、遗传编程、机器学习。
3 遗传算法的基本流程及实现技术
基本遗传算法(Simple Genetic Algorithms,SGA)只使用选择算子、交叉算子和变异算子这三种遗传算子,进化过程简单,是其他遗传算法的基础。
3.1 遗传算法的基本流程
通过随机方式产生若干由确定长度(长度与待求解问题的精度有关)编码的初始群体;
通过适应度函数对每个个体进行评价,选择适应度值高的个体参与遗传操作,适应度低的个体被淘汰;
经遗传操作(复制、交叉、变异)的个体集合形成新一代种群,直到满足停止准则(进化代数GEN>=?);
将后代中变现最好的个体作为遗传算法的执行结果。
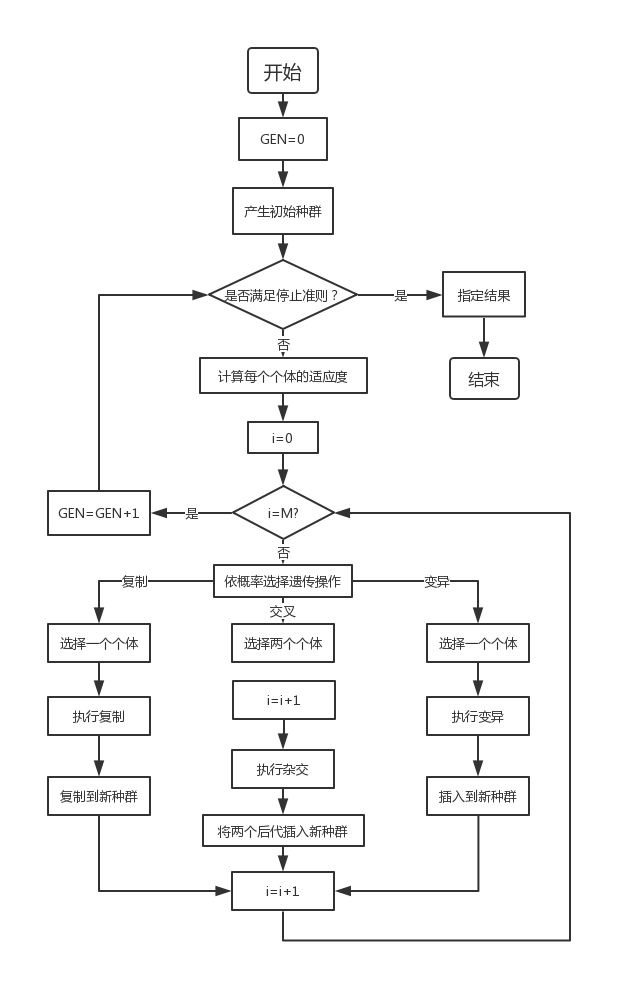
其中,GEN是当前代数;M是种群规模,i代表种群数量。
3.2 遗传算法的实现技术
基本遗传算法(SGA)由编码、适应度函数、遗传算子(选择、交叉、变异)及运行参数组成。
3.2.1 编码
(1)二进制编码
二进制编码的字符串长度与问题所求解的精度有关。需要保证所求解空间内的每一个个体都可以被编码。
优点:编、解码操作简单,遗传、交叉便于实现
缺点:长度大
(2)其他编码方法
格雷码、浮点数编码、符号编码、多参数编码等
3.2.2 适应度函数
适应度函数要有效反映每一个染色体与问题的最优解染色体之间的差距。
3.2.3选择算子

3.2.4 交叉算子
交叉运算是指对两个相互配对的染色体按某种方式相互交换其部分基因,从而形成两个新的个体;交叉运算是遗传算法区别于其他进化算法的重要特征,是产生新个体的主要方法。在交叉之前需要将群体中的个体进行配对,一般采取随机配对原则。
常用的交叉方式:
单点交叉
双点交叉(多点交叉,交叉点数越多,个体的结构被破坏的可能性越大,一般不采用多点交叉的方式)
均匀交叉
算术交叉
3.2.5 变异算子
遗传算法中的变异运算是指将个体染色体编码串中的某些基因座上的基因值用该基因座的其他等位基因来替换,从而形成一个新的个体。
就遗传算法运算过程中产生新个体的能力方面来说,交叉运算是产生新个体的主要方法,它决定了遗传算法的全局搜索能力;而变异运算只是产生新个体的辅助方法,但也是必不可少的一个运算步骤,它决定了遗传算法的局部搜索能力。交叉算子与变异算子的共同配合完成了其对搜索空间的全局搜索和局部搜索,从而使遗传算法能以良好的搜索性能完成最优化问题的寻优过程。
3.2.6 运行参数

4 遗传算法的基本原理
4.1 模式定理

4.2 积木块假设
具有低阶、定义长度短,且适应度值高于群体平均适应度值的模式称为基因块或积木块。
积木块假设:个体的基因块通过选择、交叉、变异等遗传算子的作用,能够相互拼接在一起,形成适应度更高的个体编码串。
积木块假设说明了用遗传算法求解各类问题的基本思想,即通过积木块直接相互拼接在一起能够产生更好的解。
三、部分源代码
%% 清空环境
clc;clear
%% 下载数据
load scheduleData Jm T JmNumber
%工序 时间
%% 基本参数
NIND=40; %个体数目
MAXGEN=50; %最大遗传代数
GGAP=0.9; %代沟
XOVR=0.8; %交叉率
MUTR=0.6; %变异率
gen=0; %代计数器
%PNumber 工件个数 MNumber 工序个数
[PNumber MNumber]=size(Jm);
trace=zeros(2, MAXGEN); %寻优结果的初始值
WNumber=PNumber*MNumber; %工序总个数
%% 初始化
Number=zeros(1,PNumber); % PNumber 工件个数
for i=1:PNumber
Number(i)=MNumber; %MNumber工序个数
end
% 代码2层,第一层工序,第二层机器
Chrom=zeros(NIND,2*WNumber);
for j=1:NIND
WPNumberTemp=Number;
for i=1:WNumber
%随机产成工序
val=unidrnd(PNumber);
while WPNumberTemp(val)==0
val=unidrnd(PNumber);
end
%第一层代码表示工序
Chrom(j,i)= val;
WPNumberTemp(val)=WPNumberTemp(val)-1;
%第2层代码表示机器
Temp=Jm{val,MNumber-WPNumberTemp(val)};
SizeTemp=length(Temp);
%随机产成工序机器
Chrom(j,i+WNumber)= unidrnd(SizeTemp);
end
end
%计算目标函数值
[PVal ObjV P S]=cal(Chrom,JmNumber,T,Jm);
%% 循环寻找
while gen<MAXGEN
%分配适应度值
FitnV=ranking(ObjV);
%选择操作
SelCh=select('rws', Chrom, FitnV, GGAP);
%交叉操作
SelCh=across(SelCh,XOVR,Jm,T);
%变异操作
SelCh=aberranceJm(SelCh,MUTR,Jm,T);
%计算目标适应度值
[PVal ObjVSel P S]=cal(SelCh,JmNumber,T,Jm);
%重新插入新种群
[Chrom ObjV] =reins(Chrom, SelCh,1, 1, ObjV, ObjVSel);
%代计数器增加
gen=gen+1;
%保存最优值
trace(1, gen)=min(ObjV);
trace(2, gen)=mean(ObjV);
% 记录最佳值
if gen==1
Val1=PVal;
Val2=P;
MinVal=min(ObjV);%最小时间
STemp=S;
end
%记录 最小的工序
if MinVal> trace(1,gen)
Val1=PVal;
Val2=P;
MinVal=trace(1,gen);
STemp=S;
end
end
% 当前最佳值
PVal=Val1; %工序时间
P=Val2; %工序
S=STemp; %调度基因含机器基因
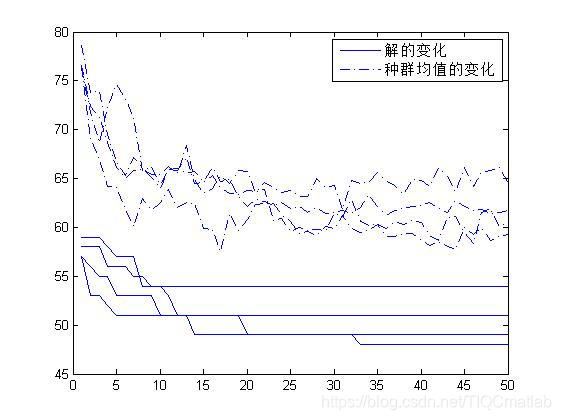
%% 描绘解的变化
figure(1)
plot(trace(1,:));
hold on;
plot(trace(2,:),'-.');grid;
legend('解的变化','种群均值的变化');
%% 显示最优解
% RANKING.M (RANK-based fitness assignment)
%
% This function performs ranking of individuals.
%
% Syntax: FitnV = ranking(ObjV, RFun, SUBPOP)
%
% This function ranks individuals represented by their associated
% cost, to be *minimized*, and returns a column vector FitnV
% containing the corresponding individual fitnesses. For multiple
% subpopulations the ranking is performed separately for each
% subpopulation.
%
% Input parameters:
% ObjV - Column vector containing the objective values of the
% individuals in the current population (cost values).
% RFun - (optional) If RFun is a scalar in [1, 2] linear ranking is
% assumed and the scalar indicates the selective pressure.
% If RFun is a 2 element vector:
% RFun(1): SP - scalar indicating the selective pressure
% RFun(2): RM - ranking method
% RM = 0: linear ranking
% RM = 1: non-linear ranking
% If RFun is a vector with length(Rfun) > 2 it contains
% the fitness to be assigned to each rank. It should have
% the same length as ObjV. Usually RFun is monotonously
% increasing.
% If RFun is omitted or NaN, linear ranking
% and a selective pressure of 2 are assumed.
% SUBPOP - (optional) Number of subpopulations
% if omitted or NaN, 1 subpopulation is assumed
%
% Output parameters:
% FitnV - Column vector containing the fitness values of the
% individuals in the current population.
%
% Author: Hartmut Pohlheim (Carlos Fonseca)
% History: 01.03.94 non-linear ranking
% 10.03.94 multiple populations
function FitnV = ranking(ObjV, RFun, SUBPOP)
% Identify the vector size (Nind)
[Nind,ans] = size(ObjV);
if nargin < 2, RFun = []; end
if nargin > 1, if isnan(RFun), RFun = []; end, end
if prod(size(RFun)) == 2,
if RFun(2) == 1, NonLin = 1;
elseif RFun(2) == 0, NonLin = 0;
else error('Parameter for ranking method must be 0 or 1'); end
RFun = RFun(1);
if isnan(RFun), RFun = 2; end
elseif prod(size(RFun)) > 2,
if prod(size(RFun)) ~= Nind, error('ObjV and RFun disagree'); end
end
if nargin < 3, SUBPOP = 1; end
if nargin > 2,
if isempty(SUBPOP), SUBPOP = 1;
elseif isnan(SUBPOP), SUBPOP = 1;
elseif length(SUBPOP) ~= 1, error('SUBPOP must be a scalar'); end
end
if (Nind/SUBPOP) ~= fix(Nind/SUBPOP), error('ObjV and SUBPOP disagree'); end
Nind = Nind/SUBPOP; % Compute number of individuals per subpopulation
% Check ranking function and use default values if necessary
if isempty(RFun),
% linear ranking with selective pressure 2
RFun = 2*[0:Nind-1]'/(Nind-1);
elseif prod(size(RFun)) == 1
if NonLin == 1,
% non-linear ranking
if RFun(1) < 1, error('Selective pressure must be greater than 1');
elseif RFun(1) > Nind-2, error('Selective pressure too big'); end
Root1 = roots([RFun(1)-Nind [RFun(1)*ones(1,Nind-1)]]);
RFun = (abs(Root1(1)) * ones(Nind,1)) .^ [(0:Nind-1)'];
RFun = RFun / sum(RFun) * Nind;
else
% linear ranking with SP between 1 and 2
if (RFun(1) < 1 | RFun(1) > 2),
error('Selective pressure for linear ranking must be between 1 and 2');
end
RFun = 2-RFun + 2*(RFun-1)*[0:Nind-1]'/(Nind-1);
end
end;
FitnV = [];
% loop over all subpopulations
for irun = 1:SUBPOP,
% Copy objective values of actual subpopulation
ObjVSub = ObjV((irun-1)*Nind+1:irun*Nind);
% Sort does not handle NaN values as required. So, find those...
NaNix = isnan(ObjVSub);
Validix = find(~NaNix);
% ... and sort only numeric values (smaller is better).
[ans,ix] = sort(-ObjVSub(Validix));
% Now build indexing vector assuming NaN are worse than numbers,
% (including Inf!)...
ix = [find(NaNix) ; Validix(ix)];
% ... and obtain a sorted version of ObjV
Sorted = ObjVSub(ix);
% Assign fitness according to RFun.
i = 1;
FitnVSub = zeros(Nind,1);
for j = [find(Sorted(1:Nind-1) ~= Sorted(2:Nind)); Nind]',
FitnVSub(i:j) = sum(RFun(i:j)) * ones(j-i+1,1) / (j-i+1);
i =j+1;
end
% Finally, return unsorted vector.
[ans,uix] = sort(ix);
FitnVSub = FitnVSub(uix);
% Add FitnVSub to FitnV
FitnV = [FitnV; FitnVSub];
end
% End of function
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
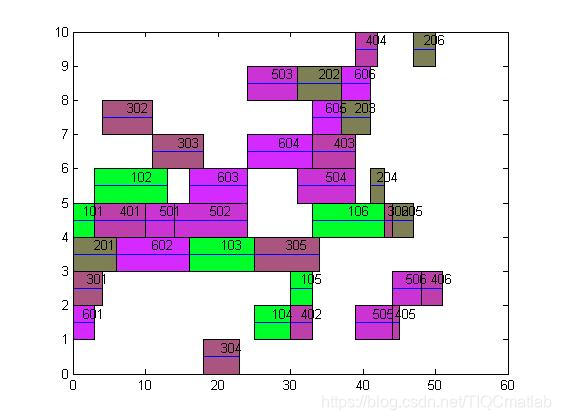
四、运行结果
五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/112131408

- 点赞
- 收藏
- 关注作者
评论(0)