【手写字母识别】基于matlab GUI BP网络手写体大写字母识别【含Matlab源码 183期】

一、获取代码方式
获取代码方式1:
完整代码已上传我的资源: 【手写字母识别】基于matlab GUI BP网络手写体大写字母识别【含Matlab源码 183期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、手写大写字母识别技术简介
1 引言
字符识别长期以来都是采用传统的识别方法,对印刷体字符的识别率一般只是稳定在96%左右,未能进一步提高,而对手写体字符的识别,其研究还处于探索阶段,其识别率还相当低,因此,为了提高识别率,就必须寻求新的方法和途径。
20世纪80年代中期, 人们已经开始利用人工神经网络解决手写体数字识别问题。人工神经网络为OCR研究提供了新的手段,它具有一些传统技术所没有的特点:1)具有很强的分类能力,可以在特征空间内形成任意复杂的决策区域;2)硬件实现后的神经网络分类速度比传统方法快得多;3)分类器便于训练,无需人为过多的干预。特别是对手写体字符识别问题,神经网络技术更显示出独特的优越性。
目前研究的神经网络字符识别系统可划分为两大类.第一类系统实际上是传统方法与神经网络技术的结合,这也是本文采用的方法.这类系统分为两块,第一块主要完成样本模式预处理和字符特征抽取任务,第二块是用前面获得的模式特征来训练神经网络分类器,从而达到识别字符的目的。这类系统充分利用了人的经验来获取模式特征以及神经网络的杰出分类能力来识别字符,是人们通常采用的方法。第二类系统省去了特征抽取工作,整个字符直接作为神经网络的输入,这类系统的神经网络结构的复杂度大大增加了,首先输入模式维数的增加导致网络规模的庞大,使得网络的训练、学习非常困难。此外神经网络结构上要消除模式变形的影响。通常这类网络都采用局部连接的方式减少网络的复杂度,并采用共享连接权的策略增强网络抗变形(输入模式)的能力。
由于人工神经网络具有并行处理和很强的容错性等特点,因此有可能大大提高手写体字母数字识别的准确率和速度。目前神经网络手写体字母数字识别系统的识别水平已与传统模式方法相当,且大有提高的余地。本文阐述了利用BP网络进行手写体字母(小写)、数字识别的一些尝试,取得了令人满意的测试结果。
2 预处理和特征抽取
2.1 样本集的获取和预处理
实验中所用的手写体数字样本集由1000个数字组成,它们是在屏幕上随意书写后,由象素点提取程序提取数据并存入磁盘文件,每个数字由6×8的网格数据组成。实验中所用的手写体小写字母样本集由400个字母组成,它们也是在屏幕上随意书写后,由象素点提取程序提取数据并存入磁盘文件,每个数字由8×10的网格数据组成。图1给出了部分原始数字图象和处理后的图像样本和部分原始字母图像和处理后的图像样本。
2.2 特征提取方法
字符是由弧线和直线构成的,弧线的弯曲方向和程度不同,字符的形状也就不一样。但是同一类不同形状的字符,它的端点数、交叉点数,点与点之间的相对位置及弧线的弯曲方向基本上是稳定的。而这些特征反映了字符的拓扑结构,是字符的重要特征。
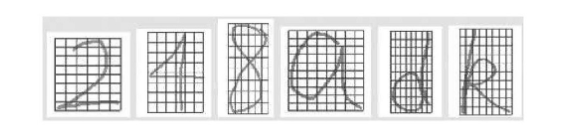
图1 部分原始图象和处理后图像样本
我们所采用的特征提取方法是:在手写(用鼠标模拟)过程中,由于鼠标会在屏幕上留下轨迹,所以只要从鼠标按键到鼠标起键,分别记录下鼠标经过的最大最小横纵坐标值,就可以分别将数字、字母划分为6×8和8×10的结构(如图1所示)o在确定好字符所占的区域之后,对于每一个网格,按照12×16的点阵提取象素点,如果在12×16的点阵上存在象素点的象素值为字体颜色,则认为相应网格取值为1,否则取值为0。
例如:图1中数字2提取的特征值为:
0011100100100000100000100001100011000110001111111
字母a提取的特征值为:
00111000010011000100010010000100100001001000110010011100110101000110001000000001
所得到的数据作为神经网络输入层的输入数据。
在生成训练集时,不但要把上述数据存入磁盘文件,同时,还要将目目标值(数字2和字母a)也分别写入磁盘文件,作为训练集数据。
3 识别和训练
3.1 神经网络的结构及其优化
我们采用的是误差反向传播的BP网络,选一层隐含层,网络结构如图2所示。输入层神经元的数目即为输入样本的维数(数字48,字母80),输出层的神经元数目为10(数字)和26(字母),分别对应10个数字和26个字母。至于隐含层神经元数目目前只有在实验的基础上经验选取,在实验中,我们将数字识别神经网络的隐含层神经元设置为20,字母的设置为40。
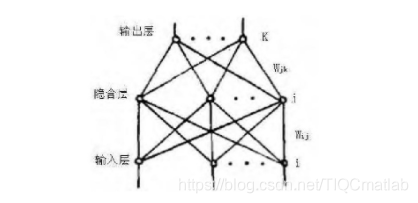
图2 BP网络结构
3.2 识别的实现

本实验中, 经调试发现, 取η=0.1, μ=0.4时, 学习与收敛速度为最佳。
二、部分源代码
%Example1 手写体大写字母识别
%形成用户界面
clear all;
%添加图形窗口
H=figure('Color',[0.8 0.8 1],...
'position',[400 300 500 400],...
'Name','基于BP神经网络的手写体大写字母识别',...
'NumberTitle','off',...
'MenuBar','none');
%画坐标轴对象,显示原始图像
h0=axes('position',[0.1 0.6 0.3 0.3]);
%添加图像打开按钮
h1=uicontrol(H,'Style','push',...
'Position',[350 300 80 60],...
'String','选择图像',...
'FontSize',14,...
'Call','op');
%画坐标轴对象,显示经过预处理之后的图像
%preprocess
p1=ones(16,16);
bw=im2bw(X,0.5);%转换成二值图像
%用矩形框截取图像
[i,j]=find(bw==0);
imin=min(i);
imax=max(i);
jmin=min(j);
jmax=max(j);
bw1=bw(imin:imax,jmin:jmax);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
四、运行结果

五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 蔡利梅.MATLAB图像处理——理论、算法与实例分析[M].清华大学出版社,2020.
[2]杨丹,赵海滨,龙哲.MATLAB图像处理实例详解[M].清华大学出版社,2013.
[3]周品.MATLAB图像处理与图形用户界面设计[M].清华大学出版社,2013.
[4]刘成龙.精通MATLAB图像处理[M].清华大学出版社,2015.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/113458966

- 点赞
- 收藏
- 关注作者
评论(0)