【ACO TSP】基于matlab蚁群算法求解76城市旅行商问题【含Matlab源码 409期】

一、获取代码方式
获取代码方式1:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
获取代码方式2:
完整代码已上传我的资源:【TSP】基于matlab蚁群算法求解76城市旅行商问题【含Matlab源码 409期】
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、TSP简介
旅行商问题,即TSP问题(Traveling Salesman Problem)又译为旅行推销员问题、货郎担问题,是数学领域中著名问题之一。假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。
TSP的数学模型

三、蚁群算法简介
1 引言
在自然界中各种生物群体显现出来的智能近几十年来得到了学者们的广泛关注,学者们通过对简单生物体的群体行为进行模拟,进而提出了群智能算法。其中, 模拟蚁群觅食过程的蚁群优化算法(Ant
Colony Optimization, A CO) 和模拟鸟群运动方式的粒子群算法(ParticleS warm Optimization,PSO) 是两种最主要的群智能算法。
蚁群算法是一种源于大自然生物世界的新的仿生进化算法,由意大利学者M.Dorigo, V.Mani ezzo和A.Color ni等人于20世纪90年代初期通过模拟自然界中蚂蚁集体寻径行为而提出的一种基于种群的启发式随机搜索算法[1].蚂蚁有能力在没有任何提示的情形下找到从巢穴到食物源的最短路径,并且能随环境的变化,适应性地搜索新的路径,产生新的选择。其根本原因是蚂蚁在寻找食物时,能在其走过的路径上释放一种特殊的分泌物――信息素2,随着时间的推移该物质会逐渐挥发,后来的蚂蚁选择该路径的概率与当时这条路径上信息素的强度成正比。当一条路径上通过的蚂蚁越来越时,其留下的信息素也越来越多,后来蚂蚁选择该路径的概率也就越高,从而更增加了该路径上的信息素强度。而强度大的信息素会吸引更多的蚂蚁,从而形成一种正反馈机制。通过这种正反馈机制,蚂蚁最终可以发现最短路径。
最早的蚁群算法是蚂蚁系统(Ant System, AS) , 研究者们根据不同的改进策略对蚂蚁系统进行改进并开发了不同版本的蚁群算法,并成功地应用于优化领域。用该方法求解旅行商(TSP) 问题、分配问
题、车间作业调度(job-shop) 问题, 取得了较好的试验结果[3-6] 。蚁群算法具有分布式计算、无中心控制和分布式个体之间间接通信等特征,易于与其他优化算法相结合,它通过简单个体之间的协作表现出了求解复杂问题的能力,已被广泛应用于求解优化问题。蚁群算法相对而言易于实现,且算法中并不涉及复杂的数学操作,其处理过程对计算机的软硬件要求也不高,因此对它的研究在理论和实践中都具有重要的意义。
目前,国内外的许多研究者和研究机构都开展了对蚁群算法理论和应用的研究,蚁群算法已成为国际计算智能领域关注的热点课题。虽然目前蚁群算法没有形成严格的理论基础,但其作为一种新兴的进
化算法已在智能优化等领域表现出了强大的生命力。
2 蚁群算法理论
蚁群算法是对自然界蚂蚁的寻径方式进行模拟而得出的一种仿生算法。蚂蚁在运动过程中,能够在它所经过的路径上留下信息素进行信息传递,而且蚂蚁在运动过程中能够感知这种物质,并以此来指导
自己的运动方向。因此,由大量蚂蚁组成的蚁群的集体行为便表现出一种信息正反馈现象:某一路径上走过的蚂蚁越多,则后来者选择该路径的概率就越大[7]。
2.1真实蚁群的觅食过程
为了说明蚁群算法的原理,先简要介绍一下蚂蚁搜寻食物的具体过程。在自然界中,蚁群在寻找食物时,它们总能找到一条从食物到巢穴之间的最优路径。这是因为蚂蚁在寻找路径时会在路径上释放出
一种特殊的信息素。蚁群算法的信息交互主要是通过信息素来完成的。蚂蚁在运动过程中,能够感知这种物质的存在和强度。初始阶段,环境中没有信息素的遗留,蚂蚁寻找事物完全是随机选择路径,
随后寻找该事物源的过程中就会受到先前蚂蚁所残留的信息素的影响,其表现为蚂蚁在选择路径时趋向于选择信息素浓度高的路径。同时,信息素是一种挥发性化学物,会随着时间的推移而慢慢地消逝。如果每只蚂蚁在单位距离留下的信息素相同,那对于较短路径上残留的信息素浓度就相对较高,这被后来的蚂蚁选择的概率就大,从而导致这条短路径上走的蚂蚁就越多。而经过的蚂蚁越多,该路径上残留的信息素就将更多,这样使得整个蚂蚁的集体行为构成了信息素的正反馈过程,最终整个蚁群会找出最优路径。
若蚂蚁从A点出发,速度相同,食物在D点,则它可能随机选择路线ABD或A CD。假设初始时每条路线分配一只蚂蚁, 每个时间单位行走一步。图5.1所示为经过8个时间单位时的情形:走路线ABD的蚂蚁到达终点:而走路线A CD的蚂蚁刚好走到C点, 为一半路程。
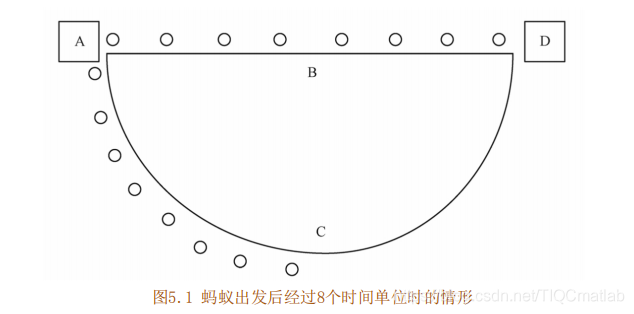
图5.2表示从开始算起, 经过16个时间单位时的情形:走路线ABD的蚂蚁到达终点后得到食物又返回了起点A,而走路线A CD的蚂蚁刚好走到D点.
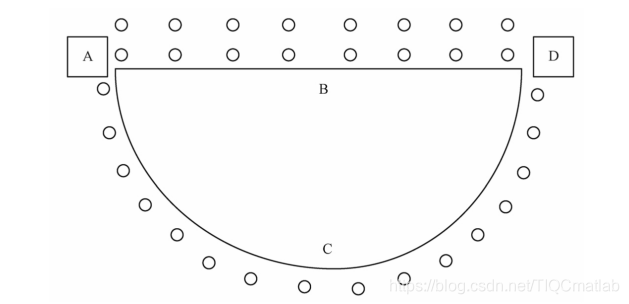
图5.2蚂蚁出发后经过16个时间单位时的情形
假设蚂蚁每经过一处所留下的信息素为1个单位,则经过32个时间单位后,所有开始一起出发的蚂蚁都经过不同路径从D点取得了食物。此时ABD的路线往返了2趟, 每一处的信息素为4个单位; 而A CD的路线往返了一趟,每一处的信息素为2个单位,其比值为2:1。
寻找食物的过程继续进行, 则按信息素的指导, 蚁群在ABD路线上增派一只蚂蚁(共2只) , 而A CD路线上仍然为一只蚂蚁。再经过32个时间单位后,两条线路上的信息素单位积累为12和4,比值为3:1。若按以上规则继续, 蚁群在ABD路线上再增派一只蚂蚁(共3只) , 而A CD路线上仍然为一只蚂蚁。再经过32个时间单位后, 两条线路上的信息素单位积累为24和6,比值为4:1.若继续进行, 则按信息素的指导, 最终所有的蚂蚁都会放弃A CD路线, 而选择ABD路线。这也就是前面所提到的正反馈效应。
2.2人工蚁群的优化过程
基于以上真实蚁群寻找食物时的最优路径选择问题,可以构造人工蚁群, 来解决最优化问题, 如TSP问题。人工蚁群中把具有简单功能的工作单元看作蚂蚁。二者的相似之处在于都是优先选择信息素浓度大的路径。较短路径的信息素浓度高,所以能够最终被所有蚂蚁选择,也就是最终的优化结果。两者的区别在于人工蚁群有一定的记忆能力,能够记忆已经访问过的节点。同时,人工蚁群再选择下一条路径的时候是按一定算法规律有意识地寻找最短路径,而不是盲目的。例如在TSP问题中, 可以预先知道当前城市到下一个目的地的距离。在TSP问题的人工蚁群算法中, 假设m只蚂蚁在图的相邻节点间移动,从而协作异步地得到问题的解。每只蚂蚁的一步转移概率由图中的每条边上的两类参数决定:一是信息素值,也称信息素痕迹:二是可见度,即先验值。
信息素的更新方式有两种:一是挥发,也就是所有路径上的信息素以一定的比率减少,模拟自然蚁群的信息素随时间挥发的过程;二是增强,给评价值“好”(有蚂蚁走过)的边增加信息素。蚂蚁向下一个目标的运动是通过一个随机原则来实现的,也就是运用当前所在节点存储的信息,计算出下一步可达节点的概率,并按此概率实现一步移动,如此往复,越来越接近最优解。蚂蚁在寻找过程中,或在找到一个解后,会评估该解或解的一部分的优化程度,并把评价信息保存在相关连接的信息素中。
2.3真实蚂蚁与人工蚂蚁的异同
蚁群算法是一种基于群体的、用于求解复杂优化问题的通用搜索技术。与真实蚂蚁通过外信息的留存、跟随行为进行间接通信相似,蚁群算法中一群简单的人工蚂蚁通过信息素进行间接通信,并利用该信息和与问题相关的启发式信息逐步构造问题的解。
人工蚂蚁具有双重特性:一方面,它们是真实蚂蚁的抽象,具有真实蚂蚁的特性:另一方面,它们还有一些真实蚂蚁没有的特性,这些新的特性使人工蚂蚁在解决实际优化问题时,具有更好地搜索较优解的能力。
人工蚂蚁与真实蚂蚁的相同点为:
(1)都是一群相互协作的个体。与真实蚁群一样,蚁群算法由一群人工蚂蚁组成,人工蚂蚁之间通过同步/异步协作来寻找问题的最优解。虽然单只人工蚂蚁可以构造出问题的解,但只有当多只人工蚂蚁
通过相互协作,才能发现问题的最优(次优)解。人工蚂蚁个体间通过写/读问题的状态变量来进行协作。
(2)都使用信息素的迹和蒸发机制。如真实蚂蚁一样,人工蚂蚁通过改变所访问过的问题的数字状态信息来进行间接的协作。在蚁群算法中,信息素是人工蚂蚁之间进行交流的唯一途径。这种通信方式在群体知识的利用上起到了至关重要的作用。另外,蚁群算法还用到了蒸发机制,这一点对应于真实蚂蚁中信息素的蒸发现象。蒸发机制使蚁群逐渐忘记过去的历史,使后来的蚂蚁在搜索中较少受到过去较差解的影响,从而更好地指导蚂蚁的搜索方向。
(3)搜索最短路径与局部移动。人工蚂蚁和真实蚂蚁具有相同的任务,即以局部移动的方式构造出从原点(蚁巢)到目的点(食物源)之间的最短路径。
(4)随机状态转移策略。人工蚂蚁和真实蚂蚁都按照概率决策规则从一种状态转移到另一种相邻状态。其中的概率决策规则是与问题相关的信息和局部环境信息的函数。在状态转移过程中,人工蚂蚁和
真实蚂蚁都只用到了局部信息,没有使用前瞻策略来预见将来的状态。
人工蚂蚁和真实蚂蚁的不同点为:
(1)人工蚂蚁生活在离散的时间,从一种离散状态到另一种离散状态。
(2)人工蚂蚁具有内部状态,即人工蚂蚁具有一定的记忆能力,能记住自己走过的地方。
(3)人工蚂蚁释放信息素的数量是其生成解的质量的函数。
(4)人工蚂蚁更新信息素的时机依赖于特定的问题。例如,大多数人工蚂蚁仅仅在蚂蚁找到一个解之后才更新路径上的信息素。
2.4蚁群算法的特点
蚁群算法是通过对生物特征的模拟得到的一种优化算法,它本身具有很多优点:
(1)蚁群算法是一种本质上的并行算法。每只蚂蚁搜索的过程彼此独立,仅通过信息激素进行通信。所以蚁群算法可以看作一个分布式的多智能体系统,它在问题空间的多点同时开始独立的解搜索,不仅增加了算法的可靠性,也使得算法具有较强的全局搜索能力。
(2)蚁群算法是一种自组织的算法。所谓自组织,就是组织力或组织指令来自于系统的内部,以区别于其他组织。如果系统在获得空间、时间或者功能结构的过程中,没有外界的特定干预,就可以说系统是自组织的。简单地说,自组织就是系统从无序到有序的变化过程。
(3)蚁群算法具有较强的鲁棒性。相对于其他算法,蚁群算法对初始路线的要求不高,即蚁群算法的求解结果不依赖于初始路线的选择,而且在搜索过程中不需要进行人工的调整。此外,蚁群算法的参
数较少,设置简单,因而该算法易于应用到组合优化问题的求解。
(4)蚁群算法是一种正反馈算法。从真实蚂蚁的觅食过程中不难看出,蚂蚁能够最终找到最优路径,直接依赖于其在路径上信息素的堆积,而信息素的堆积是一个正反馈的过程。正反馈是蚁群算法的重
要特征,它使得算法进化过程得以进行。
3 基本蚁群算法及其流程





4 改进的蚁群算法
针对基本蚁群算法一般需要较长的搜索时间和容易出现停滞现象等不足,很多学者在此基础上提出改进算法,提高了算法的性能和效率。
4.1精英蚂蚁系统

4.2 最大最小蚂蚁系统
为了克服基本蚁群系统中可能出现的停滞现象, Thomas Stutz le等人提出了最大-最小(MAX-MIN) 蚁群系统[10] , 主要有三方面的不同:
(1)与蚁群系统相似,为了充分利用循环最优解和目前为止找出的最优解,在每次循环之后,只有一只蚂蚁进行信息素更新。这只蚂蚁可能是找出当前循环中最优解的蚂蚁(迭代最优的蚂蚁),也可能是找出从实验开始以来最优解的蚂蚁(全局最优的蚂蚁);而在蚂蚁系统中,对所有蚂蚁走过的路径都进行信息素更新。
(2) 为避免搜索的停滞, 在每个解元素(TSP中是每条边) 上的信息素轨迹量的值域范围被限制在[min,Tmax] 区间内; 而在蚂蚁系统中信息素轨迹量不被限制,使得一些路径上的轨迹量远高于其他边,从而蚂蚁都沿着同条路径移动,阻止了进一步搜索更优解的行为。
(3)为使蚂蚁在算法的初始阶段能够更多地搜索新的解决方案,将信息素初始化为tmax;而在蚂蚁系统中没有这样的设置。
4.3基于排序的蚁群算法
基于排序的蚁群算法(Rank-BasedAntSystem)是Bull n heimer、Hartl和Strauss等人提出的[11] 。在该算法中, 每个蚂蚁释放的信息素按照它们不同的等级进行挥发,另外类似于精英蚁群算法,精英蚂蚁在每次循环中释放更多的信息素。在修改信息素路径前,蚂蚁按照它们的旅行长度进行排名(短的靠前),蚂蚁释放信息素的量要和蚂蚁的排名相乘。在每次循环中,只有排名前w-1位的蚂蚁和精英蚂蚁才允许在路径上释放信息素。己知的最优路径给以最强的反馈,和系数w相乘;而排名第r位的蚂蚁则乘以系数“w-(≥0)。信息素如下式所示:

4.4自适应蚁群算法
基本蚁群系统让信息量最大的路径对每次路径的选择和信息量的更新起主要作用,但由于强化了最优信息反馈,就可能导致“早熟”停滞现象。而最大最小蚁群算法将各个路径上的信息量的更新限定在固定的范围内,这虽然在一定程度上避免了“早熟”停滞现象,但在解分布较分散时会导致收敛速度变慢。以上方法的共同缺点在于:它们都按一种固定不变的模式去更新信息量和确定每次路径的选
择概率。
为了克服以上算法的不足, L.M.Gambardella和M.Dorigo提出了基于调节信息素挥发度的自适应蚁群算法[12]。相对基本蚁群算法的改进如下:
(1)在每次循环结束后求出最优解,并将其保留。
(2)自适应地改变p值。当问题规模比较大时,由于信息量的挥发系数p的存在,使那些从未被搜索到的信息量会减小到接近于0,降低了算法的全局搜索能力;当p过大且解的信息量增大时,以前搜索过的解被选择的可能性过大,也会影响到算法的全局搜索能力;通过减小p虽然可以提高算法的全局搜索能力,但又会使算法的收敛速度降低。因此可以自适应地改变p的值。p的初始值p(to)=1;当算法求得的最优值在N次循环内没有明显改进时,p减为:

5 关键参数说明
在蚁群算法中,不仅信息素和启发函数乘积以及蚂蚁之间的合作行为会严重影响到算法的收敛性,蚁群算法的参数也是影响其求解性能和效率的关键因素。信息素启发式因子α、期望启发因子β、信息
素蒸发系数p、信息素强度Q、蚂蚁数目m等都是非常重要的参数,其选取方法和选取原则直接影响到蚁群算法的全局收敛性和求解效率。
信息素启发式因子a
信息素启发式因子a代表信息量对是否选择当前路径的影响程度,即反映蚂蚁在运动过程中所积累的信息量在指导蚁群搜索中的相对重要程度。a的大小反映了蚁群在路径搜索中随机性因素作用的强度,其值越大,蚂蚁在选择以前走过的路径的可能性就越大,搜索的随机性就会减弱;而当启发式因子a的值过小时,则易使蚁群的搜索过早陷于局部最优。根据经验,信息素启发式因子a取值范围一般为[1,4]时,蚁群算法的综合求解性能较好。
期望启发因子β
期望启发因子β表示在搜索时路径上的信息素在指导蚂蚁选择路径时的向导性,它的大小反映了蚁群在搜索最优路径的过程中的先验性和确定性因素的作用强度。期望启发因子β的值越大,蚂蚁在某个局部点上选择局部最短路径的可能性就越大,虽然这个时候算法的收敛速度得以加快,但蚁群搜索最优路径的随机性减弱,而此时搜索易于陷入局部最优解。根据经验,期望启发因子β取值范围一般为[3,
5],此时蚁群算法的综合求解性能较好。实际上,信息素启发式因子α和期望启发因子β是一对关联性很强的参数:蚁群算法的全局寻优性能,首先要求蚁群的搜索过程必须要有很强的随机性;而蚁群算法的快速收敛性能,又要求蚁群的搜索过程必须要有较高的确定性。因此,两者对蚁群算法性能的影响和作用是相互配合、密切相关的,算法要获得最优解,就必须在这二者之间选取一个平衡点,只有正确选定它们之间的搭配关系,才能避免在搜索过程中出现过早停滞或陷入局部最优等情况的发生。
信息素蒸发系数p
蚁群算法中的人工蚂蚁是具有记忆功能的,随着时间的推移,以前留下的信息素将会逐渐消逝,蚁群算法与其他各种仿生进化算法一样,也存在着收敛速度慢、容易陷入局部最优解等缺陷,而信息素蒸
发系数p大小的选择将直接影响到整个蚁群算法的收敛速度和全局搜索性能。在蚁群算法的抽象模型中,p表示信息素蒸发系数,1-p则表示信息素持久性系数。因此,p的取值范围应该是0~1之间的一个
数,表示信息素的蒸发程度,它实际上反映了蚂蚁群体中个体之间相互影响的强弱。p过小时,则表示以前搜索过的路径被再次选择的可能性过大,会影响到算法的随机性能和全局搜索能力:p过大时,说
明路径上的信息素挥发的相对变多,虽然可以提高算法的随机搜索性能和全局搜索能力,但过多无用搜索操作势必会降低算法的收敛速度。
蚂蚁数目m
蚁群算法是一种随机搜索算法,与其他模拟进化算法一样,通过多个候选解组成的群体进化过程来寻求最优解,在该过程中不仅需要每个个体的自适应能力,更需要群体之间的相互协作能力。蚁群在搜
索过程中之所以表现出复杂有序的行为,是因为个体之间的信息交流与相互协作起着至关重要的作用。
对于旅行商问题,单个蚂蚁在一次循环中所经过的路径,表现为问题可行解集中的一个解,m只蚂蚁在一次循环中所经过的路径,则表现为问题解集中的一个子集。显然,子集增大(即蚂蚁数量增多),可以提高蚁群算法的全局搜索能力以及算法的稳定性;但蚂蚁数目增大后,会使大量的曾被搜索过的解(路径)上的信息素的变化趋于平均,信息正反馈的作用不明显,虽然搜索的随机性得到了加强,但收敛速度减慢;反之,子集较小(蚂蚁数量少),特别是当要处理的问题规模比较大时,会使那些从来未被搜索到的解(路径)上的信息素减小到接近于0,搜索的随机性减弱,虽然收敛速度加快了,但会使算法的全局性能降低,算法的稳定性差,容易出现过早停滞现象。m一般取10~50.
信息素强度Q对算法性能的影响
在蚁群算法中,各个参数的作用实际上是紧密联系的,其中对算法性能起着主要作用的是信息启发式因子α、期望启发式因子β和信息素挥发因子p这三个参数,总信息量(对算法性能的影响有赖于上述三个参数的选取, 以及算法模型的选取。例如, 在ant-cycle模型和ant-quantity模型中, 总信息量4所起的作用显然是有很大差异的, 即随着问题规模的不同,其影响程度也将不同。相关人员研究结果表
明:总信息量Q对ant-cycle模型蚁群算法的性能没有明显的影响。因此,在算法参数的选择上,参数Q不必作特别的考虑,可以任意选取。
最大进化代数G
最大进化代数6是表示蚁群算法运行结束条件的一个参数,表示蚁群算法运行到指定的进化代数之后就停止运行,并将当前群体中的最佳个体作为所求问题的最优解输出。一般6取100~500。
四、部分源代码
%%%%%%%%%% 问题定义:获取城市位置坐标、计算距离矩阵 %%%%%%%%%
InitOps=[];
[Location,DistMatrix,Ncities,Bestx,Lengx] = pr76init(InitOps);
close all;
figure (1);
hold on;
minx=min(DistMatrix(:,1));
maxx=max(DistMatrix(:,1));
miny=min(DistMatrix(:,2));
maxy=max(DistMatrix(:,2));
minm=min(minx,miny);
maxm=max(maxx,maxy);
l=(maxm-minm)/10;
for i=1:Ncities
plot(Location(i,1),Location(i,2),'*b');
text (Location(i,1)+l,Location(i,2)+l,num2str(i));
end
for i=1:Ncities-1
line([Location(Bestx(i),1),Location(Bestx(i+1),1)] , [Location(Bestx(i),2),Location(Bestx(i+1),2)]) ;
end
line([Location(Bestx(1),1),Location(Bestx(Ncities),1)] , [Location(Bestx(1),2),Location(Bestx(Ncities),2)]) ;
grid on,title(['初始路线图-',num2str(Lengx)]),xlabel('横坐标'),ylabel('纵坐标');
legend('城市位置');
hold off ;
% 初始化随机发生器状态
rand('state',sum(100*clock));
% ================================================
% 使用最近邻法构造一个初始游历,并据此计算信息系初值
p=zeros(1,Ncities+1);
p(1)=round(Ncities*rand+0.5);% p存储目前找到的所有城市的编号
i=p(1);
count=2;
while count <= Ncities
NNdist= inf ;%NNdist存储目前找到的和当前城市距离最短的城市的距离
pp= i ;% i存储当前城市的编号 pp存储目前找到的城市编号
for j= 1: Ncities
if (DistMatrix(i, j) < NNdist) & (j~=i) & ((j~=p) == ones(1,length(p)))
% 目标城市的要求为--距离短、且不能是当前城市,也不能是以前已经走过的城市
NNdist= DistMatrix(i, j) ;
pp= j ;
end
end
p(count)=pp;
i= pp ;
count= count + 1 ;
end
p=AcatspEval(p,DistMatrix,Ncities);
len=p(1,Ncities+1);
Q0=1/(Ncities*len);
%%%%%%%%%% 设定系统有关参数 %%%%%%%%%%
MaxNc=5000;% 最大代数
A=1;% 信息素因子
B=2;% 启发信息因子
P1=0.1;% 局部挥发系数初值
P2=0.1;% 全局挥发系数初值
R0=0.9; %选择概率
M=10;% 蚂蚁数量
%%%%%%%%%% 初始化信息素、启发信息矩阵、确定蚂蚁最初位置及允许矩阵 %%%%%%%%%%
Pheromone=Q0*ones(Ncities,Ncities);% 信息素初始矩阵;
Heuristic=1./DistMatrix;% 启发信息初始矩阵
Temp=ones(1,Ncities);
Heuristic=1./(1./Heuristic+diag(Temp));
RandL=round(rand(M,1)*Ncities+0.5);%蚂蚁最初位置
Alocation0=zeros(M,Ncities+1);% 存放M+1个蚂蚁游历的路径及长度矩阵初始化
Alocation0(:,1)=RandL;
Allow0=repmat(1:Ncities,M,1);% 允许访问的城市矩阵初始化
for Ak=1:M
Allow0(Ak,RandL(Ak))=0;
end
%%%%%%%%%% 运行参数初始化 %%%%%%%%%%
Nc=1;% 第一代
Lbestdis=inf;
Cbestdis=inf;
Fnewbest=0;
Alocation=Alocation0;% 存放个蚂蚁游历的路径及长度矩阵初始化
Allow=Allow0; % 允许矩阵赋初值
t1=clock;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 蚁群算法初始化程序结束 %%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 蚁群算法主循环开始 %%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
while(Nc<=MaxNc)
% M个蚂蚁选择Ncities个城市
for Cityi=2:Ncities+1
if Cityi<Ncities+1
for Ak=1:M
i=Alocation(Ak,Cityi-1);% 当前城市
j=Select_for_aca(R0,Ak,i,Allow,A,B,Pheromone,Heuristic);% 依据Pij选择下一个城市j
Alocation(Ak,Cityi)=j;
Allow(Ak,j)=0;% 更新允许矩阵
Pheromone(i,j)=(1-P1)*Pheromone(i,j)+P1*Q0; % 信息素在线单步更新
Pheromone(j,i)= Pheromone(i,j);
end
else % 返回出发城市
for Ak=1:M
i=Alocation(Ak,Cityi-1);% 当前城市
j=Alocation(Ak,1);
Pheromone(i,j)=(1-P1)*Pheromone(i,j)+P1*Q0; % 信息素在线单步更新
Pheromone(j,i)=Pheromone(i,j);
end
end
end
function D = dists(X1,X2,p,e)
%DISTS Calculates distances between vectors of points.
% D = dists(X1,X2,p,e)
% X1 = n x d matrix of n d-dimensional points
% X2 = m x d matrix of m d-dimensional points
% D = n x m matrix of distances
% = (n-1) x 1 vector of distances between X1 points, if X2 = []
% p = 2, Euclidean (default): D(i,j) = sqrt(sum((X1(i,:) - X2(j,:))^2))
% = 1, rectilinear: D(i,j) = sum(abs(X1(i,:) - X2(j,:))
% = Inf, Chebychev dist: D(i,j) = max(abs(X1(i,:) - X2(j,:))
% = (1 Inf), lp norm: D(i,j) = sum(abs(X1(i,:) - X2(j,:))^p)^(1/p)
% = 'rad', great circle distance in radians of a sphere
% (where X1 and X2 are decimal degree latitudes and longitudes)
% = 'mi' or 'sm', great circle distance in statute miles on the earth
% = 'km', great circle distance in kilometers on the earth
% e = epsilon for hyperboloid approximation gradient estimation
% = 0 (default); no error checking if any non-empty 'e' input
% ~= 0 => general lp used for rect., Cheb., and p outside [1,2]
%
% Great circle distances are calculated using the Haversine Formula (from R.W.
% Sinnott, "Virtues of the Haversine", Sky and Telescope, vol. 68, no. 2, 1984
% p. 159)
% Copyright (c) 1998 by Michael G. Kay
% Matlog Version 1.0 Apr-3-98
% Input Error Checking *******************************************************
if nargin == 4 & ~isempty(e) % No error checking is 'e' input
[n,d] = size(X1);
m = size(X2,1);
else % Do error checking
error(nargchk(1,4,nargin));
e = 0; % 'e' default
[n,d] = size(X1);
if n == 0 | ~isreal(X1)
error('X1 must be non-empty real matrix');
end
if nargin < 2 | isempty(X2) % Calc intra-seq dist b/w X1 points
m = 0; % X2 default
if n < 2
error('X1 must have more than 1 point');
end
else % Calc dist b/w X1 and X2 points
[m,dX2] = size(X2);
if m == 0 | ~isreal(X2)
error('X2 must be non-empty real matrix');
end
if d ~= dX2
error('Rows of X1 and X2 must have same dimensions');
end
end
if nargin < 3 | isempty(p)
p = 2; % 'p' default
elseif ~ischar(p) % lp distances
if length(p(:)) ~= 1 | ~isreal(p)
error('''p'' must be a real scalar number');
end
elseif ischar(p) % Great circle distances
p = lower(p);
if d ~= 2
error('Points must be 2-dimensional for great-circle distances');
end
if ~any(strcmp(p,{'rad','mi','sm','km'}))
error('''p'' must be either ''rad,'' ''mi,'' ''sm,'' or ''km''');
end
else
error('''p'' not valid value');
end
end
% End (Input Error Checking) ***********************************************
% Interchange if X2 is the only 1 point
intrchg = 0;
if n > 1 & m == 1
tmp = X2; X2 = X1; X1 = tmp;
m = n;n = 1;
intrchg = 1;
end
% 1-dimensional points
if d == 1
if e == 0
if m ~= 0
D = abs(X1(:,ones(1,m)) - X2(:,ones(1,n))');
else
D = abs(X1(1:n-1) - X1(2:n))'; % X1 intra-seq. dist.
end
else
if m ~= 0
D = sqrt((X1(:,ones(1,m)) - X2(:,ones(1,n))').^2 + e);
else
D = sqrt((X1(1:n-1) - X1(2:n)).^2 + e)';
end
end
% X1 only 1 point or intra-seq dist
elseif n == 1 | m == 0
if n == 1 % Expand X1 to match X2
X1 = X1(ones(1,m),:);
n = m;
else % X1 intra-seq. dist.
X2 = X1(2:n,:); % X2 = ending points
n = n - 1;
X1 = X1(1:n,:); % X1 = beginning points
end
if p == 2 % Euclidean distance
D = sqrt(sum(((X1 - X2).^2 + e)'));
elseif ischar(p) % Great-circle distance
X1 = pi*X1/180;X2 = pi*X2/180;
D = 2*asin(min(1,sqrt(sin((X1(:,1) - X2(:,1))/2).^2 + ...
cos(X1(:,1)).*cos(X2(:,1)).* ...
sin((X1(:,2) - X2(:,2))/2).^2)))';
elseif p == 1 & e == 0 % Rectilinear distance
D = sum(abs(X1 - X2)');
elseif (p >= 1 & p <= 2) | (e ~= 0 & p > 0) % General lp distance
D = sum((((X1 - X2).^2 + e).^(p/2))').^(1/p);
elseif p == Inf & e == 0 % Chebychev distance
D = max(abs(X1 - X2)');
else % Otherwise
D = zeros(1,n);
for j = 1:n
D(j) = norm(X1(j,:) - X2(j,:),p);
end
end

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
五、运行结果



六、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/114177348

- 点赞
- 收藏
- 关注作者
评论(0)