【语音识别】基于matlab MFCC GMM语音识别【含Matlab源码 535期】

【摘要】
一、高斯混合模型简介
GMM基本框架 类似的还有GMM-UBM(Universal background model)算法,其与GMM的区别在于:对L类整体样本训练一个大的GMM,而不像GMM对每一类...
一、高斯混合模型简介
GMM基本框架
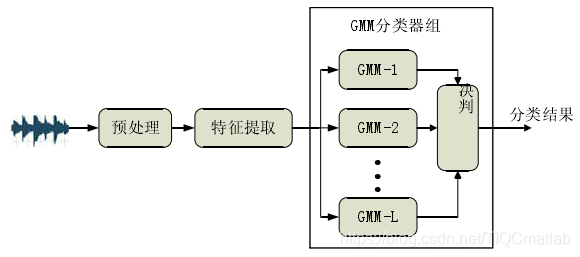
类似的还有GMM-UBM(Universal background model)算法,其与GMM的区别在于:对L类整体样本训练一个大的GMM,而不像GMM对每一类训练一个GMM模型。SVM的话MFCC作为特征,每一帧作为一个样本,可以借助VAD删除无效音频段,直接训练分类。近年来也有利用稀疏表达的方法:
二、部分源代码
% ====== Load wave data and do feature extraction
clc,clear
waveDir='trainning\';
speakerData = dir(waveDir);
%Matlab使用dir函数获得指定文件夹下的所有子文件夹和文件,并存放在在一种为文件结构体数组中.
% dir函数可以有调用方式
% dir('.') 列出当前目录下所有子文件夹和文件
% dir('G:\Matlab') 列出指定目录下所有子文件夹和文件
% dir('*.m') 列出当前目录下符合正则表达式的文件夹和文件
% 得到的为结构体数组每个元素都是如下形式的结构体
% name -- filename
% date -- modification date
% bytes -- number of bytes allocated to the file
% isdir -- 1 if name is a directory and 0 if not
% datenum -- modification date as a MATLAB serial date number
% 分别为文件名,修改日期,大小,是否为目录,Matlab特定的修改日期
% 可以提取出文件名以作读取和保存用.
speakerData(1:2) = [];
speakerNum=length(speakerData);%speakerNum:人数;
% ====== Feature extraction
fprintf('\n读取语音文件并进行特征提取... ');
% cd('D:\MATLAB7\toolbox\dcpr\');
for i=1:speakerNum
fprintf('\n正在提取第%d个人%s的特征\n', i, speakerData(i,1).name(1:end-4));
[y, fs, nbits]=wavread(['trainning\' speakerData(i,1).name]);
epInSampleIndex = epdByVol(y, fs); % endpoint detection端点检测
y=y(epInSampleIndex(1):epInSampleIndex(2)); % silence is not used去除静音
speakerData(i).mfcc=wave2mfcc(y, fs);
fprintf(' 完成!!');
end
save speakerData speakerData; % Since feature extraction is slow, you can save the data for future use if the features are not changed.
graph_MFCC; %由于特征提取速度慢,如果功能没有改变,可以保存供日后使用的数据,
fprintf('\n');
clear all;
fprintf('特征参数提取完成! \n\n请点击任意键继续...');
pause;
% ====== GMM training
fprintf('\n训练每个语者的高斯混合模型...\n\n');
load speakerData.mat
gaussianNum=12; % No. of gaussians in a GMM高斯混合模型中的高斯个数
speakerNum=length(speakerData);
for i=1:speakerNum
fprintf('\n为第%d个语者%s训练GMM……\n', i,speakerData(i).name(1:end-4));
[speakerGmm(i).mu, speakerGmm(i).sigm,speakerGmm(i).c] = gmm_estimate(speakerData(i).mfcc,gaussianNum);
fprintf(' 完成!!');
end
fprintf('\n');
save speakerGmm speakerGmm;
pause(10);
clear all;
fprintf('高斯混合模型训练结束! \n\n请点击任意键继续...');
pause;
% ====== recognition
fprintf('\n识别中...\n\n');
load speakerData;
load speakerGmm;
[filename, pathname] = uigetfile('*.wav','select a wave file to load');
if pathname == 0
errordlg('ERROR! No file selected!');
return;
end
wav_file = [pathname filename];
[testing_data, fs, nbits]=wavread(wav_file);
pause(10);
match= MFCC_feature_compare(testing_data,speakerGmm);
disp('待测模型匹配中,请等待10秒!')
pause(10);
[max_1 index]=max(match);
if length(filename)>7
fprintf('\n\n\n说话人是%s。',speakerData(index).name(1:end-4));
else
fprintf('\n\n\n说话人是%s。',filename(1:end-4));
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
三、运行结果










四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/114877082

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)