【语音编码】基于matlab ADPCM编解码【含Matlab源码 553期】

一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【语音编码】基于matlab ADPCM编解码【含Matlab源码 553期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、ADPCM编解码简介
1 ADPCM编码原理
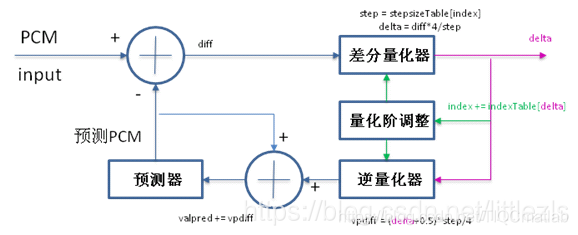
编码步骤:
求出输入的pcm数据与预测的pcm数据(第一次为上一个pcm数据)的差值diff;
通过差分量化器算出delta(通过index(首次编码index为0)求出step,通过diff和step求出delta)。delta即为编码后的数据;
通过逆量化器求出vpdiff(通过求出的delta和step算出vpdiff);
求出新的预测valpred,即上次预测的valpred+vpdiff;
通过预测器(归一化),求出当前输入pcm input的预测pcm值,为下一次计算用;
量化阶调整(通过delta查表及index,计算出新的index值)。为下次计算用;
2 ADPCM解码原理
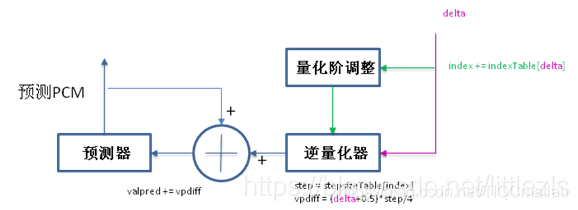
解码步骤(其实解码原理就是编码的第三到六步):
通过逆量化器求出vpdiff(通过存储的delta和index,求出step,算出vpdiff);
求出新的预测valpred,即上次预测的valpred+vpdiff;
通过预测器(归一化),求出当前输入pcm input的预测pcm值,为下一次计算用。预测的pcm值即为解码后的数据;
量化阶调整(通过delta查表及index,计算出新的index值)。为下次计算用;
注释说明
通过编码和解码的原理我们可以看出其实第一次编码的时候已经进行了解码,即预测的pcm。
因为编码再解码后输出的数据已经被量化了。根据计算公式delta = diff*4/step;vpdiff = (delta+0.5)*step/4;考虑到都是整数运算,可以推导出:pcm数据经过编码再解码生成的预测pcm数据,如果预测pcm数据再次编码所得的数据与第一次编码所得的数据是相同的。故pcm数据经过一次编码有损后,不论后面经过几次解码再编码都是数据一样,音质不会再次损失。即相对于第一次编码后,以后数据不论多少次编解码,属于无损输出。
3 ADPCM数据存放形式
本部分为adpcm数据存放说明,属于细节部分,很多代码解码出来有噪音就是因为本部分细节不对,所以需要仔细阅读。
3.1 adpcm 数据块介绍
adpcm数据是一个block一个block存放的,block由block header (block头) 和data 两者组成的。其中block header是一个结构,它在单声道下的定义如下:
Typedef struct
{
short sample0; //block中第一个采样值(未压缩)
BYTE index; //上一个block最后一个index,第一个block的index=0;
BYTE reserved; //尚未使用
}MonoBlockHeader;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
对于双声道,它的blockheader应该包含两个MonoBlockHeader其定义如下:
typedaf struct
{
MonoBlockHeader leftbher;
MonoBlockHeader rightbher;
}StereoBlockHeader;
- 1
- 2
- 3
- 4
- 5
- 6
在解压缩时,左右声道是分开处理的,所以必须有两个MonoBlockHeader;
有了blockheader的信息后,就可以不需要知道这个block前面数据而轻松地解出本block中的压缩数据。故adpcm解码只与本block有关,与其他block无关,可以只单个解任何一个block数据。
block的大小是固定的,可以自定义,每个block含的采样数nsamples计算如下:
//
#define BLKSIZE 1024
block = BLKSIZE * channels;
//block = BLKSIZE;//ffmpeg
nsamples = (block - 4 * channels) * 8 / (4 * channels) + 1;
- 1
- 2
- 3
- 4
- 5
- 6
例如audition软件就是采用上面的,单通路block为1024bytes,2041个samples,双通路block为2048,也是含有2041个sample。
而ffmpeg采用block =1024bytes,即不论单双通路都为1024bytes,通过公式可以算出单双通路的samples数分别为2041和1017;
3.2 单通路pcm格式
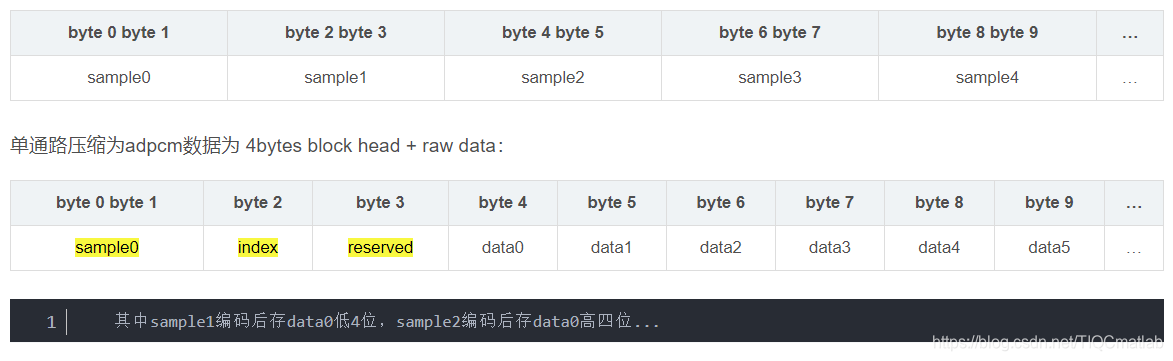
3.3 双通路pcm格式

3.4 编解码代码实现
需要特别留意双声道的处理和当数据不够1 block时的处理方式代码包含了编码和解码测试用例,实现先编码再解码。
三、部分源代码
clear all;
clc
close all;
[x,fs]= audioread('手放开.wav');
- 1
- 2
- 3
- 4
四、运行结果

五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/114977184

- 点赞
- 收藏
- 关注作者
评论(0)