【汉字识别】基于matlab SVM汉字识别【含Matlab源码 830期】

一、汉字识别简介
汉字作为中华民族文化的信息载体,与人们的日常学习和工作密不可分。在网络信息交流中,需要输入大量的中文信息 ,重复、单调的传统键盘手工输入方式效率低下,已逐渐不能满足迅速发展的信息化时代。而传统的模板匹配法对于汉字的识别率不高,作者提出一种基于SVM的多特征手写汉字识别技术,可大幅提高汉字的识别率以及录入效率。
1 系统流程
首先对汉字图像进行灰度化、二值化、形态学处理、倾斜校正、字符分割和归一化、细化等图像预处理操作,再对字符进行特征提取,最后采用SVM算法构造分类器。系统识别流程如图1所示。
2 SVM原理
SVM(Support Vector Machines)是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,面对小样本问题,其能表现出良好的学习能力,并能做到与数据的维数无关 。

图1 汉字识别流程图
SVM方法是从线性可分情况下的最优分类超平面提出的,所谓最优分类超平面就是要求分类平面不但能将两类无错地分开,且要使分类平面两侧样本之间的间隔最大[4] 。过两类样本中离最优分类超平面最近的点,且平行于最优分类超平面的分类超平面上的训练样本称为支持向量[3] 。设样本集(xi,yi),xi∈Rd,yi∈{1,-1},i=1,…,n。在线性可分情况下,则可找到权向量w,使两类间隔最大,即‖w‖2最小,同时满足
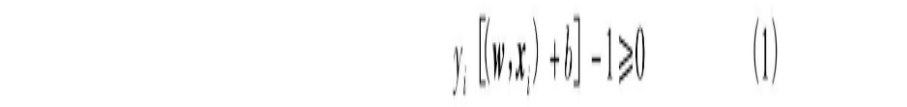
其中,i=1,…,n,n表示分类样本的数目。
为求解上述优化问题,引入拉格朗日函数

式中,α为拉格朗日乘子,αi≥0。
通过拉格朗日函数L分别对w,b求偏导,并令偏导数值为0,结果代入超平面方程得到最优分类函数
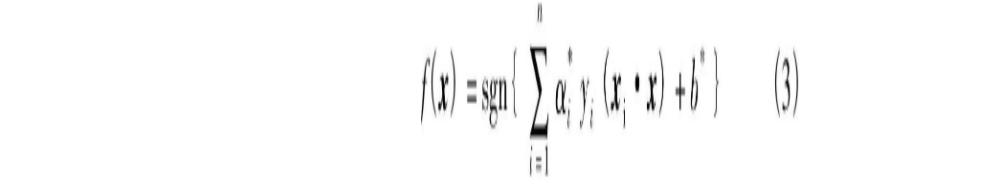
汉字识别的分类对象是非线性不可分的。对于不可分问题,可通过引入非负松弛变量ξi加以解决,则约束条件变为

式中,C是惩罚因子,用来调节分类的准确率与泛化能力[5] 。拉格朗日乘子α的取值范围变为0≤αi≤C。对于低维空间的非线性可分问题,可通过引入核函数解决。原始数据的核函数变换为(xi·xj)→K(xi·xj),则非线性情况下,使用核函数之后对应的分类函数为

3 关键技术
3.1 质心特征的提取
质心特征是字符笔划分布的体现。将二值图像转化成点阵形式,黑色像素点用“1”表示,白色像素点用“0”表示。设c(i,j)表示汉字点阵,质心计算如下:水平质心

垂直质心

式中,i表示该点阵的行;j表示该点阵的行。
3.2 笔划特征的提取
汉字由横、竖、撇、捺4种基本笔划构成,笔划的构成体现了汉字的基本形态[7] 。下面对4种基本笔划进行提取。
(1)横、竖笔划的提取。横笔划中所有的像素点具有同一纵坐标,而竖笔划中所有的像素点具有同一横坐标[8] 。其特征明显,提取算法也基本相同。本文提出一种将细化后图像与原图像相结合的笔划提取方法,方法如下:1)对细化后图像进行自上而下、从左往右的水平扫描,若同一纵坐标上连续的黑点个数大于或等于2,则记下这些黑点的坐标;2)对原图像进行水平扫描,若这些黑点依然连续,则说明这些黑点构成一个横笔划,横笔划数量加1;3)重复第1、2步;4)当细化后图像水平扫描全部完成时,记下横笔划数。同理,对细化后图像进行自左向右而下、从上往下的竖直扫描,可得到竖笔划数;
(2)撇、捺笔划的提取。1)将细化后图像中的横、竖笔划删除,降低图像的复杂性;2)自上而下、从左往右的水平扫描细化后图像,如果第i行扫描到黑点,记下该黑点的纵坐标yi;3)跳出对第i行的扫描,依次扫描第i+1,i+2,i+3,…,20行,记下首次扫描到黑点的纵坐标y2,y3,y4,…,y21-i;4)比较y2,y3,y4,…,y21-i,若满足yj+1≤yj≤yj+1+1∪yj+2≤yj≤yj+2+2,j∈{1,2,3,…,20-i},则这些点构成一撇笔划,撇笔划数量+1,若满足yj≤yj+1≤yj+1∪yj≤yj+2≤yj+2,j∈{1,2,3,…,20-i},则这些点构成一捺笔划,捺笔划数量+1;5)删除已提取的撇、捺笔划,重复第2)~4)步;6)扫描结束后,记下撇、捺笔划数。
3.3 特征点的提取
汉字笔划特征点主要有端点、折点、歧点、交点[9] 。端点是笔划的起点或终点(不与其他笔划相接);折点是指笔划方向出现显著变化的点;歧点是三叉点,要求其中两个笔端的分支方向相同;交点是四叉点,且有两对等的对顶角。自左向右、自上而下的对二值图像进行扫描,统计各笔划特征点的个数。
3.4 构造分类器
分类器是整个字符识别系统的核心,作者采用SVM来构造分类器。SVM方法解决的是二分类问题,为使其能够应用于10个汉字的分类,需构造多值分类器。将采用一对一方法构造分类器。对于10个不同的汉字,一对一方法需要构造(C210即45)个分类器,分类结束后选取得票数最多的类别作为最终的识别结果。
二、部分源代码
clc,clear,close
for i=1:5
imp=imread(['.\字库',num2str(i),'.jpg']);
create_database(imp,i);
end
load templet pattern;
aa=imread('example_1.png');
[word cnum]=get_picture(aa);
%cc=imresize(aa,[120 90]);
for i=1:cnum
class=bayesBinaryTest(word{i});
Code(i)=pattern(class).name;
end
figure(3);
imshow(aa);
tt=title(['识别文字: ', Code(1:cnum)],'Color','b');
function y = bayesBinary(sample)
%基于概率统计的贝叶斯分类器
%sample为要识别的图片的特征(1列100行的概率)
clc; %清屏
load templet pattern; %加载汉字特征
sum = 0; %初始化sum
prior = []; %先验概率
p = []; %各类别代表点
likelihood = []; %类条件概率
pwx = []; %贝叶斯概率
%%计算先验概率
for i=1:12
sum = sum+pattern(i).num; %特征总数
end
for i=1:12
prior(i) = pattern(i).num/sum; %出现每个汉字的可能性(先验概率)
end
%%计算类条件概率
for i=1:12 %12个汉字
for j=1:100 %100个模块
sum = 0;
for k=1:pattern(i).num %特征数
if(pattern(i).feature(j,k)>0.05) %概率大于阈值0.05则数量+1
sum = sum+1;
end
end
p(j,i) = (sum+1)/(pattern(i).num+2);%计算概率估计值即Pj(ωi),注意拉普拉斯平滑处理
end
end
for i=1:12
sum = 1;
for j=1:100
if(sample(j)>0.05)
sum = sum*p(j,i);%如果待测图片当前概率大于0.05认为特征值为1,直接乘Pj(ωi)
else
sum = sum*(1-p(j,i));%如果待测图片当前概率小于0.05认为特征值为0,乘(1-Pj(ωi))
end
end
likelihood(i) = sum; %将类条件概率赋值给likelihood
end
%%计算后验概率
sum = 0;
for i=1:12
sum = sum+prior(i)*likelihood(i); %求和即得P(X)
end
for i=1:12
pwx(i) = prior(i)*likelihood(i)/sum; %贝叶斯公式
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
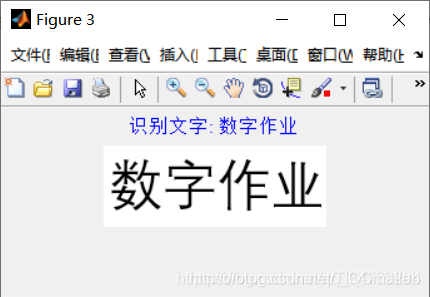
三、运行结果
四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 蔡利梅.MATLAB图像处理——理论、算法与实例分析[M].清华大学出版社,2020.
[2]杨丹,赵海滨,龙哲.MATLAB图像处理实例详解[M].清华大学出版社,2013.
[3]周品.MATLAB图像处理与图形用户界面设计[M].清华大学出版社,2013.
[4]刘成龙.精通MATLAB图像处理[M].清华大学出版社,2015.
[5]周庆曙,陈劲杰,纪鹏飞.基于SVM的多特征手写体汉字识别技术[J].电子科技. 2016,29(08)
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/116150829

- 点赞
- 收藏
- 关注作者
评论(0)