【协同任务】基于matlab多无人机目标搜索与围捕【含Matlab源码 1205期】

一、多无人机协同作业简介
0 引言
多架无人机组成无人机集群可以协同完成任务,是未来无人机的发展方向。组成无人机集群的多架无人机通过机间链路互相通信实现协作,可以迅速准确地执行路径规划、协同侦察、协同感知和协同攻击等复杂任务。
为实现无人机集群协作的诱人前景,国内外都积极开展了相关研究工作。美国方面,美国国防预先研究计划局(DARPA)于2015年推出“小精灵”项目,计划研制具备自组织和智能协同能力的无人机蜂群系统。美国防部战略能力办公室(SCO)2014年启动了“无人机蜂群”项目,旨在通过有人机空射“灰山鹑”微型无人机蜂群执行低空态势感知和干扰任务。美国海军研究局(ONR)于2015年公布了“低成本无人机蜂群”(LOCUST)项目,研发可快速连续发射的无人机蜂群,无人机之间利用近距离射频网络共享态势信息,协同执行掩护、攻击或防御任务。2017年,在 DARPA 会议中心举办“进攻性集群战术”(OFFSET)项目的提案人活动,目标是发展基于游戏的开放架构,为城市作战的无人集群系统生成、评估和集成集群战术。
欧洲方面,2016 年,欧洲防务局启动了“欧洲蜂群”项目,开展了无人机蜂群的自主决策、协同飞行等关键技术研究。2016年,英国国防部发起无人机蜂群竞赛,参赛的多个团队控制无人机蜂群实现了通信中继、协同干扰、目标跟踪定位和区域测绘等任务。2017 年,俄罗斯无线电电子技术集团对外发表研究计划称,在战斗机上装载多架蜂群无人机可实现协同侦察和攻击的新型作战样式。
国内也相继展开相关研究。最近,中国电科(CETC)电子科学研究院发布了陆军协同无人机“蜂群”视频,引起广泛关注。
面对这一重要课题,本文研究总结了无人机协同应用的发展趋势,对其当前研究进展和发展方向进行了探讨,并提出无人机集群任务协作的发展趋势是多智能体协同。
1 无人机协同应用发展趋势
对现有研究工作的分析如图1所示,无人机协同应用大体上可以分为3个阶段,分别是分布式协同,群体智能协同和未来的多智能体协同。
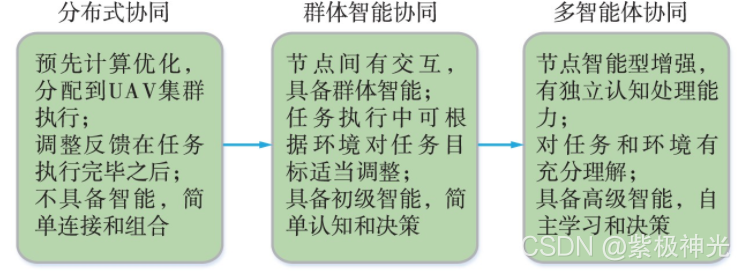
图1 无人机协同技术的发展趋势
无人机集群协同发展的第1个阶段是简单分布式协同。在该阶段,协同任务根据执行条件,预先在简单连接和组合的集群成员之间经过计算处理后分配执行。集群基本没有能力根据环境与目标的变化动态调整任务分配,各无人机分担的任务通常是确定的。
鉴于预分配方式的局限性,受生物集群活动的启发,群体智能被应用于无人机集群,使无人机集群协同发展到第2个阶段——群体智能协同。在该阶段中,各个无人机节点被赋予初级智能,能够进行简单的认知和决策;通过集群个体之间更为紧密的耦合,可以根据执行中的反馈调整优化方式或者优化目标,使整个无人机集群系统有能力构成自组织、高稳定的分布式系统。群体智能协同阶段当前正处于研究和应用迅速发展时期。
随着节点计算能力的进一步提升和人工智能技术的飞速发展,无人机协同即将进入发展的第3个阶段——多智能体协同。在多智能体协同发展阶段,集群中的各个无人机都将是一个独立的综合智能体,具有多维度认知计算和高级智能处理能力,从而实现更高效的自主学习和决策,并在此基础上,完成更复杂、更艰巨的任务。
2 分布式协同
从无人机集群出现开始就被用于解决协同路径规划、协同感知和协同任务规划等分布式协作任务。早期的无人机分布式协同任务通常都是提前进行充分的计算和分配,无人机节点按照既定算法或者方案予以执行。根据计算结果,分布式协同无人机群可组织执行配置好的任务,如图2所示。
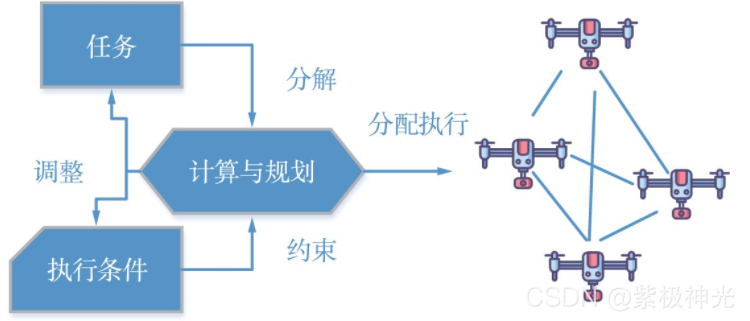
图2 分布式协同阶段的任务执行方式
2.1 协同路径规划
协同路径规划中,要求在给定目标或者搜索目标后,无人机节点根据当前的任务状态来确定飞行路径。针对协同搜索和跟踪任务的路线规划,无人机集群可采用最大化目标功能来检测最重要的目标,并在关键时刻对其进行跟踪,从而获得最有价值的信息。而协同搜索的路径规划可以分成无人机工作区间划分和全区域覆盖搜索路径规划2个子问题,将多机协同搜索转化为子区域上的单机搜索,对目标区域快速进行划分并生成飞行路线。基于改进遗传算法的多无人机协同侦察航迹规划算法,可用于解决面向复杂战场环境中高效侦察多种类型目标过程中的路径规划问题,并能够有效地提高航迹规划精度和效率。
2.2 协同感知
协同感知是多无人机集群共同探测感知某一目标区域状态的任务形式。在这类任务中最常见的是协同频谱感知。针对协同频谱感知任务特点,采用最佳融合准则的分布式协同任务执行方案可以优化检测性能,使协作频谱感知总错误率达到最小,并能降低协作感知时间,节省感知过程开销。
2.3 协同任务规划
协同任务规划要求集群系统能够根据目标任务和执行情况,对任务进行系统分配。例如,针对协同打击任务,通过建立无人机毁伤代价指标函数、航程代价指标函数和价值收益指标函数,可以实现多无人机协同打击任务的分配[5];而通过建立多目标优化模型并采用遗传算法,能有效提高任务的完成效率。针对协同搜救任务,使用一种新的基于通信保持的拍卖方法的自适应反馈调节遗传算法,能够改善传统遗传算法存在易陷入局部最优的弱点。
通过以上3种类型协同任务的相关研究工作可以看出,无人机集群的分布式协同方式虽然充分考虑了“分布式”特点,能够根据任务目标和集群特征,设置有效的目标函数和优化方法去寻求最优或者较优的结果,但是其任务执行环境和求解目标需要在任务执行之前进行优化计算,然后分配执行,不能适应实际中动态的任务目标和环境变化,缺乏“智能性”的感知和适应性行为。随着人们对“蜂群”“鸟群”等生物群体智能研究的深入,群体智能协同被进一步引入到无人机的协同中。
3 群体智能协同
“鸟群”“蚁群”等生物群体,虽然其中的个体智能有限,但是群体却展现出高度的自组织性,这一特点与无人机集群自主协同的需求相符,因而群体智能在无人机协同应用领域也得到了广泛研究,使无人机集群协同具有了初步的智能性。具备群体智能的无人机集群系统在任务拆解和执行过程中引入了群体反馈和适变能力,可执行较复杂的动态任务,其过程如图3所示。
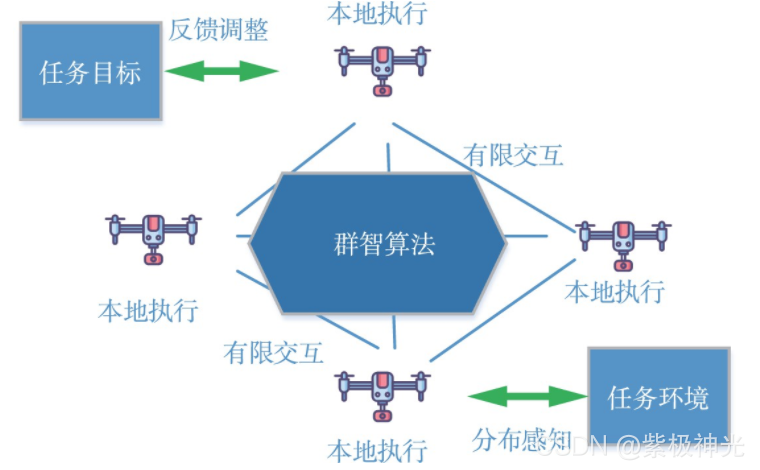
图3 群体智能协同阶段的任务执行方式
3.1 协同路径规划
山区路径规划任务受到地形特征的强烈影响,难以预先确定性分配执行,简单的分布式协同无法胜任。例如,为了执行山区应急物资运输的路径规划任务,一种考虑路径安全度的改进蚁群算法可快速收敛并生成更短路径。蚁群算法也被用于无人机协同飞抵空战场的航迹规划任务中;一种基于改进混沌蚁群算法更能克服传统蚁群智能算法中易出现局部极值、收敛效率低的缺陷,提升算法的全局寻优能力和搜索效率。针对协同攻击移动目标场景的航迹规划,另一种改进的蚁群算法建立了结合任务分配的无人机群协同航迹规划模型,可以快速地对地面多个移动目标规划出有效的航迹。
3.2 协同感知
在协同感知任务中,群体智能也得到应用。针对无人机集群通信场景和需求,出现了考虑结合认知无线电技术指导下的智能通信思想和汇聚有限智慧的群体智能理论方法,构建了群体智能协同通信模型和智能协同感知模型。
3.3 协同任务规划
协同作战是协同任务规划中的典型场景,结合群体智能优化算法的优势,基于粒子群-整数编码狼群算法的集群组网任务分配算法适合解决此类协同问题;由于无人机集群协同决策困难,还可以结合狼群算法的认知与协作能力,实现在复杂环境下迅速对目标进行跟踪和包围。这种协同任务,是第一类简单协同所不能胜任的。
虽然无人机集群和群体智能的结合可以充分发挥无人机集群优势,增强分布式协同智能性,可在任务执行过程中与环境和任务执行中间过程产生一定交互和反馈,使之具备一定的自适应能力,但是,这种智能仍然是非常有限的,其本质仍然是基于特定计算模式和反馈模式下的分布式优化算法。
4 多智能体协同
随着人工智能技术和节点自身算力的不断增强,未来无人机集群中的个体将具备更强的智能性,能够独立对环境和任务进行感知和评估,实现多个智能体之间的交互和协同,从而具备多智能体协同能力。
近年来,人工智能领域研究取得了突破性进展。其中,深度强化学习在诸多领域得到了成功应用。无线通信网络基于多智能体深度强化学习的资源分配技术也得到了深入研究。多智能体深度强化学习模型早已被用于解决车联网中频谱资源分配问题,这种应用已经与无人机集群系统颇为接近。例如一种基于多智能体深度强化学习的分布式动态功率分配方案。基于多智能体深度强化学习的策略还可被用于二者的结合——用无人机辅助车辆网络进行多维资源管理。
虽然基于强化学习的多智能体通信网络资源分配问题已经得到了广泛研究,但是由于网络特性的不同,传统的针对其他通信网络的研究成果不能直接用于无人机集群网络。因而基于强化学习的多智能体自主协同应用逐渐成为未来无人机多智能体自主协同的一个研究热点。针对无人机群的通信网络资源动态分配问题而提出的多智能体深度强化学习方案也陆续出现,例如,一种基于多智能体深度强化学习的分布式干扰协调策略被用于受到干扰的无人机网络中的文件下载业务。智能体在适用于无人机网络特点的独立强化学习中,其行为策略通常只能根据它们对全局环境的局部个体观察来制定。针对这种局限性,联合采用2种不同规模的智能体可解决智能体之间的通信问题。
无人机集群协同,经常会处理动态高维离散和连续动作状态空间的优化求解问题,近来出现的演员-评论家算法是深度强化学习的一个新兴方向,结合了基于值函数和基于策略函数的深度强化学习两大分支的优势,非常适用于无人机集群的智能协同。利用演员-评论家算法,在无线信道和可再生能源再生率都是随机变化,且环境动态变化条件下,可寻求资源分配最佳策略,如用于解决车联网中复杂动态环境下的资源分配问题。应用设备到设备(D2D)网络的异构蜂窝网络环境下,基于演员-评论家算法的策略可用于智能化节能模式选择和资源分配。
随着节点智能算力的不断增强,无人机集群中的每架无人机可以作为一个具有深度强化学习能力的智能体,而整个集群可通过合作构成多智能体。相邻无人机之间通过通信网络进行信息交换与分发。如图4所示,每架无人机都与局部环境相互作用,根据从周围环境或者同伴无人机得到的信息,针对承载的任务需求,通过深度强化学习,智能地产生动作策略,进行自身资源与行为的分配与调整,进而与环境和同伴互动,并获得个体奖励。
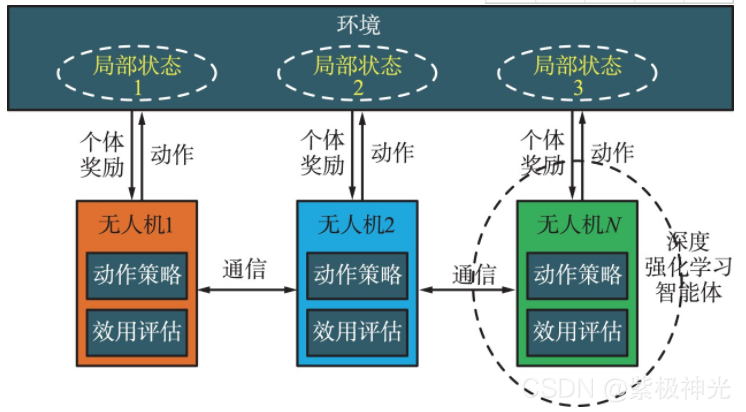
图4 基于多智能体的无人机集群
每架无人机的深度强化学习智能体由2个深度神经网络构成,包括演员网络和评论家网络,如图5所示。
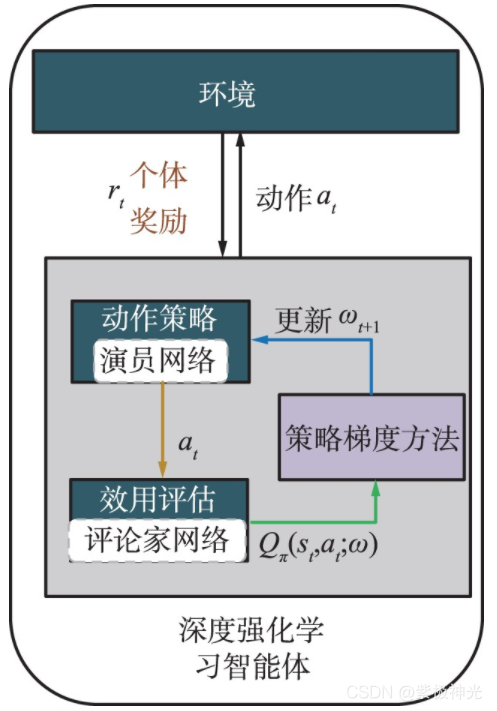
图5 基于演员评论家算法的无人机智能体
演员网络负责输出动作,评论家网络负责评价演员的动作,以获得相互促进的效果。与传统的深度强化学习方法相比,演员-评论家算法同时吸取了基于值函数方法和基于策略函数方法的优点,从价值和策略两方面来训练提升智能体,训练的更快,效果也更好。通过训练和学习,期望智能体的评论家网络可以获得最佳效用评估函数:
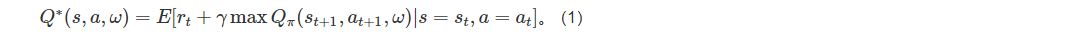
智能体从周围环境中观察得到状态信息St ,例如干扰状态、相邻无人机等。演员网络拟合动作策略函数π(St;ωπ),根据状态信息St,动作策略函数输出当前时隙的动作at,也就是资源分配结果,并应用到环境中得到个体的即时奖励rt。奖励由奖励函数计算得到,负责反馈一个即时的、合理的、具有指导意义的奖励值,从而激励智能体向目标更新策略。评论家网络拟合效用评估函数Q(St,at,ω),负责预测和评估在当前状态St采用动作at所能得到的状态动作价值,即长期性回报Rt为:

式中,γ是折扣因子,γ表示了当前对于未来收益的重视程度,取值在0~1之间,取值0则表示智能体忽视未来收益,只看重当前的收益rt,取值1则表示智能体将未来每个时刻的收益都视为与当前时刻收益一样的重要性。获得最大的长期性回报是智能体的最终目的,这个目标可以根据任务的性质被定义为不同的评判标准。
评论家网络的最佳效用评估函数对应的演员网络动作策略即为最佳动作策略π*。动作策略函数的参数通过策略梯度的方法进行更新,效用评估函数的参数采用最小化损失函数进行更新:

式中,yt为优势函数,用来衡量计算执行动作后的实际效用评估值。通过更新,智能体的演员网络的动作策略输出的动作越来越好,而评论家网络的效用评估也会越来越准确。基于多智能体的无人机群的每架无人机都会朝着收益最大的方向执行动作,从而实现集群的收益最大化。
二、部分源代码
%name:AUV targets searching and avoid obstacles
clc;
clf;
clear all;
global obstacle;
obstacle=[];
global fls;
global auvpos;
fls=cell(1,1);
auvpos=cell(1,1);
insight_point=cell(1,1);
MaximumRange = 150; % 最大探测范围
Vl=zeros(2000,2000);%环境代价矩阵
Time_AllSteps = 50; %额定步数
Y = zeros(Time_AllSteps,6); %状态变量
global subregion;
subregion=[];
sub_obs_coor=[300,900;500,1300;500,1500;700,1300;700,1100;900,700;900,500;
1100,900;1100,700;1100,500;1300,1500;1300,1300;1300,700;
1300,900;1300,500;1500,1300;1500,700;1500,500;1500,1500];%障碍物占据的子区域中心点坐标
n1=1;
n2=1;
sub_area=[];
pp=0;
sub_pp_number=0;
for i=1:5
for j=1:5
p_obs=0;
for n=1:2
for p=1:2
pp=0;
for m=1:size(sub_obs_coor,1)
if((200+(i-1)*400+(-1)^n*100~=sub_obs_coor(m,1))||(200+(j-1)*400+(-1)^p*100~=sub_obs_coor(m,2)))
p_obs=1;
else
pp=1;
break;
end
end
if(pp==0)
sub_pp_number=sub_pp_number+1;
sub_area=[sub_area,200+(i-1)*400+(-1)^n*100,200+(j-1)*400+(-1)^p*100,0];
end
end
end
if(p_obs~=0)
mm=size(sub_area,2);
if(mm>0)
subregion(n1,1:5+mm) = [n1,200+(i-1)*400,200+(j-1)*400,0,0,sub_area];
subregion(n1,18)=sub_pp_number;
sub_pp_number=0;
sub_area=[];
n1=1+n1;
end
end
end
end
global AUV_status;
AUV_status=cell(1,1);
AUV_Angle(:,1)=[0,0,0,0,0,0,0,0,0,0];%AUV的初始艏向角
auv_num(:,1)=[2,2,2,2,2,2,2,2,2,2];
global num_target;
global number_target;
global pos_target;
global pos_tar1;
global sub_auv;
global sublock_area;
global auv_hunt_flag;
global tracking_tar;
global auv_collaborators;
auv_collaborators=zeros(2,3);
[num_target,pos_target,Obstacles]=Make_obstacles4();%障碍物边界
pos_tar1=[pos_target',zeros(size(pos_target,2),1)];
number_target=num_target;
button = 0;
mouse_click=0;
a_n = 1;
while button ~= 3
[x,y,button]=ginput(1); %十字光标
pin= ~isempty(x);
if (pin==1 && button ~= 3)
mouse_click=mouse_click+1;
plot(x,y,'mo')
AUV_status{1}{a_n}(:,1)=[20,0,0,x,y,AUV_Angle(a_n,1)];
a_n = a_n+1;
end
end
hold off;
AUV_num=mouse_click;
AUV_AngTemp=AUV_Angle(1:mouse_click,1);
%******视线导引的切换点的半径*********
R=8;
n=ones(AUV_num,1);
angle_v=zeros(AUV_num,1);
flag_obsfind=zeros(AUV_num,1);
line_ok=zeros(AUV_num,1);
sub_flag = zeros(AUV_num,1);
sub_ok = zeros(AUV_num,1);
task_time = zeros(AUV_num,1);
sub_counter = 0;
flag_a=ones(AUV_num,1);
excute_task=zeros(AUV_num,1);
to_sub=zeros(AUV_num,1);
task_do=zeros(AUV_num,1);
tracking_tar=zeros(AUV_num,2);
task_continue=ones(AUV_num,1);
lock_area=zeros(AUV_num,4);
auv_task_start=zeros(AUV_num,2);
auv_hunt_flag=zeros(AUV_num,1);
allsub_task_over=0;
end_flag=0;
stop_sub=zeros(AUV_num,2);
taskovercomingflag=0;
change_flag=0;
dy_search_over=0;
flag_changesub=zeros(AUV_num,3);
sub_auv=zeros(AUV_num,1);
sublock_area=zeros(AUV_num,3);
obs_auv_PosAngleDis=cell(1,1);
sub_n=8;
sub2overflag=1;
line_color=[0,0,1;0,1,0;1,0,0;1,1,0;0,1,1;1,0,1;1,1,1];
global pid_err;
global pid_errobs;
global dynamic_mess;
global Dynamic_pos;
global hunt_time;
global dy_n;
global auv_group;
global vanish_flag;
vanish_flag=zeros(2,3);
auv_group=zeros(6,4);
dy_n=ones(AUV_num,1);
Dynamic_pos=zeros(2,3);
dy_tar_auv_num=zeros(2,1);
hunt_time=zeros(2,1);
pid_err=cell(1,3);
pid_errobs=cell(1,1);
dynamic_mess=cell(1,1);
dy_tar_num=0;
for i=1:AUV_num
pid_err{1}{i}(1:3,1)=0;
pid_errobs{1}{i}(1:3,1)=0;
obs_auv_PosAngleDis{1}{i}=[];
AUV_PosTemp(:,i)=AUV_status{1}{i}(4:5,1);%AUV位置临时变量
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%******视线导引控制PID参数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
global K_p1;
global K_i1;
global K_d1;
% K_p1 =1.0; K_i1 = 0.525; K_d1 =0; %艏向控制
K_p1 =0.35; K_i1 = 0.85; K_d1 =0; %艏向控制
global K_p1obs;
global K_i1obs;
global K_d1obs;
% K_p1obs =0.5; K_i1obs = 3.5; K_d1obs =0;
K_p1obs =0.1; K_i1obs = 0.225; K_d1obs =0;%1 0.625
%%%%%%%%%%%%%%%%%%%
%随机动目标位置生成
x_rt=800;%随机目标位置初始化
y_rt=1600;
global x_sin;
global x_change_flag;
global tar0_Angle;
x_sin=400;
x_change_flag=0;
tar0_Angle=0;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Env_handle=environment_buliding4(pos_target);%环境构建
DrawAUV(AUV_PosTemp,AUV_Angle,AUV_num);
for step=1:1:4000%最大执行步数
% step=1;
% while(1)
t_obs = 0.1;
T1(step,1)=0.1*step;
[OBS_point,flag_obs]=FLS_obsmeasure(Obstacles,AUV_PosTemp,AUV_AngTemp);
[Dynamic_pos(:,1:2),dynamic_pos,dynamic_angle]=RandTarget(x_rt,y_rt);
for i=1:length(AUV_AngTemp)
[search_tar_over]=target_search(AUV_PosTemp(:,i),AUV_AngTemp(i,1));
if(dy_tar_num<2)
[finddynamic_ok,angle_v(i,1),vanish,dy_tar_n,dynamic_tar_pos,find_tar_auv,hunt_group_done]=DynamicTargetSearchFun(AUV_PosTemp,AUV_AngTemp(i,1),Dynamic_pos,i);
end
if(search_tar_over==1)%静态目标和动态目标搜索完毕
if(dy_tar_num==2)
break;
else
dy_search_over=1;
subregion(:,4:5)=0;
end
end
if(flag_obs(i,1)==1&&line_ok(i,1)==0) %上一个时间AUV完成了导引避障
flag_a(i,1)=0;
finddynamic_ok=0;
% pid_err{1}{i}(:,1)=0;
flag_obsfind(i,1)=1;%第i个AUV遇到障碍物
AUV_status{1}{i}(1,auv_num(i,1)-1)=20;%有障碍减速
insight_point{1}{i}(:,1)=AUV_status{1}{i}(4:5,auv_num(i,1)-1);%视线导引起点为当前AUV的位置
insight_point{1}{i}(:,2)= OBS_point(i,:)'; %终点为推算的避障点
obs_auv_PosAngleDis{1}{i}(n(i,1),:)=OBS_point(i,:);
n(i,1)= n(i,1)+1;
else if((flag_obs(i,1)==1&&line_ok(i,1)==1)) %当前时刻检测到障碍物但是上一时刻未完成导引避障
flag_a(i,1)=0;
finddynamic_ok=0;
flag_obsfind(i,1)=1;%第i个AUV遇到障碍物
% AUV_status{1}{i}(1,auv_num(i,1)-1)=20;%有障碍减速
else if(flag_obs(i,1)==0&&line_ok(i,1)==1)%当前时刻未检测到障碍物但是上一时刻未完成导引避障
flag_a(i,1) =0;
finddynamic_ok=0;
flag_obsfind(i,1)=1;
else%当前时刻AUV未检测到障碍物,上一时刻的导引已经完成
flag_a(i,1) =1;
% pid_err{1}{i}(:,1)=0;
flag_obsfind(i,1)=0;%第i个AUV未遇到障碍物
% angle_v(i,1)=0; %不需要避障的,角速度为0
AUV_status{1}{i}(1,auv_num(i,1)-1)=40;%无障碍加速
end
end
end
if(flag_obsfind(i,1)==1)%判断第i个AUV需要视线导引避障
line_ok(i,1)=1;
[r,error,dt,emix]=insight_line(AUV_status{1}{i}(:,auv_num(i,1)-1),insight_point{1}{i}(:,1),insight_point{1}{i}(:,2),i);%直线视线导引控制避障
if(dt<=R)%AUV满足线段切换条件
flag_a(i,1)=1;
flag_obsfind(i,1)=0;%重启声呐检测障碍物
angle_v(i,1)=0;
pid_err{1}{i}(:,1)=0;
line_ok(i,1)=0;
else
angle_v(i,1)=r;
end
end
% %%%%%%%%%%AUV走向分配的子区域过程中或执行子区域任务与避障的临时切换机制%%%%%%%%
% %如果在AUV走向分配的子区域过程中或执行子区域任务时需要避障,
% %那么进行避障,结束后继续执行被中断的过程
% %而不是再重新分配子区域,因为被中断的过程还没有完成
% %%%%%%%%%%%%%%%%%%%切换机制代码区%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
if(flag_a(i,1)==0)
if(task_do(i,1)==1)
excute_task(i,1)=1;%在执行子区域任务时被避障事件中断
else if(sub_ok(i,1)==0)
to_sub(i,1)=1;%在走向分配的子区域是被避障事件中断
end
end
% if(tracking_tar(i,1)==1)%目标围捕过程中发生避障事件
% excute_task(i,1)=0;
% to_sub(i,1)=0;%前期执行的走向子区域和子区域搜索都作废,先避障,
% %如果动态目标不在视域内,完事再重新进行子区域分配;如果在视域内继续进行目标围捕
% end
end
if(finddynamic_ok==1)%发现动态目标,进行跟踪
tracking_tar(i,1)=1;%当前AUV处于动目标围捕过程
tracking_tar(i,2)=dy_tar_n;%当前AUV围捕的目标编号
flag_a(i,1)=0;%进行动目标围捕不执行子区域分配
if(find_tar_auv~=0)
dy_tar_auv_num(dy_tar_n,1)=find_tar_auv;
organizing_auv( AUV_PosTemp,find_tar_auv,dy_tar_n);%一个AUV发现目标后确定队形的其他AUV编号,组成围捕队形
tracking_tar(auv_collaborators(dy_tar_n,2),1)=1;%当前AUV处于动目标围捕过程
tracking_tar(auv_collaborators(dy_tar_n,2),2)=dy_tar_n;%当前AUV围捕的目标编号
flag_a(auv_collaborators(dy_tar_n,2),1)=0;
tracking_tar(auv_collaborators(dy_tar_n,3),1)=1;%当前AUV处于动目标围捕过程
tracking_tar(auv_collaborators(dy_tar_n,3),2)=dy_tar_n;%当前AUV围捕的目标编号
flag_a(auv_collaborators(dy_tar_n,3),1)=0;
sub_auv(find_tar_auv)=0;%进行目标围捕过程中,以前的子区域锁定没到达的取消,取消AUV锁定子区域的标志
sub_auv(auv_collaborators(dy_tar_n,2))=0;
sub_auv(auv_collaborators(dy_tar_n,3))=0;
if(lock_area(find_tar_auv,1)~=0)
if(subregion(lock_area(find_tar_auv,1),lock_area(find_tar_auv,2))==0.5)
subregion(lock_area(find_tar_auv,1),lock_area(find_tar_auv,2))=0;
end
end
if(lock_area(auv_collaborators(dy_tar_n,2),1))
if(subregion(lock_area(auv_collaborators(dy_tar_n,2),1),lock_area(auv_collaborators(dy_tar_n,2),2))==0.5)
subregion(lock_area(auv_collaborators(dy_tar_n,2),1),lock_area(auv_collaborators(dy_tar_n,2),2))=0;
end
end
if(lock_area(auv_collaborators(dy_tar_n,3),1))
if(subregion(lock_area(auv_collaborators(dy_tar_n,3),1),lock_area(auv_collaborators(dy_tar_n,3),2))==0.5)
subregion(lock_area(auv_collaborators(dy_tar_n,3),1),lock_area(auv_collaborators(dy_tar_n,3),2))=0;
end
end
end
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
~~
三、运行结果


四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
[3]巫茜,罗金彪,顾晓群,曾青.基于改进PSO的无人机三维航迹规划优化算法[J].兵器装备工程学报. 2021,42(08)
[4]邓叶,姜香菊.基于改进人工势场法的四旋翼无人机航迹规划算法[J].传感器与微系统. 2021,40(07)
[5]马云红,张恒,齐乐融,贺建良.基于改进A*算法的三维无人机路径规划[J].电光与控制. 2019,26(10)
[6]焦阳.基于改进蚁群算法的无人机三维路径规划研究[J].舰船电子工程. 2019,39(03)
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/119601809

- 点赞
- 收藏
- 关注作者
评论(0)