【语音去噪】基于matlab谱减法+最小均方+维纳滤波语音去噪【含Matlab源码 1542期】

一、简介
1 维纳滤波法
维纳滤波法(wiener filter)也是一个比较经典的传统做法,它的本质是估计出一个线性滤波器,也就是一个向量,这个滤波器会对不同的频段进行不同程度的抑制,其保真效果会比谱减法要好一些。
我们这里不会讲详细的推导过程,只讲其大致思想。因为这么大功夫推导出来,还是有很多不能解决的问题,还不如深度学习train一发。想看详细推导了可以去看知乎的卡尔曼滤波器详解——从零开始(3) Kalman Filter from Zero这篇,于泓-语音增强-维纳滤波这个视频讲的更偏向于应用,都很棒。
还有就是这里讲的是smoothing的问题,即根据未来的信号,过去的信号以及现在的信号来推测出现在的干净信号。除此之外,还有prediction和filtering的问题,prediction是指根据过去的和现在的信号,预测未来的干净信号;filtering的问题是指根据过去和现在的信号,推测现在的干净信号。所以这里讲的方法没法应用于实时语音去噪,只能在拿到整段信号之后,对这段信号进行去噪。
维纳滤波器的设计准则为使得干净信号x(n)x(n)和估计的干净信号x ^ ( n ) 之间的差值越小越好,即计算一个最小均方差


2 卡尔曼
卡尔曼滤波的基本思想是:以最小均方误差为最佳估计准则,采用信号与噪声的状态空间模型,利用前一时刻的估计值和当前时刻的观测值来更新对状态变量的估计,求出当前时刻的估计值,算法根据建立的系统方程和观测方程对需要处理的信号做出满足最小均方误差的估计。
语音信号在较长时间内是非平稳的,但在较短的时间内的一阶统计量和二阶统计量近似为常量,因此语音信号在相对较短的时间内可以看成白噪声激励以线性时不变系统得到的稳态输出。
3 谱减法
应该是最早被用于语音去噪的方法,它的思想非常简单,就是通过估计出噪声,并在频域里将其幅值剪掉,再还原,就结束了。为了表示方便,我们先假设纯净的声音为x(n),原始声音为y(n),噪声为e(x),就有y(n)=x(n)+e(n)
这里只有y(n)是我们有的,其他x(n)和e(n)都还不知道,目的是把x(n)给求出来。
noisereduce中的stationary的方法就是用谱减法去做的,效果还是不错的,不过也只能应对于stationary noise。
我们按谱减法步骤来说明一下整个过程。
(1)截取头部一小段语音作为噪声
e(m)=y(n)[:m]
其中e表示噪声信号,y表示原始信号,m和n表示sample的数量。
我们认为stationary noise是一直存在于背景当中的声音,而人声一般在开头的几十毫秒是没有的,所以就默认取前面一小段作为噪声。不过当无法确定噪声的时候,把整段声音都作为噪声也是可以的,noisereduce就是这么做的。
(2)分别计算原始音频和噪声的STFT,Y(ω)和E(ω)。
(3)根据噪声的频谱幅值,对原始音频的频谱幅值进行谱减。

这样做不好的地方就是会有很多坑坑洼洼的噪声频率残留,这个现象也被称为是音乐噪声。实际操作过会发现这种方法减了和没减差不多。因此有人提出了过减法,就是宁可错杀一千不能放过一个的做法。
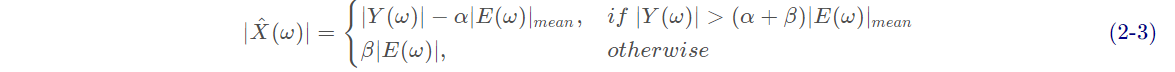
其中,α∈[0,+∞]是过减因子,β∈[0,1]是谱下限参数,用来控制残留多少的噪声。这样减出来噪声会明显少了很多,但声音也会随着α \alphaα的增大而逐渐失真。
noisereduce中的具体实现略有不同,它过减用∣E(ω)∣的方差来控制,一般是1.5倍或者1.0倍的方差。代码片段如下所示
self.mean_freq_noise = np.mean(noise_stft_db, axis=1)
self.std_freq_noise = np.std(noise_stft_db, axis=1)
self.noise_thresh = self.mean_freq_noise + self.std_freq_noise * self.n_std_thresh_stationary
- 1
- 2
- 3
小于noise_thresh的幅值会置0,其余的保留。n_std_thresh_stationary为0时,就是没有过减的式(2−2)。
(4)对∣ X ^ ( ω ) ∣做平滑处理,使得声音失真没那么严重。
noisereduce中使用的scipy.signal.fftconvolve来实现这一过程。
(5)结合原始音频的相位,还原谱减后的音频。这就是个反向STFT的过程。
二、部分源代码
global hr1 hr2 hr3 hr4 s y fs
clf reset
set(gcf,'menubar','none')
set(gcf,'unit','nor malized','position',[0.1,0.1,0.85,0.85]);
set(gcf,'defaultuicontrolunits','normal')
hr1=uicontrol(gcf,'style','popupmenu','string','谱减法|维纳滤波法|最小均方误差估计法','position',[0.65,0.85,0.25,0.03]);
hr2=uicontrol(gcf,'style','toggle','string','开始/关闭','position',[0.72,0.65,0.15,0.05]);
%uicontrol(gcf,'style',')
%htitle1=title('原是语音波形');
uicontrol('style','text','string','原始语音波形','position',[0.25,0.93,0.12,0.03],'horizontal','center');
h_axes1=axes('position',[0.05,0.54,0.52,0.38]);
set(h_axes1,'ylim',[-1,1]);
%t=0:pi/50:2*pi;
%y=sin(t);
%plot(t,y);
[y,fs,bit]=wavread('D:\3 ★Matlab★\Matalb CSDN\【信号处理】\【语音处理】\【语音增强】基于matlab谱减法、最小均方和维纳滤波语音增强【含Matlab源码 482期】\1_NumSound_snr10.wav');
L1=length(y);
t1=1:L1;
plot(t1,y);
uicontrol('style','text','string','增强后语音波形','position',[0.25,0.45,0.12,0.03],'horizontal','center');
h_axes2=axes('position',[0.05,0.05,0.52,0.38]);
set(h_axes2,'ylim',[-1,1]);
set(hr1,'callback','speech_enhancement');
set(hr2,'callback','speech_enhancement');
hr3=uicontrol(gcf,'style','toggle','string','播放原始语音','position',[0.7,0.5,0.18,0.05],'horizontal','center');
hr4=uicontrol(gcf,'style','toggle','string','播放增强后的语音','position',[0.7,0.42,0.18,0.05],'horizontal','center');
set(hr3,'callback','play');
set(hr4,'callback','play');
function y=check(x,n);
E=0;
for i=1:n,
E=x(i)*x(i)+E;
end;
E=E/n;
if E<0.01,
x=zeros(1,n);
else
x=x;
end;
y=x;
wave_serial=wavread('4ks71.wav');
figure(1);
plot(wave_serial);
b=fir1(10,1/8);
s=filter(b,1,wave_serial);
E=zeros(1,2000);
N=2000;
for i=1:N
E(i)=abs(s(i));
end
figure(2);
plot(E);
M1=0.03;
for i=0:N
if E(N-i)>M1
X=N-i;
break
end
end
X1=X-600;
X2=X-200;
s1=s(X1:X2);
N1=200;
r=zeros(1,200);
for i=1:N1
for j=1:N1
r(i)=r(i)+abs(s1(j)-s1(i+j));
end
end
figure(3);
plot(r);
M2=r(1);
for i=1:N1
if r(i)>M2
M2=r(i);
end
end
M2=M2/2-1;
Y=zeros(1,20);
B=zeros(1,20);
j=0;
for i=2:(N1-1)
if r(i-1)>r(i) & r(i)<r(i+1) & r(i) <M2
j=j+1;
Y(j)=i;
B(j)=r(i);
end
end
F=0;
j=j-1;
N_keynote=0;
for i=1:j
N_keynote=N_keynote+(Y(i+1)-Y(i));
end
F=j*4000/N_keynote;
res='0';
if F<=195
res='M';
else
res='F';
end
F
M2
res
Y
B
[y,fs,bit]=wavread('g:\gun_freq.wav');
[Y,f]=psd(y(1500:1660),256,8000);
plot(f,Y,'r-');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
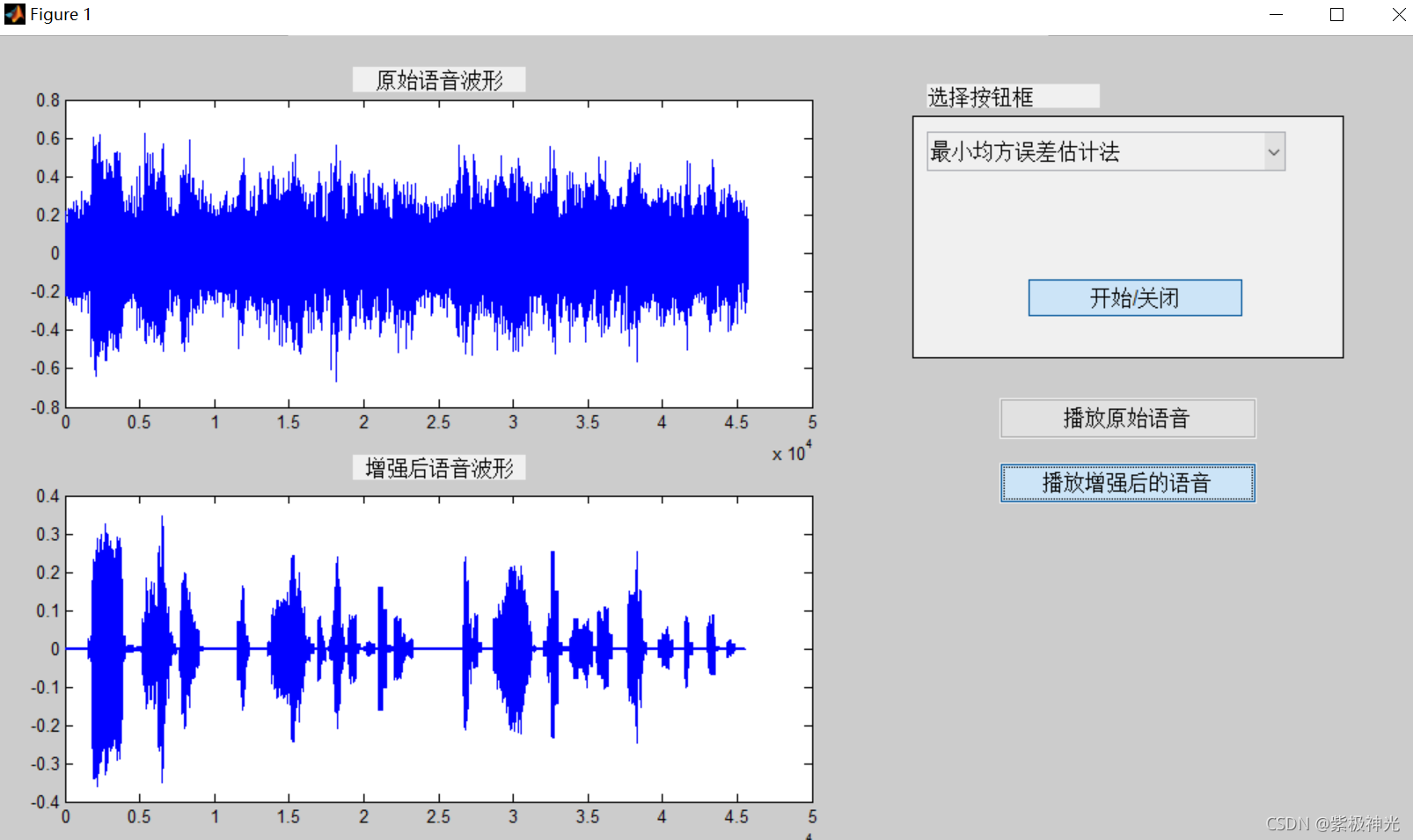
三、运行结果


四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/121590089

- 点赞
- 收藏
- 关注作者
评论(0)