【语音识别】基于matlab GUI动态时间规整算法(RTW)语音识别系统【含Matlab源码 341期】

一、动态时间规整算法(RTW)语音识别
软件算法主要分为语音信号滤波去噪、预加重、分帧、端点检测、特征参数提取、模式匹配。算法的关键点和难点是特征参数提取和模式匹配。孤立词的语音识别应用程序也是基于MATLAB的GUI进行开发。
1 语音预处理
语音信号是一种典型的非平稳随机信号, 容易受到呼吸气流、环境背景噪声、电流噪声的影响。所以, 在对语音信号进行下一步分析之前, 需要对硬件电路采集回来的语音信号进行预滤波、预加重、分帧加窗、端点检测等。预处理后的语音信号噪声干扰较小, 信号较纯净, 特征参数较稳定, 适合后续的模式识别和匹配分类, 图2是语言信号预处理过程图。
2 语音特征信息提取
经过端点检测后的语音信息再进行特征参数提取和模式匹配研究, 该算法基于线性预测系数LPC模型为基础开展研究, 由于LPC模型对于动态性较强的辅音不严格成立, 语音信号的特征参数鲁棒性不是很好。现阶段在语音识别技术中得到广泛应用的梅尔频率倒谱系数是另一种更加有效的语音特征参数。梅尔 (Mel) 频率倒谱系数是基于人耳听觉特性提出的, 将人耳听觉感知特性与人类语音产生结合起来得到的一种特征参数。由于对输入信号不做假设和约束, 与输入信号特性无关, 因此, 具有较高的鲁棒性。
当声音频率低于1000Hz的时候, 人耳对声音的感知近似满足线性关系;当声音频率高于1000Hz的时候, 人耳对声音的感知不再近似满足线性关系, 而是在对数频率坐标上近似满足线性关系。
MEL频率倒谱系数的计算过程见图3。
通常MFCC系数的第一维C (0) 的能量很大, 在语音识别系统中, 将C (0) 称为能量系数, 不作为倒谱系数。
利用上述方法提取的MFCC参数只能表征语音信号的静态特征, 然而人耳对语音信号的动态特征更为敏感。为了更准确地反映语音动态特征需要进行二次特征提取。二次特征提取是指对原始特征向量进行二次分析, 通常是加权、差分、筛选。在语音识别中, 一阶和二阶差分可以表示特征向量变化速度, 体现了语音的言语和韵律变化, 较好地描述了语音信号的动态特性。因此, 采用一阶和二阶差分倒谱参数来描述语音信号。
3 动态时间规整识别算法
前面的端点检测算法确定了语音信号的起点和终点。假设参考模板为{R1, R2, (43) Rm (43) , RM}, 共M帧;测试语音为{T1, T2, (43) Tn (43) , TN}, 共N帧。由于M≠N, 动态时间规整通过寻找一个时间规整函数m=w (n) , 使得测试语音的时间轴n通过非线性变换函数w映射到参考模板的时间轴m, 并使得该函数满足一下关系式:
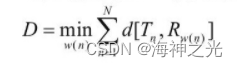
在这里, d[Tn, Rw (n) ]是第n帧测试语音特征矢量与第m帧参考模板特征矢量之间的距离。D就是处于最优时间规整情况下两矢量的累积距离。由于DTW不断地计算两矢量的距离以寻找最优的匹配路径, 所以得到的是两矢量匹配时累积距离最小所对应的规整函数, 这就保证了它们之间存在的最大声学相似性。
基本的DTW算法对端点检测非常敏感, 它要求进行比较的两个模板起点和终点分别对应, 并且对端点检测的精度要求很高, 在背景噪声较大或者语音中存在摩擦音时, 端点检测往往不会非常精准, 端点检测结果可能会对动态规整造成不可预知的误差。此时, 必须将边界约束条件放宽。通常的做法是放宽区域中边界约束条件不再要求起点和终点严格对齐, 这样就解决了由于端点检测算法的缺陷带来的参考模板和测试模板的起点和终点不能分别对齐的问题。实际中, 起点和终点分别在横轴和纵轴两个方向上各放宽2~3帧, 即起点 (1, 1) 、 (1, 2) 、 (1, 3) 、 (2, 1) 、 (3, 1) 处, 终点类推, 就可以在不影响识别结果的前提下解决端点检测缺陷问题。
二、部分源代码
- 1
三、运行结果



四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
[3]张慧敏.基于动态时间规整算法的语音识别技术研究[J].科技资讯 2017,15(26),28-31
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/124637326

- 点赞
- 收藏
- 关注作者
评论(0)